







文章目录
前言
随着各大企业数字化转型的不断推进,RPA这门技术也越来越重要,很多人都开启了RPA学习,本文就介绍了RPA的基础内容。
一、cssSelector
通过cssSelector获取元素是最简单的一种方法:
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
eles = brower.find_elements_by_css_selector("p:nth-child()") # cssSelector查找多元素,即p标签下的th子标签
for ele in eles: # 操作各元素
ele.click()
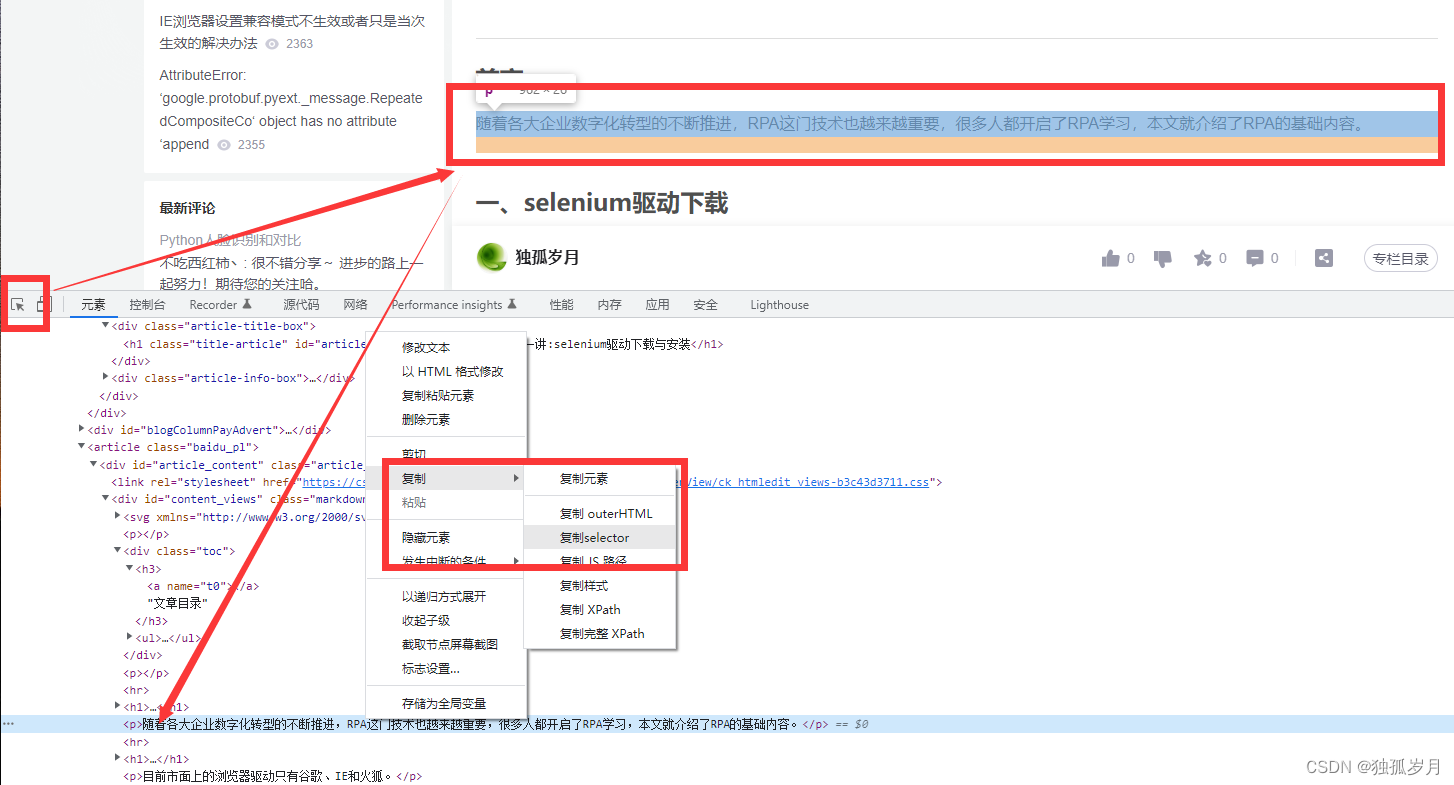
如图:
1、浏览器中按下F12,打开开发者页面,
2、点击开发者页面左上角箭头,再点击要查询的元素(标签p),自动跳转到元素在代码中的位置
3、鼠标右击元素,依次选择 复制=>复制selector
4、得到"#content_views > p:nth-child(7)",粘贴至代码中
二、XPath
1、直接使用XPath
步骤与cssSelector一致:
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
eles = brower.find_elements_by_xpath("//*[@id='content_views']/p") # xpath查找元素id为content_views的下的p标签
eles = brower.find_elements_by_xpath("/html/body/div[3]/div[1]/main/div[1]/article/div[1]/div[1]/p") # xpath全路径查找元素
for ele in eles: # 操作各元素
ele.click()
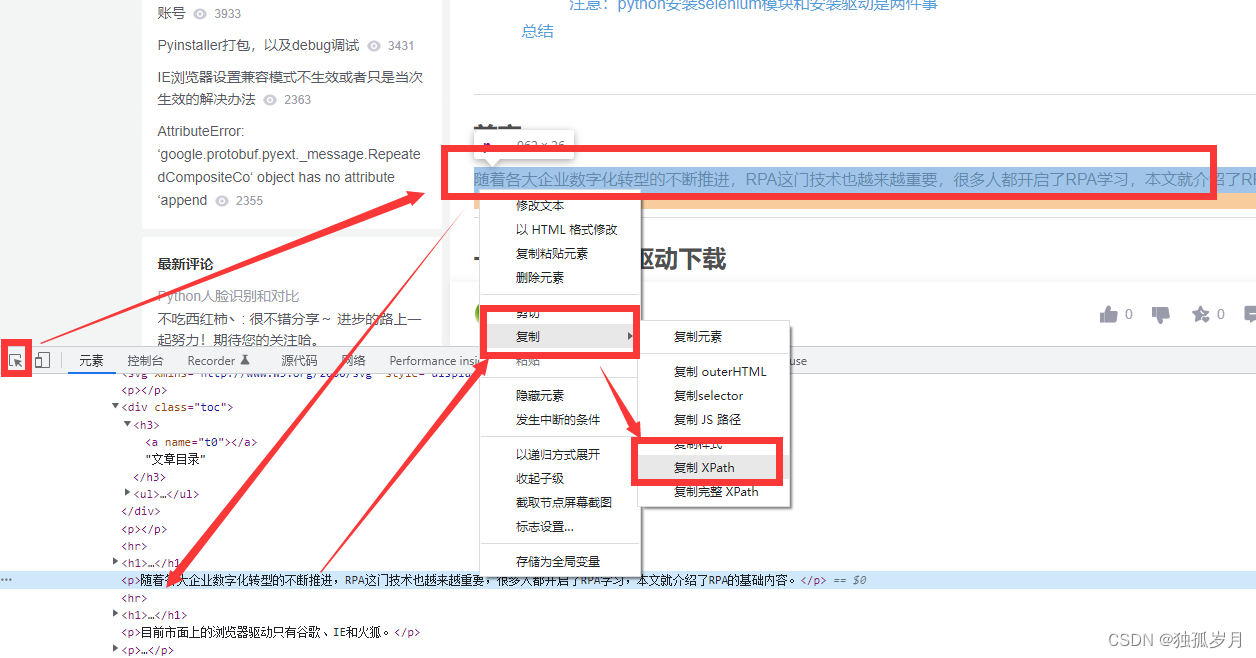
如图:
1、浏览器中按下F12,打开开发者页面,
2、点击开发者页面左上角箭头,再点击要查询的元素(标签p),自动跳转到元素在代码中的位置
3、鼠标右击元素,依次选择 复制=>复制XPath
4、得到"//*[@id=“content_views”]/p[3]",粘贴至代码中
5、【复制XPath】只是复制元素的相对路径,【复制完整XPath】复制的是元素的全路径,对比结果如代码所示
2、XPath根据内容定位元素
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
