






 文章探讨了如何利用机器学习改进参数化查询优化,特别是通过两篇VLDB和SIGMOD论文中的方法:《LeveragingQueryLogsandMachineLearningforParametricQueryOptimization》和《Kepler:RobustLearningforFasterParametricQueryOptimization》。文章详细介绍了PopulateCache和getPlan模块,以及如何通过预测和学习来优化查询计划选择过程,尽管存在训练数据收集成本和模型泛化的问题。
文章探讨了如何利用机器学习改进参数化查询优化,特别是通过两篇VLDB和SIGMOD论文中的方法:《LeveragingQueryLogsandMachineLearningforParametricQueryOptimization》和《Kepler:RobustLearningforFasterParametricQueryOptimization》。文章详细介绍了PopulateCache和getPlan模块,以及如何通过预测和学习来优化查询计划选择过程,尽管存在训练数据收集成本和模型泛化的问题。
一、背景介绍
参数化查询是指具有相同模板,且只有谓词绑定参数值不同的一类查询,它们被广泛应用在现代数据库应用程序中。它们存在反复执行动作,这为其性能优化提供了契机。
然而,当前许多商业数据库处理参数化查询的方法仅仅只优化查询中的第一条查询实例(或用户指定的实例),缓存其最佳计划并为后续的查询实例重用。该方法虽然优化时间至最小化,但由于不同查询实例的最佳计划不同,缓存计划的执行可能是任意次优的,这在实际应用场景中并不适用。
大多数传统优化方法需对查询优化器进行许多假设,但这些假设通常不符合实际应用场景。好在随着机器学习的兴起,上述问题可以得以有效解决。本期将围绕发表于 VLDB2022 和 SIGMOD2023 的两篇论文展开详细介绍:
论文 1:《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》
论文 2:《Kepler: Robust Learning for Faster Parametric Query Optimization》
二、论文 1 精华讲解
《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》此篇论文将参数化查询优化解耦为两个问题:
(1)PopulateCache:为一个查询模板缓存 K 个计划;
(2)getPlan:为每个查询实例,从缓存的计划中选择最佳计划。
该论文的算法架构如下图所示。主要分为两个模块:PopulateCache 和 getPlan module。
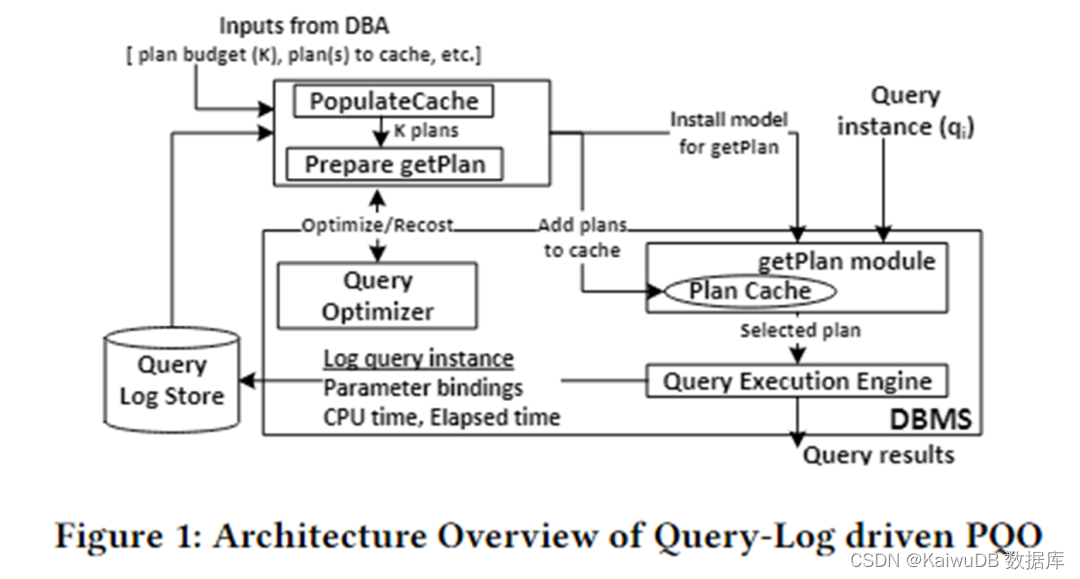
