










内核中的dump_stack()
获得内核中当前进程的栈回溯信息需要用到的最重要的三个内容就是:
栈指针:sp寄存器,用来跟踪程序执行过程。
返回地址:ra寄存器,用来获取函数的返回地址。
程序计数器:epc,用于定位当前指令的位置。
本文的内容都是基于mips体系架构的,如果你不搞mips,就只看个大致流程就可以了,不然可能会被某些内容误导。在ARM中,这三个寄存器分别为SP、LR和PC寄存器。
dump_stack()用于回溯函数调用关系,他需要做的工作很简单:
1. 从进程栈中找到当前函数(callee)的返回地址。
2. 根据函数返回地址,从代码段中定位该地址位于哪个函数中,找到的函数即为caller函数。
3. 打印caller函数的函数名。
4. 重复前3个步骤。直到返回值为0或不在内核记录的符号表范围内。
在编译程序的时候,所有函数所需要的栈空间的大小都已经计算出来,如果函数需要保存返回地址,返回地址在该函数的栈空间中保存的位置也都计算出来了。所以,我们想得到返回地址,只需得到每个函数栈即可,而所有函数栈都放在进程的栈中,栈顶为sp。
返回地址是caller函数中将要执行的指令,是指向代码段的,这个更容易得到,因为代码段在编译时就确定了。
当前函数的位置通过pc的值可以得到。
例如,现在有func0调用func1,func1又调用func2,在func2执行过程中,进程栈空间大致如下:
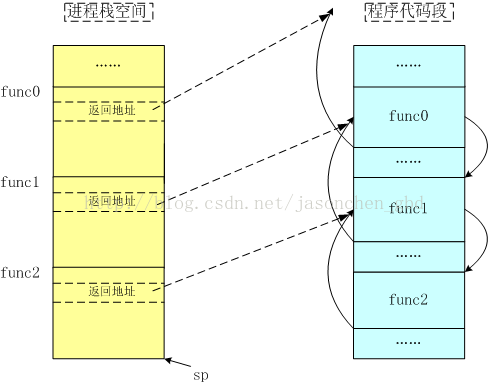
左图为栈空间,栈顶为sp,右图为程序代码的部分内容。右图中的实曲线表示出了函数之间的调用和返回关系。调用关系通过跳转指令完成,返回地址通过左图每个函数栈空间中存储的返回地址指定。这样我们就可以得到函数的调用关系,并通过每个函数的地址打印出函数名。
那dump_stack的工作流程就很清楚了。我就不帖代码了,因为基本上都是体系结构相关的操作。
需要说明的一个地方是,通过函数的地址来打印函数名是通过格式控制符%pS来打印的:
printk("[<%p>] %pS\n", (void *) ip,(void *) ip);
在内核代码树的lib/vsprintf.c中的pointer函数中,说明了printk中的%pS的意思:
即'S'表示打印符号名,而这个符号名是kallsyms里获取的。
可以看一下kernel/kallsyms.c中的kallsyms_lookup()函数,它负责通过地址找到函数名,分为两部分:
1. 如果地址在编译内核时得到的地址范围内,就查找kallsyms_names数组来获得函数名。
2. 如果这个地址是某个内核模块中的函数,则在模块加载后的地址表中查找。
kallsyms_lookup()最终返回字符串“函数名+offset/size[mod]”,交给printk打印。
关于内核符号表kallsyms_names可参考我的另一篇文章点击打开链接。
实现应用程序中的dump_stack()
按照如上所述,实现一个用户态程序的dump_stack好像不是什么难事,因为上面说的步骤在用户态都可以完成,程序运行的方式也基本上是相同的。
那我们实现一个dump_stack需要做的事情只有两点:
1. 获得程序当前运行时间点的pc值和栈指针sp。这样就可以得到每个函数栈中的返回地址。
2. 构造和内核符号表相同的应用程序符号表。
需要注意,不同用户进程都拥有自己的虚拟地址空间,所以栈回溯只能在本进程中完成。
具体实现当然也是体系结构相关的。既然原理都知道了,那我就直接给出代码供参考(mips的)。代码见https://github.com/castoz/backtrace。
其中backtrace.c实现了栈回溯,uallsyms.c用于生成符号表,main.c中为测试代码。
backtrace.c中提供了两个接口供其他文件调用:
show_backtrace():打印函数的回溯信息。
addr_to_name(addr):打印addr对应的函数名。
uallsyms.c文件直接使用内核中的scripts/kallsyms.c,只需要做少量修改,具体的改动为:
1. 符号基准地址改为__start。
2. 需要记录的符号范围改为在_init到_fini之间或_init到_end之间。
3. 维护uallsyms_addresses、uallsyms_num_syms和uallsyms_names三个全局变量,不使用压缩算法,所以不需要其他三个全局变量。
