







前言
Seaborn是基于Matplotlab开发的python数据可视化库,它提供了一个高级界面,用于绘制引人入胜且内容丰富的统计图形。
Seaborn在matplotlab上进行了更高级的API封装,从而使作图更加容易。
Seaborn针对统计绘图,能够满足数据分析的90%以上的绘图需求,他和Matplotlab的区别在于:Matplotlab很多参数需要自己配置,而且很多细节功能需要单独写代码来完成;而Seaborn就是点套餐,他把常用到的可视化绘图过程进行了函数封装,形成了一个“快捷方式”,代码更简洁。
导入库
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
单变量分布分析
先来学习Seaborn的分布分析图,首先是单变量分析:
import seaborn as sns
import numpy as np
sns.set_style('ticks') # 设置主题风格:darkgrid,whitegrid,dark,white,ticks
x=np.random.normal(size=100)
sns.distplot(x,bins=20)
-
设置Seaborn的主题风格:darkgrid,whitegrid,dark,white,ticks 共五种风格;
sns.set_style('ticks') # 设置主题风格:darkgrid,whitegrid,dark,white,ticks -
使用np.random.normal生成100个正态分布的随机数;
x=np.random.normal(size=100) -
bins=20表示将x的范围平均切分成20个小方柱。
sns.distplot(x,bins=20)

图上蓝色的弧线是KDE,即核密度估计,它可以看出数据整体分布状况。
核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。
仅用直方图来表示数据分布简单易懂,但都存在以下问题:
- 密度函数不平滑,区间越大时,锯齿现象越严重
- 只能显示出两个变量的关系
- 子区间的宽度对最后的概率密度影响较大
而核密度估计是给定空间的每个离散点的核函数加起来,得到了整体的概率密度分布,也就是给离散点套上了一个连续的分布,和直方图密度估计相比,没有锯齿看上去更加的连续、光滑和柔顺;
核密度估计用在很多机器学习算法中,比如支持向量机、k近邻、k平均等,本例默认使用高斯核函数。
双变量分布分析
散点图
观测两个变量之间的分布关系最好使用散点图。
import seaborn as sns
import numpy as np
