







文章目录
前言
最近在解决一个postgresql on JIT 上的内存问题,刚好能够有机会深入了解学习这个技术,以及 PG 如何利用 LLVM 来实现这个技术。
JIT (Just-In-Time Compilation) 动态编译技术,能够在程序运行过程中 生成优化后的程序执行逻辑,能够减少不必要的CPU分支跳转,达到提升性能的目的。比如在 PostgreSQL 这样的数据库内部有非常多的通用逻辑,对于一个表达式算子 WHERE a.col = 3 在正常的执行过程中需要经过一系列的分支判断,而JIT 能够优化这一些分支判断,生成具体的执行函数来执行这个表达式。所以 JIT 在PG 内部实际生效的位置肯定是优化器之后,拿到了具体的执行计划,就可以通过JIT 优化执行逻辑,填充具体的执行函数。
在PostgreSQL 中有非常多的通用逻辑,比如像 元组解析(heap_tuple_deforming) 有很多针对attr 类型的判断,通过JIT 能够极大得简化这样的逻辑,这种性能方面的提升对PG来说是巨大的。PG 是通过 LLVM(Low-Level-Virtual-Machine)实现JIT的,之所以选择 LLVM 主要的原因如下:
- 技术成熟且社区稳定度足够高。因为 LLVM 背后有apple 公司的支持,资金链不会断,又拥有GNU社区 以及 其他庞大的贡献者群体,整个社区能够最大可能得延续下去。
- LLVM 社区 和 PostgreSQL 开源协议(llvm是 apache 2.0)兼容度较高,都允许个人/公司 二次开发。
- LLVM 的前端编译器 clang 支持C代码生成 IR 过程需要的bitcode。
本篇在介绍 PG 的JIT 实现之前会先用个人浅薄的学习历程介绍一下LLVM ,其作为编译器工具集实在是过于庞大(社区已经有超过 44w commits了),这个方向的知识体系之庞大相比于数据库内核来说甚至犹有过之,所以只能是入门级别的一些介绍了(实现源码还都没有怎么看过)。
LLVM
llvm 推出的背景也是受GCC的影响:
- 学术方面,GCC 20-30年前作为极少数开源的编译器,被用作教学。但是当时软件工程理论还没有那么完善的情况下,GCC 用 C语言编写出来的编译器各个组件耦合度极高,很难让学生们将其中的某一个组件单独拿出来学习研究。GCC的内核越来越庞大的情况下,新加入的开发者也很难对整体的架构有大的改动,整个项目的开发难度也会越来越难,新特性的开发成本也会极高。不利于学习,不利于有热情的新的开发者们参与。
- 工业界方面则受限于 GPL 的协议,无法自由开发。很多编译器的研究人员也担心自己开发的代码只会使用一次就被丢弃,很有挫败感。
主要 基于以上原因,Chris Lattner 带领他的团队重新设计了 各个编译器组件完全解耦的编译器架构,而且在开源协议上更为自由,各个公司可以用作商业用途且只需要保留copyright 就好,这应该也是 乔布斯 欣赏LLVM 并收购这个项目及其团队的原因(传奇依旧在为未来做贡献)。
最开始的时候 LLVM 是将GCC 仅作为自己的前端,用来将高级语言转换为 LLVM IR需要的中间语言 bitcodes file。这也就导致用户想要用 llvm 的时候还需要配置GCC环境,而且 llvm 想要将很多工作放在 前端来做的话(代码静态分析,代码格式化,其他优化)需要对GCC有较大的改造,成本极高。所以 llvm 直接 重写前端部分,这也是 Clang 出现的原因,而且 Clang兼容 GCC,也提供了极为丰富的工具集合。
LLVM 编译
因为 llvm 代码仓库过于庞大,直接拉整个代码仓库的所有版本信息会超过github的大小限制。这里如果要从github 拉代码,建议只拉对应版本的最新commit即可(考虑到可能github有限速,这里贴的是清华源的链接)。
git clone -b release/13.x --depth 1 https://mirrors.tuna.tsinghua.edu.cn/git/llvm-project.git llvm-project-13
编译过程如下(主要编译的是 项目目录下的 llvm目录,这是其库的核心):
cd llvm-project-13
mkdir build && cd build
cmake -G Ninja -DCMAKE_BUILD_TYPE=debug ../llvm
ninja -j5 && make install
如果想要编译其他的组件,比如clang,也可以用同样的方式,cmake 最后指定的目录变成clang就好了。
大多数情况如果是使用的话完全不需要自己编译,比如ubuntu ,直接 sudo apt-get install llvm-10这种就可以了,编译安装可能适用于 高版本的llvm 以及 增加debug 信息,或者想要了解/学习 llvm工具集合 以及实现原理的自己编译会更方便一些。
LLVM 基本架构
LLVM 基本架构如下(图片来自 《Getting started with LLVM core libraries》):

各个组件各司其职:
- clang – 词法分析/语法(语义)分析
- LLVM IR linker – 中间代码生成
- LLVM IR optimizer – 代码优化
- LLVM backend – 生成目标代码(对接不同的平台 – X86, XCore, ARM, AArch64等),能够支持跨平台编译
- LLVM integrated assembler 用于生成binary
hh宏观上主要有这几个部分:
Frontend前端(以clang/gcc 为主),主要工作是将计算机高级语言(C/C++/Objective-C等)转换为 LLVM 编译器 IR。包括了前面说的clang 的工作。IR中间语言(Intermediate Representation)。包括 人可读(ll文件)的/字节编码(bitcode文件) 的两种方式。提供非常多的工具和调用库来构造 和 解析 两种文件。能够解析 clang编译好的 bitcode文件到内存中,可以做非常多的代码优化。JIT 的核心就是利用 IR 达成代码优化的目的。Backend后端。将生成的IR 转换为汇编代码 或者 二进制机器码。像是 寄存器分配,循环转换,特定对象的优化 都会在后端来做,最靠近CPU的部分。
整个架构内部的各个组件都可以单独拿出来和其他的项目使用,或者说禁止其中的某一个组件。
比如 不想使用LLVM IR linker,就可以禁止掉;想要使用clang作为前端的编译器 以及 代码检查分析工具,不想要使用 LLVM-IR,clang就可以单独拿出去用;opt 作为llvm的一个命令集成 libLLVMipa库,也可以单独对代码进行 IR优化。
从前面编译的结果也能够看到,llvm 提供的内部工具极多:

因为本篇主要关注的是 LLVM 的 IR ,所以接下来会浅浅得介绍一下IR。
LLVM IR
IR(Intermediate Representation) – 中间语言 作为LLVM的核心,连接了 LLVM 的前端和后端。前端负责生成IR,后端负责消费IR。
LLVM IR的设计按照官方的描述 是考虑在支持更多更通用的平台以及前端语言的情况下 保障性能,可能相比于某一些专有优化器只针对特定的平台来做的IR 功能来说性能差一些,但LLVM 目的是通用性(不是每一个公司都有足够的人力和财力投入在自己平台的编译器设计和开发中的)。
LLVM IR 的基本形态如下:
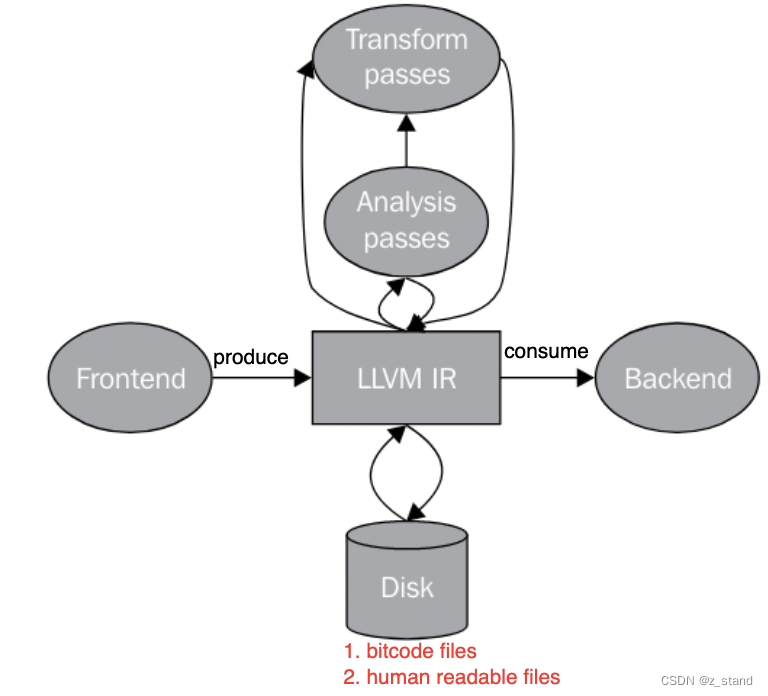
IR 有三种等价的形态:
-
内存形态的中间语言表示(主要是原始代码的 指令抽象,通过
Instruction类 以及其他Module,Function这种表示) -
磁盘上的语言表示,用空间利用率较高的编码方式形成的 bitcode files,后面会介绍一下这个文件的格式。IR 实现的时候会解析这一些格式到内存中,形成内存形态的中间语言表示。
在postgresql 中,一般处于编译之后的lib目录下 :
$libdir/postgresql/bitcode -
另一种磁盘上的语言表示(ll文件),人可读的一种格式。
LLVM IR两种磁盘文件的生成方式
对于如下代码 sum.c:
int sum(int a, int b)
{
return a+b;
}
通过如下命令可以将sum.c 转为 bitcode形态,.bc 文件的内容就都是字节序的形态了:
clang sum.c -emit-llvm -c -o sum.bc
想要看的话只能vim打开,:%!xxd来看具体字节内容了,而且bitcode文件的大小相比于原始代码文件小很多,在PostgreSQL 编译的bitcode文件相比于原始文件空间占用甚至小了两倍,但其表示的代码内容可一点也没少(转为字节数组形态压缩率还是比较好控制)。
将 sum.c 转为 人可读的另一种 ll 文件:
clang sum.c -emit-llvm -S -c -o sum.ll
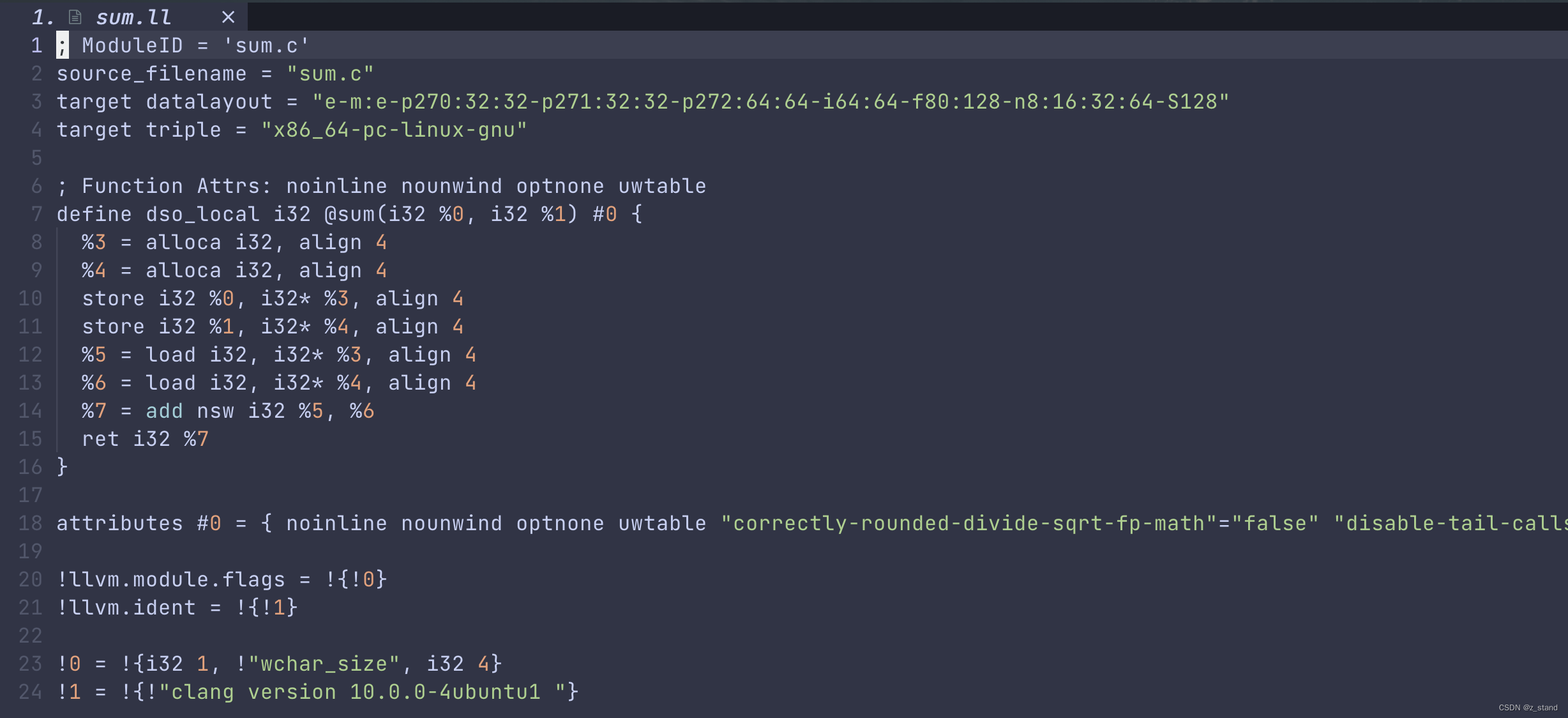
其内容如下:
对于 sum.ll 文件,可以通过 llvm-as sum.ll -o sum.bc转为 bc文件,也能通过 llvm-dis sum.bc -o sum.ll 将bc文件转位ll文件,这一些文件内部主要保存的是具体的函数 以及 各种变量/参数信息,所以llvm 也提供了从bc 文件直接提取 函数/变量的 工具:
llvm-extract -func=sum sum.bc -o sum-fn.bc
LLVM IR .ll 文件 语法形态
之所以介绍这个,首先bc文件 内容是字节序,不太好看懂,其次 .ll 文件和bc 文件 在 IR 看来是等价的,只是表示的方式不一样,最后解析到内存中生成内存的 IR 表示的时候也是按照这个 ll 文件里面的关键模块来解析的,可以方便理解后续要说的 PostgreSQL-JIT 的代码。
还是用上面的 sum.ll 文件举例:
; ModuleID = 'sum.c'
source_filename = "sum.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-linux-gnu"
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @sum(i32 %0, i32 %1) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = add nsw i32 %5, %6
ret i32 %7
}
attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-..."}
整个LLVM 文件不论是 ll 文件 还是 bc 文件,在LLVM 内部都会被整体抽象为 LLVM Module。它是整个 IR 的最顶层数据结构,在其内部会划分一系列 函数(Function)/基础块(Basic Block实际是函数的作用域),以及抽象的执行指令(Instruction)。
LLVM IR的基础特性主要有三个:
- 使用了 SSA(Static Single Assignment ),每一个值只有唯一定义它的赋值。这个特性对于生成 use-define 关系图有很大的帮助,而依赖use-def 对 常量传播 以及 消除公共表达式的分支 有巨大的优化作用。可以说 SSA 方式极大得简化了这个过程,从文件格式就定义了这个特性。
- 三地址指令 组织代码。两个源操作数将操作的结果放在不同的目标操作数中(没有太明白这个特性的优势)。
- 拥有无穷的寄存器,可以随意通过
%符号标识后续的符号 是一个寄存器,比如%1,%0,数字没有最大值的限制。
接下来看看具体的文件内容(; 是注释):
ModuleID,当前整个 ll 文件可以看作是一个module,ModuleID 唯一标识这个文件,直接用的是文件名。source_filename同理。target datalayout,保存的是端序,当前系统的类型大小等,不同的type 之前使用的是-符号来分割,其各个字段表示的内容如下。
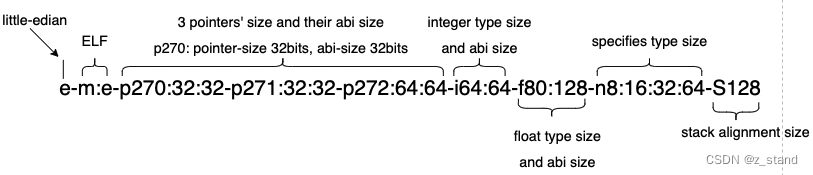
datalayout 的详细解释可以参考 https://llvm.org/docs/LangRef.html#data-layout。target triple表示当前所属平台的架构。x86_64-pc-linux-gnu显然 linux 86架构,如果在mac上,则显示的是arm64-apple-macosx12.0.0。define dso_local i32 @sum(i32 %0, i32 %1) #0表示函数声明,基本还是遵循 C 的语法。i32表示函数返回值为 32bits的整数类型,(i32 %0, i32 %1)有两个 i32 类型的参数;#0定义了一堆函数属性(像是C++的 inline/noexcept 等),在后续的attributes #0体现,比如nounwind– 标识一个函数不会 抛异常。- 函数内部的则为 basic block部分,主要是一些基础指令,
%+ 数字,就像前面说的是寄存器,临时保存变量;其他的像是alloca属于通用的指令,alloca为当前函数分配栈帧空间。%3 = alloca i32, align 4分配一个4bytes 的栈空间,且4bytes对齐,并用寄存器%3指向这个空间。
更多的语法细节 (全局变量、数组、链表 等)可以参考 官方文档 https://llvm.org/docs/LangRef.html.
