







freemarker导出word常用方法及说明
1. 如何生成word导出模板
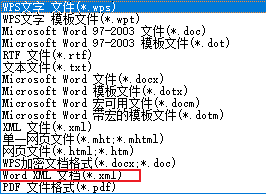
可以直接将word另存为xml文件,然后打开就是xml标签样式的模板
!!!注意保存的格式必须为Word XML文档格式
2. 标签含义
<w:p> <!--表示一个段落-->
<w:val > <!--表示一个值-->
<w:r> <!--表示一个样式串,指明它包括的文本的显示样式,表示一个特定的文本格式-->
<w:t> <!--表示真正的文本内容-->
<w:rPr> <!--是<w:r>标签内的标签,对Run文本属性进行修饰-->
<w:pPr> <!--是<w:p>标签内的标签,对Paragraph文本属性进行修饰-->
<w:rFronts> <!--字体-->
<w:hdr> <!--页眉-->
<w:ftr> <!--页脚-->
<w:drawing > <!--图片-->
<wp:extent> <!--绘图对象大小-->
<wp:effectExtent > <!--嵌入图形的效果-->
<wp:inline > <!--内嵌绘图对象,dist(T,B,L,R)距离文本上下左右的距离-->
<w:noProof > <!--不检查拼写和语法错误-->
<w:docPr> <!--表示文档属性-->
<w:rsidR> <!--指定唯一一个标识符,用来跟踪编辑在修订时表行标识,所有段落和段落中的内容都应该拥有相同的属性值,如果出现差异,那么表示这个段落在后面的编辑中被修改。-->
<w:r> <!--表示关系,段落中以相连续的中文或英文字符字符串,作为开始和结束。目的就是要把一个段落中的中英文字符区分开来。 -->
<w:ind> <!--w:pPr元素的子元素,跟w:pStyle并列,ind代表缩进情况:有几个属性值:①firstLine(首行缩进)②left(左缩进)③当left和firstLine同时出现时代表下面的元素有两种属性首行和下面其他行都是有属性的④hanging(悬挂)-->
<w:hint> <!--字体的类型,w:rFonts的子元素,属性值eastAsia表面上的意思是“东亚”,指代“中日韩CJK”类型。-->
<w:bCs> <!--复合字体的加粗-->
<w:bookmarkStart> <!--书签开始-->
<w:bookmarkEnd> <!--书签结束-->
<w:lastRenderedPageBreak > <!--页面进行分页的标记,是w:r的一个属性,表示此段字符串是一页中的最后一个字符串。-->
<w:smartTag > <!--智能标记-->
<w:attr > <!--自定义XML属性-->
<w:b w:val=”on”> <!--表示该格式串种的文本为粗体-->
<w:jc w:val="right"/> <!--表示对齐方式-->
<w:sz w:val="40"/> <!--表示字号大小-->
<w:szCs w:val="40"/> <!---->
<w:t xml:space="preserve"> <!--保持空格,如果没有这内容的话,文本的前后空格将会被Word忽略-->
<w:spacing w:line="600" w:lineRule="auto"/> <!--设置行距,要进行运算,要用数字除以240,如此处为600/240=2.5倍行距-->
<w:jc w:val="center"/> <!-- 这句话表示段落对齐方式 -->
<!-- 分页 -->
<w:r>
<w:br w:type="page"/>
</w:r>
<!-- 设置了页的宽,高,和页的各边距。各项的值均是英寸乘1440得出 -->
<w:body>
<w:sectPr>
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="720" w:footer="720" w:gutter="0"/>
</w:sectPr>
</w:body>
<!--页眉和页脚-->
<w:sectPr wsp:rsidR="002C452C">
<w:hdr w:type="odd" >
<w:p>
<w:pPr>
<w:pStyle w:val="Header"/>
</w:pPr>
<w:r>
<w:t>这是页眉</w:t>
</w:r>
</w:p>
</w:hdr>
<w:ftr w:type="odd">
<w:p>
<w:pPr>
<w:pStyle w:val="Footer"/>
</w:pPr>
<w:r>
<w:t>这是页脚</w:t>
</w:r>
</w:p>
</w:ftr>
</w:sectPr>
<!--表示文档的视图是“print”,视图比例100%-->
<w:docPr>
<w:view w:val="print"/><w:zoom w:percent="100"/>
</w:docPr>
<w:tcW w:w="269" w:type="pct"/>

3. 表格
gridCol 中的w是基于表格特定算法计算出的,推荐word调整完成后另存为word xml
<w:tbl>
<w:tblPr>
<w:tblStyle w:val="af0"/>
<w:tblW w:w="5000" w:type="pct"/>
<w:tblBorders>
<w:top w:val="single" w:color="auto" w:sz="4" w:space="0"/>
<w:left w:val="single" w:color="auto" w:sz="4" w:space="0"/>
<w:bottom w:val="single" w:color="auto" w:sz="4" w:space="0"/>
<w:right w:val="single" w:color="auto" w:sz="4" w:space="0"/>
<w:insideH w:val="single" w:color="auto" w:sz="4" w:space="0"/>
<w:insideV w:val="single" w:color="auto" w:sz="4" w:space="0"/>
</w:tblBorders>
<w:tblLook w:val="04A0" w:firstRow="1" w:lastRow="0" w:firstColumn="1" w:lastColumn="0" w:noHBand="0" w:noVBand="1"/>
</w:tblPr>
<w:tblGrid>
<w:gridCol w:w="713"/>
