







一、什么是集合
集合就是相同类型的元素的有序合集。它一个通用的概念,其中包含了列表、数组和其他相似的数据类型。每一个元素都有唯一的下标来标识当前元素在集合中的位置。PL/SQL提供了以下几种集合类型:
- 索引表,也称为关联数组,可以让我们使用数字或字符串作下标来查找元素。(这有点和其他语言中的哈希表相类似。)
- 嵌套表可以容纳任意个数的元素,使用有序数字作下标。我们可以定义等价的SQL类型,把嵌套表存到数据库中去,并通过SQL语句进行操作。
- 变长数组能保存固定数量的元素(但可以在运行时改变它的大小),使用有序数字作为下标。同嵌套表一样,也可以保存到数据库中去,但灵活性不如嵌套表好。
虽热集合是一维的,但我们可以把一个集合作为另外一个集合的元素来建立多维集合。
要在应用程序中使用集合,我们要先定义一个或多个PL/SQL类型,然后声明这些类型的变量。我们可以在过程、函数或包中定义集合类型。还可以把集合作为参数在客户端和存储子程序之间传递数据。
要查找复杂类型的数据,我们可以在集合中存放PL/SQL记录或SQL对象类型。嵌套表和变长数组也可以作为对象类型的属性。
1、理解嵌套表
在数据库中,嵌套表可以被当作单列的数据表来使用。Oracle在往嵌套表中存放数据时是没有特定顺序的。但是,当我们把检索出来的数据存放在PL/SQL变量时,所有行的下标就会从1开始顺序编号。这样,就能像访问数组那样访问每一行数据。
嵌套表有两个重要的地方不同于数组:
- 数组有固定的上限,而嵌套表是没有上界的。所以,嵌套表的大小是可以动态增长的。如下图:
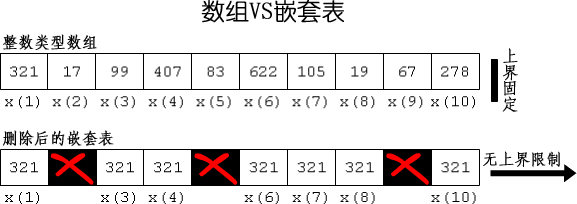
- 数 组必须是密集的(dense),有着连续的下标索引。所以我们不能从数组中删除元素。而对于嵌套表来说,初始化时,它是密集的,但它是允许有间隙的 (sparse),也就是说它的下标索引可以是不连续的。所以我们可以使用内置过程DELETE从嵌套表中删除元素。这样做会在下标索引上留下空白,但内 置函数NEXT仍能让我们遍历连续地访问所有下标。
2、理解变长数组
VARRAY被称为变长数组。它允许我们使用一个独立的标识来确定整个集合。这种关联能让我们把集合作为一个整体来操作,并很容易地引用其中每一个元素。下面是一个变长数组的例子,如果我们要引用第三个元素的话,就可以使用Grade(3)。

变长数组有一个长度最大值,是在我们定义时指定的。它的索引有一个固定的下界1和一个可扩展的上界。例如变长数组Grades当前上界是7,但我们 可以把它扩展到8、9、10等等。因此,一个变长数组能容纳不定个数的元素,从零(空的时候)到类型定义时所指定的最大长度。
3、理解关联数组(索引表)
关联数组就是键值对的集合,其中键是唯一的,用于确定数组中对应的值。键可以是整数或字符串。第一次使用键来指派一个对应的值就是添加元素,而后续这样的操作就是更新元素。下面的例子演示了如何使用关联数组:
DECLARE
TYPE population_type IS TABLE OF NUMBER
INDEX BY VARCHAR2 (64);
country_population population_type;
continent_population population_type;
howmany NUMBER ;
which VARCHAR2 (64);
BEGIN
country_population('Greenland' ) := 100000;
country_population('Iceland' ) := 750000;
howmany := country_population('Greenland' );
continent_population('Australia' ) := 30000000;
continent_population('Antarctica' ) := 1000; -- Creates new entry
continent_population('Antarctica' ) := 1001; -- Replaces previous value
which := continent_population.FIRST;
-- Returns 'Antarctica'
-- as that comes first alphabetically.
which := continent_population.LAST;
-- Returns 'Australia'
howmany :=
continent_population(continent_population.LAST);
-- Returns the value corresponding to the last key, in this
-- case the population of Australia.
END ;
/
关联数组能帮我们存放任意大小的数据集合,快速查找数组中的元素。它像一个简单的SQL表,可以按主键来检索数据。
因为关联数组的作用是存放临时数据,所以不能对它应用像INSERT和SELECT INTO这样的SQL语句。
4、全球化设置对使用VARCHAR2类型作主键的关联数组的影响
如果在使用VARCHAR2作为键的关联数组的会话中改变国家语言或全球化设置,就有可能引起一个运行时异常。例如,在一个会话中改变初始化参数 NLS_COMP或NLS_SORT的值后,再调用NEXT和PRIOR就可能会引起异常。如果我们必须在会话中更改这些设置的话,那么,在重新使用关联 数组的相关操作之前,就必须确保参数值被改回原值。
在用字符串作为关联数组的键的时候,声明时必须使用VARCHAR2、STRING或LONG类型,但使用的时候可以使用其他类型,如NVARCHAR2,VARCHAR2等,甚至是DATE,这些类型值都会被TO_CHAR函数转成VARCHAR2。
但是,在使用其他类型作为键的时候一定要慎重。这里举几个例子:当初始化参数NLS_DATE_FORMAT发生改变时,函数SYSDATE转成字 符串的值就可能发生改变,这样的话,array_element(SYSDATE)的结果就和先前的结果不一样了;两个不同的NVARCHAR2类型值转 成VARCHAR2值之后可能得出的结果是相同的,这样,数组array_element(national_string1)和 array_element(national_string2)可能引用同一个元素。
当我们使用数据库连接(database link)把关联数组作为参数传递给远程数据库时,如果两个数据库的全球化设置不一致,远程数据库会使用自己的字符顺序来调用FIRST和NEXT操作, 即使该顺序与原集合顺序不同。由于字符集的不同,就可能出现在一个数据库中两个不同的键在另一个数据库被当作同一个键处理的情况,这时程序就会收到一个 VALUE_ERROR异常。
二、集合类型的选择
如果我们有用其他语言编写的代码或业务逻辑,通常可以把其中的数组或集合直接转成PL/SQL的集合类型。
- 其他语言中的数组可以转成PL/SQL中的VARRAY。
- 其他语言中的集合和包(bags)可以转成PL/SQL中的嵌套表。
- 哈希表和其他无序查找表(unordered lookup table)可以转成PL/SQL中的关联数组。
当编写原始代码或从头开始设计业务逻辑的时候,我们应该考虑每种类型的优势,然后决定使用哪个类型更加合适。
1、嵌套表与关联数组间的选择
嵌套表和关联数组(原来称为索引表)都使用相似的下标标志,但它们在持久化和参数传递上有些不同的特性。
嵌套表可以保存到数据表字段中,而关联数组不可以。嵌套表适于存放能够被持久化的重要数据。
关联数组适用于存放较小量的数据,每次调用过程或包初始化时在内存中构建出来。它能够保存容量不固定的信息,因为它的长度大小是可变的。关联数组的索引值很灵活,可以是负数,不连续的数字,适当的时候还可以使用字符串代替数字。
PL/SQL能自动地将使用数字作为键的关联数组和主数组(host array)进行转换。集合和数据库服务器间数据传输的最有效的方法就是使用匿名PL/SQL块进行批量绑定数据绑定。
2、嵌套表与变长数组间的选择
在数据个数能够预先确定的情况下,使用变长数组是一个很好的选择。在存入数据库的时候,变长数组会保持它们原有的顺序和下标。
无论在表内(变长数组大小不到4k)还是在表外(变长数组大小超过4k),每个变长数组都被作为独立的一个对象对待。我们必须对变长数组中的所有元素进行一次性检索或更新。但对于较大量的数据来说,变长数组就不太适用了。
嵌套表是可以有间隙的:我们可以任意地删除元素,不必非得从末端开始。嵌套表数据是存放在系统生成的数据表中,这就使嵌套表适合查询和更新集合中的部分元素。我们不能依赖于元素在嵌套表中的顺序和下标,因为这些顺序和下标在嵌套表存到数据库时并不能被保持。
三、定义集合类型
要使用集合,我们首先要创建集合类型,然后声明该类型的变量。我们可以在任何PL/SQL块、子程序或包的声明部分使用TABLE和VARRAY类型。
集合的作用域和初始化规则同其他类型和变量一样。在一个块或子程序中,当程序进入块或子程序时集合被初始化,退出时销毁。在包中,集合在我们第一次引用包的时候初始化,直至会话终止时才销毁。
- 嵌套表
对于嵌套表,可以使用下面的语法来进行定义:
TYPE type_name IS TABLE OF element_type [NOT NULL ];
其中type_name是在集合声明使用的类型标识符,而element_type可以是除了REF CURSOR类型之外的任何PL/SQL类型。对于使用SQL声明的全局嵌套表来说,它的元素类型受到一些额外的限制。以下几种类型是不可以使用的:
- BINARY_INTEGER, PLS_INTEGER
- BOOLEAN
- LONG, LONG RAW
- NATURAL, NATURALN
- POSITIVE, POSITIVEN
- REF CURSOR
- SIGNTYPE
- STRING
- 变长数组
对于变长数组类型,可以使用下面的语法进行定义:
TYPE
type_name IS {VARRAY | VARYING ARRAY } (size_limit) OF
element_type [NOT NULL ];
type_name和element_type的含义与嵌套表相同。size_limit是正整数,代表数组中最多允许存放元素的个数。在定义VARRAY时,我们必须指定它的长度最大值。下例中,我们定义了一个存储366个DATE类型的VARRAY:
DECLARE
TYPE Calendar IS VARRAY(366) OF DATE ;
- 关联数组
对于关联数组,可以使用下面的语法进行定义:
TYPE type_name IS TABLE OF element_type [NOT NULL ]
INDEX BY [BINARY_INTEGER | PLS_INTEGER | VARCHAR2 (size_limit)];
INDEX BY key_type;
key_type可以是BINARY_INTEGER或PLS_INTEGER,也可以是VARCHAR2或是它的子类型VARCHAR、 STRING或LONG。在用VARCHAR2做键的时候,我们必须指定VARCHAR2的长度,但这里不包括LONG类型,因为LONG等价于 VARCHAR2(32760)。而RAW、LONG RAW、ROWID、CHAR和CHARACTER都是不允许作为关联数组的键的。在引用一个使用VARCHAR2类型作为键的关联数组中的元素时,我们 还可以使用其他类型,如DATE或TIMESTAMP,因为它们自动地会被TO_CHAR函数转换成VARCHAR2。索引表可以使用不连续的键作下标索 引。如下例中,索引表的下标是7468而不是1:
DECLARE
TYPE emptabtyp IS TABLE OF emp%ROWTYPE
INDEX BY BINARY_INTEGER ;
emp_tab emptabtyp;
BEGIN
/* Retrieve employee record. */
SELECT *
INTO emp_tab(7468)
FROM emp
WHERE empno = 7468;
END ;
1、定义与PL/SQL集合类型等价的SQL类型
要把嵌套表或变长数组存到数据表中,我们必须用CREATE TYPE来创建SQL类型。SQL类型可以当作数据表的字段或是SQL对象类型的属性来使用。
我们可以在PL/SQL中声明与之等价的类型,或在PL/SQL变量声明时直接使用SQL类型名。
- 嵌套表的例子
下面的SQL*Plus脚本演示了如何在SQL中创建嵌套表,并把它作为对象类型的属性来使用:
CREATE TYPE CourseList AS TABLE OF VARCHAR2 (10) -- define type
/
CREATE TYPE Student AS OBJECT ( -- create object
id_num INTEGER (4),
name VARCHAR2 (25),
address VARCHAR2 (35),
status CHAR (2),
courses CourseList) -- declare nested table as attribute
/
标识符courses代表整张嵌套表,courses中的每个元素存放一个大学课程的代号,如"Math 1020"。
- 变长数组的例子
下面的脚本创建了能够存储变长数组的数据库字段,其中每个元素包含一个VARCHAR2类型值:
-- Each project has a 16-character code name.
