






大数据组件配置
1. 前置准备
1.1下载
- VMware下载
- liunx(centos)下载
- finalshell下载
1.2 安装
- VMware和finalshell正常安装即可
- 打开VMware
- 新建虚拟机
文件->新建虚拟机

依次点击下一步,到下图步骤选择稍后安装操作系统
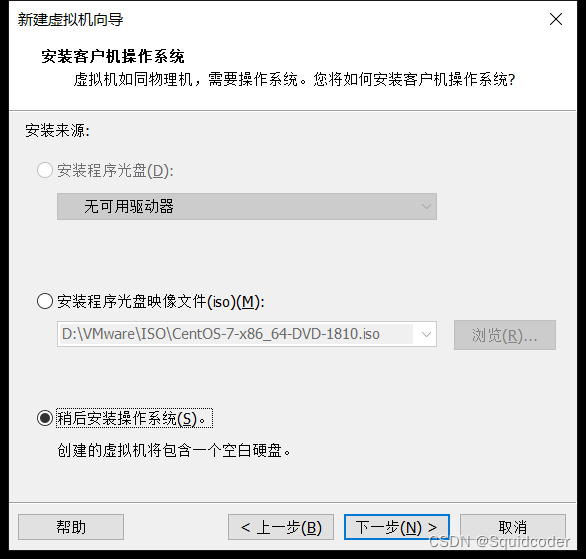
选择linux,版本centos7 64位
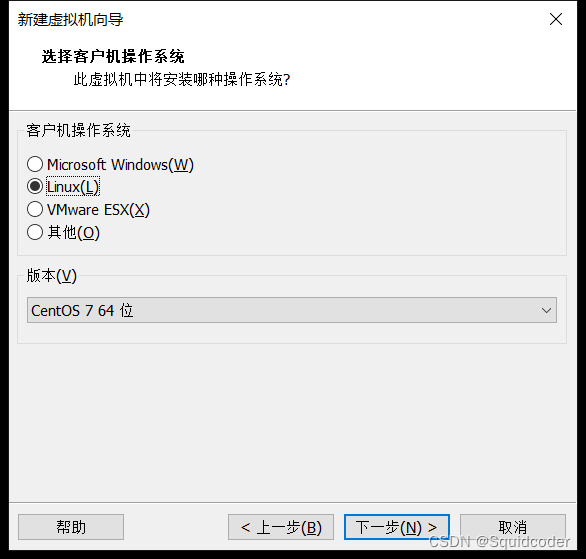
选择虚拟机磁盘的存放位置和名字
后续依次下一步确定即可(可自行设置虚拟机的硬件配置)
点击完成后,左侧‘我的计算机’显示刚安装的虚拟机
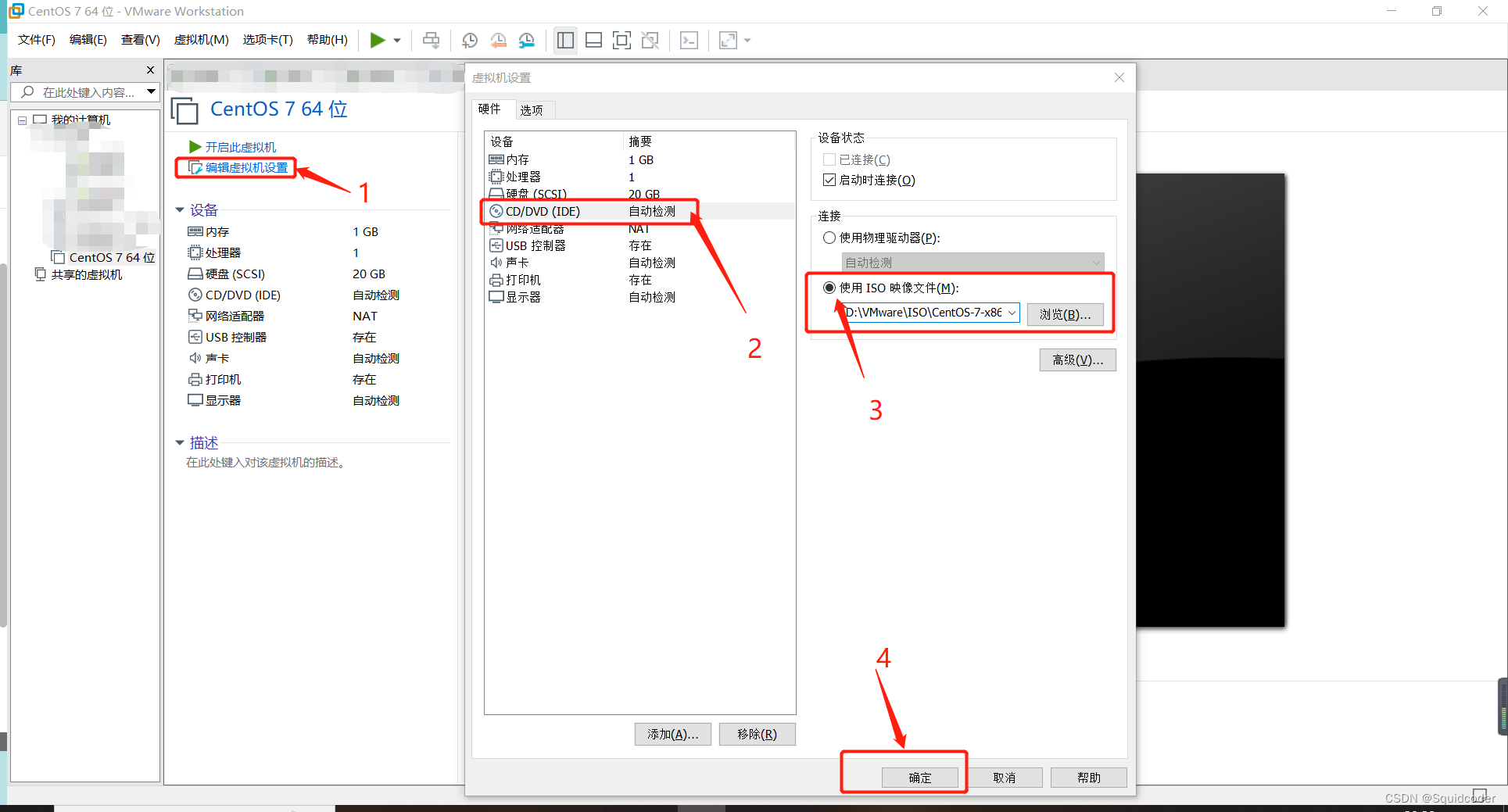
- 编辑虚拟机设置
依次点击 编辑虚拟机设置->CD/DVD->使用ISO镜像->浏览,选择下载的centos7的iso文件后点击确定
- 开启此虚拟机,依次点击确定
- 语言可选中文
- 系统安装位置需要点进去确认一下,才能点击开始安装按钮
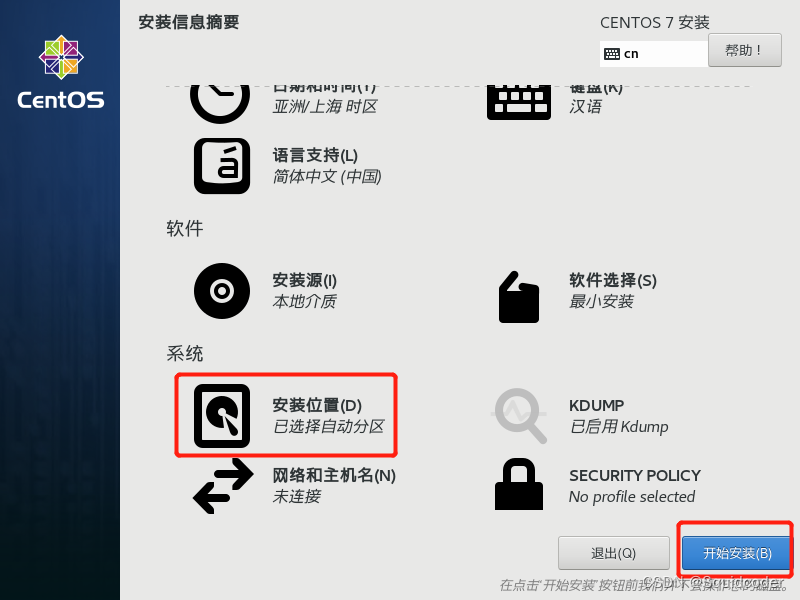
- 设置root密码。过于简单的密码需要点击两次完成。
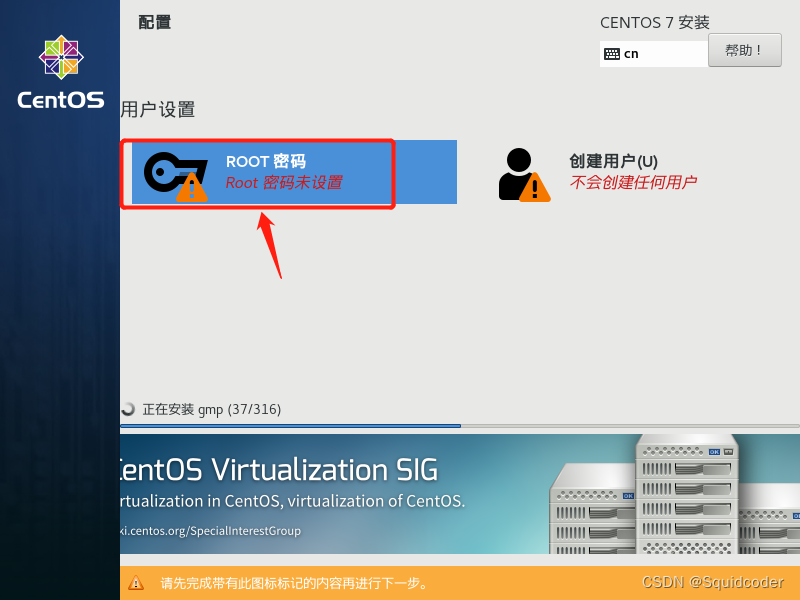
- 等待安装即可
1.3 配置
1.3.1 VMware网段设置
- 编辑->虚拟网络编辑器,点击VMnet8,更改设置
此操作需要管理员权限
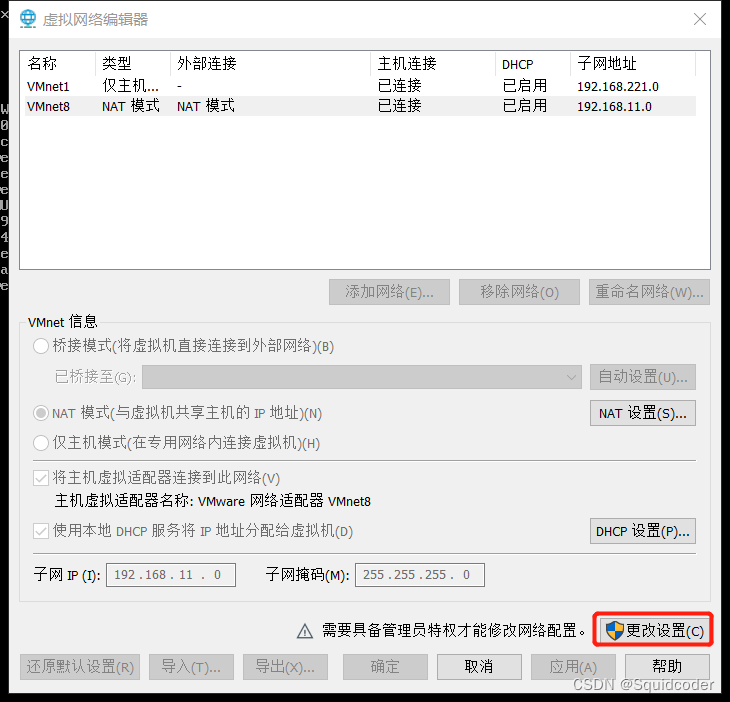
- 设置网络
子网:192.168.11.0
子网掩码:255.255.255.0
NAT设置->网关:192.168.11.2
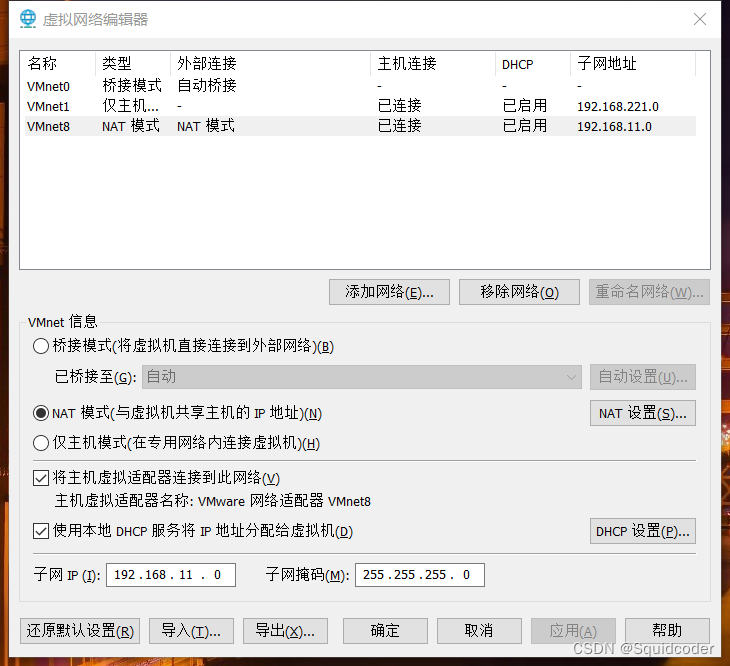
- 确定
1.3.2 liunx设置
- 打开liunx
- 输入账号密码
密码不显示在界面上,实际已经输入进去了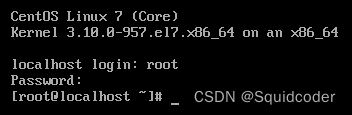
- IP设置
编辑网络设置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改为如下
(
BOOTPROTO由dhcp改为static
ONBOOT由no改为yes
新增: IPADDR=“192.168.11.131”
NETMASK=“255.255.255.0”
GATEWAY=“192.168.11.2”
DNS1=“192.168.11.2”
)
(进入文件后按i输入,esc退出输入,:q不保存退出,:wq保存并退出)
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=845fb44f-f628-4bc2-a6da-b096197cf088
DEVICE=ens33
ONBOOT=yes
IPADDR="192.168.11.131"
NETMASK="255.255.255.0"
GATEWAY="192.168.11.2"
DNS1="192.168.11.2"
- 重启
reboot
1.4配置SSH连接
- 打开FinalShell
- 点击左上角的连接管理器
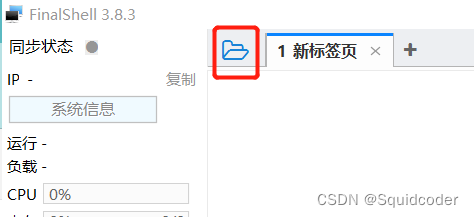
- 新建SSH连接
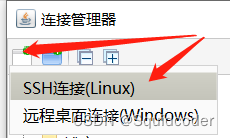
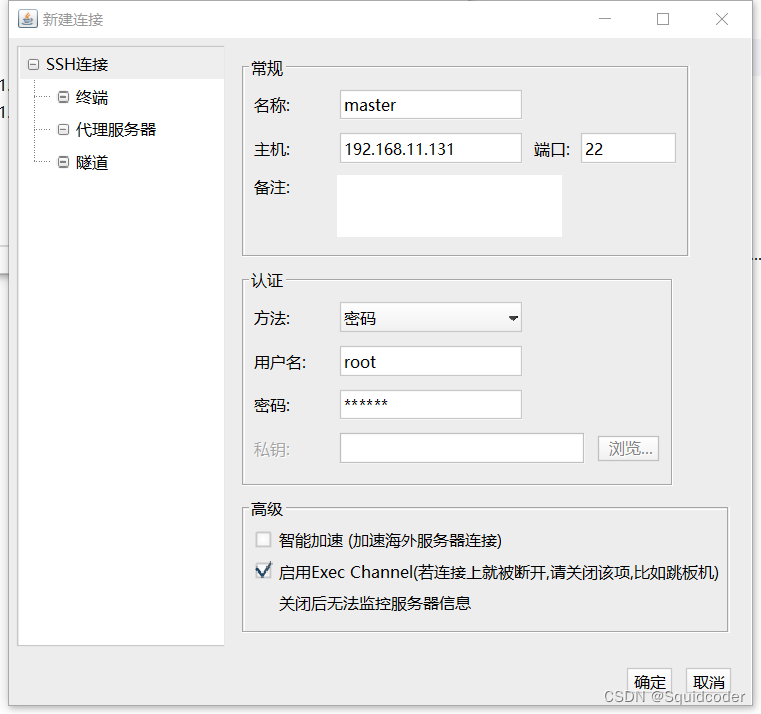
- 输入主机ip、账号、密码后点确定
- 双击即可连接上目标主机
2.Hadoop集群部署
2.1 master节点部署
部署单节点hadoop环境的只需部署此节点
2.1.1 jdk和hadoop下载
- jdk8下载
- hadoop3.3.4下载
官网
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
清华镜像
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4