import pandas as pd
mean,cov=[0,1],[(1,.5),(.5,1)]
data=np.random.multivariate_normal(mean,cov,300)
df=pd.DataFrame(data,columns=['x','y'])
sns.jointplot(x='x',y='y',data=df)
-
首先生成300组数据,mean是均值,0 1分别表示x和y的均值,cov表示协方差矩阵,即x和y的协方差矩阵为 [ 1 0.5 0.5 1 ] \begin{bmatrix}1&0.5\\0.5&1\end{bmatrix} [10.50.51];
-
使用np.random方法生成了给定的均值和协方差的300组x和y的数值,这里使用pandas的dateframe来保存数据,你可以把它想象成一个excel的二维数据表;
mean,cov=[0,1],[(1,.5),(.5,1)] data=np.random.multivariate_normal(mean,cov,300)协方差:表示变量间的相互关系。
变量间的相互关系一般有三种:正相关、负相关和不相关。- 正相关:假设有两个变量 x和y,若x越大y越大;x越小y越小,则x和y为正相关。
- 负相关:假设有两个变量 x和y,x越大y越小;x越小而y越大,则x和y为负相关。
- 不相关:假设有两个变量 x和y,若x和y的变化无关联,则x和y不相关。
它使用以下公式来完成计算: c o v ( X , Y ) = ∑ i = 1 n ( X i − X ˉ ) ( Y i − Y ˉ ) n − 1 \mathrm{cov}(\mathrm{X},\mathrm{Y})=\frac{\sum_{i=1}^n(X_i-\bar{X})(Y_i-\bar{Y})}{n-1} cov(X,Y)=n−1∑i=1n(Xi−Xˉ)(Yi−Yˉ)其中 X ˉ \bar{X} Xˉ和 Y ˉ \bar{Y} Yˉ是X和Y的平均值。
-
colums给每个数据加上字段名标识;
df=pd.DataFrame(data,columns=['x','y']) -
seaborn的jointplot能够绘制出两列数据关联关系的散点图,第一个维度是x,第二个维度是y,即横轴是x,纵轴是y,中间的散点表示每一对x和y的坐标点,上面是单变量x的密度直方图,右边是单变量y的密度直方图。
sns.jointplot(x='x',y='y',data=df)
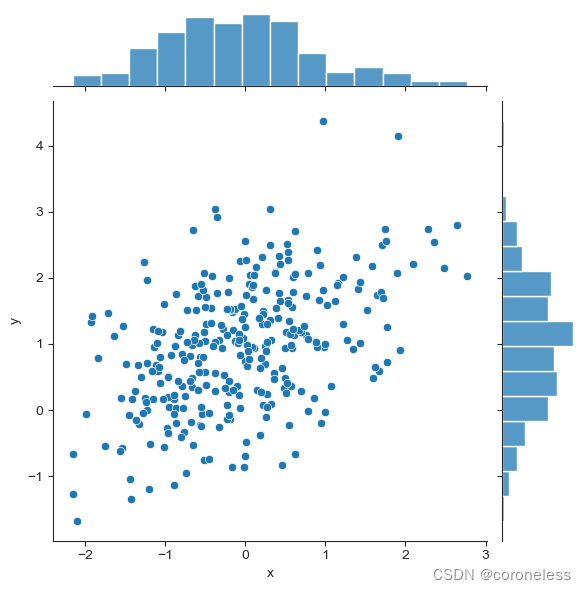
散点图可以很容易看出二者的关系,但是随着数据量的增加图中的点会越来越密集;
