






# 背景
当前公司内部使用的虚拟机,主要为共享型实例。共享型实例在物理CPU上采用超卖机制,如超卖3倍到超卖5倍。共享型实例采用非绑定CPU调度模式,每个vCPU会被随机分配到任何空闲CPU超线程上,不同实例vCPU会争抢物理CPU资源,并导致高负载时计算性能波动不稳定,但是每台实例的成本相对来说较低。
随着企业内部对虚拟化性能的要求日益提高,共享型实例的这种不稳定性,已不能满足业务使用,企业级实例应运而生。与共享型实例相比,企业级实例采用固定CPU调度模式。每个vCPU绑定到一个物理CPU超线程,实例间无CPU资源争抢,实例计算性能保持稳定。
由于企业级实例在物理CPU不再进行超卖,分配给企业级实例使用的CPU价格必然比共享型实例要高。针对价格问题,当前企业级实例采用80核/768G内存/双口Mellanox-CX5网卡的HPC机型,极大程度提高虚拟机密度,一定程度对成本进行均衡控制。
# 企业级实例特点
企业级实例具有高性能、高隔离,高稳定的计算能力和平衡网络性能的特点。因为具有独享且稳定的计算、存储、网络资源,非常适合对业务稳定性具有高要求的企业场景。
# 企业级实例应用了哪些技术
在360的实际生产环境中,综合应用了下面这些技术来生产企业级实例,并已落地应用了通用型,计算型,内存型,本地SSD型共18种企业级实例。
应用NUMA拓扑和CPU亲和性绑定技术到虚拟机,虚拟机之间CPU隔离
采用固定CPU调度模式。每个vCPU绑定到一个物理CPU超线程,实例间无CPU资源争抢,实例计算性能稳定
应用宿主机进程绑核技术,宿主机进程占用分配的固定CPU,不占用虚拟机使用的CPU
分离共享型实例与企业级实例所使用的宿主机
开启网卡多队列
应用PCI Passthrough技术来挂载本地Nvme SSD磁盘
对不同规格虚拟机,应用不同网络限速规则
对不同Size云硬盘,应用不同云硬盘限速规则
# CPU绑核技术介绍
下面对企业级实例中最重要的CPU绑核技术进行介绍,通过两张图来给大家建立起一个直观的认识。物理机选用当前在生产环境使用的80核(2socket*20core*2开启超线程), 768G内存,双口Mellanox-CX5网卡的HPC机型。
首先来看共享型实例的vCPU使用情况,在虚机实际使用过程中,共享型实例的每个vCPU会在所有物理CPU超线程上浮动,共享型实例之间会一起争抢这80个核。而企业级实例的每个vCPU绑定到一个固定的物理CPU超线程上,同时我们将运行Openstack管理服务的docker进程,如nova-compute,neutron-openvswitch-agent,neutron-l3-agent等固定在了物理CPU超线程的0,1,40,41核上,在企业级实例调度时刨除这4个核,保证宿主机进程不去争抢虚机资源。
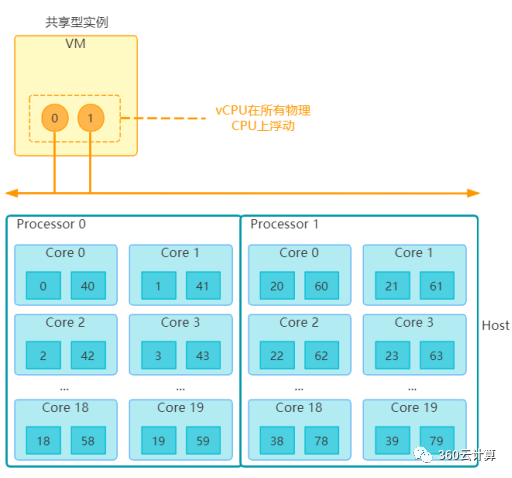
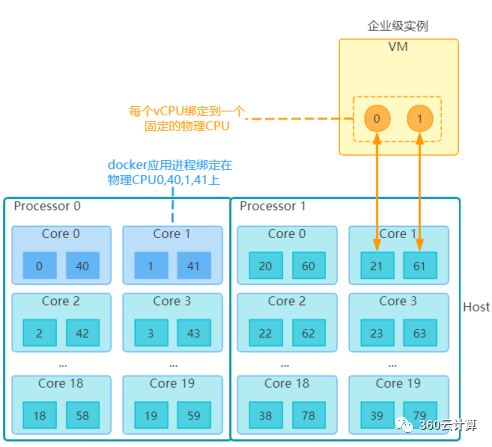