LLVM IR in-memory 表示形式
前面描述了 ll 文件的详细格式 以及与其等价的其他两种表示方式,除了bc 文件之外就是 内存表示方式了。
下面提到的是重要的几种数据结构:
Module类。前面描述 ll 文件的时候简单说过,其是最顶层的IR 数据结构的表示方式,内存中的Moduleclass 则会保存所有转换单元的数据。(在 PostgreSQL 实现的jit 中,一个表达式执行单元是一个module,包含了这个表达式执行过程中所有的function/bb/instructions等)。
这个Module类提供了Module::iterator类型 通过begin()和end()函数可以非常便捷得迭代 module对象内部所有的 functions。Function类。包含了原始高级语言代码中对函数的声明或者及定义。而且 Function类中提供了isDeclaration()这样的接口来判断代码中函数是定义还是声明。通过getArgumentList()函数能拿到实际的函数参数 或者arg_begin()/arg_end()能够遍历函数参数。BasicBlock类则包含了一系列 LLVM 指令,同样可以通过其提供的begin()/end()函数来访问。Instruction类,每一个instruction 对象代表了一个 LLVM IR 的原子计算单元。
这四者之间的关系,按照前面 sum.c 生成的 sum.ll 来看,如下:
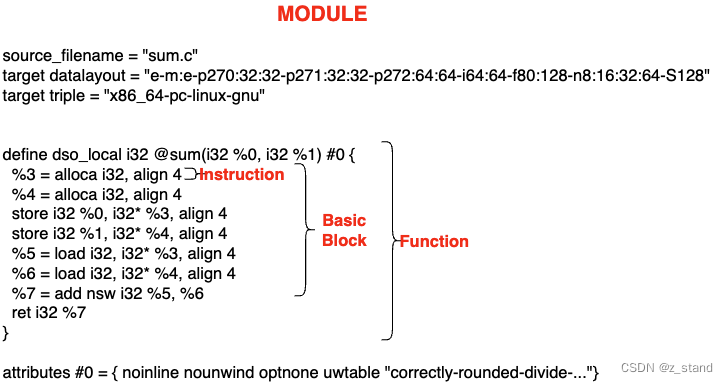
BasicBlock 在函数内部会有多个,比如有分支 跳转/循环 这种执行逻辑,每一个分支都算是一个BasicBlock,它们构成了函数的控制流。PostgreSQL 的分支裁剪就是减少尽可能多的 BasicBlock(每一个BasicBlock都需要执行一批instructions,会破坏CPU的流水线)。
LLVM IR Optimization
前面已经按照 module构造好 了IR 的内存表示,接下来就是进行优化了,当然也可以直接通过 llvm 提供的 opt 工具从磁盘文件进行优化,只是因为要实现JIT 的话,肯定是调用接口,就需要调用对应的优化接口了。
再看看前面的架构图 就对 optimization 所处的位置清晰很多了:
llvm 同样提供了几种优化驱动(clang 也会做,man clang中能够看到如下信息)
-O0什么优化也不做,包含了最多的可调式信息。-O1优化程度介于 O0-O1,具体优化了什么内容(官方没有提太多,估计就是小幅度得提升)-O2更高级一些的优化层级,开启大多数优化(具体什么还不太清楚)-O3和 O2 类似,不过为了性能,代码更多-Os和O2类似,不过代码大小会更小-Oz, 和O2 以及 Os 类似,不过是更进一步得减少了代码大小-O4开启了链接时优化
这一些优化驱动可以通过 opt 工具单独执行:
opt -O3 sum.bc -o sum-O3.bc
每执行一次 这个指令,可以理解为进行了一次 Pass,Pass 是IR 优化中 一轮的表示。而 mem2reg 则是 pass 过程非常重要的一部分,关于 mem2reg 的描述我没有看的特别明白:
This file promotes memory references to be register references. It promotes alloca instructions which only have loads and stores as uses. An alloca is transformed by using dominator frontiers to place phi nodes, then traversing the function in depth-first order to rewrite loads and stores as appropriate. This is just the standard SSA construction algorithm to construct “pruned” SSA form.
感觉还是得看 R大 的文章:https://www.zhihu.com/question/41999500/answer/93243408,还是需要花费更多的精力来研究,总之mem2reg 是IR优化过程中至关重要的一部分 😐。
Pass 是实现 IR优化的主要类,这块因为不专业,也不会过多的深入,只能说浅尝辄止,希望后续还能继续深入下去,有非常多有趣的设计思想和算法。
接下来我们看看 LLVM 的JIT 功能,这是后续介绍 PostgreSQL JIT的铺垫,因为 PG内部会用到 LLVM的 JIT引擎。
LLVM JIT
JIT 本身的优势前面已经说过了,能够在程序运行时按需编译,不需要存储程序的二进制程序,而且能够精确的获取到该程序运行的平台以及架构,更方便得调整代码体系来适配其所处的平台。被大规模应用在了 GPU,浏览器Javascript引擎,机器学习平台(tensorflow等)。
LLVM JIT 则能够提供一套完整的工具集(从前端到后端) 且 支持多语言和多平台 ,更有雄厚的工业界实践,这一些世 Libjit(2004年当时和llvm 的一些方向一样的开源项目,做的是编译器后端)所不能比的。
更为细致的一些对比可以参考 这篇博客:http://eli.thegreenplace.net/2014/01/15/some-thoughts-on-llvm-vs-libjit。这个博客里提到了 llvm创始人 Chris Lattner 和 libjit 创始人 Rhys Weatherley 的一些讨论 : https://lists.gnu.org/archive/html/dotgnu-libjit/2004-05/msg00012.html 非常有意思,也很感动。Chris Lattner 希望能够和 Libjit 的团队合并在一起来做 整个编译器架构,他们当时有比较接近的目标和方向,都是做 JIT(当时应该是赚钱多一些)以及编译器后端,只是LLVM 架构设计以及目标更为远大(整个编译器的全栈),libjit 只是作为编译器的后端且专攻JIT方向。 Chris 非常真诚得想要让两个团队合并,将双方好的代码以及架构融合在一起,再一起为一个目标奋斗,而不是作为开源产品分裂为两个项目,不利于长远发展。Rhys 的回复也很感动,认可了LLVM 的优势,但是他热爱他的项目,他不想放弃前面做的一切,如果加入到了LLVM 团队中,意味着他们的libjit 只能作为llvm 的一个JIT API,他们做了很长时间的 jit backend就没法用了,这是热爱自己产品的人不愿意看到的。最后当然是没有合并,libjit 也存活着,只是maintainer 基本没有太多,修一修文档和fix,新特性都很少了。而 LLVM 用自己的远大的目标 以及 完全解藕的架构成为业界主流。当然,热爱 以及 code for fun 真的没有什么问题,要不然也不会开源了。
LLVM JIT实现有三种:
- Lagacy JIT 1.0-3.5 版本,之后的版本就没有怎么用了
- MCJIT 2.9-present
- ORC JIT 3.7-present,这个版本也是在 > 11版本之后大家基本都用的一个实现(性能好)
本文会简单提一下Lagacy 版本的JIT,主要介绍的是 ORC 版本,因为这个版本的实现是在PostgreSQL 中用的。
Lagacy JIT(llvm1.0 – llvm3.5)
这个版本的JIT 实现比较旧,目前在比较新的版本中基本没有用这个实现了。
Lagacy JIT 的核心是 ExecutionEngine类,是一个执行引擎,用来执行 LLVM IR 构造好的 modules,同时还支持以下几种应用场景:
- Lazy compilation 延迟编译。 这个引擎允许在函数被调用的时机编译。如果 lazy compilation被关闭,则引擎会在用户请求访问一个函数指针的时候去编译这个函数。
- Compilation of external global variables 编译模块之外的全局变量,包括解析这个变量的符号 以及为它分配内存空间。
- Lookup and symbol resolution for external symbols via dlsym 通过 dlsym 查找和解析额外的符号。主要是在进程运行的时候通过 DSO(dynamic shared object)。
对于 LLVM JIT 主要关注的是如下几个方面,来辅助我们更好得理解PostgreSQL的 JIT实现:
- Memory Management,这在 PostgreSQL 的jit 实现中也是非常重要的一部分。
- 接口的基本用法
Memory Management 内存管理
LLVM JIT 引擎通过 类ExecutionManager 完成二进制符号写入到内存中的,从而能够让我们方便得跳到 指定的内存空间去 执行这一些指令。在这个过程中,内存管理 对于调度这一过程至关重要,需要提供像是 内存分配、释放、库的加载空间、内存访问权限的处理等。
在 LLVM 的 JIT 中,内存管理主要是通过 继承 RTDyldMemoryManager 类完成的,这个基类定义如下几种方法:
allocateCodeSection()和allocateDataSection()函数 能够分配且持有代码以及数据所需要的存储空间,并按照其类型对齐;极大得方便 manager 去追踪内存分配的过程。getSymbolAddress()这个函数会返回当前连接的库在内存中可以访问的地址。比如 有一个std::string 对象,JIT 想要访问的话需要拿到这个对象的符号名字才能使用 std::string 相关的函数。finalizeMemory()这个函数用来释放内存。但是在对戏那个使用完成之后只能调用一次。
ORC JIT (3.7 – present)
ORC(On Request Compilation) 按需编译。这个版本的JIT 从LLVM-3.7 开始到现在还一直在迭代,从LLVM-7开始社区开发了 ORC2 版本,在ORC的基础上进一步提升了性能,后面会简单提一下两个版本的差异。
ORC 提供的主要特性如下
- JIT-Linking。可以在运行时将可重定位的目标文件连接到进程,这里的可重定位目标文件是平台相关的(COFF,ELF,MachO)等。
- LLVM IR compilation。提供了将 IR 添加到运行JIT的进程中执行。
- Eager and lazy compilation。和 Legacy JIT 一样,这是一个基本的功能,即在JIT 要编译的对象被查找或者使用的时候进行真正的编译。
- Support for Custom Compilers and Program Representations。支持运行用户指定/支持的其他的编译器,而非运行自己的。