2.1.2 jdk和hadoop安装
- 将jdk安装包通过FinalShell上传至/app/jdk
- 解压
tar -zxvf jdk-8u161-linux-x64.tar.gz
- 将hadoop安装包通过FinalShell上传至/app/hadoop
- 解压
tar -zxvf hadoop-3.3.4.tar.gz
- 配置环境变量
vim /etc/profile
追加如下配置
#java环境
export JAVA_HOME=/app/jdk/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#hadoop环境
export HADOOP_HOME=/app/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib/*
- 应用设置
source /etc/profile
7.验证
jdk验证
java -version
hadoop验证
hadoop version
2.1.3hadoop配置
- 添加主机映射
liunx下
vim /etc/host
增加如下字段
192.168.11.131 master
192.168.11.132 node1
192.168.11.133 node2
window下
打开C:\Windows\System32\drivers\etc目录,选择记事本打开hosts文件
增加如下字段
192.168.11.131 master
192.168.11.132 node1
192.168.11.133 node2
- 修改core-site.xml文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
增加如下字段
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
- 修改hadoop-env.sh文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
增加如下字段
export JAVA_HOME=/app/jdk/jdk1.8.0_161
export HADOOP_HOME=/app/hadoop/hadoop-3.3.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- 修改hdfs-site.xml文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
增加如下字段
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>master,node1,node2</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data/sn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
- 修改mapred-env.sh文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/mapred-env.sh
增加如下字段
export JAVA_HOME=/app/jdk/jdk1.8.0_161
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
- 修改mapred-site.xml文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/mapred-site.xml
增加如下字段
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce的运行框架设置为YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>历史服务器通讯端口为master:10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>历史服务 器web端口为master的 19888</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mrhistory/tmp</value>