PopulateCache 利用查询日志中的信息,为所有查询实例缓存 K 个计划。getPlan module 首先通过与优化器交互收集 K 个计划与查询实例之间的 cost 信息,利用该信息训练机器学习模型。将训练好的模型部署于 DBMS 中。当一个查询实例到达时,可快速预测出该实例的最佳计划。
PopulateCache
PolulateCache 模块负责为给定的参数化查询识别一组缓存计划,搜索阶段利用两个优化器 API:
- Optimizer call:返回优化器为一个查询实例选择的计划;
- Recost call:为一个查询实例和对应计划返回优化器估计的 cost;
算法流程如下:
- Plan-collection phase:调用 optimizer call,为查询日志中 n 个查询实例收集候选计划;
- Plan-recost phase:为每个查询实例,每个候选计划,调用 recost call,形成 plan-recost matrix;
- K-set identification phase:采用贪心算法,利用 plan-recost matrix 缓存 K 个计划,最小化次优性。
getPlan
getPlan 模块负责为给定的查询实例,从缓存的 K 个计划中选择一个用于执行。getPlan 算法可以考虑两个目标:在 K 个缓存计划中,最小化优化器估计的 cost 或最小化实际执行的 cost。
考虑目标 1:利用 plan-recost matrix 训练监督 ML 模型,可考虑分类和回归。
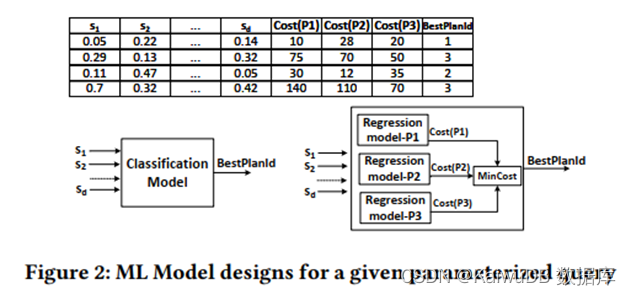
考虑目标 2:利用基于多臂赌博机( Multi-Armed Bandit )的强化学习训练模型。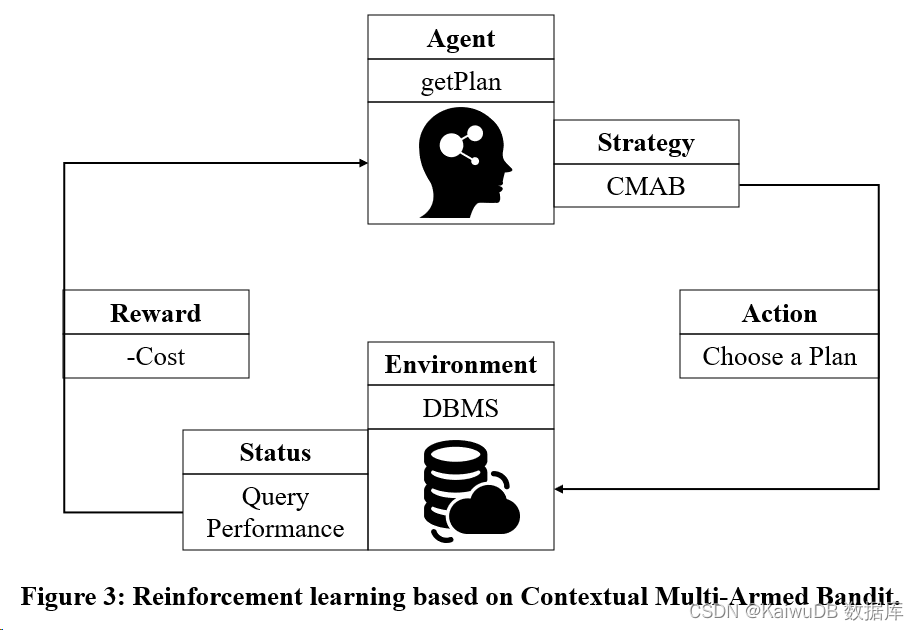
三、论文 2 精华讲解
《Kepler: Robust Learning for Faster Parametric Query Optimization》该论文提出一种端到端、基于学习的参数化查询优化方法,旨在减少查询优化时间的同时,提高查询的执行性能。
算法架构如下,Kepler 同样将问题解耦为两部分:plan generation 和 learning-based plan prediction。主要分为三个阶段:plan generation strategy、training query execution phase 和 robust neural network model。
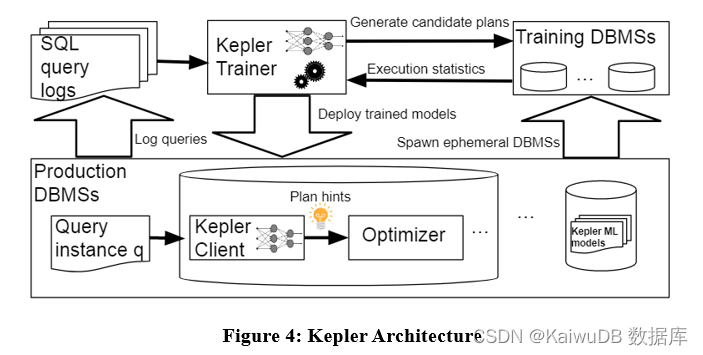
如上图所示,将查询日志中的查询实例输入给 Kepler Trainer,Kepler Trainer 首先生成候选计划,然后收集候选计划相关的执行信息,作为训练数据训练机器学习模型,训练好后将模型部署于 DBMS 中。当查询实例到来时,利用 Kepler Client 预测最佳计划并执行。