-- We will store up to 50 projects at a time in a database column.
CREATE TYPE projectlist AS VARRAY(50) OF VARCHAR2 (16);
/
CREATE TABLE department ( -- create database table
dept_id NUMBER (2),
NAME VARCHAR2 (15),
budget NUMBER (11,2),
-- Each department can have up to 50 projects.
projects projectlist)
/
四、声明PL/SQL集合变量
在定义了集合类型之后,我们就可以声明该类型的变量了。在声明中要使用新的类型名称,使用方法跟使用预定义类型(如NUMBER和INTEGER等)声明的方法一样。
- 例一:声明嵌套表、变长数组和关联数组
DECLARE
TYPE nested_type IS TABLE OF VARCHAR2 (20);
TYPE varray_type IS VARRAY(50) OF INTEGER ;
TYPE associative_array_type IS TABLE OF NUMBER
INDEX BY BINARY_INTEGER ;
v1 nested_type;
v2 varray_type;
v3 associative_array_type;
- 例二:%TYPE
我们可以利用%TYPE来引用已声明过的集合类型,这样,在集合的定义发生改变时,所有依赖这个集合类型的变量也会相应地改变自己的元素个数和类型,与类型保持一致:
DECLARE
TYPE platoon IS VARRAY(20) OF soldier;
p1 platoon;
-- If we change the number of soldiers in a platoon, p2 will
-- reflect that change when this block is recompiled.
p2 p1%TYPE ;
- 例三:把嵌套表声明为过程参数
我们可以把集合声明为函数或过程的形式参数。这样,就能把集合从一个存储子程序传递到另一个。下面例子中把嵌套表声明为打包过程的参数:
CREATE PACKAGE personnel AS
TYPE staff IS TABLE OF employee;
...
PROCEDURE award_bonuses(members IN staff);
END personnel;
想要从包外调用PERSONNEL.AWARD_BONUSES,我们就得声明PERSONNEL.STAFF类型的变量,然后把它作为参数传递进去。我们还可以在函数说明部分指定RETURN的类型为集合:
DECLARE
TYPE SalesForce IS VARRAY(25) OF Salesperson;
FUNCTION top_performers (n INTEGER ) RETURN SalesForce IS ...
- 例四:用%TYPE和%ROWTYPE指定集合的元素类型
在指定元素的集合类型时,我们可以使用%TYPE和%ROWTYPE。示例如下:
DECLARE
TYPE EmpList IS TABLE OF emp.ename%TYPE ; -- based on column
CURSOR c1 IS SELECT * FROM dept;
TYPE DeptFile IS VARRAY(20) OF c1%ROWTYPE ; -- based on cursor
- 例五:记录类型的变长数组
下面的例子中,我们使用RECORD作为元素的数据类型:
DECLARE
TYPE anentry IS RECORD (
term VARCHAR2 (20),
meaning VARCHAR2 (200)
);
TYPE glossary IS VARRAY(250) OF anentry;
- 例六:为集合的元素添加NOT NULL约束
DECLARE
TYPE EmpList IS TABLE OF emp.empno%TYPE NOT NULL ;
五、初始化与引用集合
在我们为嵌套表和变长数组初始化之前,它们都会自动地被设置成空值。所谓的空值指的是集合本身是空,不是针对它所拥有的元素。可以使用系统定义的与集合类型同名的函数来初始化集合。
我们必须显式地调用构造函数为每一个变长数组和嵌套表变量进行初始化操作(对于关联数组来说,是不需要使用构造函数进行初始化的)。
- 例一:嵌套表的构造函数
在下面的例子中,我们为构造函数CourseList()传递多个元素,然后构造函数就能为我们返回包含这些元素的嵌套表:
DECLARE
TYPE courselist IS TABLE OF VARCHAR2 (16);
my_courses courselist;
BEGIN
my_courses := courselist('Econ 2010' ,
'Acct 3401' ,
'Mgmt 3100'
);
END ;
由于嵌套表没有声明最大长度,所以我们可以在构造中可以放置任意个数的元素。
- 例二:变长数组的构造函数
DECLARE
TYPE projectlist IS VARRAY(50) OF VARCHAR2 (16);
accounting_projects projectlist;
BEGIN
accounting_projects := projectlist('Expense Report' ,
'Outsourcing' ,
'Auditing'
);
END ;
我们不需要初始化整个变长数组,对于一个长度为50的变长数组来说,我们只需传递一部分元素给它的构造函数即可。
- 例三:包含空元素的集合构造函数
如果我们没有对元素使用NOT NULL约束,那么我们就可以把空值传给构造函数:
BEGIN
my_courses := CourseList('Math 3010' , NULL , 'Stat 3202' );
- 例四:把声明和构造结合起来
我们可以在声明的时候初始化集合,这是一个很好的编程习惯:
DECLARE
TYPE courselist IS TABLE OF VARCHAR2 (16);
my_courses courselist := courselist('Art 1111' ,
'Hist 3100' ,
'Engl 2005'
);
- 例五:空的(empty)变长数组构造函数
如果在调用构造函数时不传递任何参数,就会得到一个空的(empty)集合,这里指的是集合内容为空,而不是集合本身为空:
DECLARE
TYPE clientele IS VARRAY(100) OF customer;
vips clientele := clientele(); -- initialize empty varray
BEGIN
IF vips IS NOT NULL THEN
-- condition yields TRUE
...
END IF ;
END ;
这种情况下,我们可以调用EXTEND方法来添加元素。
- 例六:SQL语句中使用嵌套表构造函数
下例中,我们把几个标量值和一个CourseList嵌套表插入到表SOPHOMORES中:
BEGIN
INSERT INTO sophomores
VALUES (5035, 'Janet Alvarez' , '122 Broad St' , 'FT' ,
courselist('Econ 2010' ,
'Acct 3401' ,
'Mgmt 3100'
));
- 例七:SQL语句中使用变长数组构造函数
下例中,我们把一行数据插入到表DEPARTMENT。变长数组构造函数ProjectList()为字段PROJECTS提供数据:
BEGIN
INSERT INTO department
VALUES (60, 'Security' , 750400,
projectlist('New Badges' ,
'Track Computers' ,
'Check Exits'
));
1、引用集合中的元素
集合的引用包含了集合的名称和用圆括号夹起来的下标索引。下标索引决定了要选取哪个元素。语法如下:
collection_name(subscript)
多数情况下,下标是一个运算结果为整数的表达式,对于使用字符串作键的关联数组来说也可能是一个VARCHAR2类型值。下标索引允许的范围如下:
- 对于嵌套表,索引值的范围在1至2**31之间。
- 对于变长数组,索引值的范围在1至最大长度之间,最大长度是在声明时指定的。
- 对于使用数字作键的关联数组来说,索引值的范围在-2**31至2**31之间。
- 对于使用字符串作键的关联数组来说,键的长度和可用值的数量要依赖于类型声明时对VARCHAR2的长度限制和数据库字符集。
- 例一:使用下标索引来引用嵌套表中的元素
这里我们演示一下如何引用嵌套表NAMES中的元素:
DECLARE
TYPE roster IS TABLE OF VARCHAR2 (15);
names roster := roster('J Hamil' ,
'D Caruso' ,
'R Singh'
);
BEGIN
FOR i IN names.FIRST .. names.LAST LOOP
IF names(i) = 'J Hamil' THEN
NULL ;
END IF ;
END LOOP ;
END ;
- 例二:把嵌套表元素作为参数传递
这个例子中我们在调用子程序时引用了集合中的元素:
DECLARE
TYPE roster IS TABLE OF VARCHAR2 (15);
names roster := roster('J Hamil' ,
'D Piro' ,
'R Singh'
);
i BINARY_INTEGER := 2;
BEGIN
verify_name(names(i)); -- call procedure
END ;
六、集合的赋值
集合可以用INSERT、UPDATE、FETCH或SELECT语句来赋值,也可以用赋值语句或调用子程序来赋值。
我们可以使用下面的语法来为某个指定的集合元素进行赋值:
collection_name(subscript) := expression;
其中expression的值和被指定的元素类型必须一致。下面我们来看三个例子。
- 例一:数据的兼容性
例子中的集合与集合之间互相赋值,但必须是两个集合类型相同的才可以,光是元素的类型相同是不够的。
DECLARE
TYPE clientele IS VARRAY(100) OF customer;
TYPE vips IS VARRAY(100) OF customer;
-- These first two variables have the same datatype.
group1 clientele := clientele(...);
group2 clientele := clientele(...);
-- This third variable has a similar declaration,
-- but is not the same type.
group3 vips := vips(...);
BEGIN
-- Allowed because they have the same datatype
group2 := group1;
-- Not allowed because they have different datatypes
group3 := group2;
END ;
- 例二:为嵌套表赋空值
当我们把一个被自动初始化为空的嵌套表或变长数组赋给另外一个嵌套表或变长数组时,被赋值的集合就会被重新初始化,结果也为NULL。
DECLARE
TYPE clientele IS TABLE OF VARCHAR2 (64);
-- This nested table has some values.
group1 clientele := clientele('Customer 1' , 'Customer 2' );
-- This nested table is not initialized ("atomically null").
group2 clientele;
BEGIN
-- At first, the test IF group1 IS NULL yields FALSE .