<description>历史信息在HDFS的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在HDFS的记录路径</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为HADOOP HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为HADOOP_HOME</description>
</property>
</configuration>
- 修改yarn-env.sh文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/yarn-env.sh
增加如下字段
export JAVA_HOME=/app/jdk/jdk1.8.0_161
export HADOOP_HOME=/app/hadoop/hadoop-3.3.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- 修改yarn-site.xml文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/yarn-site.xml
增加如下字段
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>ResourceManager设置在master节点</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce程席开启Shuffle服务 </description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
<description>历史服务器URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>master:8089</value>
<description>代理服务器主机和端口</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
</configuration>
- 修改workers文件
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/workers
增加如下字段(不搭集群环境可不写node1、node2)
master
node1
node2
2.2 集群部署
2.2.3 节点克隆
- master节点关机
- 克隆master节点主机
选中master节点主机,右键->管理->克隆,依次点击下一步,在克隆方法这一步,务必选择创建完整克隆
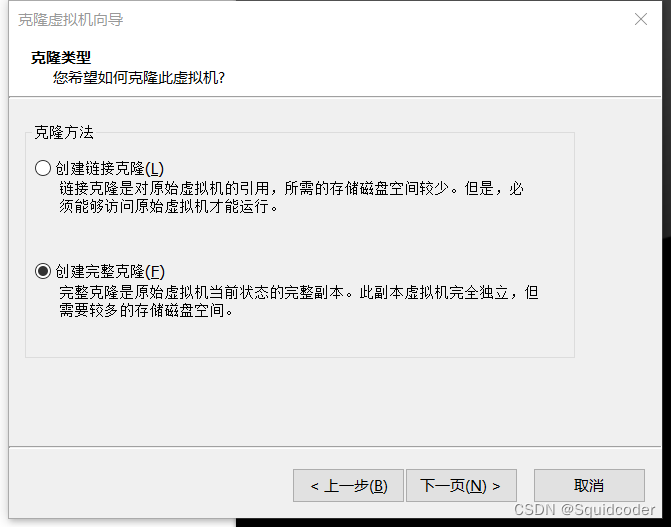
原主机重命名为master,分别克隆两台主机,命名为node1,node2。 - master节点的内存可修改大一些,开机
2.2.3 修改node节点IP
- 修改主机IP
node1、node2
vi /etc/sysconfig/network-scripts/ifcfg-ens33
将IPADDR=“192.168.11.131”的IP作修改,node1改为192.168.11.132,node2改为192.168.11.133
- 重启网卡
node1、node2
systemctl restart network
- 此时可以FinalShell连接上三台主机
2.2.3 修改主机名
- 修改主机名
master、node1、node2
分别执行
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node1
2.2.3 配置SSH免密登录、创建hadoop用户
- 配置root用户的SSH免密登录
1)master、node1、node2 都执行
