






在爬取百度翻译之前,我们首先要认识一下百度翻译

我们尝试着在里面输入我们要翻译的内容:

通过简单地观察可以发现,当我们输入你好后,url变成了 /#zh/en/你好
同时下方页面显示出了翻译后的结果,右边显示出了对应的英文单词,我们可以注意到除了上方和下方,别的页面都没有变化,这个和AJAX(阿贾克斯)请求的特点相符合
附上有关于AJAX请求的相关介绍

这里我们打开浏览器自带的抓包工具(按下F12)进行验证

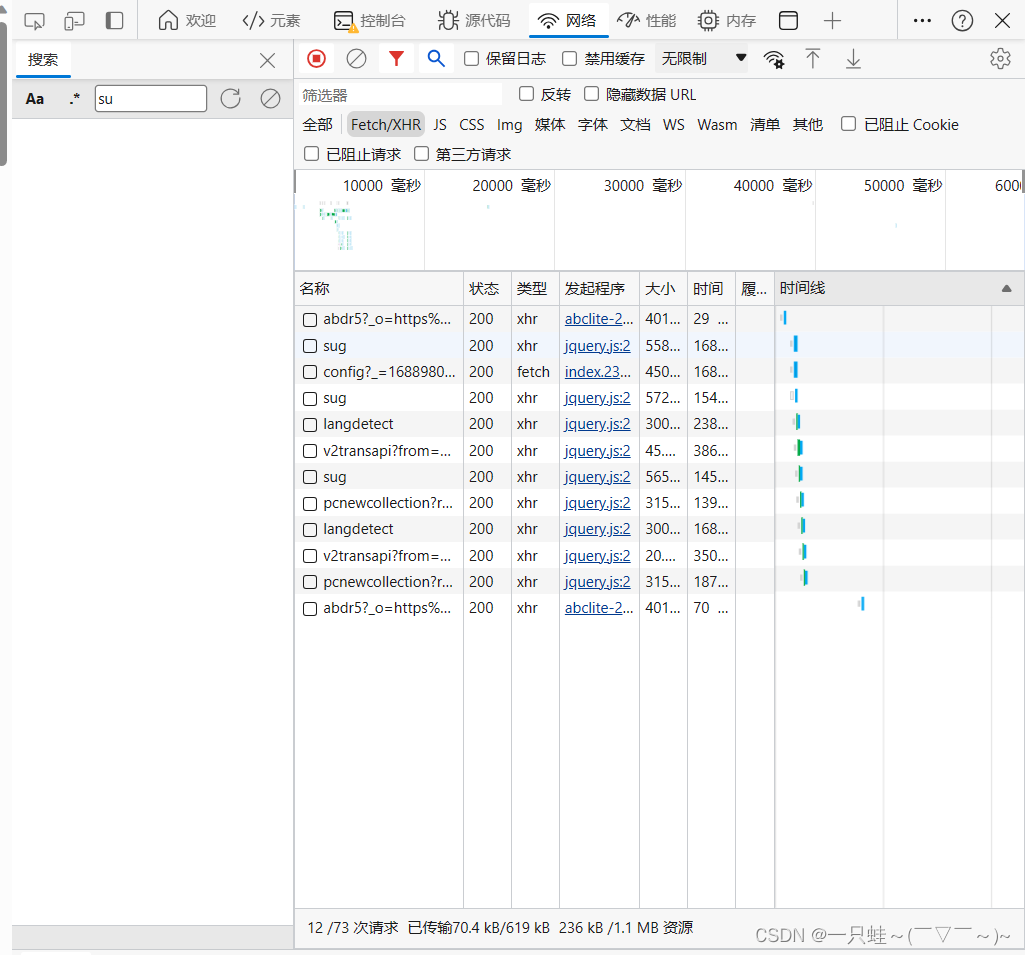
我们从网络的Fetch/XHR目录中找到的就是更新的文件。我们找到三个sug,分别查看它们的属性
