






这几天正在做数据库国产化的相关工作,之前的一个项目数据库用的是oracle的,现在要换成达梦的。所以我就把遇到的,需要修改的列出来,本篇文章持续更新中。
目录
5 oracle有自动收集统计信息的定时任务,而达梦需要自己去弄个定时任务
1 达梦数据库中会出现多余的0占位
无论是oracle还是达梦数据库,都有number类型,格式都为number(m,n)。两个数据库中有相同的表,由于业务需求,我不能将原表的相关表的表结构晒出,现将测试表的结构展示如下:
CREATE TABLE CESHI (
ID VARCHAR2(50) DEFAULT SYS_GUID() NOT NULL,
NAME VARCHAR2(50) NULL,
ADDRESS VARCHAR2(50) NULL,
COLUMN1 VARCHAR2(70) NULL,
TOTAL NUMBER(15,3) NULL,
CONSTRAINT CESHI_PK PRIMARY KEY (ID)
);
达梦数据库的数据如下:
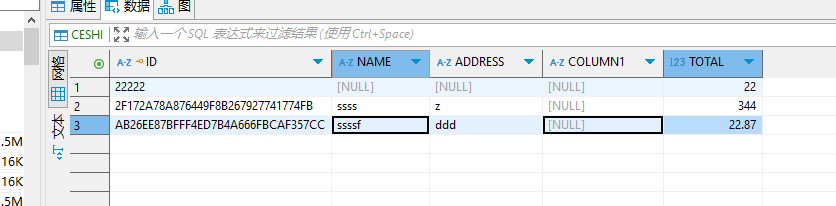
oracle数据库如下:
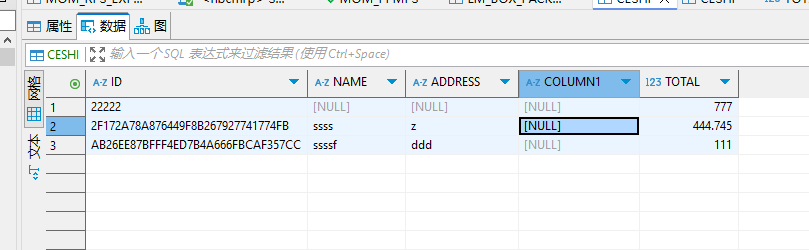
java端用的是springboot加mybatis,代码如下:
package boke.hbc.dingshiqi.ceshi;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
@RequestMapping("/ceshi")
@RestController
public class CeshiController {
@Autowired
private CeshiService service;
@RequestMapping(value = "/dmandorcl")
public JSONObject dmandorcl() {
List<Map> list1=service.dmandorcl();
for(Map map1:list1) {
System.out.println(map1.toString());
}
JSONObject resultjson=new JSONObject();
resultjson.put("code", 0);
return resultjson;
}
}
service:
package boke.hbc.dingshiqi.ceshi;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.alibaba.fastjson.JSONObject;
@Service
public class CeshiService {
@Autowired
CeshiMapper mapper;
public List<Map> dmandorcl() {
// TODO Auto-generated method stub
return mapper.dmandorcl();
}
}
mapper
package boke.hbc.dingshiqi.ceshi;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
@Mapper
public interface CeshiMapper {
@Select("select * from ceshi")
List<Map> dmandorcl();
}
在oracle数据库的情况下,控制台显示如下:
{TOTAL=777, ADDRESS=null, ID=22222, COLUMN1=null, NAME=null}
{TOTAL=444.745, ADDRESS=z, ID=2F172A78A876449F8B267927741774FB, COLUMN1=null, NAME=ssss}
{TOTAL=111, ADDRESS=ddd, ID=AB26EE87BFFF4ED7B4A666FBCAF357CC, COLUMN1=null, NAME=ssssf}
在dameng数据库环境下,控制台显示如下:
{TOTAL=22.000, ADDRESS=null, ID=22222, COLUMN1=null, NAME=null}
{TOTAL=344.000, ADDRESS=z, ID=2F172A78A876449F8B267927741774FB, COLUMN1=null, NAME=ssss}
{TOTAL=22.870, ADDRESS=ddd, ID=AB26EE87BFFF4ED7B4A666FBCAF357CC, COLUMN1=null, NAME=ssssf}
这种小数点后三个0的情况输入到前端页面显然是不合适的,所以我做了个拦截器,代码如下:
package com.bocomsoft.util;
import java.math.BigDecimal;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import org.apache.ibatis.type.MappedTypes;
@MappedJdbcTypes({JdbcType.NUMERIC,JdbcType.DECIMAL})
@MappedTypes(BigDecimal.class)
public class BigDecimalTypeHandler extends BaseTypeHandler<String> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType)
throws SQLException {
// TODO Auto-generated method stub
System.out.println("i="+i+"@parameter="+parameter+"@jdbcType="+jdbcType.toString());