-- Then we assign a null nested table to group1.
group1 := group2;
-- Now the test IF group1 IS NULL yields TRUE .
-- We must use another constructor to give it some values.
END ;
- 例三:集合赋值时可能引起的异常
在下面几种给集合元素赋值的情况下,可能会引起多种异常。
- 如果下标索引不存在或无法转换成正确的数据类型,PL/SQL就会抛出预定义异常VALUE_ERROR。通常,下标是一个整数。但关联数组的下标也可以是VARCHAR2类型。
- 如果所给下标索引指向了一个未初始化的元素时,PL/SQL就会抛出SUBSCRIPT_BEYOND_COUNT异常。
- 如果集合被自动初始化为空值并且程序引用了其中的一个元素,PL/SQL会抛出COLLECTION_IS_NULL异常。
DECLARE
TYPE wordlist IS TABLE OF VARCHAR2 (5);
words wordlist;
BEGIN
/* Assume execution continues despite the raised exceptions. */
-- Raises COLLECTION_IS_NULL. We haven't used a constructor yet.
-- This exception applies to varrays and nested tables, but not
-- associative arrays which don't need a constructor.
words(1) := 10;
-- After using a constructor, we can assign values to the elements.
words := wordlist(10,
20,
30
);
-- Any expression that returns a VARCHAR2(5) is OK.
words(1) := 'yes' ;
words(2) := words(1) || 'no' ;
-- Raises VALUE_ERROR because the assigned value is too long.
words(3) := 'longer than 5 characters' ;
-- Raises VALUE_ERROR because the subscript of a nested table must
-- be an integer.
words('B' ) := 'dunno' ;
-- Raises SUBSCRIPT_BEYOND_COUNT because we only made 3 elements
-- in the constructor. To add new ones, we must call the EXTEND
-- method first.
words(4) := 'maybe' ;
END ;
七、比较集合
我们可以检查一个集合是不是空,但不能判断两个集合是不是相同。像大于、小于这样的操作都是不允许使用的。
- 例一:检查集合是否为空
嵌套表和变长数组都能被自动初始化为空值,所以它们可以做判空操作:
DECLARE
TYPE staff IS TABLE OF employee;
members staff;
BEGIN
-- Condition yields TRUE because we haven’t used a constructor.
IF members IS NULL THEN ...
END ;
- 例二:比较两个集合
集合不能直接进行等或不等的比较。例如下面的IF条件表达式就是不允许的。
DECLARE
TYPE clientele IS TABLE OF VARCHAR2 (64);
group1 clientele := clientele('Customer 1' , 'Customer 2' );
group2 clientele := clientele('Customer 1' , 'Customer 3' );
BEGIN
-- Equality test causes compilation error.
IF group1 = group2 THEN
...
END IF ;
END ;
这个约束也适用于隐式的比较。所以,集合不能出现在DISTINCT、GROUP BY或ORDER BY中。
如果我们想对集合进行比较的话,就得自定义等于、小于、大于比较规则。同时还要编写一个或多个函数来检查集合和它们的元素并返回真假值。
八、在SQL语句中使用PL/SQL的集合类型
集合允许我们用PL/SQL来操作复杂的数据类型。我们的程序能计算下标索引值,并在内存中处理指定的元素,然后用SQL语句把结果保存到数据库中。
1、关于嵌套表的例子
- 例一:创建与PL/SQL嵌套表对应的SQL类型
在SQL*Plus中,我们可以创建与PL/SQL嵌套表和变长数组相对应的SQL类型:
SQL > CREATE TYPE CourseList AS TABLE OF VARCHAR2 (64);
我们可以把这些类型当作数据库字段来使用:
SQL > CREATE TABLE department (
2 name VARCHAR2 (20),
3 director VARCHAR2 (20),
4 office VARCHAR2 (20),
5 courses CourseList)
6 NESTED TABLE courses STORE AS courses_tab;
字段COURSES中的每一个值都是一个嵌套表类型,能够保存系(department)所提供的课程。
- 例二:向数据库中插入嵌套表
现在,我们可以数据表填充了。嵌套表的构造函数为字段COURSES提供了值:
BEGIN
INSERT INTO department
VALUES ('English' , 'Lynn Saunders' , 'Breakstone Hall 205' ,
courselist ('Expository Writing' ,
'Film and Literature' ,
'Modern Science Fiction' ,
'Discursive Writing' ,
'Modern English Grammar' ,
'Introduction to Shakespeare' ,
'Modern Drama' ,
'The Short Story' ,
'The American Novel'
));
END ;
- 例三:从数据库中检索嵌套表
我们可以把英语系所提供的所有课程放到PL/SQL嵌套表中:
DECLARE
english_courses CourseList;
BEGIN
SELECT courses
INTO english_courses
FROM department
WHERE name = 'English' ;
END ;
在PL/SQL中,我们可以循环遍历嵌套表的元素并使用TRIM或EXTEND方法来更新嵌套表中部分或全部的元素。然后,在把更新后的结果保存到数据库中去。
- 例四:用嵌套表更新数据库中
我们可以修改英语系所提供的课程列表:
DECLARE
new_courses courselist
:= courselist ('Expository Writing' ,
'Film and Literature' ,
'Discursive Writing' ,
'Modern English Grammar' ,
'Realism and Naturalism' ,
'Introduction to Shakespeare' ,
'Modern Drama' ,
'The Short Story' ,
'The American Novel' ,
'20th-Century Poetry' ,
'Advanced Workshop in Poetry'
);
BEGIN
UPDATE department
SET courses = new_courses
WHERE NAME = 'English' ;
END ;
2、变长数组的一些例子
假设我们在SQL*Plus中定义了对象类型Project:
SQL > CREATE TYPE Project AS OBJECT (
2 project_no NUMBER (2),
3 title VARCHAR2 (35),
4 cost NUMBER (7,2));
下一步,定义VARRAY类型的ProjectList,用来存放Project对象:
SQL > CREATE TYPE ProjectList AS VARRAY(50) OF Project;
最后,创建关系表department,其中的一个字段类型为ProjectList:
SQL > CREATE TABLE department (
2 dept_id NUMBER (2),
3 name VARCHAR2 (15),
4 budget NUMBER (11,2),
5 projects ProjectList);
在字段projects中的每一项都是一个用于存放给定系的项目计划的变长数组。
现在让我们准备插入一些测试数据。注意一下,在下面的例子中,变长数组的构造函数ProjectList()是如何为字段projects提供数据的:
BEGIN
INSERT INTO department
VALUES (30, 'Accounting' , 1205700,
projectlist (project (1, 'Design New Expense Report' , 3250),
project (2, 'Outsource Payroll' , 12350),
project (3, 'Evaluate Merger Proposal' , 2750),
project (4, 'Audit Accounts Payable' , 1425)
));
INSERT INTO department
VALUES (50, 'Maintenance' , 925300,
projectlist (project (1, 'Repair Leak in Roof' , 2850),
project (2, 'Install New Door Locks' , 1700),
project (3, 'Wash Front Windows' , 975),
project (4, 'Repair Faulty Wiring' , 1350),
project (5, 'Winterize Cooling System' , 1125)
));
INSERT INTO department
VALUES (60, 'Security' , 750400,
projectlist (project (1, 'Issue New Employee Badges' , 13500),
project (2, 'Find Missing IC Chips' , 2750),
project (3, 'Upgrade Alarm System' , 3350),
project (4, 'Inspect Emergency Exits' , 1900)
));
END ;
现在,让我们对Security系做个更新操作:
DECLARE
new_projects projectlist
:= projectlist (project (1, 'Issue New Employee Badges' , 13500),
project (2, 'Develop New Patrol Plan' , 1250),
project (3, 'Inspect Emergency Exits' , 1900),
project (4, 'Upgrade Alarm System' , 3350),
project (5, 'Analyze Local Crime Stats' , 825)
);
BEGIN
UPDATE department
SET projects = new_projects
WHERE dept_id = 60;
END ;
接下来,对Accounting系做一次查询操作,并把结果放到本地变量中去:
DECLARE
my_projects projectlist;
BEGIN
SELECT projects
INTO my_projects
FROM department
WHERE dept_id = 30;
END ;
最后,删除记录Accounting:
BEGIN
DELETE FROM department
WHERE dept_id = 30;
END ;
3、使用SQL语句操作特定的集合元素
默认情况下,SQL操作会一次性的保存或检索整个集合而不是一个独立的元素。要用SQL语句操作集合中的独立的元素,可以使用TABLE操作符。 TABLE操作符用一个子查询把变长数组或嵌套表的内容提取出来,这样的话,INSERT、UPDATE或DELETE语句就可以作用于嵌套表,而不是整 张数据表了。
下面,让我们看看一些具体的操作实例。
- 例一:向嵌套表中插入元素
首先,我们向历史系的嵌套表COURSES插入一条记录:
BEGIN
-- The TABLE operator makes the statement apply to the nested
-- table from the 'History' row of the DEPARTMENT table.