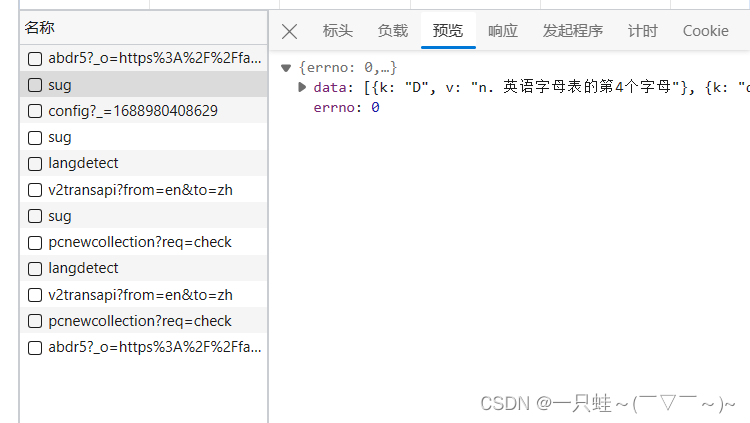
第一个sug预览中含有与d有关的翻译介绍
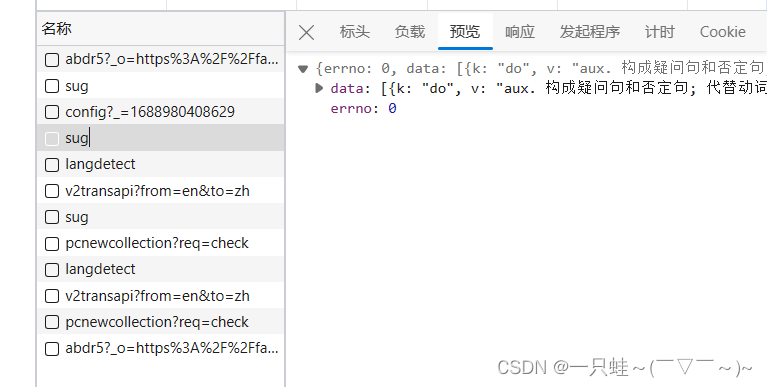
第二个sug含有与do有关的介绍
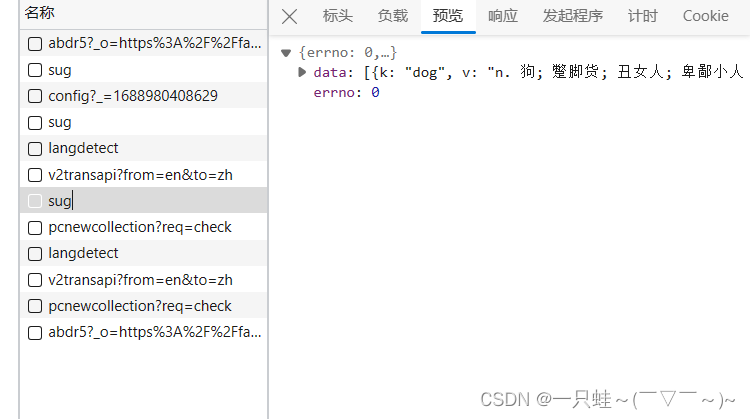
理所当然,第三个sug 内部就含有与dog翻译有关的内容啦
下面我们来看一看sug的属性
点开标头
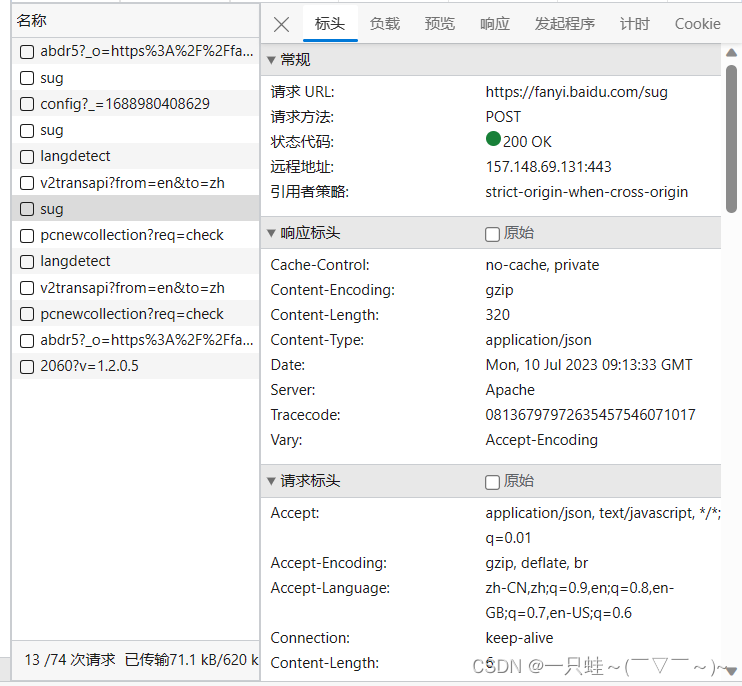
在常规这里我们可以找到sug对应的URL,这个就是我们后面要使用的。
在请求方法这个部分,我们可以看到是post,这个也是我们后面要注意的一个点