<w:gridCol w:w="1619"/>
<w:gridCol w:w="1404"/>
<w:gridCol w:w="1404"/>
<w:gridCol w:w="2373"/>
<w:gridCol w:w="1231"/>
</w:tblGrid>
<w:tr>
<w:trPr>
<w:trHeight w:val="425"/>
</w:trPr>
<w:tc>
<w:p>
<w:pPr>
<w:rPr>
<w:rFonts w:ascii="微软雅黑" w:eastAsia="微软雅黑" w:hAnsi="微软雅黑" w:cs="微软雅黑"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="微软雅黑" w:eastAsia="微软雅黑" w:hAnsi="微软雅黑" w:cs="微软雅黑" w:hint="eastAsia"/>
</w:rPr>
<w:t>序号</w:t>
</w:r>
</w:p>
</w:tc>
</w:tr>
4. 逻辑符号
- if
结构
<#if 条件>
...
<#else>
...
</#if>
条件示例
<#if list?? && list?size gt 0>
集合不为null且集合大小大于0
</#if>
------------------------------------
!!!!!!!!注意,这里有一坑,Java中布尔值应命名为isXXX,比如 private boolean isBigHeadline;
否则不会识别成功
<#if o.bigHeadline>
布尔值为true
</#if>
------------------------------------
<#list o.keyEntList as item>
<#if item_has_next>
集合是否有下一个元素
</#if>
</#list>
------------------------------------
!!! 注意需要加括号,也是一个坑
<#if (o.num+1) lte 2>
数字+1,小于等于2
</#if>
- 递归
<#macro> 宏方法,Tree方法名, param 入参, list为传入参数
<#macro Tree param>
<#list param as o>
<#if o.children?? && o.children?size gt 0>
<@Tree param = o.children/>
</#if>
</#list>
</#macro>
<!-- 调用宏 生成递归树 -->
<@Tree param = list />
5. 自定义方法(序号转中文序号)
- java中定义方法
import freemarker.template.TemplateMethodModelEx;
import java.util.List;
/**
* 数字转中文
*/
public class NumToChineseMethod implements TemplateMethodModelEx {
@Override
public Object exec(List args) {
if (args.isEmpty()) {
return "";
}
int src = Integer.parseInt(args.get(0).toString());
final String[] num = {"零", "一", "二", "三", "四", "五", "六", "七", "八", "九"};
final String[] unit = {"", "十", "百", "千", "万", "十", "百", "千", "亿", "十", "百", "千"};
String dst = "";
int count = 0;
while (src > 0) {
dst = (num[src % 10] + unit[count]) + dst;
src = src / 10;
count++;
}
if (dst.startsWith("一十")) {
dst = dst.substring(1);
}
return dst.replaceAll("零[千百十]", "零").replaceAll("零+万", "万")
.replaceAll("零+亿", "亿").replaceAll("亿万", "亿零")
.replaceAll("零+", "零").replaceAll("零$", "");
}
}
- 数据渲染模板时一并传入
// 填充数据
Map<String, Object> dataMap = new HashMap<>();
dataMap.put("list", list);
dataMap.put("numToChinese", new NumToChineseMethod());
WordUtils.generateWord(dataMap, "xxxxx.ftl", "xxxx.doc", response);
- 模板中使用
<w:r>
<w:rPr>
<w:rStyle w:val="19"/>
</w:rPr>
<w:t>${numToChinese((o_index+1))} 、${o.labelName}</w:t>
</w:r>
6. 导出图片至word
首先需要将图片转为base64编码,然后将 编码后的内容 ( imgData ) 渲染在模板中
<#list list as item>
<w:p>
<w:pPr>
<w:spacing w:line="240" w:line-rule="auto"/>
<w:rPr>
<w:rFonts w:ascii="仿宋" w:h-ansi="仿宋" w:fareast="仿宋" w:hint="fareast"/>
<w:sz w:val="32"/>
<w:sz-cs w:val="32"/>
<w:lang w:val="EN-US" w:fareast="ZH-CN"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:ascii="仿宋" w:h-ansi="仿宋" w:fareast="仿宋" w:hint="fareast"/>
<w:sz w:val="32"/>
<w:sz-cs w:val="32"/>
<w:lang w:val="EN-US" w:fareast="ZH-CN"/>
</w:rPr>
<w:pict>
<w:binData w:name="wordml://${item_index}.png">
${item.imgData}
</w:binData>