Row Count Evolution
本文提出一种名为 Row Count Evolution (RCE) 的候选计划生成算法,通过扰动优化器基数估计生成候选计划。
该算法的想法来源:基数的错误估计是优化器次优性的主要原因,并且候选计划生成阶段只需要包含一个实例的最优计划,而不是选出单一的最优计划。
RCE 算法首先为查询实例生成最优计划,而后在指数间隔范围内扰动其子计划的 join cardinality,重复多次并进行多次迭代,最终将生成的所有计划作为候选计划。具体实例如下:
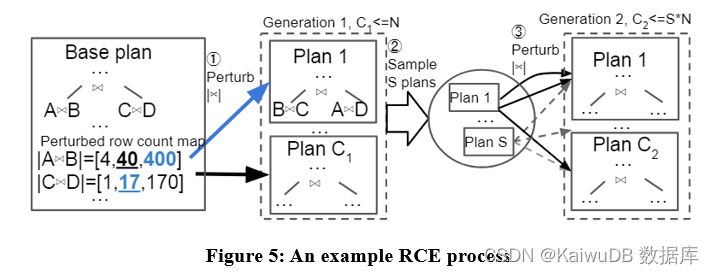
通过 RCE 算法,生成的候选计划可能优于优化器产生的计划。因为优化器可能存在基数估计错误,而 RCE 通过不断扰动基数估计,可产生正确基数对应的最佳计划。
Training Data Collection
得到候选计划集后,在 workload 上为每个查询实例执行每个计划,收集真实执行时间,用于有监督最佳计划预测模型的训练。上述过程较为繁琐,本文提出一些机制来加速训练数据的收集,如并行执行、自适应超时机制等。
Robust Best-Plan Prediction
利用得到的实际执行数据训练神经网络,为每个查询实例预测最佳计划。其中采用的神经网络为谱归一化高斯神经过程,该模型确保网络的稳定性和训练的收敛性的同时,可以为预测提供不确定性估计。当不确定性估计大于某个阈值时,交给优化器选择执行计划。一定程度上避免了性能的回归。
四、总结
上述两篇论文都将参数化查询解耦为 populateCache 和 getPlan 两部分。二者的对比如下表所示。

基于机器学习模型的算法虽然在计划预测方面表现良好,但其训练数据收集过程较为昂贵,且模型不易于泛化和更新。因此,现有参数化查询优化方法仍有一定的提升空间。
本文图示来源:
1)Kapil Vaidya & Anshuman Dutt, 《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》, 2022 VLDB,https://dl.acm.org/doi/pdf/10.14778/3494124.3494126
2)LYRIC DOSHI & VINCENT ZHUANG, 《Kepler: Robust Learning for Faster Parametric Query Optimization》, 2023 SIGMOD,https://dl.acm.org/doi/pdf/10.1145/3588963
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