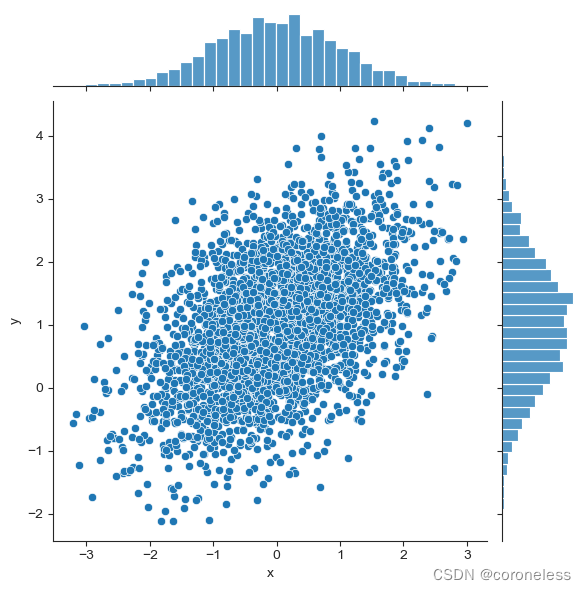
这是3000组数据的散点图,已经无法分辨出哪个部位的数据落下的多,哪个部位数据落下的少。
六边蜂窝图
散点图可以很容易看出两个特征值的关系,但随着数据量的增加到3000个时就完全看不清楚了,可以试着换成六边蜂窝图:
import seaborn as sns
import numpy as np
import pandas as pd
mean,cov=[0,1],[(1,.5),(.5,1)]
data=np.random.multivariate_normal(mean,cov,2000)
df=pd.DataFrame(data,columns=['x','y'])
sns.jointplot(x='x',y='y',kind='hex',data=df,color='k')
- 添加kind=‘hex’,color='k’设置color为黑色。
sns.jointplot(x='x',y='y',kind='hex',data=df,color='k')

现在的图看上去明晰许多,颜色越深的六边形蜂窝说明落在该区域的点越多。
多变量分布分析
接下来是多变量分析,我们将使用鸢尾花数据来完成。
鸳尾花数据集是一个经典的数据集,在统计学习和机器学习的领域经常被用作示例,数据集内包含有3类鸳尾花;
我们使用这样的命令就可以查看到鸳尾花的种类:
import pandas as pd
df= pd.read_csv('iris.csv')
df['Species'].unique()
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)
数据集共150条记录,每类各50条记录,每条记录都有四个特征,花萼长度,花萼宽度,花瓣长度,花瓣宽度,可以通过这四个特征来预测鸳尾花属于这三类中的哪一个品种。
df
| SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
150 rows × 5 columns
表达变量两两之间的关系使用pairplot最为合适,其中pair是成对的意思,变量两两之间的关系为线性、非线性或有无较明显的相关关系。
import pandas as pd
import seaborn as sns
df=pd.read_csv('iris.csv',usecols=[0,1,2,3,4])
sns.pairplot(df,hue='Species',height=3)
-
使用pandas的read_csv来读入鸢尾花数据,usecols是共有五列;