brower.find_elements_by_xpath("//p[contains(text(), "随着各大企业数字化转型的不断推进")]") # 1、xpath根据内容查找,p标签的内容中包含某些内容(页面中具体内容不唯一,但是肯定包含某些字段时使用)
brower.find_elements_by_xpath("//p[contains(text(), "随着各大企业数字化转型的不断推进,RPA这门技术也越来越重要,很多人都开启了RPA学习,本文就介绍了RPA的基础内容。")]") # 2、xpath根据内容查找,p标签的内容中就是某些内容(页面中内容确定且唯一时使用)
brower.find_elements_by_xpath("//*[contains(text(), "随着各大企业数字化转型的不断推进,RPA这门技术也越来越重要,很多人都开启了RPA学习,本文就介绍了RPA的基础内容。")]") # 3、xpath根据内容查找,标签不确定时使用(页面中内容确定且唯一)
brower.find_elements_by_xpath("//p[text()="数字化转型" and text()="RPA"]") # 4、xpath根据内容查找,(页面中可以确定的内容不连续时使用)
三、ID
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
brower.find_elements_by_id("_5") # 当元素存在id属性时使用
四、class
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
brower.brower.find_elements_by_class_name('t1') # 当元素存在class属性并且页面内class标签内容唯一时使用
五、name
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
brower.brower.find_elements_by_name('t1') # 当元素存在name属性并且页面内name属性唯一时使用
六、tag name
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
brower.brower.find_elements_by_tag_name('p') # 根据元素的标签属性查找元素
七、超链接内容
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
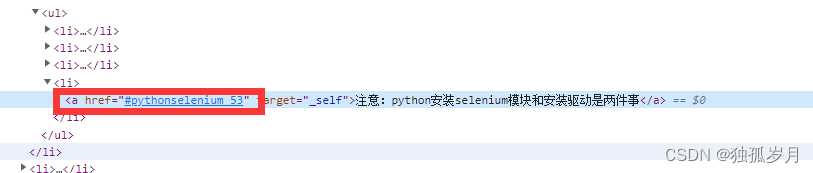
brower.find_elements_by_link_text('注意:python安装selenium模块和安装驱动是两件事') # 当元素是a标签或者标签内存在href等可以跳转的链接时使用