INSERT INTO TABLE (SELECT courses
FROM department
WHERE NAME = 'History' )
VALUES ('Modern China' );
END ;
- 例二:更新嵌套表中的元素
然后对嵌套表的学分进行调整:
BEGIN
UPDATE TABLE (SELECT courses
FROM department
WHERE NAME = 'Psychology' )
SET credits = credits + adjustment
WHERE course_no IN (2200, 3540);
END ;
- 例三:从嵌套表中检索一个元素
下面,我们从历史系检索出一个特定课程名称:
DECLARE
my_title VARCHAR2 (64);
BEGIN
-- We know that there is one history course with 'Etruscan'
-- in the title. This query retrieves the complete title
-- from the nested table of courses for the History department.
SELECT title
INTO my_title
FROM TABLE (SELECT courses
FROM department
WHERE NAME = 'History' )
WHERE NAME LIKE '%Etruscan%' ;
END ;
- 例四:从嵌套表中删除元素
最后,我们从英语系中删除所有那些学分为5的课程:
BEGIN
DELETE TABLE (SELECT courses
FROM department
WHERE NAME = 'English' )
WHERE credits = 5;
END ;
- 例五:从变长数组中检索元素
下面例子演示了从变长数组类型的字段projects中检索出公务处第四个项目的名称和费用:
DECLARE
my_cost NUMBER (7, 2);
my_title VARCHAR2 (35);
BEGIN
SELECT COST, title
INTO my_cost, my_title
FROM TABLE (SELECT projects
FROM department
WHERE dept_id = 50)
WHERE project_no = 4;
...
END ;
- 例六:对变长数组应用INSERT、UPDATE和DELETE操作
目前,我们还不能在INSERT、UPDATE和DELETE语句中引用变长数组中的元素,必须先检索整个变长数组,使用PL/SQL来添加、删除或更新元素,然后把修改结果重新放回数据库中。
下面的存储过程ADD_PROCEDURE演示了如何按给定的位置向department中插入一个新的project。
CREATE PROCEDURE add_project (
dept_no IN NUMBER ,
new_project IN project,
POSITION IN NUMBER
) AS
my_projects projectlist;
BEGIN
SELECT projects
INTO my_projects
FROM department
WHERE dept_no = dept_id
FOR UPDATE OF projects;
my_projects.EXTEND; -- make room for new project
/* Move varray elements forward. */
FOR i IN REVERSE POSITION .. my_projects.LAST - 1 LOOP
my_projects (i + 1) := my_projects (i);
END LOOP ;
my_projects (POSITION) := new_project; -- add new project
UPDATE department
SET projects = my_projects
WHERE dept_no = dept_id;
END add_project;
下例代码为一个指定的工程更新数据:
CREATE PROCEDURE update_project (
dept_no IN NUMBER ,
proj_no IN NUMBER ,
new_title IN VARCHAR2 DEFAULT NULL ,
new_cost IN NUMBER DEFAULT NULL
) AS
my_projects projectlist;
BEGIN
SELECT projects
INTO my_projects
FROM department
WHERE dept_no = dept_id
FOR UPDATE OF projects;
/* Find project, update it, then exit loop immediately. */
FOR i IN my_projects.FIRST .. my_projects.LAST LOOP
IF my_projects (i).project_no = proj_no THEN
IF new_title IS NOT NULL THEN
my_projects (i).title := new_title;
END IF ;
IF new_cost IS NOT NULL THEN
my_projects (i).COST := new_cost;
END IF ;
EXIT ;
END IF ;
END LOOP ;
UPDATE department
SET projects = my_projects
WHERE dept_no = dept_id;
END update_project;
- 例七:对嵌套表应用INSERT、UPDATE和DELETE操作
为了能对一个PL/SQL嵌套表使用DML操作,我们需要使用TABLE和CAST操作符。这样,我们就可以直接使用SQL标志对嵌套表进行集合操作而不用把更改过的嵌套表保存在数据库中。
CAST的操作数可以是PL/SQL集合变量和SQL集合类型(使用CREATE TYPE语句创建)。CAST可以把PL/SQL集合转成SQL类型的。
下面的例子用来计算修改后的课程列表和原始课程列表的不同点的数量(注意,课程3720的学分从4变成3):
DECLARE
revised courselist
:= courselist (course (1002, 'Expository Writing' , 3),
course (2020, 'Film and Literature' , 4),
course (2810, 'Discursive Writing' , 4),
course (3010, 'Modern English Grammar ' , 3),
course (3550, 'Realism and Naturalism' , 4),
course (3720, 'Introduction to Shakespeare' , 3),
course (3760, 'Modern Drama' , 4),
course (3822, 'The Short Story' , 4),
course (3870, 'The American Novel' , 5),
course (4210, '20th-Century Poetry' , 4),
course (4725, 'Advanced Workshop in Poetry' , 5)
);
num_changed INTEGER ;
BEGIN
SELECT COUNT (*)
INTO num_changed
FROM TABLE (CAST (revised AS courselist)) NEW ,
TABLE (SELECT courses
FROM department
WHERE NAME = 'English' ) OLD
WHERE NEW .course_no = OLD.course_no
AND (NEW .title != OLD.title OR NEW .credits != OLD.credits);
DBMS_OUTPUT.put_line (num_changed);
END ;
九、使用多级集合
除了标量类型或对象类型集合之外,我们也可以创建集合的集合。例如,我们可以创建元素是变长数组类型的变长数组,元素是嵌套表类型的变长数组等。
在用SQL创建字段类型为嵌套表类型的嵌套表时,Oracle会检查CREATE TABLE语句的语法,看如何定义存储表。
这里有几个例子演示了多级集合的语法。
- 多级VARRAY
DECLARE
TYPE t1 IS VARRAY(10) OF INTEGER ;
TYPE nt1 IS VARRAY(10) OF t1; -- multilevel varray type
va t1 := t1(2, 3, 5);
-- initialize multilevel varray
nva nt1 := nt1(va, t1(55, 6, 73), t1(2, 4), va);
i INTEGER ;
va1 t1;
BEGIN
-- multilevel access
i := nva(2)(3); -- i will get value 73
DBMS_OUTPUT.put_line(i);
-- add a new varray element to nva
nva.EXTEND;
nva(5) := t1(56, 32);
-- replace an inner varray element
nva(4) := t1(45, 43, 67, 43345);
-- replace an inner integer element
nva(4)(4) := 1; -- replaces 43345 with 1
-- add a new element to the 4th varray element
-- and store integer 89 into it.
nva(4).EXTEND;
nva(4)(5) := 89;
END ;
- 多级嵌套表
DECLARE
TYPE tb1 IS TABLE OF VARCHAR2 (20);
TYPE ntb1 IS TABLE OF tb1; -- table of table elements
TYPE tv1 IS VARRAY(10) OF INTEGER ;
TYPE ntb2 IS TABLE OF tv1; -- table of varray elements
vtb1 tb1 := tb1('one' , 'three' );
vntb1 ntb1 := ntb1(vtb1);
vntb2 ntb2 := ntb2(tv1(3, 5), tv1(5, 7, 3)); -- table of varray elements
BEGIN
vntb1.EXTEND;
vntb1(2) := vntb1(1);
-- delete the first element in vntb1
vntb1.DELETE (1);
-- delete the first string from the second table in the nested table
vntb1(2).DELETE (1);
END ;
/
- 多级关联数组
DECLARE
TYPE tb1 IS TABLE OF INTEGER
INDEX BY BINARY_INTEGER ;
-- the following is index-by table of index-by tables
TYPE ntb1 IS TABLE OF tb1
INDEX BY BINARY_INTEGER ;
TYPE va1 IS VARRAY(10) OF VARCHAR2 (20);
-- the following is index-by table of varray elements
TYPE ntb2 IS TABLE OF va1
INDEX BY BINARY_INTEGER ;
v1 va1 := va1('hello' , 'world' );
v2 ntb1;
v3 ntb2;
v4 tb1;
v5 tb1; -- empty table
BEGIN
v4(1) := 34;
v4(2) := 46456;
v4(456) := 343;
v2(23) := v4;
v3(34) := va1(33, 456, 656, 343);
-- assign an empty table to v2(35) and try again
v2(35) := v5;
v2(35)(2) := 78; -- it works now
END ;
/
- 多级集合和批量SQL
CREATE TYPE t1 IS VARRAY(10) OF INTEGER ;
/
CREATE TABLE tab1 (c1 t1);
INSERT INTO tab1
VALUES (t1(2, 3, 5));
INSERT INTO tab1
VALUES (t1(9345, 5634, 432453));
DECLARE
TYPE t2 IS TABLE OF t1;
v2 t2;
BEGIN
SELECT c1
BULK COLLECT INTO v2
FROM tab1;
DBMS_OUTPUT.put_line(v2.COUNT); -- prints 2
END ;
/
十、集合的方法
集合提供了以下几个方法,能帮助我们更加方便维护和使用它:
- EXISTS
- COUNT
- LIMIT
- FIRST和LAST
- PRIOR和NEXT
- EXTEND
- TRIM
- DELETE
一个集合方法就是一个内置于集合中并且能够操作集合的函数或过程,可以通过点标志来调用。使用方法如下:
collection_name.method_name[(parameters)]
集合的方法不能在SQL语句中使用。并且,EXTEND和TRIM方法不能用于关联数组。 EXISTS,COUNT,LIMIT,FIRST,LAST,PRIOR和NEXT是函数;EXTEND,TRIM和DELETE是过程。 EXISTS,PRIOR,NEXT,TRIM,EXTEND和DELETE对应的参数是集合的下标索引,通常是整数,但对于关联数组来说也可能是字符 串。
只有EXISTS能用于空集合,如果在空集合上调用其它方法,PL/SQL就会抛出异常COLLECTION_IS_NULL。
1、检测集合中的元素是否存在(EXISTS)
函数EXISTS(n)在第n个元素存在的情况下会返回TRUE,否则返回FALSE。我们主要使用EXISTS和DELETE来维护嵌套表。其中EXISTS还可以防止引用不存在的元素,避免发生异常。下面的例子中,PL/SQL只在元素i存在的情况下执行赋值语句:
IF courses.EXISTS (i) THEN
courses(i) := new_course;
END IF ;
当下标越界时,EXISTS会返回FALSE,而不是抛出SUBSCRIPT_OUTSIDE_LIMIT异常。
2、计算集合中的元素个数(COUNT)
COUNT能够返回集合所包含的元素个数。例如,当下面的变长数组projects中含有25个元素时,IF条件就为TRUE:
IF projects.COUNT = 25 THEN ...