继续往下滑,我们可以看到我们浏览器上面的cookie,cookie可不是曲奇饼的意思,这个是我们保存在本地的简单文本文件,我们可以简单理解为我们在设备上的账号信息或者偏好设置
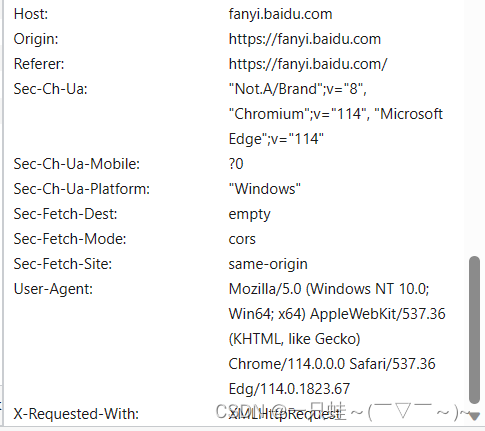
继续下滑,我们可以看到一个叫做User-Agent的东西,这个其实就是请求头,里面含有我们的客户端信息(你用的是什么设备,用的是啥浏览器)
对了,忘记了一个很重要的东西
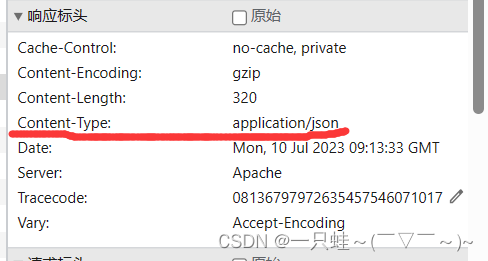
注意这里的类型是json,后面要用到,嗯,就是这样
然后我们跳到负载页面
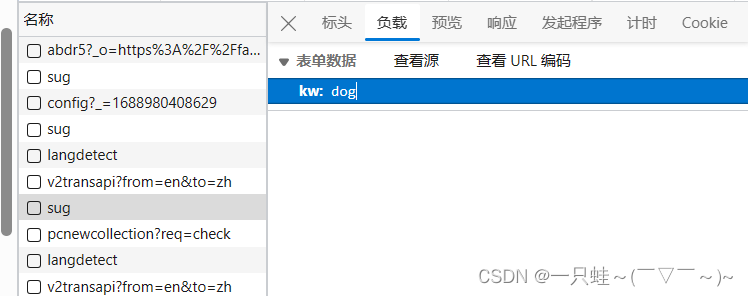
这里的kw实际上就是我们的属性啦
OK,简单地分析完后,我们就进入代码阶段

首先是我们需要的库,json库是自带的,requests库需要我们自己安装,安装的方式很简单,只需要在cmd终端内部输入 pip install requests即可( •̀ ω •́ )✧
 然后我们定义一个url,还记得吗,这就是我们上文中用F12找到的东西(●'◡'●)
然后我们定义一个url,还记得吗,这就是我们上文中用F12找到的东西(●'◡'●)

第二步就是进行UA伪装,如果我们不伪装的话,很多网站具有反爬虫机制,我们会被认定为爬虫,然后可能会请求访问失败(っ °Д °;)っ,这里我的UA就不展示了,大家可以通过方法找到自己的UA

第三步就是参数处理啦,同样利用负载中的小玩意儿,定义一个字典,ik是我们自己想要翻译的词

第四步就是请求啦,我们的请求方式记得使用POST,同样这也是我们之前解析出来的东西,
然后调用response中json方法来处理json,这里返回的是一个字典对象
最后一步,我们如果想要把结果保存到本地,我们可以这样做

这里我们要用utf-8进行解码,因为网络流是utf-8编码,而python的本地解释器是gbk编码,然后我们使用JSON模块中的dump方法传入参数。(●'◡'●)
注意力,由于我们是有中文的,中文不在ascii码 ,所以这里我们ensure_ascii码选择False
最后,我们就保存成功啦
PS:
写的代码只有20行,但是代码分析还是比较充足的,学习爬虫不易,我们即使使用了UA,也会由于用一个UA在短时间内多次访问而被识别为机器人(╬▔皿▔)╯,爬虫道路漫漫,希望各位看客们能给出好的建议,诚恳感谢















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









