







一、概述
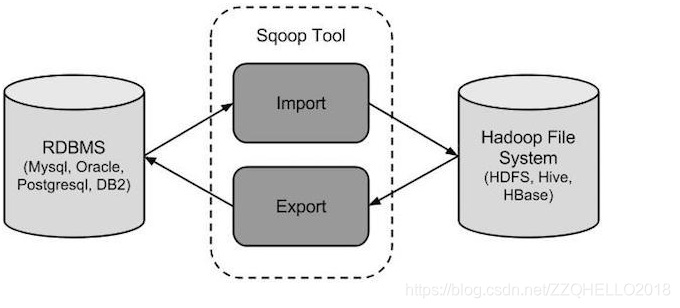
sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。sqoop的含义就是
“SQL to Hadoop”
核心的功能有两个:导入;导出
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等
Sqoop 的本质还是一个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论。
二、工作机制
将导入或导出命令翻译成 MapReduce 程序来实现 在翻译出的 MapReduce 中主要是对 InputFormat 和 OutputFormat 进行定制
三、安装前知识
1.版本说明
共有两代版本,两代之间是两个完全不同的版本,不兼容
sqoop1:1.4.x 绝大部分企业所使用的sqoop的版本都是 sqoop1,例如sqoop-1.4.6 或者 sqoop-1.4.7
sqoop2:1.99.x
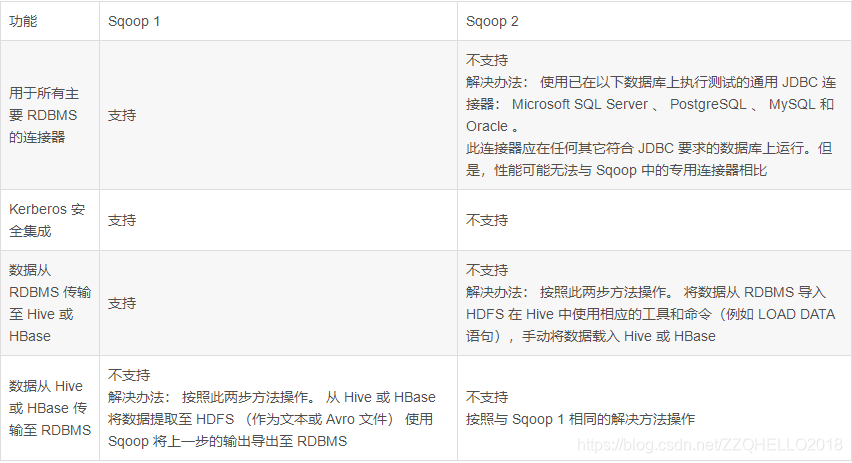
2.sqoop1和sqoop2功能性对比
四、安装配置Sqoop
1.去官网下载sqoop,直接百度即可
2.解压后进入conf目录
guo@drguo1:/opt/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/conf$ cp sqoop-env-template.sh sqoop-env.sh
3.在sqoop-env.sh添加各种home
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/Hadoop/hadoop-2.7.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/Hadoop/hadoop-2.7.2
#set the path to where bin/hbase is available
export HBASE_HOME=/opt/hbase
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/apache-hive-2.0.0-bin
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/opt/zookeeper-3.4.8/conf
4.把MySQL驱动jar包导入lib/下
5.建表
mysql> use hive;
Database changed
mysql> create table urlrule(
-> url varchar(1024),
-> info varchar(50)
-> );
Query OK, 0 rows affected (0.12 sec)
mysql> show tables;
+---------------+
| Tables_in_hive |
+---------------+
| urlrule |
+---------------+
1 row in set (0.00 sec)
6.将数据从HDFS导入MySQL
sqoop export --connect jdbc:mysql://drguo1:3306/url --username hive --password guo \
--table urlrule \
--export-dir /flow/topkurl/ \
--columns url \
--input-fields-terminated-by '\t'
7.将数据从MySQL导入HDFS
[hdfs@ws1dn1 root]$ sqoop import -m 1 --connect jdbc:mysql://192.168.1.65:3306/v3 --username root --password guo --table t_log_2016_done --target-dir /user/hdfs/testdata/
1、该脚本是创建sqoop的job脚本,原则上只需要执行一次即可,以后不需要执行该脚本,只需要执行sqoop job -exec
jobname。
2、该文件中的全部为增量表的sqoop的job语句。
3、如果需要重新运行,则运行方式:load_data_incr_sqoop.sh
#增量将数据导入到hive中(注:业务系统中表有自增的id的就用id来增量导出;否则都用create_date字段来导出)
五、导入导出格式:
注意导入之前在hive中需要先建库,表可以指定自动生成,但是库不能自动生成
导入格式
sqoop import
--connect jdbc:mysql://spark02:3306/database
--table table_name
--username root
--password root
--hbase-create-table
--hbase-table A
--column-family infor
--hbase-row-key id
--fields-terminated-by '\t'
-m 1
--null-string ''
--incremental append
--check-column id
--last-value num
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -hbase-create-table:表示在hbase中建立表
- -hbase-table A:指定在hbase中建立表A
- -column-family infor:表示在表A中建立列族infor。
- -hbase-row-key :表示表A的row-key是consumer表的id字段
-m:并发的map数量
- -null-string:导入的字段为空时,用指定的字符进行替换
- -incremental append:增量导入
- -check-column:指定增量导入时的参考列
- -last-value:上一次导入的最后一个值
导出格式:
sqoop export
--connect jdbc:msyql://localhost:3306:/database
--table table_name
--username root
--password root
--export-dir /test1/
--fields-terminated-by '\t'
-m 1
说明:
- -connect:指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