ps.setString(i, parameter);
}
@Override
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
// TODO Auto-generated method stub
//System.out.println("哈哈1="+columnName);
BigDecimal val = rs.getBigDecimal(columnName);
if(val!=null) {
String val2=val.toPlainString();
if (val2.indexOf(".") > 0) {
// 去掉多余的0
val2 = val2.replaceAll("0+?$", "");
// 如果最后一位是. 则去掉
val2 = val2.replaceAll("[.]$", "");
}
return val2;
}else {
return "";
}
}
@Override
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
// TODO Auto-generated method stub
//System.out.println("哈哈2");
BigDecimal val = rs.getBigDecimal(columnIndex);
if(val!=null) {
String val2=val.toPlainString();
if (val2.indexOf(".") > 0) {
// 去掉多余的0
val2 = val2.replaceAll("0+?$", "");
// 如果最后一位是. 则去掉
val2 = val2.replaceAll("[.]$", "");
}
return val2;
}else {
return "";
}
}
@Override
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
// TODO Auto-generated method stub
//System.out.println("哈哈3");
BigDecimal val = cs.getBigDecimal(columnIndex);
if(val!=null) {
String val2=val.toPlainString();
if (val2.indexOf(".") > 0) {
// 去掉多余的0
val2 = val2.replaceAll("0+?$", "");
// 如果最后一位是. 则去掉
val2 = val2.replaceAll("[.]$", "");
}
return val2;
}else {
return "";
}
}
}
这样输出的结果就不带有多余的0了
2 order by 排序的时候会把null空值排前面
在oracle中,select语句如果涉及到排序,默认的情况是把排序字段中为null的值排后,而达梦数据库正好相反,还是看那个ceshi表,两个数据库执行同样的sql语句:SELECT * FROM ceshi t ORDER BY t.ADDRESS,oracle的执行结果如下所示:
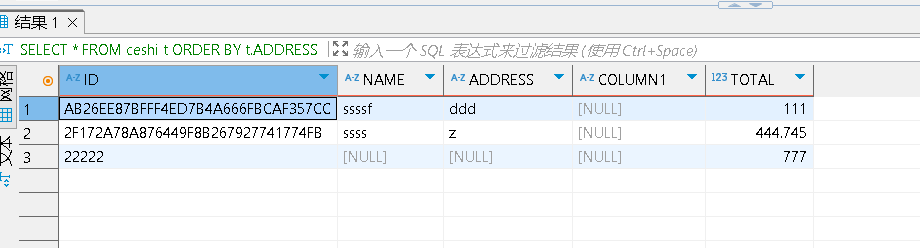
而达梦数据库则变成这个样子了:
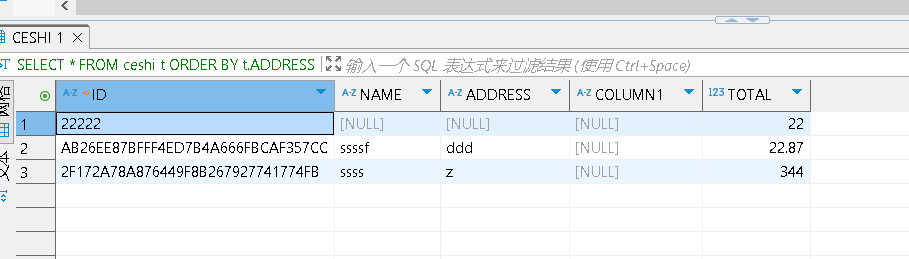
如果要做数据库适配的话一定要注意。
3 is null,is not null与空字符不兼容
在oracle中,如果一个字段的值是空字符得话,他与null是等价的,我们可以用is null或is not null进行判断,但是达梦有可能是不一样,空字符和null不是等价的。主要与数据库设置有关,这个参数叫COMPATIBLE_MODE,具体参考链接如下所示:达梦数据库非空约束错误解决,明明插入空字符串,但还是触发非空约束_达梦数据库违反列非空约束-CSDN博客
4 达梦数据库查询语句严格区分字符串尾部空格问题
在oracle数据库中,是严格区分'a'和'a '的,但是在达梦数据库中是有可能不区分的,可数据库的BLANK_PAD_MODE参数,当BLANK_PAD_MODE=0时,除去group by 这种分组操作时严格区分外,其他比较、count等操作不严格区分'a'和'a ',认为这两个字符串是相等的。而且比较坑的是数据库实例已经建立的情况下,他是不能改的,除非重装数据库((╯‵□′)╯︵┴─┴ 掀桌),补救的措施是修改SPACE_COMPARE_MODE参数,然后重启服务器,右空格可以这么解决,左空格自求多福吧,我当时找的参考链接如下:
达梦数据库查询语句严格区分字符串尾部空格问题_达梦数据库空格填充模式-CSDN博客
5 oracle有自动收集统计信息的定时任务,而达梦需要自己去弄个定时任务
这个问题我当时是这么发现的,当时我们达梦上的测试库和正式库的数据量差不多,然后我就发现正式库查询特别慢,我就问达梦数据库的售后咋回事,他调了半天,说oracle默认的情况下有自动收集统计信息的定时任务,当高于一个阈值的时候,他会自动进行收集统计信息。达梦需要自己弄(后来我在网上看到说达梦也可以进行设定,但是我没时间,以后去验证一下吧),他就用sysdba用户加了个定时任务,里面执行的sql脚本为:CALL DBMS_STATS.GATHER_SCHEMA_STATS('大写的用户名',100,TRUE,'FOR ALL COLUMNS SIZE AUTO'),每两天执行一次,参考链接如下:
达梦数据库如何收集统计信息?_达梦收集统计信息-CSDN博客
6 oracle和达梦date数据类型区别
oracle和达梦都有date数据类型,但oracle是精确到秒,达梦只能精确到天,默认值都可以用sysdate,所以,如果达梦想要精确到秒,数据类型应该使用TIMESTAMP

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