COUNT函数很有用,因为集合的当前大小不总是能够被确定。例如,如果我们把一个字段中的值放入嵌套表中,那么嵌套表中会有多少个元素呢?COUNT会给我们答案。
我们可以在任何可以使用整数表达式的地方使用COUNT函数。下例中,我们用COUNT来指定循环的上界值:
FOR i IN 1 .. courses.COUNT LOOP ...
对于变长数组来说,COUNT值与LAST值恒等,但对于嵌套表来说,正常情况下COUNT值会和LAST值相等。但是,当我们从嵌套表中间删除一个元素,COUNT值就会比LAST值小。
计算元素个数时,COUNT会忽略已经被删除的元素。
3、检测集合的最大容量(LIMIT)
因为嵌套表和关联数组都没有上界限制,所以LIMIT总会返回NULL。但对于变长数组来说,LIMIT会返回它所能容纳元素的个数最大值,该值是 在变长数组声明时指定的,并可用TRIM和EXTEND方法调整。例如下面的变长数组projects在最大容量是25的时候,IF的条件表达式值为真:
IF projects.LIMIT = 25 THEN ...
我们可以在任何允许使用整数表达式的地方使用LIMIT函数。下面的例子中,我们使用LIMIT来决定是否可以为变长数组再添加15个元素:
IF (projects.COUNT + 15) < projects.LIMIT THEN ...
4、查找集合中的首末元素(FIRST和LAST)
FIRST和LAST会返回集合中第一个和最后一个元素在集合中的下标索引值。而对于使用VARCHAR2类型作为键的关联数组来说,会分别返回最 低和最高的键值;键值的高低顺序是基于字符串中字符的二进制值,但是,如果初始化参数NLS_COMP被设置成ANSI的话,键值的高低顺序就受初始化参 数NLS_SORT所影响了。
空集合的FIRST和LAST方法总是返回NULL。只有一个元素的集合,FIRST和LAST会返回相同的索引值。
IF courses.FIRST = courses.LAST THEN ... -- only one element
下面的例子演示了使用FIRST和LAST函数指定循环范围的下界和上界值:
FOR i IN courses.FIRST .. courses.LAST LOOP ...
实际上,我们可以在任何允许使用整数表达式的地方使用FIRST或LAST函数。下例中,我们用FIRST函数来初始化一个循环计数器:
i := courses.FIRST;
WHILE i IS NOT NULL LOOP ...
对于变长数组来说,FIRST恒等于1,LAST恒等于COUNT;但对嵌套表来说,FIRST正常情况返回1,如果我们把第一个元素删除,那么FIRST的值就要大于1,同样,如果我们从嵌套表的中间删除一个元素,LAST就会比COUNT大。
在遍历元素时,FIRST和LAST都会忽略被删除的元素。
5、循环遍历集合中的元素(PRIOR和NEXT)
PRIOR(n)会返回集合中索引为n的元素的前驱索引值;NEXT(n)会返回集合中索引为n的元素的后继索引值。如果n没有前驱或后继,PRIOR(n)或NEXT(n)就会返回NULL。
对于使用VARCHAR2作为键的关联数组来说,它们会分别返回最低和最高的键值;键值的高低顺序是基于字符串中字符的二进制值,但是,如果初始化参数NLS_COMP被设置成ANSI的话,键值的高低顺序就受初始化参数NLS_SORT所影响了。
这种遍历方法比通过固定的下标索引更加可靠,因为在循环过程中,有些元素可能被插入或删除。特别是关联数组,因为它的下标索引可能是不连续的,有可能是(1,2,4,8,16)或('A','E','I','O','U')这样的形式。
PRIOR和NEXT不会从集合的一端到达集合的另一端。例如,下面的语句把NULL赋给n,因为集合中的第一个元素没有前驱:
n := courses.PRIOR (courses.FIRST); -- assigns NULL to n
PRIOR是NEXT的逆操作。比如说,存在一个元素i,下面的语句就是用元素i给自身赋值:
projects(i) := projects.PRIOR (projects.NEXT(i));
我们可以使用PRIOR或NEXT来遍历集合。在下面的例子中,我们使用NEXT来遍历一个包含被删除元素的嵌套表:
i := courses.FIRST; -- get subscript of first element
WHILE i IS NOT NULL LOOP
-- do something with courses(i)
i := courses.NEXT(i); -- get subscript of next element
END LOOP ;
在遍历元素时,PRIOR和NEXT都会忽略被删除的元素。
6、扩大集合的容量(EXTEND)
为了扩大嵌套表或变长数组的容量,可以使用EXTEND方法。但该方法不能用于索引表。该方法有三种形式:
- EXTEND 在集合末端添加一个空元素
- EXTEND(n) 在集合末端添加n个空元素
- EXTEND(n,i) 把第i个元素拷贝n份,并添加到集合的末端
例如,下面的语句在嵌套表courses的末端添加了元素1的5个副本:
courses.EXTEND(5,1);
不能使用EXTEND初始化一个空集合。同样,当我们对TABLE或VARRAY添加了NOT NULL约束之后,就不能再使用EXTEND的前两种形式了。
EXTEND操作的是集合内部大小,其中也包括被删除的元素。所以,在计算元素个数的时候,EXTEND也会把被删除的元素考虑在内。PL/SQL会为每一个被删除的元素保留一个占位符,以便在适当的时候让我们重新使用。如下例:
DECLARE
TYPE courselist IS TABLE OF VARCHAR2 (10);
courses courselist;
BEGIN
courses := courselist('Biol 4412' , 'Psyc 3112' , 'Anth 3001' );
courses.DELETE (3); -- delete element 3
/* PL/SQL keeps a placeholder for element 3. So, the
next statement appends element 4, not element 3. */
courses.EXTEND; -- append one null element
/* Now element 4 exists, so the next statement does
not raise SUBSCRIPT_BEYOND_COUNT. */
courses(4) := 'Engl 2005' ;
END ;
当包含被删除元素时,嵌套表的内部大小就不同于COUNT和LAST返回的值了。举一个例子,假如我们初始化一个长度为5的嵌套表,然后删除第二个 和第五个元素,这时的内部长度是5,COUNT返回值是3,LAST返回值是4。EXTEND方法会把所有的被删除的元素都一样对待,无论它是第一个,最 后一个还是中间的。
7、缩减集合的空间(TRIM)
TRIM有两种形式:
- TRIM 从集合末端删除一个元素
- TRIM(n) 从集合末端删除n个元素
例如,下面的表达式从嵌套表courses中删除最后三个元素:
courses.TRIM(3);
如果n值过大的话,TRIM(n)就会抛出SUBSCRIPT_BEYOND_COUNT异常。
同EXTEND相似,TRIM也不会忽略被删除的元素。看一下下面的例子:
DECLARE
TYPE courselist IS TABLE OF VARCHAR2 (10);
courses courselist;
BEGIN
courses := courselist('Biol 4412' , 'Psyc 3112' , 'Anth 3001' );
courses.DELETE (courses.LAST); -- delete element 3
/* At this point, COUNT equals 2, the number of valid
elements remaining. So, you might expect the next
statement to empty the nested table by trimming
elements 1 and 2. Instead, it trims valid element 2
and deleted element 3 because TRIM includes deleted
elements in its tally. */
courses.TRIM(courses.COUNT);
DBMS_OUTPUT.put_line(courses(1)); -- prints 'Biol 4412'
END ;
一般的,不要同时使用TRIM和DELETE方法。最好是把嵌套表当作定长数组,只对它使用DELETE方法,或是把它当作栈,只对它使用TRIM和EXTEND方法。PL/SQL对TRIM掉的元素不再保留占位符。这样我们就不能简单地为被TRIM掉的元素赋值了。
8、删除集合中的元素(DELETE)
DELETE方法有三种形式:
- DELETE 删除集合中所有元素
- DELETE(n) 从以数字作主键的关联数组或者嵌套表中删除第n个元素。如果关联数组有一个字符串键,对应该键值的元素就会被删除。如果n为空,DELETE(n)不会做任何事情。
- DELETE(m,n) 从关联数组或嵌套表中,把索引范围m到n的所有元素删除。如果m值大于n或是m和n中有一个为空,那么DELETE(m,n)就不做任何事。
例如:
BEGIN
courses.DELETE (2); -- deletes element 2
courses.DELETE (7, 7); -- deletes element 7
courses.DELETE (6, 3); -- does nothing
courses.DELETE (3, 6); -- deletes elements 3 through 6
projects.DELETE ; -- deletes all elements
nicknames.DELETE ('Chip' ); -- deletes element denoted by this key
nicknames.DELETE ('Buffy' , 'Fluffy' );
-- deletes elements with keys
-- in this alphabetic range
END ;
变长数组是密集的,我们不能从中删除任何一个元素。如果被删除的元素不存在,DELETE只是简单地忽略它,并不抛出异常。PL/SQL会为被删除的元素保留一个占位符,以便我们可以重新为被删除的元素赋值。
DELETE方法能让我们维护有间隙的嵌套表。下面的例子中,我们把嵌套表prospects的内容放到临时表中,然后从中删除一部分元素后,再重新把它存入数据库中:
DECLARE
my_prospects prospectlist;
revenue NUMBER ;
BEGIN
SELECT prospects
INTO my_prospects
FROM customers
WHERE ...
FOR i IN my_prospects.FIRST .. my_prospects.LAST LOOP
estimate_revenue(my_prospects(i), revenue); -- call procedure
IF revenue < 25000 THEN
my_prospects.DELETE (i);
END IF ;
END LOOP ;
UPDATE customers
SET prospects = my_prospects
WHERE ...
END ;
分配给嵌套表的内存是动态的,删除元素时内存会被释放。
9、使用集合类型参数的方法
在子程序中,我们可以对集合类型的参数直接调用它的内置方法,如下例:
CREATE PACKAGE personnel AS
TYPE staff IS TABLE OF employee;
...
PROCEDURE award_bonuses(members IN staff);
END personnel;
CREATE PACKAGE BODY personnel AS
PROCEDURE award_bonuses(members IN staff) IS
...