- -table:指的是要读取数据库database中的表名
- -username - -password:指的是Mysql数据库中的用户名和密码
- -export-dir 在hdfs中的位置
- -fields-terminated-by :HDFS中的文件字段的间隔符
-m:并发的map数量
1.关系型数据库导入Hadoop
(1)从Mysql导入
sqoop import \
--connect jdbc:mysql://服务器地址:3306/数据库名 \
--username 账号 \
--password 密码 \
--table 表名 \
--fields-terminated-by "," \
--lines-terminated-by "\n" \
--hive-import \
--hive-database 数仓中库名 \
--hive-table 数仓中表名 \
--hive-overwrite
举例:
#1、全量导入 合同表lnk_agreement:
sqoop import \
--connect jdbc:mysql://172.30.2.217:3306/linkcrm \
--username biuser \
--password 123456 \
--table lnk_agreement \
--fields-terminated-by "," \
--lines-terminated-by "\n" \
--hive-import \
--hive-database test_ods \
--hive-table ods_lnk_agreement \
--hive-overwrite;
说明:从mysql(地址为172.30.2.217,端口3306,账号密码为biuser/123456)的源数据库,导入表到hive中;
源数据库名:linkcrm,
表名:lnk_agreementhive中数据库名:crm_ods(这个需要先提前在hive中创建)
表名:ods_lnk_agreement(自动生成,不需要建)
(2)从Oracle导入
#全量导入(不需要提前建表,自动生成表,后续增量会覆盖)
#销售主表B2B_SALE_ORDER
sqoop import --hive-import \
--connect jdbc:oracle:thin:@172.31.13.27:1521/xtpdg \
--username=dmuser \
--password=kWV8xudDIic= \
--table MPLATFORM.B2B_SALE_ORDER \
--hive-database test_ods \
--hive-table ods_B2B_SALE_ORDER \
--hive-overwrite -m 1 \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--null-string '\\N' \
--null-non-string '\\N';
#query方式全量导入
#产品基础表
sqoop import --hive-import \
--connect jdbc:oracle:thin:@172.31.13.27:1521/xtpdg \
--username=dmuser \
--password=kWV8xudDIic= \
--direct \
--query "select * from MPLATFORM.BASE_PRODUCT_INFO where \$CONDITIONS" \
--target-dir /test01/ods_tmp/ods_BASE_PRODUCT_INFO/ \
--hive-database test_ods \
--hive-table ods_BASE_PRODUCT_INFO \
--hive-overwrite \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--null-string '\\N' \
--null-non-string '\\N' \
-m 1 ;
(3)从SqlServer导入
#全量导入方式
#AD人员表
sqoop import --driver com.microsoft.sqlserver.jdbc.SQLServerDriver \
--connect "jdbc:sqlserver://172.30.3.93:1433;username=dds_user;password=dds_user;database=Ultimus2017Biz;selectMethod=cursor" \
--table ORG_USER --hive-table test_ods.ods_ORG_USER \
--hive-import -m 1 \
--hive-overwrite \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--null-string '\\N' \
--null-non-string '\\N' \
--hive-drop-import-delims \
--fields-terminated-by '\0001';
#query方式导入
#场景:个别字段过长容易失败可以选择query导入,指定条件和字段)
#流程实例表(xml格式的列不支持)
sqoop import --driver com.microsoft.sqlserver.jdbc.SQLServerDriver \
--connect "jdbc:sqlserver://172.30.3.93:1433; username=dds_user;password=dds_user;database=Ultimus2017Server;selectMethod=cursor" \
--query 'select PROCESSNAME,INCIDENT,SUMMARY,STARTTIME,ENDTIME,STATUS,INITIATOR,TIMELIMIT from INCIDENTS WHERE $CONDITIONS' \
--target-dir /test01/ods_tmp \
--hive-table test_ods.ods_INCIDENTS --hive-import -m 1 --hive-overwrite \
--input-null-string '\\N' --input-null-non-string '\\N' \
--null-string '\\N' \
--null-non-string '\\N' \