如图所示:
八、超链接内容的部分匹配
代码如下(示例):
from selenium import webdriver
brower = webdriver.Chrome(options=option) # 打开谷歌浏览器
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.maximize_window() # 最大化谷歌浏览器窗口
brower.find_elements_by_partial_link_text('注意:python') # 当元素是a标签或者标签内存在href等可以跳转的链接时使用,只需要标签的部分内容即可
九、自定义查找
代码如下(示例):
from selenium import webdriver
from selenium.webdriver.common.by import By
brower = webdriver.Chrome(options=option)
brower.implicitly_wait(10) # 查找元素的默认等待时间是10s
brower.get('https://blog.csdn.net/Z_baihang/article/details/126538978?spm=1001.2014.3001.5501') # 打开网址
brower.find_elements(By.ID, 'id') # 通过id
brower.find_elements(By.XPATH, 'xpath') # 通过xpath
brower.find_elements(By.NAME, 'name') # 通过name
brower.find_elements(By.TAG_NAME, 'tagName') # 通过tag name
brower.find_elements(By.CSS_SELECTOR, 'css') # 通过cssSelector
brower.find_elements(By.CLASS_NAME, 'className') # 通过class name
brower.find_elements(By.LINK_TEXT, 'linkText') # 通过link text
brower.find_elements(By.PARTIAL_LINK_TEXT, 'partialLinkText') # 通过 partial link text
总结
以上是selenium获取单个元素的方法总结。














 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









