







题目链接:
Code
- 方法1
with pre as(
select customer_id,transaction_id
from Visits left join Transactions
on Visits.visit_id=Transactions.visit_id)
select customer_id,count(*) as count_no_trans
from pre
where transaction_id is null
group by customer_id;
- 方法2
select customer_id,count(*) as count_no_trans
from Visits
left join Transactions
on Visits.visit_id=Transactions.visit_id
where transaction_id is null
group by customer_id;
其实,以上两种方法没有太大的区别,法1相比于法2多使用了with,有中间过程->对于思考更有帮助吧。
所以接下来主要解释一下法2的思路。
解题思路
首先,必须先明确要求,理解题意。如果你是一个小白,得先看这道题的输出要求的列是哪些,然后看原始table的列名,并且理清楚table之间的关系,用最土的方式去看每个table到底记录了什么,table与table之间有什么关联。(这是做每道题前必须做的事情)
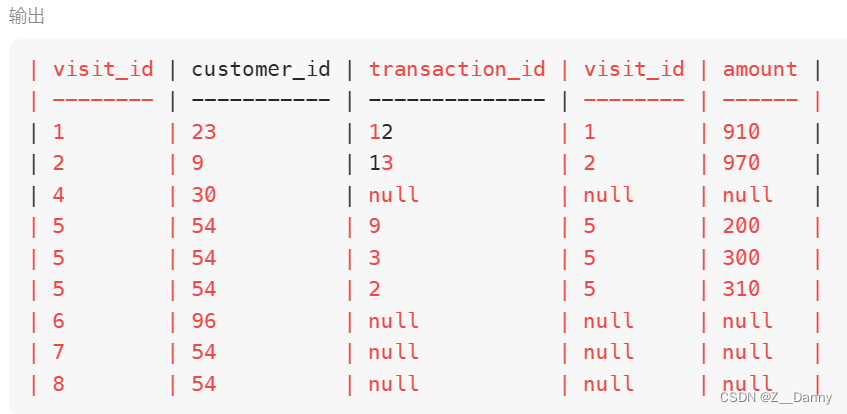
接着,我们来整体分析。左关联后的table如下,左边两列是table1的列,右边三列是table2的。每个顾客customer_id是不变的,每个顾客来超市1次就会有1个不一样的visit_id,而只有有交易记录的visit_id会出现在table2中,所以table1的visit_id>=table2的visit_id,左关联就可以让有来超市但是没有交易记录的visit_id后面3列变成null,这样我们就可以用null来筛选。一个顾客可能有多个visit_id有null值,所以我们要用group by,就可以把每个顾客只来超市但没有交易的次数用count()函数计算出来。
Code逐句分析
select customer_id,count(*) as count_no_trans
select是选择后面的两列展示(列名为customer_id 和 count_no_trans),其中as的作用就是把后面的count_no_trans 当作 count()*的别名biascount()可以计算 row 数,*是通配符
from Visits
left join Transactions
on Visits.visit_id=Transactions.visit_id
from ...left join...on...的作用是把 Visits 和 Transactions 两个table左关联起来,关联的条件就是on后面的内容,让table1的 visit_id 匹配table2的 visit_id 。因为左关联以第一个table为主,右边和左边不匹配的全部变成null值
where transaction_id is null
group by customer_id;
where筛选出transaction_id是null值的rowgroup by跟在where后面就是,以每个不同的customer_id为研究对象,计算出现的行
结语
就先这样,语言后面有空再慢慢修改了。















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