- Concurrent JIT’d code and Concurrent Compilation 允许多线程执行JIT 的代码,以及 并发编译,Legacy 并不支持这一些。
- Orthogonality and Composability。前面提到的 JIT 的特性都是可以正交 且 互相组合使用的。
使用方式有两种, LLJIT 和 LLLazyJIT。
前者 分别通过 IRCompileLayer 和 RTDyldObjectLinkingLayer 编译 LLVM IR 以及 链接编译结果为可以重定向的目标文件。
后者则扩展了 LLJIT的功能,添加了 CompileOnDemandLayer 来支持 IR 的 lazy compilation。
两者的实例可以分别通过 LLJITBuilder 和 LLazyJITBuilder 创建,如下案例 有一个 IR 的module M 被加载到了 一个 ThreadSafeContext 的 ctx 中:
// 生成 LLJITBuilder 实例
auto JIT = LLJITBuilder().create();
// JIT 创建失败了,返回错误
if (!JIT)
return JIT.takeError();
// 添加一个 module,这个module 是 LLVM IR 生成好的(比如从bc中load到内存的完整bc信息)
if (auto Err = JIT->addIRModule(TheadSafeModule(std::move(M), Ctx)))
return Err;
// 查找要执行的 函数entry的信息,编译会在这一步进行。
// 如果使用的是LLazyJITBuilder 且通过addLazyIRModule 添加的module
// 则这里不会编译,到真正执行的时候才会编译。
auto EntrySym = JIT->lookup("entry");
if (!EntrySym)
return EntrySym.takeError();
// 将查找的结果转换为函数地址
auto *Entry = (void(*)())EntrySym.getAddress();
// 调用JIT中生成好的该函数的代码,进行执行
// 如果开启lazy compilation,则到这里执行的时候才会编译
// 这个函数的 IR 代码。
Entry();
两种使用方式的 builder都提供了比较多的配置信息,创建 JIT 实例的时候可以指定编译的线程数/是否开启lazy compilation等。
auto JIT = LLLazyJITBuilder()
.setNumCompileThreads(4)
.setLazyCompileFailureAddr(
toJITTargetAddress(&handleLazyCompileFailure))
.create();
上面案例的完整可运行代码如下,里面添加了IR 以及 IR Optimization的过程。
其中 IR module 保存的代码逻辑 主要是计算输入的整数 n 的阶乘,里面的格式就是我们前面讲 ll 文件的时候描述的格式。
int fac(int n) {
return n == 0 ? 1 : n * fac(n-1);
}
完整代码如下:
#include "llvm/ExecutionEngine/Orc/LLJIT.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Support/InitLLVM.h"
#include "llvm/Support/TargetSelect.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Transforms/IPO.h"
#include "llvm/Transforms/Scalar.h"
#include "../ExampleModules.h"
using namespace llvm;
using namespace llvm::orc;
ExitOnError ExitOnErr;
// Example IR module.
//
// This IR contains a recursive definition of the factorial function:
//
// fac(n) | n == 0 = 1
// | otherwise = n * fac(n - 1)
//
// It also contains an entry function which calls the factorial function with
// an input value of 5.
//
// We expect the IR optimization transform that we build below to transform
// this into a non-recursive factorial function and an entry function that
// returns a constant value of 5!, or 120.
// 将前面 计算 n阶乘的代码转为 IR 的表达方式如下,默认输入的n 是5。
// 这里期望的优化是 真正执行的代码不会有这一些递归的过程,而是执行
// 逻辑已经完全展开。
const llvm::StringRef MainMod =
R"(
define i32 @fac(i32 %n) {
entry:
%tobool = icmp eq i32 %n, 0
br i1 %tobool, label %return, label %if.then
if.then: ; preds = %entry
%arg = add nsw i32 %n, -1
%call_result = call i32 @fac(i32 %arg)
%result = mul nsw i32 %n, %call_result
br label %return
return: ; preds = %entry, %if.then
%final_result = phi i32 [ %result, %if.then ], [ 1, %entry ]
ret i32 %final_result
}
define i32 @entry() {
entry:
%result = call i32 @fac(i32 5)
ret i32 %result
}
)";
// A function object that creates a simple pass pipeline to apply to each
// module as it passes through the IRTransformLayer.
// IR 的 optimiztion 过程是通过 Pass 完成的,这里实现了一个可打印优化过程的Pass。
class MyOptimizationTransform {
public:
MyOptimizationTransform() : PM(std::make_unique<legacy::PassManager>()) {
PM->add(createTailCallEliminationPass());
PM->add(createFunctionInliningPass());
PM->add(createIndVarSimplifyPass());
PM->add(createCFGSimplificationPass());
}
Expected<ThreadSafeModule> operator()(ThreadSafeModule TSM,
MaterializationResponsibility &R) {
TSM.withModuleDo([this](Module &M) {
dbgs() << " -- opt -- \n";
PM->run(M);
});
return std::move(TSM);
}
private:
std::unique_ptr<legacy::PassManager> PM;
};
int main(int argc, char *argv[]) {
// Initialize LLVM.
InitLLVM X(argc, argv);
InitializeNativeTarget();
InitializeNativeTargetAsmPrinter();
ExitOnErr.setBanner(std::string(argv[0]) + ": ");
// (1) Create LLJIT instance.
auto J = ExitOnErr(LLJITBuilder().create());
// (2) Install transform to optimize modules when they're materialized.
J->getIRTransformLayer().setTransform(MyOptimizationTransform());
// (3) Add modules.
ExitOnErr(J->addIRModule(ExitOnErr(parseExampleModule(MainMod, "MainMod"))));
// (4) Look up the JIT'd function and call it.
outs() << "--- lookup -- \n";
auto EntrySym = ExitOnErr(J->lookup("entry"));
auto *Entry = (int (*)())EntrySym.getAddress();
outs() << "--- run Entry() -- \n";
int Result = Entry();
outs() << "--- Result ---\n"
<< "entry() = " << Result << "\n";
return 0;
}
执行结果如下,我们主要是想确认 JIT 编译过程会在哪一步进行,可以看到在 lookup的过程中输出了 optimization 的打印:
--- lookup --
-- opt --
--- run Entry() --
--- Result ---
entry() = 120
这个是 ORC 默认没有开启 lazy的过程,如果我们用 LLLazyJITBuilder 创建,并开启lazy compilation呢?修改一下初始化代码就好了:
// 创建 jit 实例的函数变更一下
auto J = ExitOnErr(LLLazyJITBuilder().create());
...