--hive-drop-import-delims --fields-terminated-by '\0001' ;
#优化,引入--delete-target-dir参数代表指定目录如果存在先删除目录再重新创建
#ods_INCIDENTS流程实例表
sqoop import --driver com.microsoft.sqlserver.jdbc.SQLServerDriver \
--connect "jdbc:sqlserver://172.31.12.41:1433; username=dds_user;password=dds_user;database=Ultimus2017Server;selectMethod=cursor" \
--query 'select PROCESSNAME,INCIDENT,SUMMARY,STARTTIME,ENDTIME,STATUS,INITIATOR,TIMELIMIT from INCIDENTS WHERE $CONDITIONS' \
--target-dir /test01/ods_tmp \
--delete-target-dir \
--hive-table test01.ods_INCIDENTS --hive-import -m 1 --hive-overwrite \
--input-null-string '\\N' --input-null-non-string '\\N' \
--null-string '\\N' \
--null-non-string '\\N' \
--hive-drop-import-delims --fields-terminated-by '\0001' ;
2.Hadoop导出到MySQL
(1)导出到MySQL
将数据集市(DM层)结果表导出到MySQL中
#注意一定要先在mysql中建好表结构,包括字段和字段类型,否则会导入失败
#dm层(表名为dm_numcheck)导出到mysql(表名为mysql_numcheck)
sqoop export \
--connect jdbc:mysql://172.30.3.78:3309/Test?useSSL=false \
--username ywfxuat \
--password ywfxuat123 \
--table mysql_numcheck \
--export-dir /data/user/hive/warehouse/test_dm.db/dm_numcheck/000000_0 \
--input-fields-terminated-by '\001' \
--update-key id \
--update-mode allowinsert \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
--fields-terminated-by '\t';
将hive中的 nofollowdetail 表导出到 BPM_ZB库的 nofollowdetail 表中
六、过滤导入
在实际的项目中,要处理的数据,需要进行初步清洗和过滤
1.指定分隔符和导入路径
sqoop import \
--connect jdbc:mysql://hadoop1:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /user/hadoop11/my_help_keyword1 \
--fields-terminated-by '\t' \
-m 2
2.导入数据:带where条件
sqoop import \
--connect jdbc:mysql://hadoop1:3306/mysql \
--username root \
--password root \
--where "name='STRING' " \
--table help_keyword \
--target-dir /sqoop/hadoop11/myoutport1 \
-m 1
3.查询指定列
sqoop import \
--connect jdbc:mysql://hadoop1:3306/mysql \
--username root \
--password root \
--columns "name" \
--where "name='STRING' " \
--table help_keyword \
--target-dir /sqoop/hadoop11/myoutport22 \
-m 1
selct name from help_keyword where name = "string"
4.query:自定义查询SQL
sqoop import \
--connect jdbc:mysql://hadoop1:3306/ \
--username root \
--password root \
--target-dir /user/hadoop/myimport33_1 \
--query 'select help_keyword_id,name from mysql.help_keyword where $CONDITIONS and name = "STRING"' \
--split-by help_keyword_id \
--fields-terminated-by '\t' \
-m 4
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--query 'select id, account from my_user where $CONDITIONS' \
--target-dir /user/beifeng/sqoop/imp_my_user_query \
--num-mappers 1
ps: query 这个属性代替了 table 可以通过用sql 语句来导出数据
(where $CONDITIONS' 是固定写法 如果需要条件查询可以
select id, account from my_user where $CONDITIONS' and id > 1)
注意:
在以上需要按照自定义SQL语句导出数据到HDFS的情况下:
(1)、引号问题,要么外层使用单引号,内层使用双引号,$CONDITIONS的$符号不用转义, 要么外层使用双引号,那么内层使用单引号,然后$CONDITIONS的$符号需要转义
(2)、自定义的SQL语句中必须带有WHERE \$CONDITIONS















 6803
6803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