<v:shape id="_x0000_s10${item_index}" o:spt="75" type="#_x0000_t75"
style="height:261.2pt;width:414.95pt;" filled="f" o:preferrelative="t" stroked="f"
coordsize="21600,21600">
<v:path/>
<v:fill on="f" focussize="0,0"/>
<v:stroke on="f"/>
<v:imagedata src="wordml://${item_index}.png" o:title="图片${item_index}"/>
<o:lock v:ext="edit" aspectratio="t"/>
<w10:wrap type="none"/>
<w10:anchorlock/>
</v:shape>
</w:pict>
</w:r>
</w:p>
</#list>
7.freemarker导出word工具类及远程图片转BASE64 - 代码
import freemarker.cache.ClassTemplateLoader;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import org.apache.commons.io.IOUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ui.freemarker.FreeMarkerTemplateUtils;
import javax.servlet.http.HttpServletResponse;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import java.util.Map;
/**
* @author ZHAIKE
* @date 2023/02/14 15:51
*/
public class WordUtils {
private static Logger logger = LoggerFactory.getLogger(WordUtils.class);
/**
* 生成 word 文档方法
*
* @param dataMap 要填充的数据
* @param templateName 模版名称
* @param filename 文件名
*/
public static void generateWord(Map<String, Object> dataMap, String templateName, String filename, HttpServletResponse response) {
// 设置FreeMarker的版本和编码格式
Configuration configuration = new Configuration(Configuration.VERSION_2_3_25);
configuration.setDefaultEncoding("UTF-8");
configuration.setClassicCompatible(true);
configuration.setTemplateLoader(new ClassTemplateLoader(WordUtils.class.getClassLoader(), "templates"));
// 设置FreeMarker生成Word文档所需要的模板
try {
Template t = configuration.getTemplate(templateName, "UTF-8");
String content = FreeMarkerTemplateUtils.processTemplateIntoString(t, dataMap);
// 导出
response.setContentType("application/msword");
response.addHeader(
"content-disposition",
"attachment;filename=" + new String(filename.getBytes(), StandardCharsets.ISO_8859_1));
OutputStream os = response.getOutputStream();
IOUtils.copy(new ByteArrayInputStream(content.getBytes(StandardCharsets.UTF_8)), os);
os.close();
} catch (IOException | TemplateException e) {
logger.error("freemarker生成word失败", e);
}
}
/**
* 远程图片转base64编码
*/
public static String base64Encode(String imageUrl) throws IOException {
imageUrl = encode(imageUrl, "UTF-8");
URL url = new URL(imageUrl);
InputStream in = url.openStream();
return Base64.getEncoder().encodeToString(IOUtils.toByteArray(in));
}
/**
* 替换中文字符串
*
* @param str 被替换的字符串
* @param charset 字符集
* @throws UnsupportedEncodingException 不支持的字符集
*/
public static String encode(String str, String charset) throws UnsupportedEncodingException {
String zhPattern = "[\\u4e00-\\u9fa5]";
Pattern p = Pattern.compile(zhPattern);
Matcher m = p.matcher(str);
StringBuffer b = new StringBuffer();
while (m.find()) {
m.appendReplacement(b, URLEncoder.encode(m.group(0), charset));
}
m.appendTail(b);
return b.toString();
}
}
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