# 虚拟机实例XML对比
通过virsh dumpxml命令获取创建出来的共享型实例和企业级实例的XML文件,可以明显看到企业级实例通过vcpupin和emulatorpin将VCPU固定到指定的物理CPU上,并且内存分配采用strict模式,表示不允许内存跨NUMA分配。对于32核及以下的套餐,我们采用单Numa分配方式,对于48核的套餐,一个Numa已经不能满足,因此会从两个Numa分别分配24个物理机CPU。
01
共享型实例
<memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <vcpu placement='static'>8</vcpu> <cputune> <shares>8192</shares> </cputune> <cpu mode='host-passthrough' check='none'> <topology sockets='8' cores='1' threads='1'/> </cpu> |
02
企业级实例
<memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <vcpu placement='static'>8</vcpu> <cputune> <shares>8192</shares> <vcpupin vcpu='0' cpuset='18'/> <vcpupin vcpu='1' cpuset='58'/> <vcpupin vcpu='2' cpuset='52'/> <vcpupin vcpu='3' cpuset='12'/> <vcpupin vcpu='4' cpuset='8'/> <vcpupin vcpu='5' cpuset='48'/> <vcpupin vcpu='6' cpuset='13'/> <vcpupin vcpu='7' cpuset='53'/> <emulatorpin cpuset='8,12-13,18,48,52-53,58'/> </cputune> <numatune> <memory mode='strict' nodeset='0'/> <memnode cellid='0' mode='strict' nodeset='0'/> </numatune> <cpu mode='host-passthrough' check='none'> <topology sockets='1' cores='4' threads='2'/> <numa> <cell id='0' cpus='0-7' memory='16777216' unit='KiB'/> </numa> </cpu> |
# CPU和内存性能压测对比
为对比共享型实例和企业级实例的性能,我们选用了sysbench和stream这两款工具。主要目的是验证企业级实例对比共享型实例在隔离性,稳定性,性能方面的优势。
# 压测工具说明
01
sysbench