ssh-keygen -t rsa -b 4096
然后一路回车
2)master、node1、node2 都执行
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
3)执行完毕后,实现 master、node1、node2 之间root用户的免密登录
- 创建hadoop用户(后续大数据相关的操作均通过hadoop用户提交)
1)master、node1、node2 都执行
创建账户
useradd hadoop
设置密码
passwd hadoop
切换到hadoop用户
su - hadoop
- 配置hadoop用户SSH免密登录,同上面root用户配置
2.2.5 关闭防火墙和SELinnx
(记得切换root用户)
- 关闭防火墙和开机自启
master、node1、node2 都执行
systemctl stop fiewalld
systemctl disable fiewalld
- 关闭SELinnx
master、node1、node2 都执行
vim /etc/sysconfig/seliunx
将第七行,*SELIUNX=enforcing*改为*SELIUNX=disabled*
2.2.6 时间同步
(记得切换root用户)
- 安装ntp软件
master、node1、node2 都执行
yum install ntpdate -y
- 同步window当前时间
master、node1、node2 都执行
ntpdate time.windows.com
- 重启三台机器
master、node1、node2 都执行
reboot
2.3 启动hadoop集群并查看状态
(记得切换hadoop用户)
2.3.0 初始化集群
hadoop namenode -format
2.3.1 启动集群
- 启动HDFS
start-dfs.sh
- 启动YARN
start-yarn.sh
- 历史服务器
mapred --daemon start historyserver
2.3.2 查看节点
- 查看当前的java进程
jps
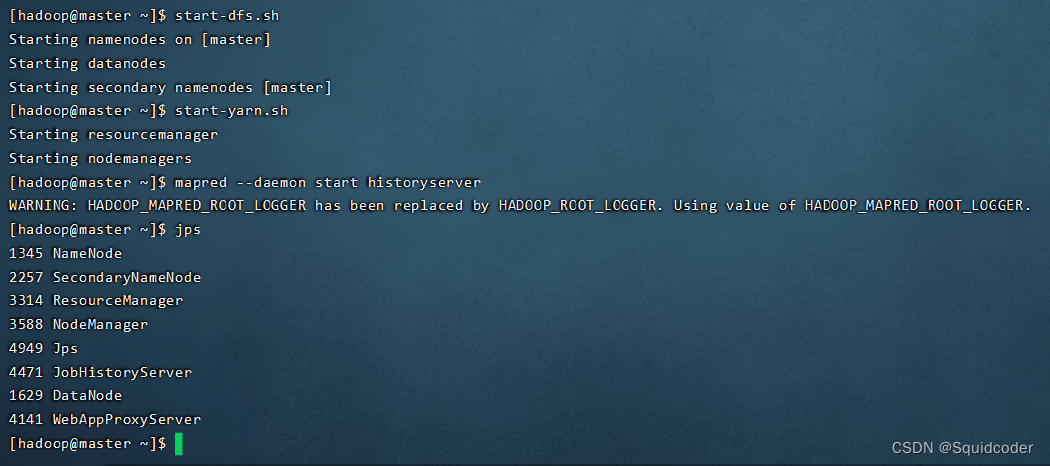
- 查看hdfs
master:9870
- 查看yarn
master:8088
- 查看hadoop历史服务器
master:19888
2.4 idea直连liunx文件
2.5 图形化界面查看HDFS文件系统
(务必已启动hadoop集群)
此处以idea为例,datagrip和pycharm同理
2.5.0 前置准备-window下安装hadoop
- 由于内部通讯节点8020只能hadoop内部使用,外部无法访问。但是我们可以通过在window安装hadoop,来实现内部端口对window本机开放。
- 将liunx下的hadoop安装包解压至指定位置
这里以D:\hadoop为例
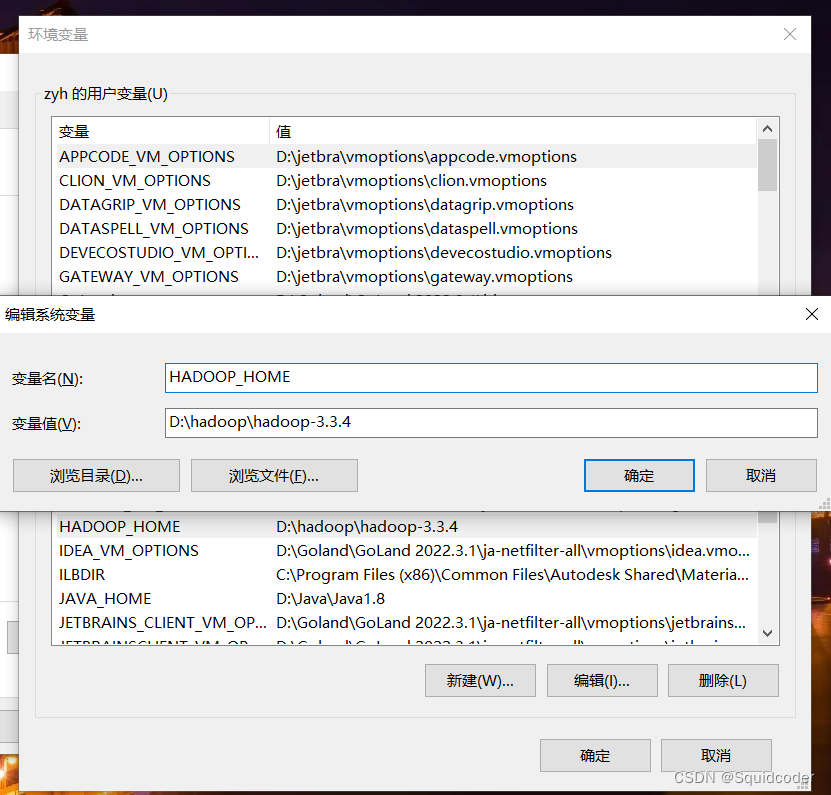
- 设置环境变量
将安装包下的bin包路径D:\hadoop\hadoop-3.3.4设为HADOOP_HOME
此电脑右键->属性->高级系统设置->环境变量
在系统环境变量新增下列字段
2.5.1 idea查看HDFS文件系统
-
文件->设置->插件
插件市场搜索big data tools,安装此插件 -
安装完成后,打开右侧边栏的标签,点击+号,选择HDFS
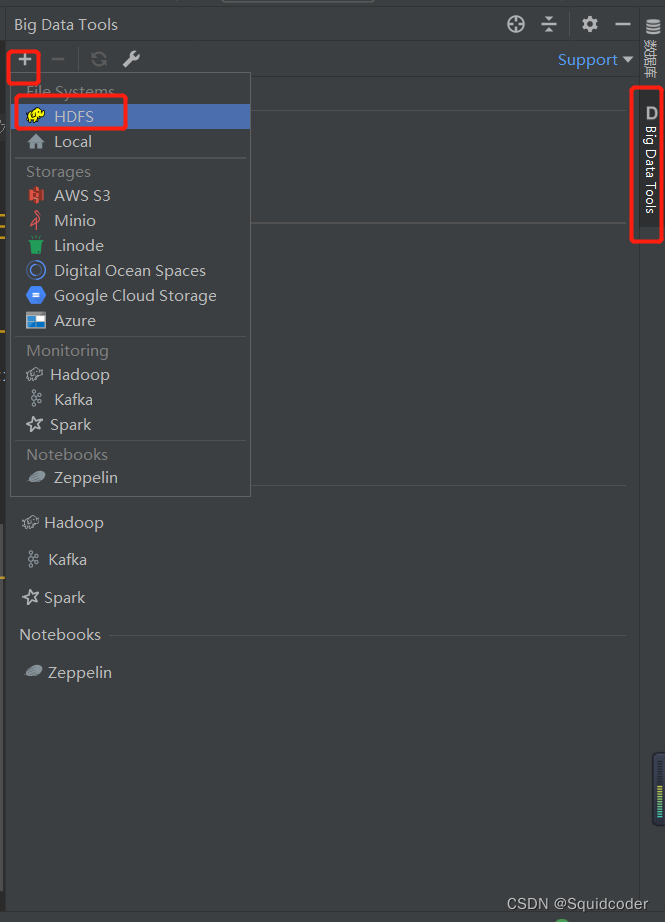
-
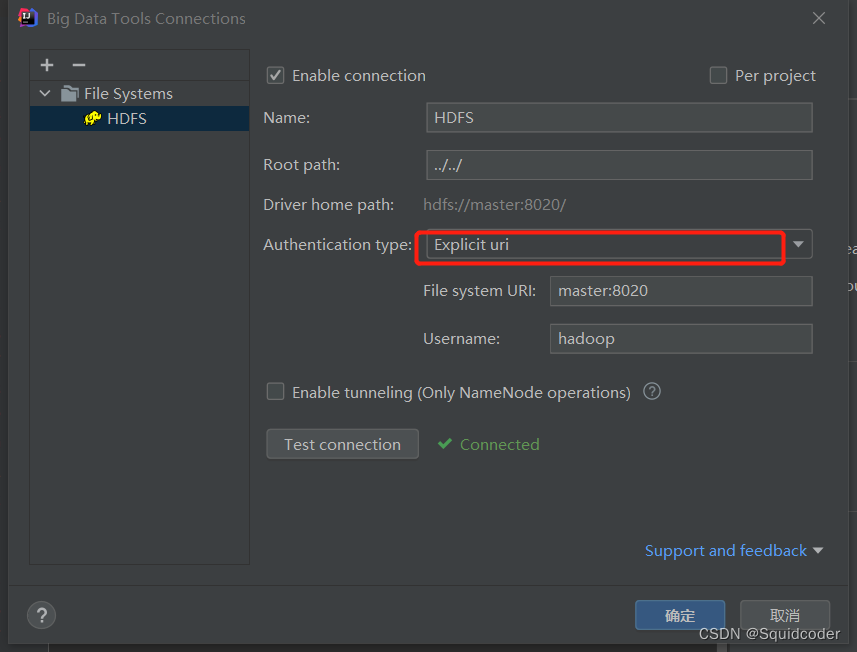
切换type为 Explicit uri,输入URI为:master:8020,用户名为hadoop,然后测试连接。
(若连接失败,请检查自己hadoop集群是否启动)
-
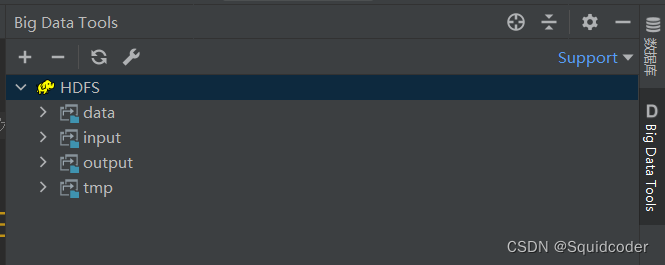
此时HDFS已经有文件显示了
(若一直转圈,可能是你HDFS文件系统下没有文件(夹))
2.5.1 注意事项
请勿直接用big data tools删除hdfs的文件,否则会进入hdfs安全模式,hdfs变为只读,退出安全模式命令:
hadoop dfsadmin -safemode leave
3.Hive安装和部署
3.1MySQL安装
在master节点使用yum在线安装MySQL5.7版本
- 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
- 安装MySQL yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
- yum 安装MySQL
yum -y install mysql-community-server
- 启动MySQL
systemctl start mysqld
- 设置开机启动
systemctl enable mysqld
- 检查MySQL状态
systemctl status mysqld
- 第一次启动会生成随机密码,查看密码
cat /var/log/mysqld.log | grep 'temporary password'
- 登录MySQL
mysql -uroot -p
- 输入复制的随机密码
- 降低密码等级
set global validate_password_policy=LOW;
- 修改密码最低位数
set global validate_password_length=4;
- 修改本机登录密码
ALTER USER 'root'@'localhost' identified by '123456';
- 修改远程登录密码
grant all privileges on *.* to root@"%" identified by '123456' with grant option;
- 刷新权限
flush privileges;
- 创建数据库hive
CREATE DATABASE hive CHARSET UTF8;
- 退出数据库
Ctrl+D
3.2 配置Hadoop
- Hive的运行依赖于Hadoop,配置Hadoop的代理用户
vim /app/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
新增如下字段
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
3.3Hive安装和启动
3.3.1 Hive下载
- 下载Hive安装包
https://archive.apache.org/dist/hive/hive-3.1.2/ - 上传至/app/hive,并解压
直接下载好的文件通过finalShell上传至目标位置
cd /app/hive
tar -zxvf apache-hive-3.1.2-bin.tar.gz
- 下载MySQL驱动包
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-
5.1.34.jar - 将下载好的驱动包放入hive安装文件夹的lib目录内
直接下载好的jar文件通过finalShell上传至目标位置
3.3.2. 配置hive
- 设置hive-env.sh
vim /app/hive/apache-hive-3.1.2-bin/conf/hive-env.sh
新增如下字段
export HADOOP_HOME=/app/hadoop/hadoop-3.3.4
export HIVE_HOME=/app/hive/apache-hive-3.1.2-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=$HIVE_HOME/lib
- 配置hive-site.xml
vim /app/hive/apache-hive-3.1.2-bin/conf/hive-site.xml
新增如下字段
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.server2.thrift.bing.host</name>
<value>master</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