df=pd.read_csv('iris.csv',usecols=[0,1,2,3,4]) -
hue是按照species即类型分类;
sns.pairplot(df,hue='Species',height=3)
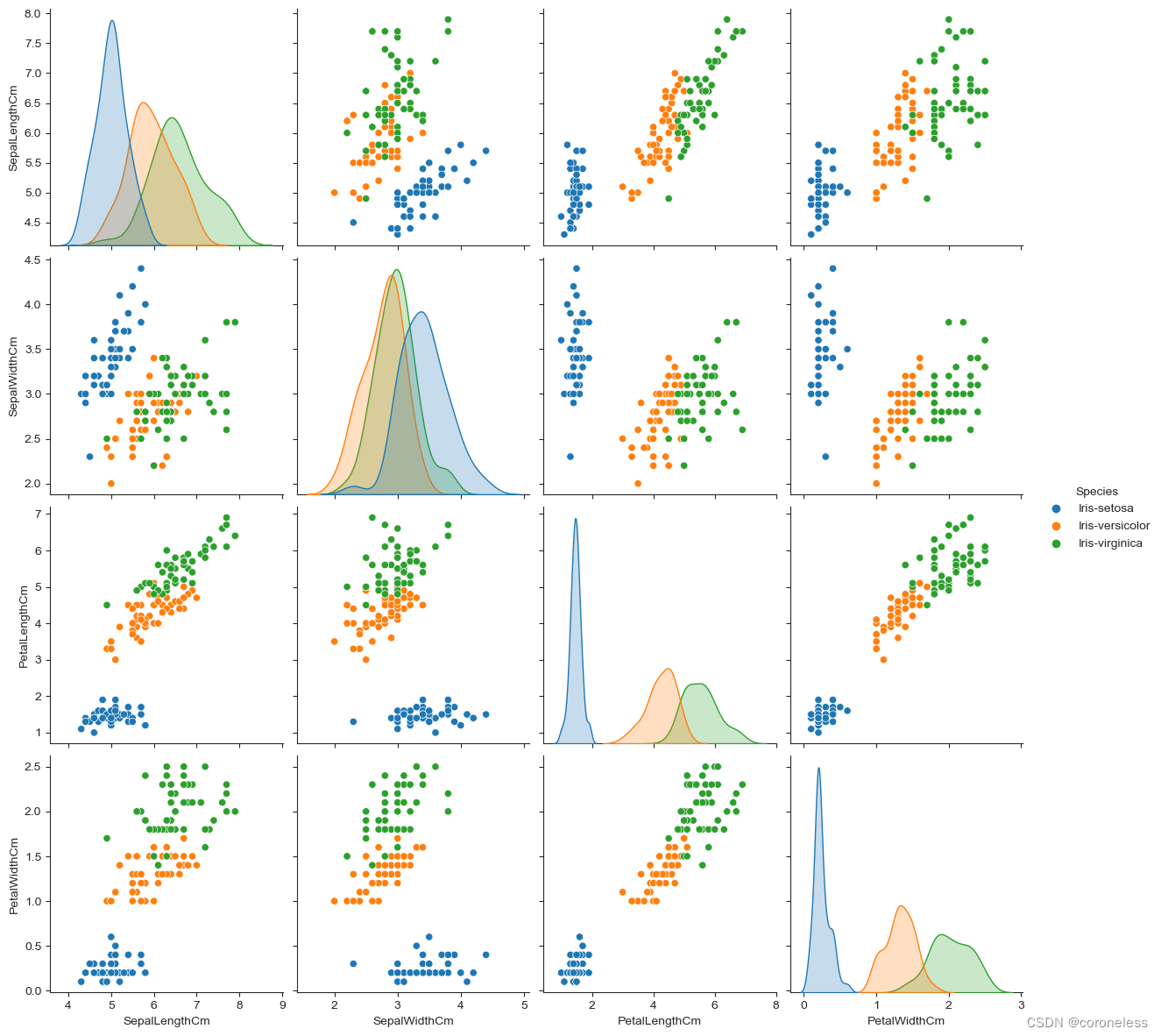
大家可以看到有三种颜色,分别表示三类鸢尾花;
x轴有花萼长度,花萼宽度,花瓣长度,花瓣宽度四个特征值,y轴同样也是这四个特征值;
对角线是每个特征值自己和自己的关系,即核密度函数图,而其他位置是每个特征和其他三个特征之间的散点图,并且以主对角线为对称轴对称分布。
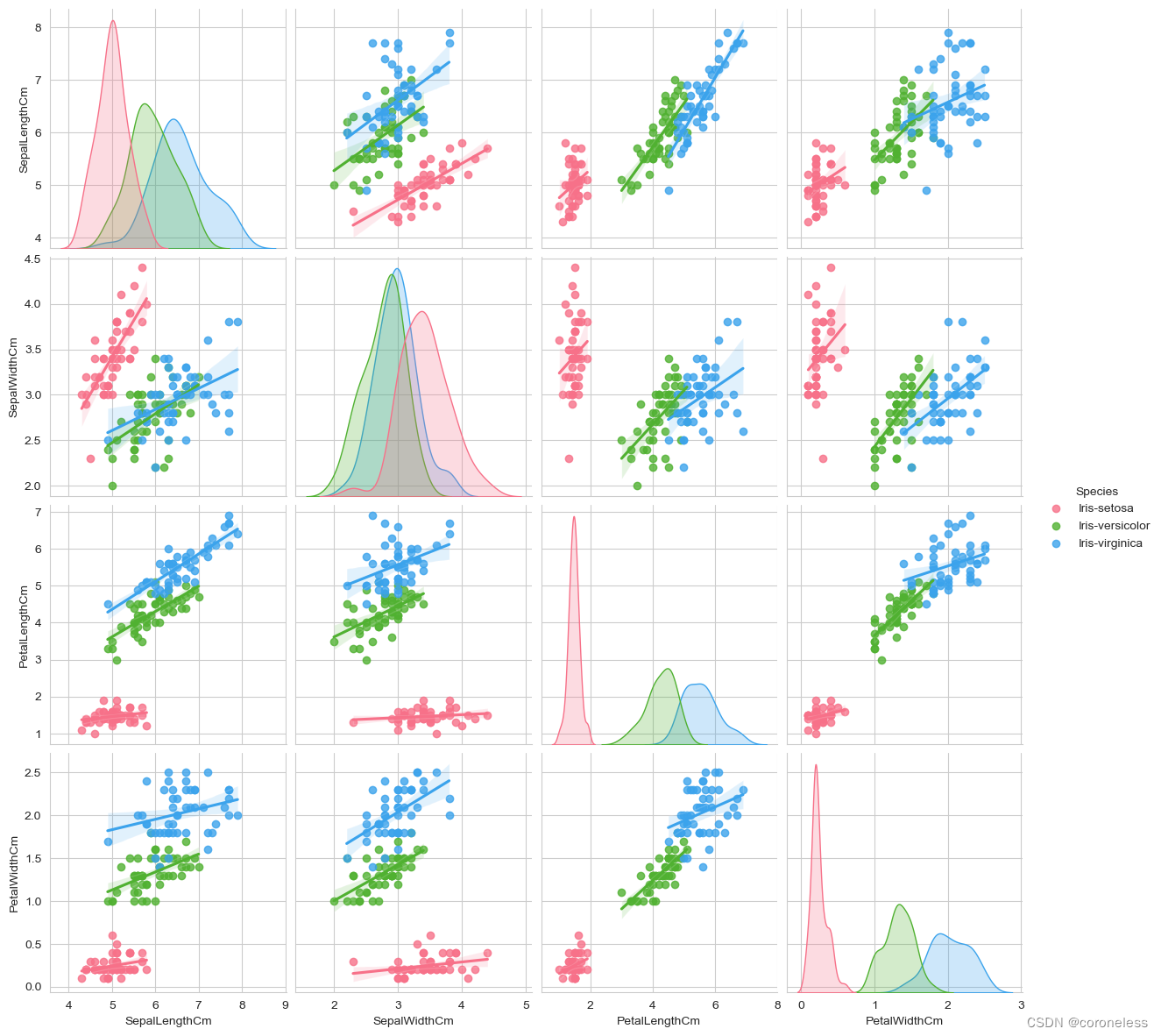
再加上三个参数:
-
diag_kind控制对角线上图的类型,可选择‘hist’和’kde’, hist是直方图,kde是核密度函数图,默认为’kde’;
-
kind用于控制非对角线上的图的类型,可选’scatter’与’reg’,默认为’scatter’散点图;reg属于回归分析,它为非对角线上的散点图拟合出的一条回归直线,更直观的显示出变量之间的关系;
-
使用palette选择调色板色系;
sns.pairplot(df,hue='Species',height=3,diag_kind='kde',kind='reg',palette='husl')
回归分析
如果只想看某两个变量之间的回归关系,我们也可以直接选择regplot:
import pandas as pd
import seaborn as sns
sns.set_style('whitegrid') # 设置主题
df=pd.read_csv('iris.csv',usecols=[0,1,2,3,4])
sns.regplot(x='SepalLengthCm',y='PetalWidthCm',data=df,color='pink',marker='+')
-
前三个参数是必须的,分别表示x轴和y轴的数据字段,还有data数据集,颜色和标记可以自行添加,marker选择了加号点。
sns.regplot(x='SepalLengthCm',y='PetalWidthCm',data=df,color='pink',marker='+')
现在可以看到一条拟合直线和花萼长度、花瓣宽度大致的分布状况。

核密度分析
我们可以绘制出两个特征值的核密度图:
import pandas as pd
import seaborn as sns
sns.set_style('whitegrid') # 设置主题