// 添加module 的函数变更为 AddLazyIRModule 即可
ExitOnErr(J->addLazyIRModule(ExitOnErr(parseExampleModule(MainMod, "MainMod"))));
再看看输出,确实会在 执行 Entry的过程中进行 JIT 的编译:
--- lookup --
--- run Entry() --
-- opt --
-- opt --
--- Result ---
entry() = 120
核心优化其实还是在 IR过程,只是JIT 可以让用户方便得调度这个过程,控制优化实际执行的时机。
大家可以在 上面案例中的 MyOptimizationTransform 中的 Expected<ThreadSafeModule> operator() 运算符打印 M的内容,对比优化前后 M 的变化,优化后的M 也是我们后面调用 Entry() 执行时真正执行的代码。
不过这里为什么会优化了两次,执行了两次Pass?
关于 ORC JIT 接口基本的使用就介绍完了,当然这一些都只是基本接口。
更多关于 ORC 的介绍,可以看看油管的这个视频:https://www.youtube.com/watch?v=K2AO6sZBlY8,ORC开发者的一个全功能介绍。
到此LLVM的介绍只简单浅浅的介绍了 我们PostgreSQL JIT 使用需要的一些功能 ,IR 以及 JIT。更多的LLVM的其他组件 以及 更深入的细节 需要更长的时间来学习,编译器体系实在是复杂,感觉难度以及复杂度是超过数据库内核的,毕竟其是和 linux kernel 一个级别的项目(时间接近的演进历史)。
统计了一下整个 LLVM-project 13版本 的代码量:
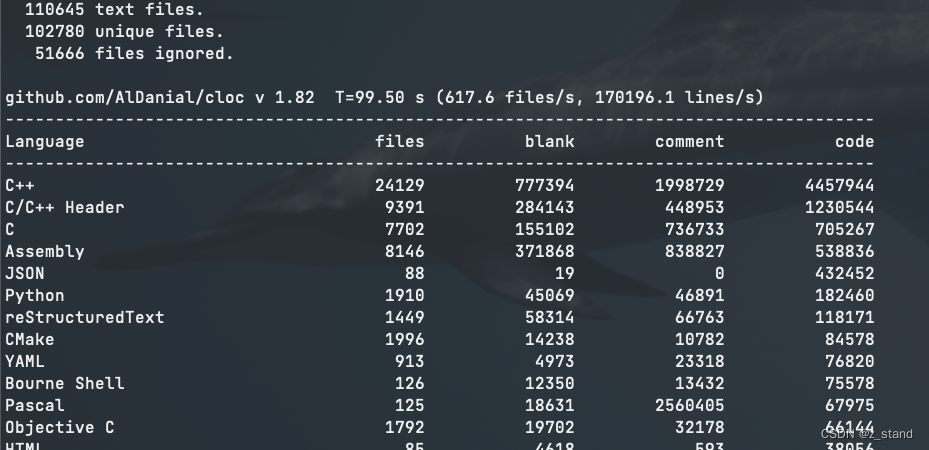
630w行的 c/c++ 代码,44w commits。
还是回到数据库领域吧,接下来看看 PostgreSQL 中的JIT 用法以及实现。
PostgreSQL JIT
Orc JIT 中能够看到,JIT 能够调度 执行IR 优化的时机,因为代码优化时需要消耗CPU 和内存的,我们PostgreSQL 也是使用的是 ORC JIT 来实现这一过程。
后面描述的是
llvm-13版本下的 JIT 实现,postgresql 版本是REL_12_STABLE
JIT 的使用
-
编译
前面其实介绍过 LLVM 和 PG结合的相关编译参数,很简单,llvm编译这里就不说了,前面已经提过了,简单说一下和PG相结合的编译(确保环境中有自己的llvm 版本)。# 拿到 PG 的源代码,生成makefile LLVM_CONFIG='/opt/local/bin/llvm-config-mp-13' \ ./configure --prefix=/Users/zhanghuigui/Desktop/work/source/postgres/build \ --with-llvm make -s -j5 && make install主要是利用
LLVM_CONFIG,指定llvm-config程序的路径,后面LLVM相关的库以及头文件的依赖都会通过llvm-config去找,只要你编译好,就不需要设置什么环境变量之类的了。 -
启用JIT
目前 PG 12版本的 JIT 默认是开启的,如果想要关闭,可以通过在当前session或者postgresql.conf设置set jit=off就可以了。当然,还有一些其他参数,可能会影响JIT的性能测试:
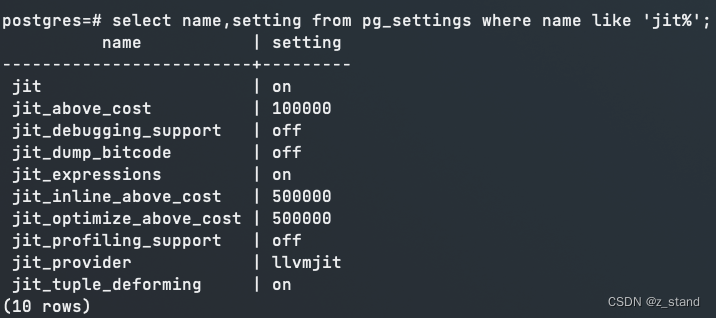
比如 cost 相关的几个,尤其是前面介绍LLVM说到的 JIT 优化的核心部分(IR 以及 IR optimize),这两个的启用分别由jit_inline_above_cost以及jit_optimize_above_cost来控制,如果我们测试的SQL cost 小于这两个值(默认50w),那也不会启用这两个优化,可能性能收益没有预期那么高,所以测试的时候也需要关注测试的sql 的cost 是否满足启用这两个优化的要求。其他的,默认都是开着的。 -
性能对比
这里跑了 jit=off 和 jit=on 的 标准 tpch-50G 的数据,虽然数据集不大,但是部分查询场景JIT 在 PG 这种接近30年历史的数据库中还是有20-30%的性能提升,可见 JIT 的作用还是非常大的。测试环境是 Mac M1-Max, 64G 的内存,10cores 硬件环境。TPCH 版本是 3.0.1,PG版本是12.11。
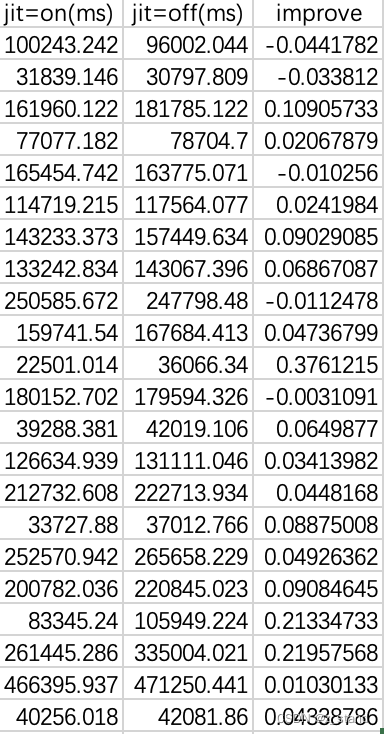
有一些场景开启 JIT 之后 性能还略差一些,不过并没有差很多,基本在1%-4% 之间。
LLVM JIT PG 中的实现流程
直接看下面的草图,JIT 的过程主要是和优化器以及执行器相关:
- 深绿色部分是PG 优化器或者执行器的代码
- 浅绿色部分是 PG 实现的调度 llvm jit 的函数
- 黄色部分 是内存相关的
- 红色部分 是IR相关的,也是性能优化的核心
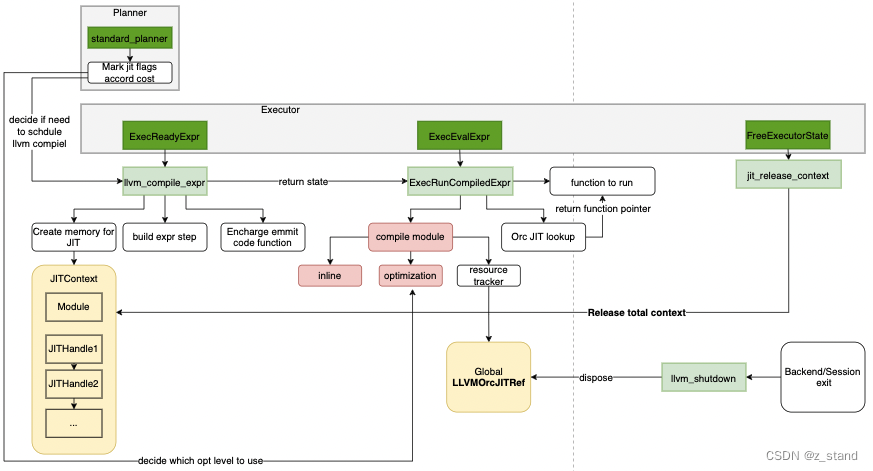
利用这个图来描述整个JIT 的PG侧实现就非常容易理解了。
大体过程 以及相关的实现代码 如下。
1. 根据 Planner cost 写入相关 JIT调度 标识
Planner 生成查询计划的时候会有一些cost 预估,这里会根据cost 来写入一些jit 的flags。包括:
是否调度JIT(PGJIT_PERFORM),是否开启LLVM-IR -O3优化(PGJIT_OPT3),是否开启inline(PGJIT_INLINE),是否开启表达式优化(PGJIT_EXPR),是否开启元组变型优化(PGJIT_DEFORM)。因为 opt和inline 都是在 LLVM IR阶段做的,生成IR 的内存表示过程中可以做inline,生成好的module 可以通过IR optimizer进一步优化,所以两者的触发条件默认是一样的。
PlannedStmt *
standard_planner(Query *parse, int cursorOptions, ParamListInfo boundParams)
{
...