4. 在生成的汇编代码中删除"#include <asm/types.h>"一行,因为在编译时不需要。
测试文件main.c的内容:
执行make all生成可执行文件testbt,放到mips的系统上运行。
运行结果:
参考自:http://blog.csdn.net/jasonchen_gbd/article/details/44066815
在内核中维护者一张符号表,记录了内核中所有的符号(函数、全局变量等)的地址以及名字,这个符号表被嵌入到内核镜像中,使得内核可以在运行过程中随时获得一个符号地址对应的符号名。而内核代码中可以通过 printk("%pS\n", addr) 打印符号名。
本文介绍内核符号表的生成和查找过程。
1. System.map和/proc/kallsyms
System.map文件是编译内核时生成的,它记录了内核中的符号列表,以及符号在内存中的虚拟地址。这个文件通过nm命令生成,具体可参考内核目录下的scripts/mksysmap脚本。System.map中每个条目由三部分组成,例如:
f0081e80 T alloc_vfsmnt
即“地址 符号类型 符号名”
其中符号类型有如下几种:
- A =Absolute
- B =Uninitialised data (.bss)
- C = Comonsymbol
- D =Initialised data
- G =Initialised data for small objects
- I = Indirectreference to another symbol
- N =Debugging symbol
- R = Readonly
- S =Uninitialised data for small objects
- T = Textcode symbol
- U =Undefined symbol
- V = Weaksymbol
- W = Weaksymbol
- Corresponding small letters are local symbols
/proc/kallsyms文件是在内核启动后生成的,位于文件系统的/proc目录下,实现代码见kernel/kallsyms.c。前提是内核必须打开CONFIG_KALLSYMS编译选项。它和System.map的区别是它同时包含了内核模块的符号列表。
通常情况下我们只需要_stext~_etext和_sinittext~_einittext之间的符号,如果需要将nm命令获得的所有符号都记录下来,则需要开启内核的CONFIG_KALLSYMS_ALL编译选项,不过一般是不需要打开的。
2. 内核符号表
内核在执行过程中,可能需要获得一个地址所在的函数,比如在输出某些调试信息的时候。一个典型的例子就是使用dump_stack()函数打印栈回溯信息。
但是内核在查找一个地址对应的函数名时,没有求助于上述两个文件,而是在编译内核时,向vmlinux嵌入了一个符号表,这样做可能是为了方便快速的查找并避免文件操作带来的不良影响。
2.1 内核符号表的结构
内嵌的符号表是通过内核目录下的scripts/kallsyms工具生成的,工具的源码为相同目录下的kallsyms.c。这个工具的用法如下:
可见同样是通过nm命令得到vmlinux的符号表,并将这些符号表信息进行调整,最终生成一个汇编文件。这个汇编文件中包含了6个全局变量:kallsyms_addresses,kallsyms_num_syms,kallsyms_names,kallsyms_markers,kallsyms_token_table和kallsyms_token_index,其中:
- kallsyms_addresses:一个数组,存放所有符号的地址列表,按地址升序排列。
- kallsyms_num_syms:符号的数量。
- kallsyms_names:一个数组,存放所有符号的名称,和kallsyms_addresses一一对应。
其他三个全局变量的含义后续会提到。
这些变量被嵌入在vmlinux中,所以在内核代码中直接extern就可以使用。例如dump_stack()就是通过这些变量来查找一个地址对应的函数名的。
那由scripts/kallsyms生成的汇编文件是如何嵌入到vmlinux中的呢。在编译内核的后期主要进行了一下几步额外的编译和链接过程:
- 链接器ld将内核的绝大部分组件链接成临时内核映像.tmp_vmlinux1。
- 使用nm命令将.tmp_vmlinux1中符号和相对的地址导出来,并使用kallsyms工具生成tmp_kallsyms1.S的文件。
- 对.tmp_kallsyms1.S文件进行编译生成.tmp_kallsyms1.o文件。
- 重复1的链接过程,这次将步骤3得到的.tmp_kallsyms1.o文件链接进入内核得到临时内核映像.tmp_vmlinux2文件,其中包含的部分函数和非栈变量的地址发生了变化,但但由于.tmp_kallsyms1.S中的符号表还是旧的,所以.tmp_vmlinux2还不能作为最终的内核映像。
- 再使用nm命令将.tmp_vmlinux2中符号和相对的地址导出来,并使用kallsyms工具生成tmp_kallsyms2.S的文件。
- 对.tmp_kallsyms2.S文件进行编译生成.tmp_kallsyms2.o文件。
- .tmp_kallsyms2.o即为最终的kallsyms.o目标,并链接进入内核生成vmlinux文件。
此时,上面的那6个全局变量被写进vmlinux中的“.rodata”段(所以还是叫全局常量吧),内核代码就可以使用了,使用前需extern一下:
weak属性表示当我们不确定外部模块是否提供了某个变量或函数时,可以将这个变量或函数定义为弱属性,如果外部有定义则使用,没有定义则相当于自己定义。
在使用这6个全局常量之前,我们先要弄清楚他们都是干什么用的。kallsyms_addresses、kallsyms_num_syms和kallsyms_names在前面已经讲过,实际上他们已经可以提供一个[地址 : 符号]的映射关系了,但是内核中几万个符号这样一条一条的存起来会占用大量的空间,所以内核采用一种压缩算法,将所有符号中出现频率较高的字符串记录成一个个的token,然后将原来的符号中和token匹配的子串进行压缩,这样可以实现使用一个字符来代替n个字符,以减小符号存储长度。
因此符号表维护了一个kallsyms_token_table,他有256个元素,对应一个字节的长度。由于符号名的只能出现下划线、数字和字母,那在kallsyms_token_table[256]数组中,除了这些字符的ASCII码对应的位置,还有很多未被使用的位置就可以用来存储压缩串。kallsyms_token_table表的内容像下面这样:
那我们在表示一个函数名时,就可以用0x00来表示“end”,用0x04来表示“to_”等。没有被压缩的如0x61仍然表示“a”。
kallsyms_token_index记录每个token首字符在kallsyms_token_table中的偏移。同token table共256条,在打印token时需要用到。
至于kallsyms_token_table表是如何生成的,可以阅读scripts/kallsyms.c的实现,大致就是将所有符号出现的相邻的两个字符出现的次数都记录起来,例如对于“nf_nat_nf_init”,就记录下“nf”、“f_”、“_n”、“na”、……,每两个字符组合出现的次数记录在token_profit[0x10000]数组中(两个字符一组,共有2^8 * 2^8 = 0x10000中可能组合),然后挑选出现次数最多的一个组合形成一个token,比如用“g”来表示“nf”,那“nf_nat_nf_init”就被改为“g_nat_g_init”。接下来,再在修改后的所有符号中计算每两个字符的出现次数来挑选出现次数最多的组合,例如用“J”来表示“g_”,那“g_nat_g_init”又被改为“Jnat_Jinit”。直到生成最终的token表。
2.2 内核查找一个符号的过程
这时还没讲到全局常量kallsyms_markers。我们先来看内核如何根据这六个全局常量来查找一个地址对应的函数名的,实现函数为kernel/kallsyms.c中的kallsyms_lookup()。
我不讲函数实现,只是用一个例子来说明内核符号的查找过程:
比如我在内核中想打印出0x80216bf4地址所在的函数。首先不管内核怎么做,我们可以先在System.map文件中看到这个地址位于为nf_register_hook和nf_register_hooks两个符号之间,那可以确定它属于nf_register_hook函数了。
80060000 A _text
... ...