- 配置环境变量
vim /etc/profile
新增如下
#hive环境变量
export HIVE_HOME=/app/hive/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
- 应用环境变量配置
source /etc/profile
3.3.3 hive初始化
- 初始化元数据库
cd /app/hive/apache-hive-3.1.2-bin/bin
./schematool -dbType mysql -initSchema -verbos
- 创建日志文件夹
mkdir /app/hive/apache-hive-3.1.2-bin/logs
- 将hive权限赋予hadoop用户
chown -R hadoop:hadoop /app/hive
3.3.4 启动hive
- 切换为hadoop用户,进入目录
su - hadoop
记得先启动hadoop
- 启动元数据
前台启动
hive --service metastore
后台启动
nohup hive --service metastore >> /app/hive/apache-hive-3.1.2-bin/logs/metastore.log 2>&1 &
- 启动客户端,二选一
Hive Shell方式(可以直接写SQL)
hive
Hive ThriftServer方式(不可以直接写SQL,需要外部客户端连接使用)
hive --service hiveserver2
4.Spark安装和部署
4.1Anaconda3安装和启动
4.1.1Anaconda3下载与安装
- 下载
使用Anaconda3清华镜像
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh
- 运行安装包
sh /app/anaconda/Anaconda3-2021.05-Linux-x86_64.sh
根据提示按enter、yes和空格
- 安装目录选
/app/anaconda/Anaconda3-2021.05
- 安装完成后重新连接shell,显示如下,即为成功
(base) [root@master ~]#
4.1.2 配置和启动
- 配置国内镜像(清华镜像)
vim ~/.condarc
输入如下
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
- 创建pyspark虚拟环境,输入如下
conda create -n pyspark python=3.8
根据提示确认即可
- 切换为pyspark虚拟环境
conda activate pyspark
4.2 Spark-Local模式
4.2.1 Spark下载与安装
- 下载地址
https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
- 上传至liunx的/app/spark,解压
tar -zxvf spark-3.4.0-bin-hadoop3.tgz
- 配置环境变量
vim /etc/profile
新增如下字段
#spark环境变量
export SPARK_HOME=/app/spark/spark-3.4.0-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export SPARK_CONF_DIR=$SPARK_HOME/conf
export PYSPARK_PYTHON=/app/anaconda/Anaconda3-2021.05/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
- 配置环境变量
vim /root/.bashrc
新增如下字段
export JAVA_HOME=/app/jdk/jdk1.8.0_161
export PYSPARK_PYTHON=/app/anaconda/Anaconda3-2021.05/envs/pyspark/bin/python3.8
- 应用配置
source /etc/profile