/* 开启JIT,且 above_cost >0,且优化器生成的plan的 cost也要超过 above_cost */
if (jit_enabled && jit_above_cost >= 0 &&
top_plan->total_cost > jit_above_cost)
{
result->jitFlags |= PGJIT_PERFORM;
/*
* Decide how much effort should be put into generating better code.
*/
if (jit_optimize_above_cost >= 0 &&
top_plan->total_cost > jit_optimize_above_cost)
result->jitFlags |= PGJIT_OPT3;
if (jit_inline_above_cost >= 0 &&
top_plan->total_cost > jit_inline_above_cost)
result->jitFlags |= PGJIT_INLINE;
/*
* Decide which operations should be JITed.
*/
if (jit_expressions)
result->jitFlags |= PGJIT_EXPR;
if (jit_tuple_deforming)
result->jitFlags |= PGJIT_DEFORM;
}
...
}
2. 执行器初始化 plan ,初始化JIT 资源
这一步会通过 执行器的底层函数 ExecReadyExpr 调用到 llvm_compile_expr。对于 JIT来说,因为默认使用的是llvm 编译器,所以主要是初始化后续 llvm JIT 资源管理 需要的一些变量,并且根据当前PlanState 的 opcode 来构造 IR 需要的BasicBlock,会填充函数/函数内部的变量/函数参数等信息。
这一步在JIT 的实现中重心是三个功能:
-
创建管理当前PlanState 后续执行过程中需要的内存数据结构。
主要通过llvm_create_context创建LLVMJitContext,其重要的部分字段如下typedef struct LLVMJitContext { JitContext base; // 保存flag信息,resource owner,统计信息。 /* number of modules created */ size_t module_generation; // 复用这个context时期生成来多少个module /* current, "open for write", module */ LLVMModuleRef module; // 当前表达式使用的module信息,IR 操作的部分 /* is there any pending code that needs to be emitted */ bool compiled; // 是否执行了 llvm orc jit的编译过程,没有则需要执行 ... /* list of handles for code emitted via Orc */ List *handles; // 一个context可能管理了多个module,每一个module // 完成 orc jit 编译之后会将module转为 thread safe // module,托管给 llvm resource tracker,统一放在 // JitHandle 链表中。方便表达后续执行完释放内存的时候 // 可以直接释放。 } LLVMJitContext;这个函数内部会初始化 llvm 后续IR解析 bitcode files 需要的一些targe ,还有通过
llvm_create_types获取 LLVM 能够识别到的符号信息到内存中,获取的途径是 bitcode files所在的路径中的llvmjit_types.bc文件。
将这个 .bc 文件通过llvm-dis工具转为ll 文件之后,能看到里面有大量的types类型
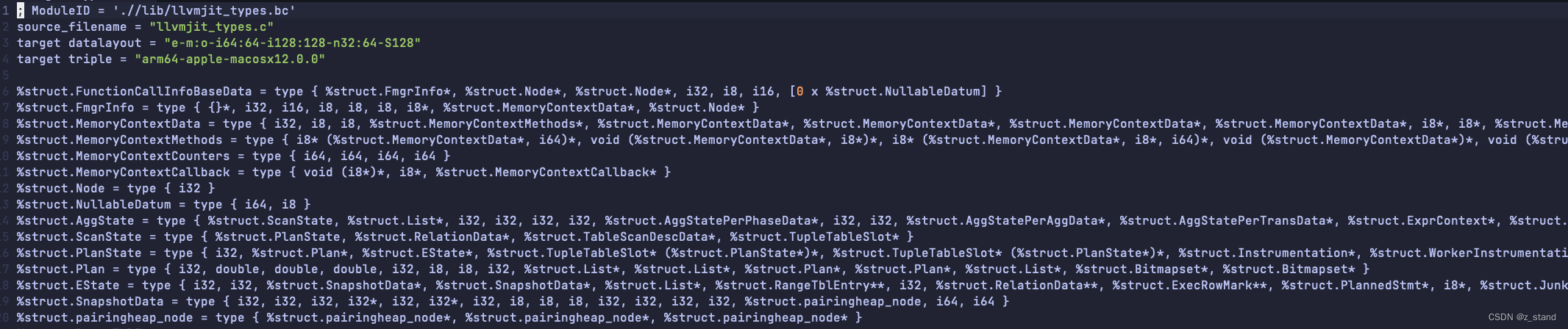
主要是标识postgresql 内部的数据结构 在当前平台的大小,这样在生成BasicBlock的内存表示的时候就能直接用了,通过load_type内部的 llvm相关的接口 取到所有的这一些JIT 过程需要的数据结构的type 之后 会放在全局变量中。初始化完type 之后还有非常重要的一个过程就是初始化 LLVM Orc JIT实例。
前面介绍 LLVM Orc JIT的时候也看到了 Orc JIT的一些基本用法,PG里面也是差不多,不过用的接口更多了一些。static void llvm_session_initialize(void) { ... llvm_create_types(); ... #if LLVM_VERSION_MAJOR > 11 { llvm_ts_context = LLVMOrcCreateNewThreadSafeContext(); llvm_opt0_orc = llvm_create_jit_instance(opt0_tm); opt0_tm = 0; llvm_opt3_orc = llvm_create_jit_instance(opt3_tm); opt3_tm = 0; } ... }这里还有一个
llvm_ts_context,是一个thread safe的LLVMOrcThreadSafeContextRef,用来在后续 编译module的时候 管理 thread safe的module,保证module访问的线程安全 以及 异常退出时的资源释放。llvm_create_context之后,会通过llvm_mutable_module创建一个module,可以看到如下函数,这里面就是我们介绍 llvm IR 表示的时候sum.ll中需要的一些字段:module_name,target datalayout,target triple都会在这里添加。LLVMModuleRef llvm_mutable_module(LLVMJitContext *context) { llvm_assert_in_fatal_section(); /* * If there's no in-progress module, create a new one. */ if (!context->module) { context->compiled = false; context->module_generation = llvm_generation++; context->module = LLVMModuleCreateWithName("pg"); LLVMSetTarget(context->module, llvm_triple); LLVMSetDataLayout(context->module, llvm_layout); } return context->module; }
下一步,就显而易见了,肯定是填充 Function, BasicBlocks 以及 Instruction 到Module中(这里并不会直接填充 对应函数的 basicblocks 以及 instruction,只是先填充function 以及 其需要的参数,后续inline 的过程拿到实际函数定义所在的 bc 文件 会进行 BB 和 instruction的生成,那个时候也才能进行分支优化)。
- 填充Module,整个过程就相当于将 后续要执行的表达式的函数以及参数 生成IR 在内存中能够识别的格式。
在llvm_compiled_expr有两千多行代码,都在做这个事情。
先填充的是function,function类型主要是plan执行相关的evalexpr,再利用第一步中llvm_create_types加载进来的类型 按照ExprState的op 类型将 function 需要参数填填充进去。
比如:
上面的逻辑就是根据op类型,会生成一个 function 到mod中,并将参数填充进去,参数就是case EEOP_PARAM_EXEC: build_EvalXFunc(b, mod, "ExecEvalParamExec", v_state, v_econtext, op); LLVMBuildBr(b, opblocks[i + 1]); break;v_state,v_econtext,op。因为函数ExecEvalParamExec本身也就这三个参数。