80216b8c T nf_unregister_hooks
80216be4 T nf_register_hook
80216c8c T nf_register_hooks
... ...
注意,System.map和内核启动后的/proc/kallsyms文件中的符号表只是给我们看的,内核不会使用它们。
在由script/kallsyms工具生成的.tmp_kallsyms2.S文件中,kallsyms_addresses数组存放着所有符号的地址,并且是按照地址升序排列的,所以通过二分查找可以定位到0x80216bf4所在函数的起始地址是下面的这个条目:
kallsyms_addresses:
... ...
PTR _text + 0x1b6be4
... ...
而这一项在kallsyms_addresses中的index为8801,所以现在需要找到kallsyms_names中的第8801个符号。
我们这时实际上可以在kallsyms_names进行查找了,怎么找呢?我们先看一下kallsyms_names大致的样子:
其中每一行存储一个压缩后的符号,而index和kallsyms_addresses中的index是一一对应的。每一行的内容分为两部分:第一个byte指明符号的长度,后续才是符号自身。虽然我们这里看到的符号是一行一行分开的,但实际上kallsyms_names是一个unsigned char的数组,所以想要找第8801个符号,只能这样来找:
1. 从第一个字节开始,获得第一个符号的长度len;
2. 向后移len+1个字节,就达到第二个符号的长度字节,这时记录下已经走过的总长度;
3. 重复前两步的动作,直到走过的总长度为8801。
这样找的话,要找到kallsyms_names的第8801个符号就要移动8801次,那如果要寻找最后一个符号,就要移动更多次,时间耗费较多,所以内核通过一个kallsyms_markers数组进行查找。
将kallsyms_names每256个符号分为一组,每一组的第一个字符的位置记录在kallsyms_markers中,这样,我们在找kallsyms_names中的某个条目时,可以快速定义到它位于那个组,然后再在组内寻找,组内移动次数最多为255次。
所以我们先通过(8801 >> 8)得到了要找的符号位于第34组,
我们看到kallsyms_markers的第34项为:
PTR 91280
这个值指明了kallsyms_names中第34组的起始字符的偏移,所以我们直接找到kallsyms_names[91280]位置,即是第34组所有符号的第一个字节。同时我们可以通过(8801 && 0xFF)得到要找的符号在第34组组内的序号为97,即第97个符号。
接下来寻找第97个符号就只能通过上面讲到的方法了。
通过上面一系列的查找,我们定位到第34组中第97个符号如下:
.byte 0x08, 0x05, 0x66, 0xdc, 0xb6, 0xc8, 0x68, 0x6f,0x0b
这个是压缩后的符号,第一个字节0x08是符号长度,所以我们接下来的任务就剩下解压了。
每个字节解压后对应的字符串在kallsyms_token_table中可以找到。于是在kallsyms_token_table表中寻找第5(0x05)项、第5(0x05)项、第102(0x66)项、……、第11(0x0b)项,得到的结果分别为:
"Tn", "f", "_re","gist", "er_", "h", "o", "ok"
由于在压缩的时候将符号类型“T”也压进去了,所以要去掉第一个字符,至此就获得了0x80216bf4地址所在的函数为nf_register_hook。
参考自:http://blog.csdn.net/jasonchen_gbd/article/details/44025681
3. 内核模块的符号
内核模块是在内核启动过程中动态加载到内核中的,所以,不能试图将模块中的符号嵌入到vmlinux中。加载模块时,模块的符号表被存放在该模块的struct module结构中。所有已加载的模块的structmodule结构都放在一个全局链表中。
在查找一个内核模块的符号时,调用的函数依然是kallsyms_lookup(),模块符号的实际查找工作在get_ksymbol()函数中完成。
附录:一个.tmp_kallsyms2.S文件


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











