






行程编码是一种简单的无损数据压缩算法,其原理是将连续重复出现的数据项用一个计数值和一个表示数据项的符号来表示,从而实现数据的压缩。
行程编码的核心思想在于利用数据的重复性来减少数据的存储空间。当数据中存在大量连续重复出现的情况时,行程编码能够取得较好的压缩效果。然而,如果数据中没有连续重复的情况,行程编码的效率会较低,甚至可能导致压缩后的数据比原始数据还要大。
下面我举一个简单的例子:
假设原始数据为:AAAABBBCCDAA
通过行程编码,可以将其表示为:4A3B2C1D2A
在这个示例中,连续的A有4个,连续的B有3个,连续的C有2个,连续的D有1个,连续 的A有2个。这样就用了数字表示了原来重复的部分,实现了对数据的压缩。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
## 彩色图像灰度化
image = cv.imread('picture3.jpg', 1)
grayimg = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
rows, cols = grayimg.shape
image1 = grayimg.flatten() # 把灰度化后的二维图像降维为一维列表
# print(len(image1))
# 二值化操作
for i in range(len(image1)):
if image1[i] >= 127:
image1[i] = 255
if image1[i] < 127:
image1[i] = 0
data = []
image3 = []
count = 1
# 行程压缩编码
for i in range(len(image1) - 1):
if (count == 1):
image3.append(image1[i])
if image1[i] == image1[i + 1]:
count = count + 1
if i == len(image1) - 2:
image3.append(image1[i])
data.append(count)
else:
data.append(count)
count = 1
if (image1[len(image1) - 1] != image1[-1]):
image3.append(image1[len(image1) - 1])
data.append(1)
# 压缩率
ys_rate = len(image3) / len(image1) * 100
print('压缩率为' + str(ys_rate) + '%')
# 计算数据冗余率
original_data_size = rows * cols
compressed_data_size = len(image3)
redundancy_rate = (original_data_size - compressed_data_size) / original_data_size * 100
print('数据冗余率为' + str(redundancy_rate) + '%')
# 行程编码解码
rec_image = []
for i in range(len(data)):
for j in range(data[i]):
rec_image.append(image3[i])
rec_image = np.reshape(rec_image, (rows, cols))
# cv.imwrite('image/output.jpg', rec_image)
cv.imwrite('image/output_fruit.jpg', rec_image)
# 显示原始图像和重建图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv.cvtColor(image, cv.COLOR_BGR2RGB))
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(rec_image, cmap='gray')
plt.title('Decoded Image')
plt.axis('off')
plt.show()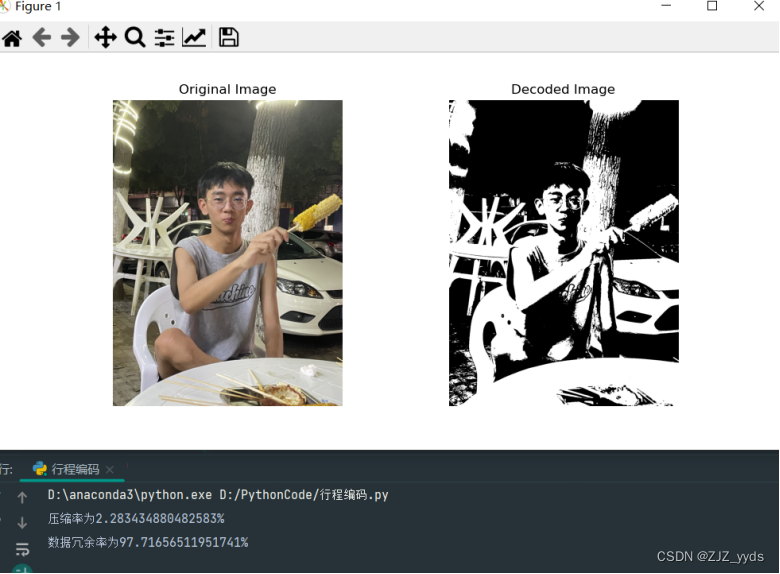















 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