而像EEOP_SCAN_FETCHSOMEop类型,需要读tuple的 attr数据,就可以进行 tuple_deforming,则其逻辑会更复杂 一些:case EEOP_SCAN_FETCHSOME: { TupleDesc desc = NULL; LLVMValueRef v_slot; LLVMBasicBlockRef b_fetch; LLVMValueRef v_nvalid; LLVMValueRef l_jit_deform = NULL; const TupleTableSlotOps *tts_ops = NULL; /*从表达式的 ExprEvalStep 数据结构中获取对应字段的数据,并填充*/ b_fetch = l_bb_before_v(opblocks[i + 1], "op.%d.fetch", i); if (op->d.fetch.known_desc) desc = op->d.fetch.known_desc; ... /* 开启tuple deforming,将相关的 Function 以及 参数添加进来, 等待后续inline 的优化 */ if (tts_ops && desc && (context->base.flags & PGJIT_DEFORM)) { l_jit_deform = slot_compile_deform(context, desc, tts_ops, op->d.fetch.last_var); } ... - 填充 emmit function,控制实际 JIT 编译的时机在表达式执行的时候。
到这里可以看到 PG 的 OrcJIT 的实现是和前面案例比较接近的,属于 Lazy模式,不过整个过程是 PG 通过 LLVM Orc JIT 以及 LLVM IR相关 接口自己控制的。
这里llvm_compile_expr会填充后续 表达式执行的实际的优化函数:{ CompiledExprState *cstate = palloc0(sizeof(CompiledExprState)); cstate->context = context; cstate->funcname = funcname; state->evalfunc = ExecRunCompiledExpr; state->evalfunc_private = cstate; }
3. 执行器执行 Plan 执行 JIT 的编译
这一步是真正执行 plan 的时候,实际的执行是在 ExecEvalExpr 中 会通过 state->evalfunc 函数指针访问到前面的 ExecRunCompiledExpr 函数。
这个函数的宏观逻辑很简单:
static Datum
ExecRunCompiledExpr(ExprState *state, ExprContext *econtext, bool *isNull)
{
CompiledExprState *cstate = state->evalfunc_private;
ExprStateEvalFunc func;
CheckExprStillValid(state, econtext);
llvm_enter_fatal_on_oom();
func = (ExprStateEvalFunc) llvm_get_function(cstate->context,
cstate->funcname);
llvm_leave_fatal_on_oom();
Assert(func);
/* remove indirection via this function for future calls */
state->evalfunc = func;
return func(state, econtext, isNull);
}
核心函数是 llvm_get_function,可以理解为 PG 实现了 JIT 的lazy 过程,就是在执行器执行 plan 的时候再对表达式进行编译 和 优化。
在 llvm_get_function 中主要做下面几件事情:
- 检查 这个context 有没有被编译过(即经历过 inline 以及 optimize 的过程?),没有,则通过
llvm_compile_module进行编译(最前面流程图中的红色两部分)。 - 完成之后,用 context 管理的 handle 中的
LLVMOrcLLJITReflookup 指定的funcname。 - 返回找到的函数地址
所以优化的核心还是在llvm_compile_module 中,这个函数主要做的事情如下:
a. llvm_inline 进行 inline,即填充前面构造module是没有填充的 BasicBlocks 和 Instructions。这里会利用LLVM的module相关接口 扫描 module中的 function,找到function的 declaration 或者 defination 所在的bc文件,加载其中的BB 和 instruction(因为有一个postgres.index.bc,可以方便快速得找到某一个文件所在的路径 – 每一个内核源码.c文件会对应一个 .bc文件 ,也就是一个module)。
因为这个 函数内部还有可能调用其他的函数,其他的函数的定义/声明 不在当前bc文件内部的话(external function),也需要判断这个函数是否有必要添加到当前module,如果这个函数所在的分支不会走到,那就不需要加载了,这也是分支裁剪优化的主要部分。
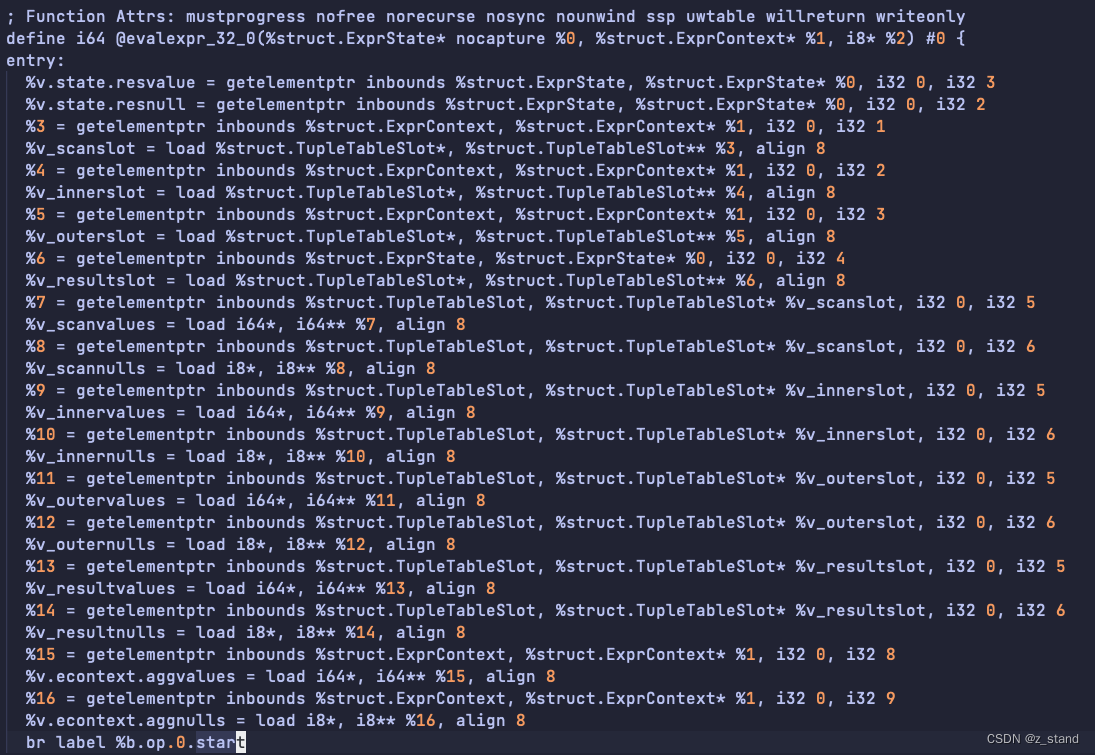
b. llvm_optimize_module 通过 LLVM IR optimizer 提供优化。里面会通过 IR Pass Manager来进行优化,会先优化 Function,再优化Module,完成优化之后会 Dispose前面创建的pass manager,这里是实际优化query性能的核心,关于如何优化的细节可以参考 PostgreSQL JI T 实现性能加速的一些补充。
inline 和 optimize 生成的module 都可以通过 guc : jit_dump_bitcode=on 开启, 开启之后会在 initdb 指定的data 目录下生成 procid.module_generation.bc 或者 procid.module_generation.optimize.bc 类似 : 57872.32.optimized.bc,这样我们就能看到 inline 和 optimize 之后module 的差异了。
从下面转换后的 ll 文件中能够看到 生成之后的执行函数已经没有 其他的函数调用了,全部是寄存器的访问和赋值操作,从而极大得简化了整个执行流程。
c. 将module 转为 TSM(ThreadSafe Module),并托管其内存资源到LLVMOrcLLJITRef 的 resource_tracker,这样做的目的是PG侧不用考虑 module的内存问题了,module 会随着 OrcJit 实例的析构被释放,或者用户指定释放也能够释放其占用的内存资源。主要是防止多个进程/线程访问module时的一致性问题,并且TSM 保证程序异常退出时占用的资源能够被释放( 大于 llvm11版本才会有这个特性)。
4. 释放内存资源
每一个表达式执行完成之后会尝试释放这个表达式能够释放的资源,像是context 内部的module(没有执行 inline的module,执行了inline & optimize 之后会被托管到handle链表中),以及 handle。
FreeExecutorState
--> jit_release_context
--> llvm_release_context
static void
llvm_release_context(JitContext *context)
{
...
/* 正常执行的 module 资源不会在这里释放。*/
if (llvm_context->module)
{
LLVMDisposeModule(llvm_context->module);
llvm_context->module = NULL;
}
/* 在这里释放,因为module 在llvm_compile_module 中被托管给了TSM,和resource_tracker
都赋值给了LLVMJitHandle,从而放在了context管理的hanle单链表中。
所以这里会扫描handle 并释放其资源。
当然这里不释放,会有内存泄漏,虽然当前session 进程退出时会释放jit所有的资源,包括OrcJIT实例,
但是如果这个session 持续跑sql,内存会一直上涨(module的资源并没有释放)
*/
while (llvm_context->handles != NIL)
{
LLVMJitHandle *jit_handle;
jit_handle = (LLVMJitHandle *) linitial(llvm_context->handles);
llvm_context->handles = list_delete_first(llvm_context->handles);
#if LLVM_VERSION_MAJOR > 11
{
LLVMOrcExecutionSessionRef ee;
LLVMOrcSymbolStringPoolRef sp;
LLVMOrcResourceTrackerRemove(jit_handle->resource_tracker);
LLVMOrcReleaseResourceTracker(jit_handle->resource_tracker);
/*
* Without triggering cleanup of the string pool, we'd leak
* memory. It'd be sufficient to do this far less often, but in
* experiments the required time was small enough to just always
* do it.