BEGIN
...
IF members.COUNT > 10 THEN -- apply method
...
END IF ;
END ;
END personnel;
注意:对于变长数组参数来说,LIMIT的值与参数类型定义相关,与参数的模式无关。
十一、避免集合异常
大多情况下,如果我们引用了一个集合中不存在的元素,PL/SQL就会抛出一个预定义异常。例如:
DECLARE
TYPE numlist IS TABLE OF NUMBER ;
nums numlist; -- atomically null
BEGIN
/* Assume execution continues despite the raised exceptions. */
nums(1) := 1; -- raises COLLECTION_IS_NULL (1)
nums := numlist(1, 2); -- initialize table
nums(NULL ) := 3; -- raises VALUE_ERROR (2)
nums(0) := 3; -- raises SUBSCRIPT_OUTSIDE_LIMIT (3)
nums(3) := 3; -- raises SUBSCRIPT_BEYOND_COUNT (4)
nums.DELETE (1); -- delete element 1
IF nums(1) = 1 THEN
... -- raises NO_DATA_FOUND (5)
END ;
第一句,嵌套表是空的;第二句,下标为空;三四句,下标超出合法范围之外;第五句,下标指向了一个被删除的元素。下表是一些异常情况的说明:
| 集合异常 | 发生时机 |
|---|---|
| COLLECTION_IS_NULL | 调用一个空集合的方法 |
| NO_DATA_FOUND | 下标索引指向一个被删除的元素,或是关联数组中不存在的元素 |
| SUBSCRIPT_BEYOND_COUNT | 下标索引值超过集合中的元素个数 |
| SUBSCRIPT_OUTSIDE_LIMIT | 下标索引超过允许范围之外 |
| VALUE_ERROR | 下标索引值为空,或是不能转换成正确的键类型。当键被定义在 PLS_INTEGER的范围内,而下标索引值超过这个范围就可能抛 出这个异常 |
在某些情况下,如果我们为一个方法传递了一个无效的下标,并不会抛出异常。例如在使用DELETE方法的时候,我们向它传递NULL,它只是什么都没做而已。同样,用新值替换被删除的元素也不会引起NO_DATA_FOUND异常,如下例:
DECLARE
TYPE numlist IS TABLE OF NUMBER ;
nums numlist := numlist(10, 20, 30); -- initialize table
BEGIN
nums.DELETE (-1); -- does not raise SUBSCRIPT_OUTSIDE_LIMIT
nums.DELETE (3); -- delete 3rd element
DBMS_OUTPUT.put_line(nums.COUNT); -- prints 2
nums(3) := 30; -- allowed; does not raise NO_DATA_FOUND
DBMS_OUTPUT.put_line(nums.COUNT); -- prints 3
END ;
打包集合类型和本地集合类型总是不兼容的。假设我们想调用下面的打包过程:
CREATE PACKAGE pkg1 AS
TYPE NumList IS VARRAY(25) OF NUMBER (4);
PROCEDURE delete_emps (emp_list NumList);
END pkg1;
CREATE PACKAGE BODY pkg1 AS
PROCEDURE delete_emps (emp_list NumList) IS ...
...
END pkg1;
在运行下面PL/SQL块时,第二个过程调用会因参数的数量或类型错误(wrong number or types of arguments error)而执行失败。这是因为打包VARRAY和本地VARRAY类型不兼容,虽然它们的定义形式都是一样的:
DECLARE
TYPE numlist IS VARRAY(25) OF NUMBER (4);
emps pkg1.numlist := pkg1.numlist(7369, 7499);
emps2 numlist := numlist(7521, 7566);
BEGIN
pkg1.delete_emps(emps);
pkg1.delete_emps(emps2); -- causes a compilation error
END ;
十二、使用集合批量绑定减少循环开销
如下图所示,PL/SQL引擎会执行过程化语句,但它把SQL语句发送给SQL引擎处理,然后SQL引擎把处理的结果返回给PL/SQL引擎。

PL/SQL和SQL引擎间的频繁切换会大大降低效率。典型的情况就是在一个循环中反复执行SQL语句。例如,下面的DELETE语句就会在FOR循环中被多次发送到SQL引擎中去:
DECLARE
TYPE numlist IS VARRAY(20) OF NUMBER ;
depts numlist := numlist(10, 30, 70); -- department numbers
BEGIN
...
FOR i IN depts.FIRST .. depts.LAST LOOP
DELETE FROM emp
WHERE deptno = depts(i);
END LOOP ;
END ;
这种情况下,如果SQL语句影响了四行或更多行时,使用批量绑定就会显著地提高性能。
1、批量绑定如何提高性能
用SQL语句中为PL/SQL变量赋值称为绑定,PL/SQL绑定操作可以分为三种:
- 内绑定(in-bind):用INSERT或UPDATE语句将PL/SQL变量或主变量保存到数据库。
- 外绑定(out-bind):通过INSERT、UPDATE或DELETE语句的RETURNING子句的返回值为PL/SQL变量或主变量赋值。
- 定义(define):使用SELECT或FETCH语句为PL/SQL变量或主变量赋值。
DML语句可以一次性传递集合中所有的元素,这个过程就是批量绑定。如果集合有20个元素,批量绑定的一次操作就相当于执行20次SELECT、 INSERT、UPDATE或DELETE语句。这项技术是靠减少PL/SQL和SQL引擎间的切换次数来提高性能的。要对INSERT、UPDATE和 DELETE语句使用批量绑定,就要用PL/SQL的FORALL语句。
如果要在SELECT语句中使用批量绑定,我们就要在SELECT语句后面加上一个BULK COLLECT子句来代替INTO子句。
- 例一:对DELETE语句应用批量绑定
下面的DELETE语句只往SQL引擎中发送一次,即使是执行了三次DELETE操作:
DECLARE
TYPE numlist IS VARRAY(20) OF NUMBER ;
depts numlist := numlist(10, 30, 70); -- department numbers
BEGIN
FORALL i IN depts.FIRST .. depts.LAST
DELETE FROM emp
WHERE deptno = depts(i);
END ;
- 例二:对INSERT语句应用批量绑定
下例中,我们把5000个零件编号和名称放到索引表中。所有的表元素都向数据库插入两次:第一次使用FOR循环,然后使用FORALL语句。实际上,FORALL版本的代码执行速度要比FOR语句版本的快得多。
SQL > SET SERVEROUTPUT ON
SQL > CREATE TABLE parts (pnum NUMBER (4), pname CHAR (15));
Table created.
SQL > GET test.sql
1 DECLARE
2 TYPE NumTab IS TABLE OF NUMBER (4) INDEX BY BINARY_INTEGER ;
3 TYPE NameTab IS TABLE OF CHAR (15) INDEX BY BINARY_INTEGER ;
4 pnums NumTab;
5 pnames NameTab;
6 t1 NUMBER (5);
7 t2 NUMBER (5);
8 t3 NUMBER (5);
9
10
11 BEGIN
12 FOR j IN 1..5000 LOOP -- load index-by tables
13 pnums(j) := j;
14 pnames(j) := 'Part No. ' || TO_CHAR(j);
15 END LOOP ;
16 t1 := dbms_utility.get_time;
17 FOR i IN 1..5000 LOOP -- use FOR loop
18 INSERT INTO parts VALUES (pnums(i), pnames(i));
19 END LOOP ;
20 t2 := dbms_utility.get_time;
21 FORALL i IN 1..5000 -- use FORALL statement
22 INSERT INTO parts VALUES (pnums(i), pnames(i));
23 get_time(t3);
24 dbms_output.put_line('Execution Time (secs)' );
25 dbms_output.put_line('---------------------' );
26 dbms_output.put_line('FOR loop: ' || TO_CHAR(t2 - t1));
27 dbms_output.put_line('FORALL: ' || TO_CHAR(t3 - t2));
28* END ;
SQL > /
Execution Time (secs)
---------------------
FOR loop: 32
FORALL: 3
十三、使用FORALL语句
关键字FORALL能让PL/SQL引擎在将集合发送到SQL引擎之前,批量导入集合元素。虽然FORALL也包含了迭代的模式,但它并不是简单的FOR循环。它的使用语法如下:
FORALL index IN lower_bound..upper_bound
sql_statement;
index只能在FORALL语句块内作为集合下标使用。SQL语句必须是引用了集合元素的INSERT、UPDATE或DELETE语句。bound的有效范围是连续的索引号。在这个范围内,SQL引擎为每个索引号执行一次SQL语句。
- 例一:使用FORALL操作集合的部分内容
如下例所示,FORALL循环的边界值可作用于集合的部分内容,不必是全部的元素:
DECLARE
TYPE numlist IS VARRAY(10) OF NUMBER ;
depts numlist := numlist(20, 30, 50, 55, 57, 60, 70, 75, 90, 92);
BEGIN
FORALL j IN 4 .. 7 -- bulk-bind only part of varray
UPDATE emp
SET sal = sal * 1.10
WHERE deptno = depts(j);
END ;
- 例二:使用集合下标索引的批量绑定
SQL语句能引用一个以上的集合。但是PL/SQL引擎的批量绑定只能为一个集合添加下标索引。所以,在下面的例子中,对于传递给函数median的集合sals,并没有使用到批量绑定。
FORALL i IN 1..20
INSERT INTO emp2 VALUES (enums(i), names(i), median(sals), ...);
- 例三:使用FORALL为对象表添加数据
除了关系表之外,FORALL语句还可以操作对象表,如下例所示:
CREATE TYPE pnum AS OBJECT(
n NUMBER
);
/
CREATE TABLE partno OF pnum;
DECLARE
TYPE numtab IS TABLE OF NUMBER ;
nums numtab := numtab(1, 2, 3, 4);
TYPE pnumtab IS TABLE OF pnum;
pnums pnumtab := pnumtab(pnum(1), pnum(2), pnum(3), pnum(4));
BEGIN
FORALL i IN pnums.FIRST .. pnums.LAST
INSERT INTO partno
VALUES (pnums(i));
FORALL i IN nums.FIRST .. nums.LAST
DELETE FROM partno
WHERE n = 2 * nums(i);
FORALL i IN nums.FIRST .. nums.LAST
INSERT INTO partno
VALUES (100 + nums(i));
END ;
1、FORALL语句对回滚的影响
在FORALL语句中,如果SQL语句引起了一个未捕获异常,以前对数据库的所有操作都会被回滚。但是,如果我们捕获到被抛出的异常并加以处理,此次之前的操作就不会被回滚。举一个例子,假设我们创建了数据表用来存储部门编号和职别:
CREATE TABLE emp2 (deptno NUMBER (2), job VARCHAR2 (15));
下一步,为刚才建立的数据表添加一些记录:
INSERT INTO emp2 VALUES (10, 'Clerk' );
INSERT INTO emp2 VALUES (10, 'Clerk' );
INSERT INTO emp2 VALUES (20, 'Bookkeeper' ); -- 10-char job title
INSERT INTO emp2 VALUES (30, 'Analyst' );
INSERT INTO emp2 VALUES (30, 'Analyst' );
然后,我们用下面的UPDATE语句为特定的职称加上七位字符串' (temp)':
DECLARE
TYPE numlist IS TABLE OF NUMBER ;
depts numlist := numlist(10, 20, 30);
BEGIN
FORALL j IN depts.FIRST .. depts.LAST
UPDATE emp2
SET job = job || ' (temp)'
WHERE deptno = depts(j);
-- raises a "value too large" exception
EXCEPTION
WHEN OTHERS THEN
COMMIT ;
END ;
SQL引擎会执行UPDATE语句三次,第一次成功,但在第二次会因字符串值'Bookkeeper (temp)'太长而无法赋给job字段,所以就会执行失败。这种情况下,只有第二条语句回滚。
只要有SQL语句抛出异常,FORALL语句就会终止执行。在上面的例子中,第二个UPDATE语句抛出了异常,第三个语句就不会被执行了。
2、使用%BULK_ROWCOUNT属性来计算FORALL语句所影响到的行数
处理SQL数据操作语句时,SQL引擎会隐式地打开一个名为SQL的游标。这个游标的标量属性%FOUND、%ISOPEN、%NOTFOUND和%ROWCOUNT,能够提供最近一次执行的SQL数据操作语句信息。
SQL游标还有一个专门为FORALL设计的复合属性%BULK_ROWCOUNT。这个属性有些像索引表。它的第i个元素保存了第i次的 INSERT或UPDATE或DELETE语句所影响到的行数。如果第i次操作没有行被影响,%BULK_ROWCOUNT(i)就返回零。下面来看一个 例子:
DECLARE
TYPE numlist IS TABLE OF NUMBER ;
depts numlist := numlist(10, 20, 50);
BEGIN
FORALL j IN depts.FIRST .. depts.LAST
UPDATE emp
SET sal = sal * 1.10
WHERE deptno = depts(j);
-- Did the 3rd UPDATE statement affect any rows?
