







下载后的KEEL数据集用记事本打开会看到数据最上面有@符号的是文件头信息
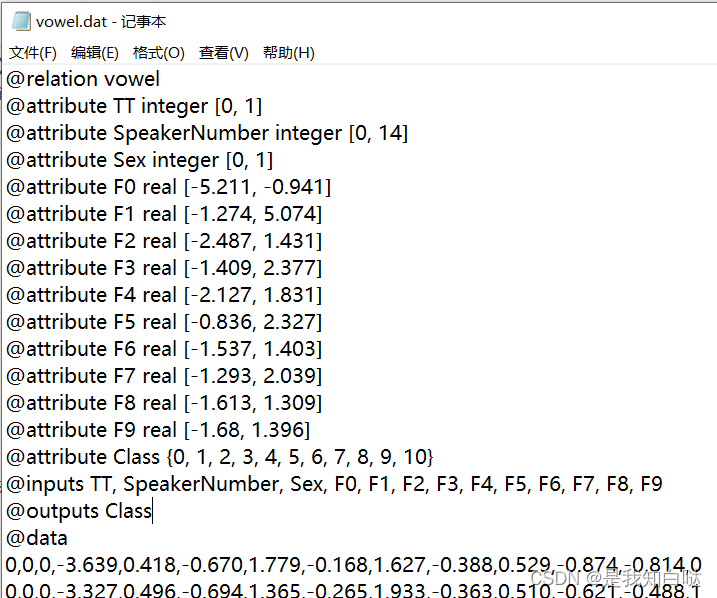
1. @relation vowel 表示数据集的名称为vowel。
2. @attribute 后面跟着的是每个属性(即特征)的定义,包括属性名称、属性类型和属性取值范围等信息。例如,@attribute F0 real [-5.211, -0.941] 表示属性F0是一个实数类型,其取值范围在[-5.211, -0.941]之间。
3. @inputs 和 @outputs 分别定义输入和输出特征的名称,这里分别是TT, SpeakerNumber, Sex, F0, F1, F2, F3, F4, F5, F6, F7, F8, F9 和 Class。
4. @data 表示数据部分开始,后面的行都是数据记录,每行包含一个样本的特征值和对应的输出(即标签)。
使用pandas打开这个数据集:
import pandas as pd
# 读取数据文件并提取数据部分
data_lines = []
with open('D:/Users/Admin/Desktop/vowel.dat', 'r') as file:
for line in file:
if line.strip() == '@data':
break
for line in file:
data_lines.append(line.strip().split(',')) # 使用逗号作为字段分隔符
# 获取属性名列表
attribute_names = ['TT', 'SpeakerNumber', 'Sex', 'F0', 'F1', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8', 'F9', 'Class']
# 为DataFrame的列命名
df = pd.DataFrame(data_lines, columns=attribute_names)
# 输出DataFrame
print(df)















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