df = pd.read_csv('iris.csv',usecols=[0,1,2,3,4])
# 取出所有的setosa类的花的数据
setosa=df.loc[df.Species=='Iris-setosa']
# 取出所有的versicolor类的花的数据
versicolor=df.loc[df.Species=='Iris-versicolor']
# 取出所有的virginca类的花的数据
virginica=df.loc[df.Species=='Iris-virginica']
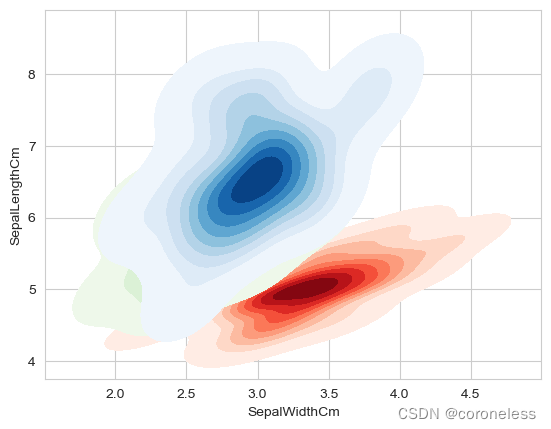
# 绘制三类花在花萼宽度、花萼长度两个维度的KDE可视化,两两变量组合,颜色越深表示出现的概率密度越大,也就是出现的频率越多
ax = sns.kdeplot(data=setosa,x=setosa['SepalWidthCm'], y=setosa['SepalLengthCm'], cmap='Reds', shade=True, thresh=0.01)
ax = sns.kdeplot(data=versicolor,x=versicolor['SepalWidthCm'], y=versicolor['SepalLengthCm'], cmap='Greens', shade=True, thresh=0.01)
ax = sns.kdeplot(data=virginica,x=virginica['SepalWidthCm'], y=virginica['SepalLengthCm'], cmap='Blues', shade=True, thresh=0.01)
-
使用pandas取出三类鸢尾花的数据;
df = pd.read_csv('iris.csv',usecols=[0,1,2,3,4]) -
绘制setosa类鸢尾花花萼宽度和花萼长度的核密度图,颜色越深表示落在该区域的数据越多,也就是概率密度越大;
-
cmap是色彩模式为红色系列,shade=True是包含有阴影色彩,thresh=0.01指定绘制阴影的最低等高线阈值;
-
另外两行代码同理。
ax = sns.kdeplot(data=setosa,x=setosa['SepalWidthCm'], y=setosa['SepalLengthCm'], cmap='Reds', shade=True, thresh=0.01) ax = sns.kdeplot(data=versicolor,x=versicolor['SepalWidthCm'], y=versicolor['SepalLengthCm'], cmap='Greens', shade=True, thresh=0.01) ax = sns.kdeplot(data=virginica,x=virginica['SepalWidthCm'], y=virginica['SepalLengthCm'], cmap='Blues', shade=True, thresh=0.01)
箱型图
我们还可以绘制箱型图:
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
df = pd.read_csv('iris.csv',usecols=[0,1,2,3,4])
fig,axes=plt.subplots(1,2,figsize=(15,8))
sns.set_style('whitegrid') # 设置主题
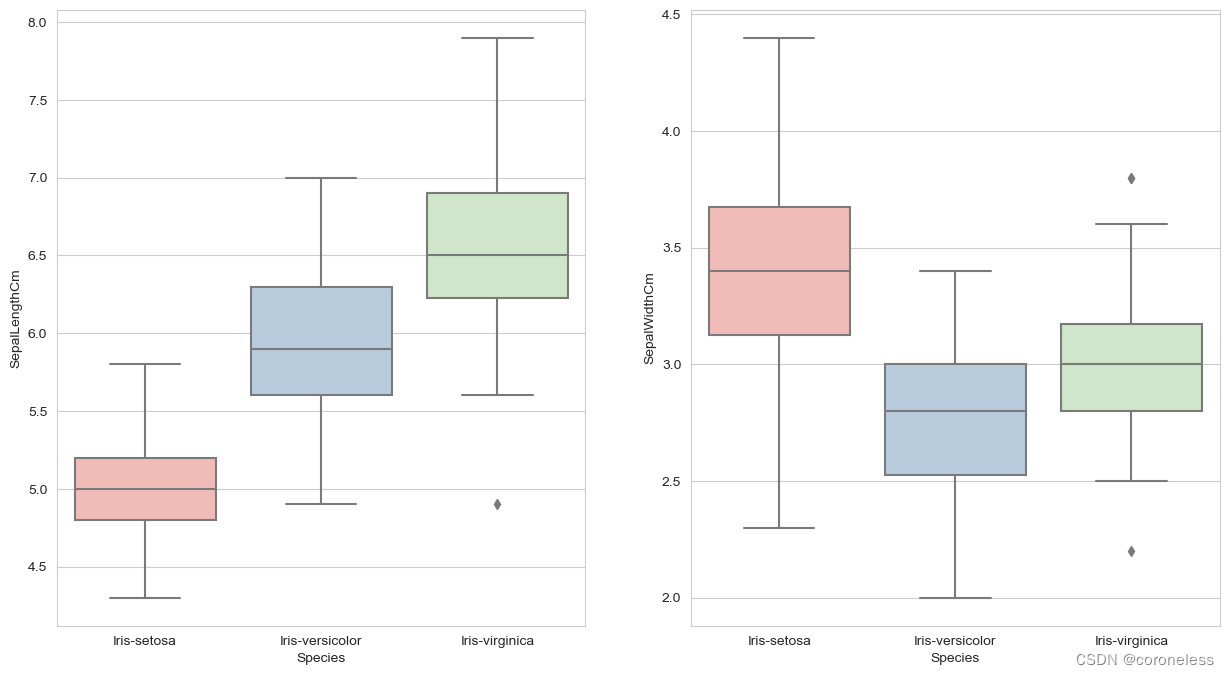
sns.boxplot(x='Species',y='SepalLengthCm',data=df,palette='Pastel1',ax=axes[0])
sns.boxplot(x='Species',y='SepalWidthCm',data=df,palette='Pastel1',ax=axes[1])
-
利用matplotlib划出子图的位置,1,2 表示第一行有两个字图,figsize表示每个子图的尺寸是15*8;
fig,axes=plt.subplots(1,2,figsize=(15,8)) -
调用boxplot绘制箱型图,x轴为类别,所以有红蓝绿三个箱子,是三种花的类型,y轴是花萼的长度,palette是选择的色板色系;
-
axes[0]表示绘制第一个子图,即左边的子图,axes[1]表示绘制在右边的子图里。
sns.boxplot(x='Species',y='SepalLengthCm',data=df,palette='Pastel1',ax=axes[0]) sns.boxplot(x='Species',y='SepalWidthCm',data=df,palette='Pastel1',ax=axes[1])
小提琴图
小提琴图看上去其实更像一片树叶,小提琴图其实和箱型图是一样的含义,但是它能更连续、光滑的反映出数据的概率密度分布。
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
sns.set_style('whitegrid') # 设置主题
df = pd.read_csv('iris.csv',usecols=[0,1,2,3,4])