*/
ee = LLVMOrcLLJITGetExecutionSession(jit_handle->lljit);
sp = LLVMOrcExecutionSessionGetSymbolStringPool(ee);
LLVMOrcSymbolStringPoolClearDeadEntries(sp);
}
...
pfree(jit_handle);
}
}
5. Session 退出时释放 所有JIT资源
第四步并没有释放全局的 LLVMOrcLLJITRef 和 LLVMOrcThreadSafeContextRef,也就是一些 TSM 的资源又可能还没有被释放。
当前session 退出的时候能够保证所有 LLVMOrcLLJITRef 管理的资源都被释放,这也是为什么 在LLVM版本大于11之后,将内存资源的管理完全交给 LLVMOrcLLJITRef,这样它就能管理所有的 module 资源了,并且保证用户在来不及释放 module资源的时候 LLVMOrcLLJITRef一定能够释放。
其实现,是通过 before_shmem_exit 函数 注册 proc_exit 调用时 exit 之前要执行的函数。
static void
llvm_shutdown(int code, Datum arg)
{
/*
* If llvm_shutdown() is reached while in a fatal-on-oom section an error
* has occurred in the middle of LLVM code. It is not safe to call back
* into LLVM (which is why a FATAL error was thrown).
*
* We do need to shutdown LLVM in other shutdown cases, otherwise
* e.g. profiling data won't be written out.
*/
if (llvm_in_fatal_on_oom())
{
Assert(proc_exit_inprogress);
return;
}
#if LLVM_VERSION_MAJOR > 11
{
if (llvm_opt3_orc)
{
LLVMOrcDisposeLLJIT(llvm_opt3_orc);
llvm_opt3_orc = NULL;
}
// 保存 -O0 下的 OrcJIT 实例
if (llvm_opt0_orc)
{
LLVMOrcDisposeLLJIT(llvm_opt0_orc);
llvm_opt0_orc = NULL;
}
if (llvm_ts_context)
{
LLVMOrcDisposeThreadSafeContext(llvm_ts_context);
llvm_ts_context = NULL;
}
}
...
}
到此整个 PG 实现JIT的过程就描述完了,对于 OrcJIT的使用大体和 介绍LLVM Orc JIT 的案例时说的差不多,只不过PostgreSQL 的实现过程考虑的东西更全面一些,包括内存管理、和执行器的逻辑结合,异常安全 以及 最重要的 IR 和 IR optimizer 的调度,所以需要用到的接口更多,整体细节也会更多更复杂。
LLVM JIT 在PG 中的内存泄漏
这是最近关注到的一个问题, 也就是我们在一个session上开启 JIT 跑 百万以上的SQL,会发现RSS内存在持续上涨。排除了 PG MemoryContext 之后 通过 valgrind + massif 抓到的内存占用都是在llvm中。
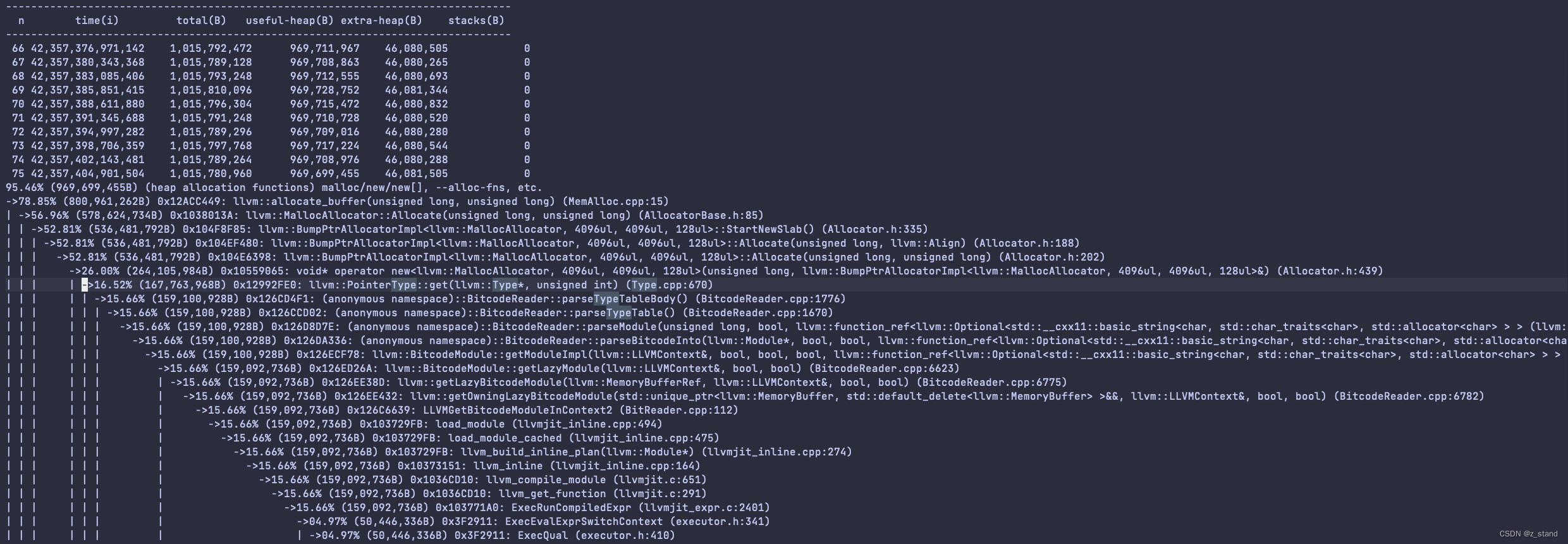
这其实不符合前面提到的 JIT内存管理部分的 逻辑,llvm_release_context 是在表达式执行完成之后就会释放 当前表达式执行过程 使用到的 Module。理论上除了执行当前SQL 需要加载page 到内存导致的短时间上涨之外,查询场景应该不会再有内存上涨的情况。
最后发现社区的活跃 issue列表中有这个问题:
原因是说llvm 加载 bitcode 中的数据到module中的时候会生成一堆types相关的数据,从上面的调用栈能看到是在分配 一个PointerType,实际后面的其他调用栈也都是在分配types 类型对应的存储空间,每一次执行表达式可能需要load不止一个bc文件,这个时候types会生成很多,但是LLVM 不会复用前面已有的一样的types 的内存数据,而是重新为当前module分配一个新的这个type要保存的空间,之前的这一些types 对应的内存空间其实都会被保存在 LLVMOrcLLJITRef中,运行了一段时间的 JIT 后会积累大量的这种 types 的无用数据。LLVM 之所以这么做 猜测:应该是为了性能,因为 每一个 modules 中的 types实在是太多了,想要在load 下一个module的时候复用上一个module中的types 类型,那就需要耗费CPU去查找,不如耗费一点内存去从磁盘上load,内存中按需分配。
用户想要释放这一部分内存的话,就 reset LLVMOrcLLJITRef,后面重新创建?
社区也是考虑这样的修复,只是太
darn yucky(恶心,不优雅)了。因为没有深入看过LLVM 这里的实现代码,不知道描述的这一部分问题原因是否是LLVM 本身实现上的考虑(不复用已存在于其他module的 types,而是直接为当前module分配新的)。
总结
经历了漫长而又痛苦的学习过程,才发现自己只是刚刚入门而已。
在 PostgreSQL 上做了很多 JIT 相关的测试,性能确实有可观的提升。而这样的提升在 计算密集的 AP 场景则会被放大很多,因为像分支裁剪 和 元组变型 这一些优化能够极大得简化其查询效率。在ClickHouse 这样的列存引擎 数据库中,存储引擎的高性能将瓶颈转移到了CPU侧,所以高并发下的CPU指令执行的多少,流水线是否不会中断得过多 都会有性能上的影响,而 LLVM IR + JIT能够极大得避免这种问题,在 CK infra-meeting 中能看到开发者对 JIT的介绍 :https://presentations.clickhouse.com/meetup53/jit_in_clickhouse/,极大得减少了cpu-cache-misses以及 cpu-cycles,而且在部分查询场景,性能甚至有20倍的提升。
参考
- Get Started With LLVM Core Libraries
- postgresql REL_12_STABLE 代码
- LLVM vs Libjit talk
- PG upstream JIT 内存问题
后续相关的分享会放在公众号里:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