4.2.1 Spark-Local模式启动
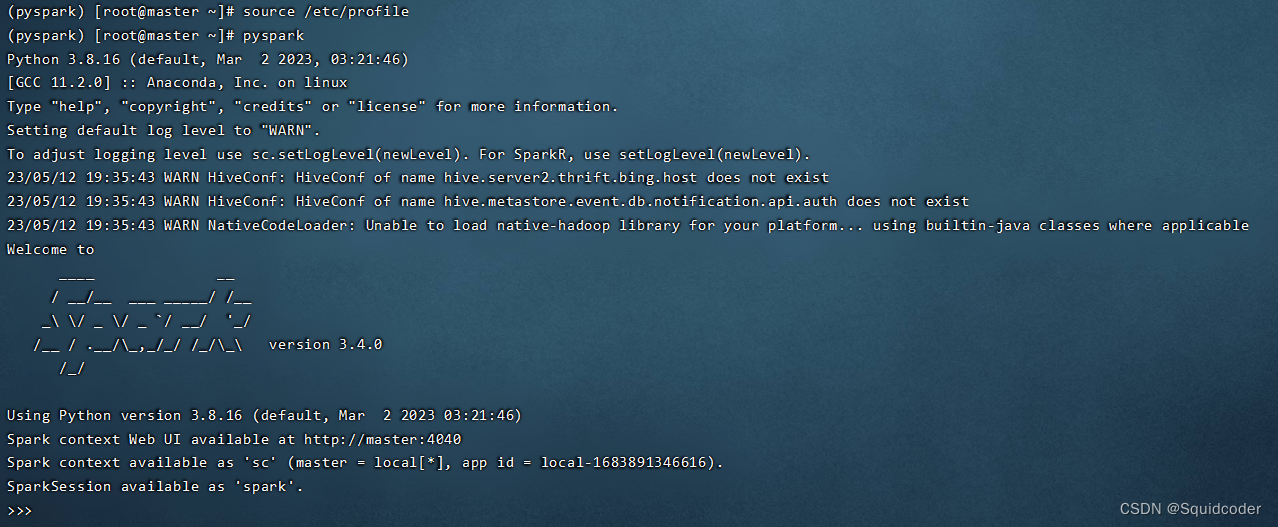
- 启动pyspark
pyspark
4.3 Spark-Standalone集群
4.3.1 node节点安装Anaconda
- node节点新增目录anaconda
node1,node2执行
mkdir /app/anaconda
- master复制anaconda安装包到node节点
master执行
scp /app/anaconda/Anaconda3-2021.05-Linux-x86_64.sh node1:/app/anaconda
scp /app/anaconda/Anaconda3-2021.05-Linux-x86_64.sh node2:/app/anaconda
- node节点执行anaconda安装和配置(参考4.1)
- node节点执行spark的配置(参考4.2)
4.3.2 master节点配置Spark
- 授予hadoop用户spark文件权限
chown -R hadoop:hadoop /app/spark
- 切换hadoop用户
su - hadoop
- 进入spark配置文件目录
cd /app/spark/spark-3.4.0-bin-hadoop3/conf
- 修改workers文件
修改文件后缀
mv workers.template workers
修改文件
vim workers
删除localhost
输入如下
master
node1
node2
- 配置spark-env.sh文件
修改文件后缀
mv spark-env.sh.template spark-env.sh
修改文件
vim spark-env.sh
追加如下内容
## 设置JAVA安装目录
JAVA_HOME=/app/jdk/jdk1.8.0_161
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/app/hadoop/hadoop-3.3.4/etc/hadoop
YARN_CONF_DIR=/app/hadoop/hadoop-3.3.4/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=master
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://master:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
- 在HDFS上创建程序运行历史记录存放的文件夹
hdfs dfs -mkdir /sparklog
hdfs dfs -chmod 777 /sparklog
- 配置spark-defaults.conf文件
修改文件后缀
mv spark-defaults.conf.template spark-defaults.conf
修改文件
vim spark-defaults.conf
追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://master:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
- 配置log4j.properties文件
可选,更改级别为WARN 只输出警告和错误日志
修改文件后缀
mv log4j2.properties.template log4j2.properties
修改文件
vim log4j2.properties
将rootLogger.level = info改为rootLogger.level = warn
4.3.4 master节点分发spark
master执行(权限不够的话,切换root用户)
scp -r /app/spark node1:/app/spark
scp -r /app/spark node2:/app/spark
4.3.5 StandAlone集群启动
- 启动历史服务器
start-history-server.sh
- 启动master进程