IF SQL %BULK_ROWCOUNT(3) = 0 THEN ...
END ;
FORALL语句和%BULK_ROWCOUNT属性使用同样的下标索引。如果FORALL使用下标索引的范围在5到10的话,那 么%BULK_ROWCOUNT的也是。对于插入操作来说,%BULK_ROWCOUNT的结果一般是1,但是对于INSERT ... SELECT这样的结构来说,%BULK_ROWCOUNT的值就有可能大于1。例如,下面的FORALL语句在循环插入数据的过程中,每次插入的行的个 数都是不固定的,%BULK_ROWCOUNT可以记录每次插入的行数:
SET SERVEROUTPUT ON ;
DECLARE
TYPE num_tab IS TABLE OF NUMBER ;
deptnums num_tab;
BEGIN
SELECT deptno
BULK COLLECT INTO deptnums
FROM dept;
FORALL i IN 1 .. deptnums.COUNT
INSERT INTO emp_by_dept
SELECT empno, deptno
FROM emp
WHERE deptno = deptnums(i);
FOR i IN 1 .. deptnums.COUNT LOOP
-- Count how many rows were inserted for each department; that is,
-- how many employees are in each department.
DBMS_OUTPUT.put_line( 'Dept '
|| deptnums(i)
|| ': inserted '
|| SQL %BULK_ROWCOUNT(i)
|| ' records' );
END LOOP ;
DBMS_OUTPUT.put_line('Total records inserted =' || SQL %ROWCOUNT);
END ;
/
我们还可以在批量绑定中使用标量属性%FOUND、%ISOPEN、%NOTFOUND和%ROWCOUNT。例如,%ROWCOUNT会返回所有的SQL语句处理的总行数。
%FOUND和%NOTFOUND只是针对最后一次SQL语句执行的结果。但是,我们可以利用%BULK_ROWCOUNT来推断出每个单独语句的处理结果。当%BULK_ROWCOUNT(i)为零时,%FOUND和%NOTFOUND就分别为FALSE和TRUE。
3、使用%BULK_EXCEPTIONS属性来控制FORALL异常
PL/SQL为FORALL语句提供了一个异常控制机制。这个机制能让使用批量绑定的操作保存异常信息并不中断地执行直至完成操作。
为了让批量绑定在错误发生时还能够继续执行,需要在FORALL语句中添加关键字SAVE EXCEPTIONS,语法如下:
FORALL index IN lower_bound..upper_bound SAVE EXCEPTIONS
{insert_stmt | update_stmt | delete_stmt}
执行时发生的所有的异常信息都会保存在新的游标属性%BULK_EXCEPTIONS中。%BULK_EXCEPTIONS是一个记录类型集合,每 个记录有两个域,分别是ERROR_INDEX和ERROR_CODE,前者保存FORALL语句的"循环"索引,后者保存对应的Oracle错误编号。
存放在%BULK_EXCEPTIONS中的值总是与最近一次FORALL语句执行的结果相关,异常的个数存放在%BULK_EXCEPTIONS 的COUNT属性中,%BULK_EXCEPTIONS有效的下标索引范围在1到%BULK_EXCEPTIONS.COUNT之间。
我们不使用关键字SAVE EXCEPTIONS时,如果异常发生,FORALL语句就会停止执行,SQL%BULK_EXCEPTIONS.COUNT的值就是 一,SQL%BULK_EXCEPTIONS中只包含一条记录;如果没有异常发生,SQL%BULK_EXCEPTIONS.COUNT的值就是零。下面 的例子演示了%BULK_EXCEPTIONS的一些用法:
DECLARE
TYPE numlist IS TABLE OF NUMBER ;
num_tab numlist := numlist(10, 0, 11, 12, 30, 0, 20, 199, 2, 0, 9, 1);
ERRORS NUMBER ;
dml_errors EXCEPTION ;
PRAGMA EXCEPTION_INIT(dml_errors, -24381);
BEGIN
FORALL i IN num_tab.FIRST .. num_tab.LAST SAVE EXCEPTIONS
DELETE FROM emp
WHERE sal > 500000 / num_tab(i);
EXCEPTION
WHEN dml_errors THEN
ERRORS := SQL %BULK_EXCEPTIONS.COUNT;
DBMS_OUTPUT.put_line('Number of errors is ' || ERRORS);
FOR i IN 1 .. ERRORS LOOP
DBMS_OUTPUT.put_line( 'Error '
|| i
|| ' occurred during '
|| 'iteration '
|| SQL %BULK_EXCEPTIONS(i).ERROR_INDEX);
DBMS_OUTPUT.put_line( 'Oracle error is '
|| SQLERRM (-SQL %BULK_EXCEPTIONS(i).ERROR_CODE));
END LOOP ;
END ;
例子中,PL/SQL在i等于2、6、10时会抛出预定义异常ZERO_DIVIDE。当批量绑定完成 时,SQL%BULK_EXCEPTIONS.COUNT就会返回3,SQL%BULK_EXCEPTIONS的内容就是(2,1476), (6,1476)和(10,1476)。如果想得到错误消息,我们可以把SQL%BULK_EXCEPTIONS(i).ERROR_CODE传递给错误 报告函数SQLERRM,这样就能得到下面的输出结果:
Number of errors is 3
Error 1 occurred during iteration 2
Oracle error is ORA-01476: divisor is equal to zero
Error 2 occurred during iteration 6
Oracle error is ORA-01476: divisor is equal to zero
Error 3 occurred during iteration 10
Oracle error is ORA-01476: divisor is equal to zero
十四、利用BULK COLLECTION子句为集合赋值
关键字BULK COLLECT会通知SQL引擎在将数据返回给PL/SQL引擎之前,把输出的数据批量地绑定到一个集合。我们可以在SELECT INTO、FETCH INTO和RETURNING INTO子句中使用BULK COLLECT。语法如下:
... BULK COLLECT INTO collection_name[, collection_name] ...
SQL引擎能批量绑定出现在INTO列表后的所有集合。对应的字段可以保存为标量类型或复合类型的值,其中也包括对象类型。在下面的例子中,SQL引擎在把数据返回给PL/SQL引擎之前,它将完整的empno和ename绑定到嵌套表中:
DECLARE
TYPE numtab IS TABLE OF emp.empno%TYPE ;
TYPE nametab IS TABLE OF emp.ename%TYPE ;
enums numtab; -- no need to initialize
names nametab;
BEGIN
SELECT empno, ename
BULK COLLECT INTO enums, names
FROM emp;
...
END ;
接下来的例子中,SQL引擎会批量地把对象字段的值放到嵌套表中:
CREATE TYPE coords AS OBJECT(
x NUMBER ,
y NUMBER
);
CREATE TABLE grid (num NUMBER , loc coords);
INSERT INTO grid
VALUES (10, coords(1, 2));
INSERT INTO grid
VALUES (20, coords(3, 4));
DECLARE
TYPE coordstab IS TABLE OF coords;
pairs coordstab;
BEGIN
SELECT loc
BULK COLLECT INTO pairs
FROM grid;
-- now pairs contains (1,2) and (3,4)
END ;
SQL引擎会为我们初始化和扩展集合(但是,它不能把变长数组的长度扩大到超过变长数组的最大长度值)。然后从索引1开始,连续地插入元素并覆盖先前已存在的元素。
SQL引擎能批量绑定整个字段。所以,如果一个数据表中有50000行记录,引擎就会一次性加载50000个值到目标集合中去。但是,我们可以使用伪列ROWNUM来限制要处理的行记录个数。下例中,我们把每次处理的记录个数限制为100:
DECLARE
TYPE sallist IS TABLE OF emp.sal%TYPE ;
sals sallist;
BEGIN
SELECT sal
BULK COLLECT INTO sals
FROM emp
WHERE ROWNUM <= 100;
...