sysbench是一款开源的多线程性能测试工具,可以执行CPU、内存、线程、IO、数据库等方面的性能测试。sysbench的CPU测试是在指定时间内,循环进行素数计算。
# sysbench cpu --cpu-max-prime=20000 --threads=8 --time=30 run
素数上限20000个,时间30秒,8线程
输出结果:
events per second:所有线程每秒完成了几轮的素数计算
Avg(ms):所有event的平均耗时
02
STREAM
STREAM是业界广为流行的综合性内存带宽实际性能测量工具之一。STREAM支持Copy 、Scale 、 Add、 Triad四种操作。
Copy操作最为简单,它先访问一个内存单元读出其中的值,再将值写入到另一个内存单元。
Scale操作先从内存单元读出其中的值,作一个乘法运算,再将结果写入到另一个内存单元。
Add操作先从内存单元读出两个值,做加法运算, 再将结果写入到另一个内存单元
Triad的中文含义是将三个组合起来,在本测试中表示的意思是将Copy、Scale、Add三种操作组合起来进行测试。具体操作方式是:先从内存单元中中读两个值a、b,对其进行乘加混合运算(a + 因子 * b ) ,将运算结果写入到另一个内存单元。
# 测试环境
物理机两台,配置均是80核 768g 双口25G网卡。
物理机A上创建9台 8核16g的企业级实例。这里因为已经隔离了4个核给宿主机进程使用,因此只能创建出9台企业级实例,使用72个核。
物理机B上配置CPU 3倍超卖,创建29台8核16g的共享型实例。
# 测试数据
01
测试场景1-单台实例对比
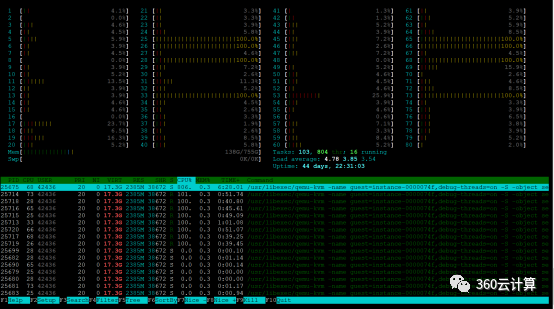
单台企业级实例执行sysbench,看宿主机htop,可以看到8个物理CPU是处于使用率100%的情况,其他物理机CPU不受干扰
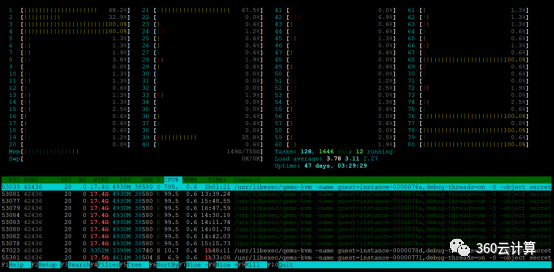
单台共享型实例执行sysbench,看宿主机htop,8个核来回调度,100%使用率不是固定的
分别对物理机,单台企业级实例,单台共享型实例在无压力的情况下进行sysbench压测
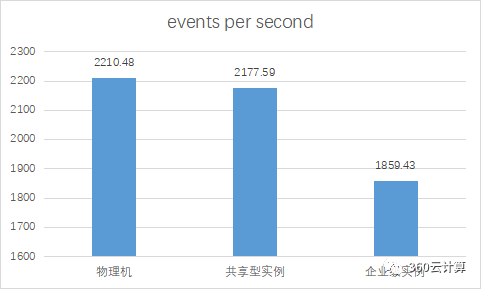
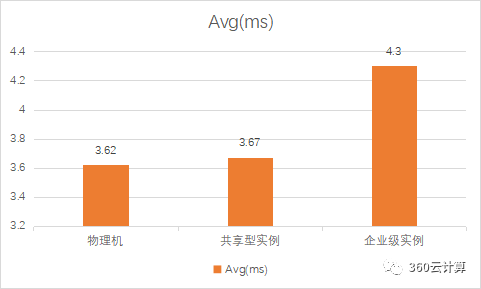
分析:
在物理机空闲时,共享型实例由于可以在所有CPU上浮动,此时性能会比绑定了固定CPU的企业级实例还更好些
共享型相比物理机来说,CPU性能损耗在1.5%左右
企业级相比物理机来说,CPU性能损耗在16%左右
对单台物理机,单台企业级实例,单台共享型实例在无压力的情况下进行stream压测
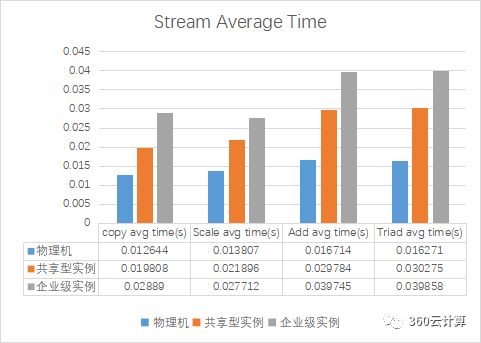
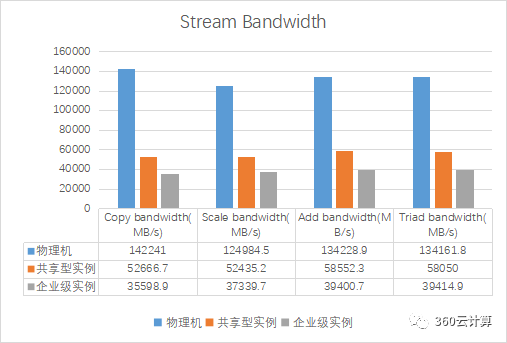
分析:
在物理机空闲时,共享型实例由于可以在所有CPU上浮动,此时性能会比绑定了固定CPU的企业级实例还更好些