start-master.sh
- 启动workers进程
start-workers.sh
- 【可选】
start-all.sh可直接启动master进程和workers进程,但spark的start-all.sh和hadoop的start-all.sh都存在,会冲突,可重命名该文件
cd /app/spark/spark-3.4.0-bin-hadoop3/sbin
mv start-all.sh start-all-spark.sh
mv stop-all.sh stop-all-spark.sh
随后使用start-all-spark.sh、stop-all-spark.sh实现master进程和workers进程的一键启停
4.3.6 连接到StandAlone集群
- pyspark以StandAlone集群模式启动
pyspark --master spark://master:7077
4.3.7 查看节点
- 查看spark的历史服务器
master:18080
- 查看master和worker
master:8080
- 查看driver
(若占用,端口往后顺延,运行结束释放端口)
master:4040
4.4 Spark StandAlone HA 环境搭建
- 开启Zookeeper和hdfs集群
- 停止当前StandAlone集群
- 修改spark-env.sh
注释掉下面
SPARK_MASTER_HOST=master
新增如下
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,node1:2181,node2:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
- 分发配置到node1、node2
- 重新启动Spark StandAlone集群
- 在某个node节点上再启动一台master进程
4.5 Spark on Yarn 环境搭建
- 开启hdfs和yarn集群
- 停止当前StandAlone集群
- 开启Spark on Yarn
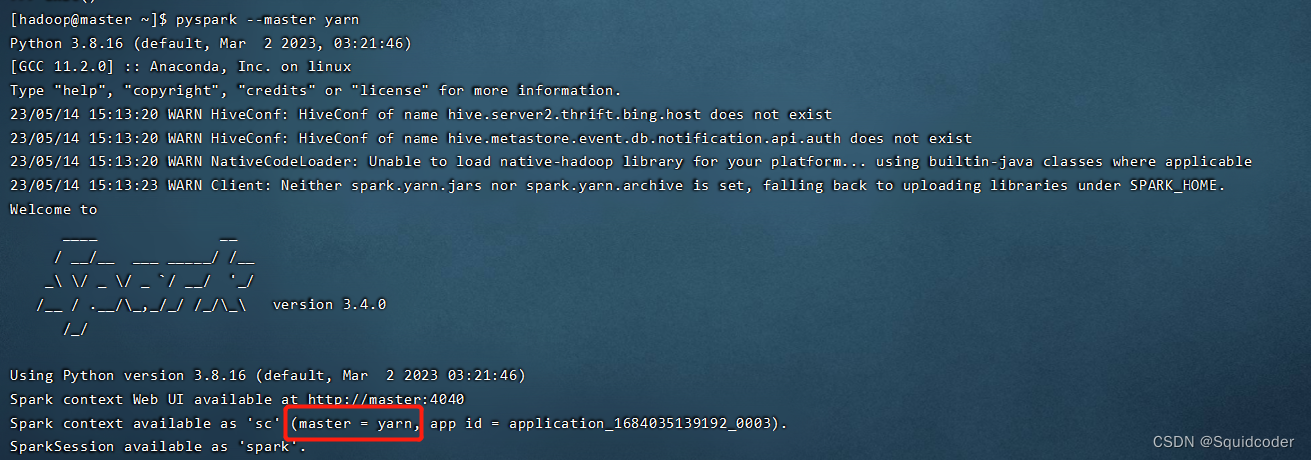
pyspark --master yarn
默认部署模式是 客户端模式
显示master = yarn即为成功
- 部署模式使用 集群模式
spark-submit --master yarn --deploy-mode cluster [任务]
注意: 交互式环境 pyspark 和 spark-shell 无法运行 cluster模式
4.6 PySpark类库安装
- 切换root
- 切换pyspark虚拟环境
conda activate pyspark
- 安装PySpark类库
master、node1、node2执行
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
4.7 Spark on hive
1.在spark的conf文件夹下新增hive-site.xml,新增如下内容
vim /app/spark/spark-3.4.0-bin-hadoop3/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
</configuration>
-
在spark的jars文件夹下,加上jdbc驱动包
下载地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-
5.1.34.jar -
开启spark-sql的守护进程
这里以设置端口号10000、在master以local模式启动为例
start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.host=master --master local[*]
然后就可以用datagrip等工具连接上了















 3205
3205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