f,axes=plt.subplots(2,2,figsize=(8, 8),sharex=True)
sns.despine(left=True)
sns.violinplot(x='Species',y='SepalLengthCm', data=df,palette='husl',ax=axes[0,0])
sns.violinplot(x='Species',y='SepalWidthCm',data=df,palette='Set2_r',ax=axes[0,1])
sns.violinplot(x='Species',y='PetalLengthCm',data=df,palette='Blues',ax=axes[1,0])
sns.violinplot(x='Species',y='PetalWidthCm',data=df,palette='CMRmap',ax=axes[1,1])
-
使用matplotlib划分出2 * 2即四个子图的位置;
f,axes=plt.subplots(2,2,figsize=(8, 8),sharex=True) -
seaborn的函数despine()用来去除轴线;
sns.despine(left=True) -
violinplot是画小提琴图的命令,除了x轴和y轴选择的特征之外,还选用了四种不同的调色板配色。
sns.violinplot(x='Species',y='SepalLengthCm', data=df,palette='husl',ax=axes[0,0]) sns.violinplot(x='Species',y='SepalWidthCm',data=df,palette='Set2_r',ax=axes[0,1]) sns.violinplot(x='Species',y='PetalLengthCm',data=df,palette='Blues',ax=axes[1,0]) sns.violinplot(x='Species',y='PetalWidthCm',data=df,palette='CMRmap',ax=axes[1,1])
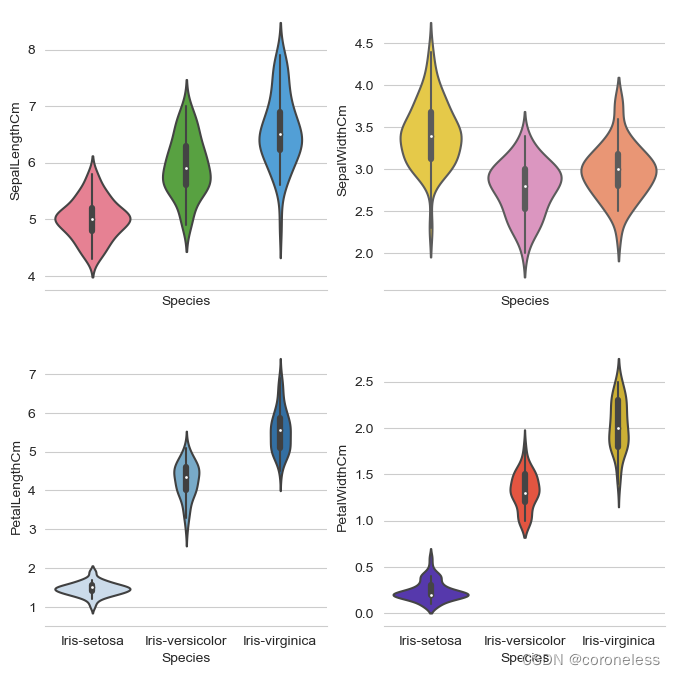
我们可以看到,小提琴侧边越胖,说明落在这个区间的点越多,概率密度越大;越符合正态分布的小提琴图的侧边就越是中间高、两侧逐渐降低的效果;
其实大家仔细看小提琴图中间有一个黑色的竖线,它就是一个变瘦的箱型图。
















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