共享型和企业级相比物理机来说,内存带宽仅能达到37%和25%,性能相差太大,需要分析
02
测试场景2-企业级VS共享型不超卖
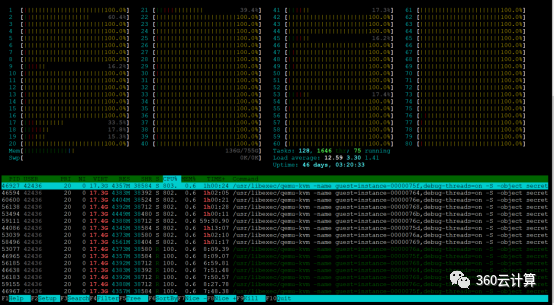
9台企业级实例同时执行sysbench,看宿主机htop,可以看到72个物理CPU是处于使用率100%的情况,另外8个物理机CPU不受干扰
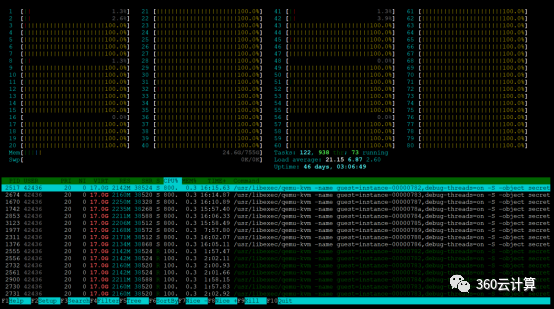
9台共享型实例同时执行sysbench,看宿主机htop,大部分CPU也都处于100%使用率的情况了
对9台企业级实例,9台共享型实例同时进行sysbench压测分析
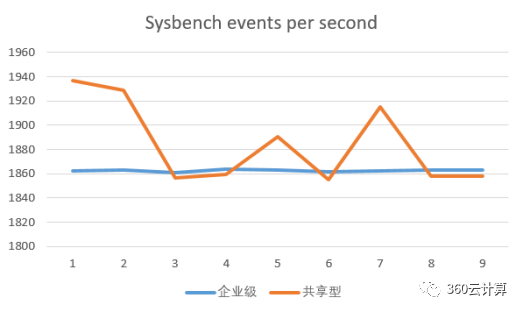
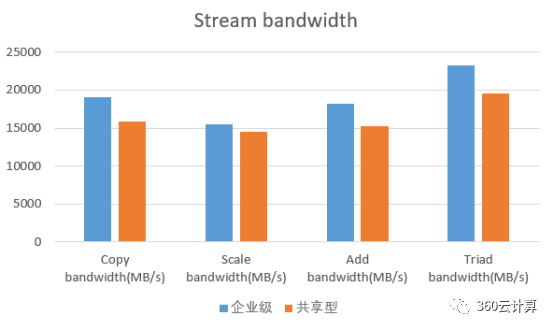
分析:
物理机压力打满的情况下,企业级的CPU算力非常稳定,而共享型有波动
内存带宽方面,企业级实例相比于共享型实例提升20%
03
测试场景3-企业级VS共享型3倍超卖
29台共享型实例同时执行sysbench,与9台企业级,和共享型不超卖的9台,进行横向对比分析
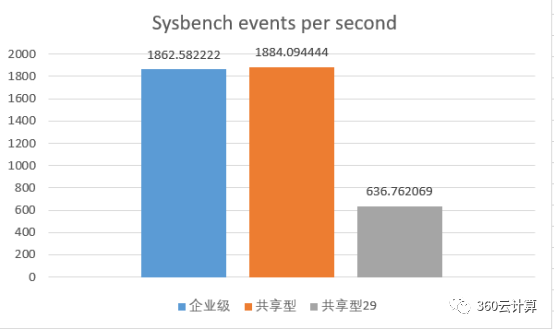
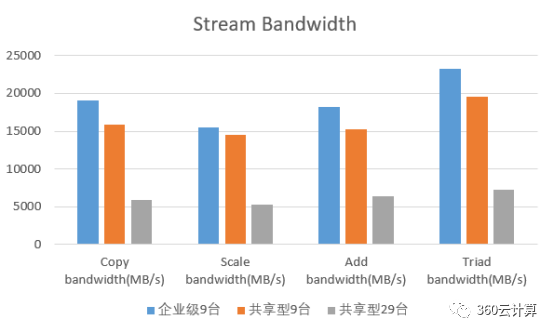
分析:
企业级VS共享型3倍超卖情况下,企业级的CPU算力和内存带宽基本是共享型的3倍。
# Emulator thread问题
当前企业级实例已开启网卡多队列。网卡多队列驱动将各个队列通过中断绑定到不同的核上,来解决网络I/O带宽升高时,单核CPU的处理瓶颈,以提升网络PPS和带宽性能。
在相同的网络PPS和网络带宽的条件下,与1个队列相比,2个队列最多可提升性能达50%到100%,4个队列的性能提升更大。
在实际使用中,企业级实例的VCPU thread和emulator thread由于都固定到了相同的物理CPU上,两者间有资源争抢,当某个报文到达打满的CPU时,会表现出延迟高的现象;对于共享型的实例,由于能调度宿主机的所有物理CPU,在物理机空闲情况下,反而在Ping延迟方面占优。
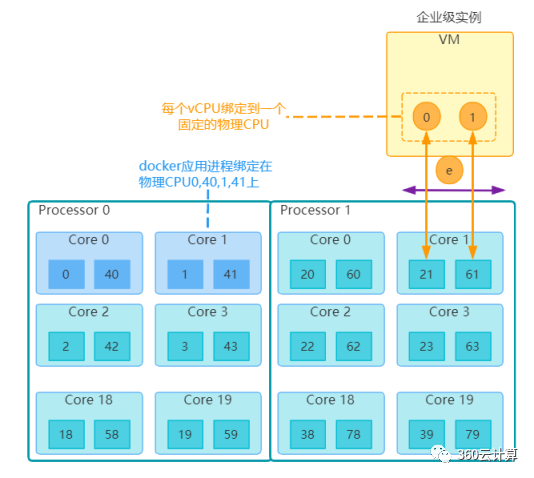
如果想要企业级实例获取更高的网络性能,可通过将emulator thread绑定到与VCPU thread 不一样的物理CPU上,但与此同时,那么就需要考虑CPU资源开销问题。
# 未来探索
对企业级实例的高隔离,高稳定的这种特性,非常适合与在离线业务结合使用,将在离线业务部署为企业级实例,通过混合部署,借助离线业务的高计算使用量,在不影响在线业务使用的同时,拉高业务整体资源水位,快速地提升物理资源利用率,降低总体成本。
随着企业级实例的全面覆盖,相信可以给企业带来更高的资源利用率。















 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