END ;
1、从游标中批量取得数据的例子
- 插入一个或多个集合
我们可以从游标中批量取得数据并绑定到一个或多个集合中去:
DECLARE
TYPE namelist IS TABLE OF emp.ename%TYPE ;
TYPE sallist IS TABLE OF emp.sal%TYPE ;
CURSOR c1 IS
SELECT ename, sal
FROM emp
WHERE sal > 1000;
names namelist;
sals sallist;
BEGIN
OPEN c1;
FETCH c1
BULK COLLECT INTO names, sals;
END ;
- 绑定记录类型的集合
我们可以批量取得数据并绑定到记录类型的集合中去:
DECLARE
TYPE deptrectab IS TABLE OF dept%ROWTYPE ;
dept_recs deptrectab;
CURSOR c1 IS
SELECT deptno, dname, loc
FROM dept
WHERE deptno > 10;
BEGIN
OPEN c1;
FETCH c1
BULK COLLECT INTO dept_recs;
END ;
2、使用LIMIT子句限制FETCH操作批量取得的数据个数
可选的LIMIT子句只允许出现在FETCH操作语句的批量中,它能够帮助我们限制批量取得的数据数量,语法如下:
FETCH ... BULK COLLECT INTO ... [LIMIT rows];
其中rows可以是文字,变量或表达式,但它的计算结果必须是一个数字。否则的话,PL/SQL就会抛出预定义异常VALUE_ERROR。如果 rows是非正数,PL/SQL会抛出INVALID_NUMBER异常。在必要的时候,PL/SQL还会将数字四舍五入到rows最接近的整数。
在下面的例子中,每次FETCH操作都会取出10条记录放到索引表empno中去,之前的数据内容会被当前的数据所覆盖:
DECLARE
TYPE numtab IS TABLE OF NUMBER
INDEX BY BINARY_INTEGER ;
CURSOR c1 IS
SELECT empno
FROM emp;
empnos numtab;
ROWS NATURAL := 10;
BEGIN
OPEN c1;
LOOP
/* The following statement fetches 10 rows (or less). */
FETCH c1
BULK COLLECT INTO empnos LIMIT ROWS;
EXIT WHEN c1%NOTFOUND;
...
END LOOP ;
CLOSE c1;
END ;
3、使用RETURNING INTO子句将DML的操作结果绑定到集合
我们还可以在INSERT、UPDATE或DELETE语句的RETURNING INTO子句中使用BULK COLLECT来进行数据绑定,示例如下:
DECLARE
TYPE numlist IS TABLE OF emp.empno%TYPE ;
enums numlist;
BEGIN
DELETE FROM emp
WHERE deptno = 20
RETURNING empno
BULK COLLECT INTO enums;
-- if there were five employees in department 20,
-- then enums contains five employee numbers
END ;
4、BULK COLLECT的限制
下面是使用BULK COLLECT的一些限制:
- 不能对使用字符串类型作键的关联数组使用BULK COLLECT子句。
- 只能在服务器端的程序中使用BULK COLLECT,如果在客户端使用,就会产生一个不支持这个特性的错误。
- BULK COLLECT INTO的目标对象必须是集合类型,如下例所示:
DECLARE
TYPE namelist IS TABLE OF emp.ename%TYPE ;
names namelist;
salary emp.sal%TYPE ;
BEGIN
SELECT ename, sal
BULK COLLECT INTO names, salary -- illegal target
FROM emp
WHERE ROWNUM < 50;
...
END ; - 复合目标(如对象类型)不能在RETURNING INTO子句中使用。
- 如果有多个隐式的数据类型转换的情况存在,多重复合目标就不能在BULK COLLECT INTO子句中使用。
- 如果有一个隐式的数据类型转换,复合目标的集合(如对象类型集合)就不能用于BULK COLLECT INTO子句中。
5、把FORALL和BULK COLLECTION结合起来使用
我们可以把BULK COLLECT和FORALL语句结合起来使用,这时,SQL引擎会批量绑定字段值。下例中,如果集合depts有三个元素,每个元素都能执行五次DELETE操作,当语句执行完毕的时候,enums中就会有十五个元素:
FORALL j IN depts.FIRST .. depts.LAST
DELETE FROM emp
WHERE empno = depts(j)
RETURNING empno
BULK COLLECT INTO enums;
我们不能在FORALL语句中使用SELECT ... BULK COLLECT语句。否则,就会得到一条错误消息:不能在SELECT语句中同时使用FORALL和BULK COLLECT INTO(cannot use FORALL and BULK COLLECT INTO together in SELECT statements)。
6、使用主数组进行批量绑定
客户端程序可以使用匿名PL/SQL块来把数据批量地从主数组中输入或批量地输出到主数组。实际上,这是与服务器端交互传递集合的最高效的方法。
主数组是声明在主环境中的,如OCI或Pro*C程序,并且必须以冒号为前缀,以区别于PL/SQL集合。在下面的例子中,DELETE语句中使用到一个输入主数组。运行时,匿名PL/SQL块被发送到数据库服务器端执行:
DECLARE
...
BEGIN
-- assume that values were assigned to the host array
-- and host variables in the host environment
FORALL i IN :lower..:upper
DELETE FROM emp
WHERE deptno = :depts(i);
...
END ;
十五、什么是记录
记录就是相关的数据项集中存储在一个单元中,每项都有它自己的名字和数据类型。假定我们有关于雇员的各种数据信息,如名字、薪水和雇佣日期,这些项在逻辑上是相关联的,但类型不相似。记录可以把它所拥有的每一项当作一个逻辑单元,这样就便于组织和表现信息。
%ROWTYPE属性能让我们声明代表数据表中一行记录的类型。但是我们不能利用它指定或声明自己的数据类型。不过没关系,RECORD关键字可以满足我们定义自己的记录的要求。
十六、定义和声明记录
要创建记录,我们就得先声明记录类型,然后声明该类型的记录。我们可以在PL/SQL块、子程序或包的声明部分使用下面的语法来定义RECORD类型:
TYPE type_name IS RECORD (field_declaration[,field_declaration]...);
其中field_declaration的形式如下:
field_name field_type [[NOT NULL ] {:= | DEFAULT } expression]
type_name是声明记录用的类型区分符,field_type是除了REF CURSOR以外的任何PL/SQL数据类型,expression的结果值与field_type相同。
注意:与VARRAY类型和TABLE(嵌套)类型不同的是,RECORD是不能存在于数据库中的。
创建记录时也可以使用%TYPE和%ROWTYPE来指定记录各个域的类型。下例中,我们定义了一个名为DeptRec的记录类型:
DECLARE
TYPE deptrec IS RECORD (
dept_id dept.deptno%TYPE ,
dept_name VARCHAR2 (14),
dept_loc VARCHAR2 (13)
);
BEGIN
...
END ;
在下面的例子中,我们在记录类型中包含对象、集合和其他的记录(又叫嵌套记录)。但是对象类型中不能把RECORD类型作为它的属性。
DECLARE
TYPE timerec IS RECORD (
seconds SMALLINT ,
minutes SMALLINT ,
hours SMALLINT
);
TYPE flightrec IS RECORD (
flight_no INTEGER ,
plane_id VARCHAR2 (10),
captain employee, -- declare object
passengers passengerlist, -- declare varray
depart_time timerec, -- declare nested record
airport_code VARCHAR2 (10)
);
BEGIN
...
END ;
下面的例子演示了如何将函数的返回类型指定为RECORD类型:
DECLARE
TYPE emprec IS RECORD (
emp_id NUMBER (4),
last_name VARCHAR2 (10),
dept_num NUMBER (2),
job_title VARCHAR2 (9),
salary NUMBER (7, 2)
);
...
FUNCTION nth_highest_salary(n INTEGER )
RETURN emprec IS ...
BEGIN
...
END ;
1、声明记录
一旦定义了RECORD类型,我们就可以声明该类型的记录。如下例所示,标识符item_info代表了整条记录:
DECLARE
TYPE stockitem IS RECORD (
item_no INTEGER (3),
description VARCHAR2 (50),
quantity INTEGER ,
price REAL (7, 2)
);
item_info stockitem; -- declare record
BEGIN
...
END ;
同标量类型的变量一样,用户定义的记录也可以作为函数或过程的形式参数来使用:
DECLARE
TYPE emprec IS RECORD (
emp_id emp.empno%TYPE ,
last_name VARCHAR2 (10),
job_title VARCHAR2 (9),
salary NUMBER (7, 2)
);
...
PROCEDURE raise_salary(emp_info emprec);
BEGIN
...
END ;
2、初始化记录
下面的例子演示了如何在定义记录的时候,同时进行初始化操作。当我们声明TimeRec类型的记录时,它的三个域都被初始化为零:
DECLARE
TYPE timerec IS RECORD (
secs SMALLINT := 0,
mins SMALLINT := 0,
hrs SMALLINT := 0
);
BEGIN
...
END ;
我们可以为记录添加NOT NULL约束,对于有NOT NULL约束的字段,声明时必须进行初始化:
DECLARE
TYPE stockitem IS RECORD (
item_no INTEGER (3) NOT NULL := 999,
description VARCHAR2 (50),
quantity INTEGER ,
price REAL (7, 2)
);
BEGIN
...
END ;
3、引用记录
同集合中的元素不同,它们的引用方式是使用下标索引,而记录对于它的域的引用要使用名称。语法如下:
record_name.field_name
例如,我们想访问记录emp_info下的hire_date域,那么就要使用:
emp_info.hire_date ...
在调用一个返回用户定义的记录类型的函数时,要使用下面的语法:
function_name(parameter_list).field_name
例如,下例对函数nth_highest_sal的调用就引用到记录类型emp_info的salary域:
DECLARE
TYPE emprec IS RECORD (
emp_id NUMBER (4),
job_title VARCHAR2 (9),
salary NUMBER (7, 2)
);
middle_sal NUMBER (7, 2);
FUNCTION nth_highest_sal(n INTEGER )
RETURN emprec IS
emp_info emprec;
BEGIN
...
RETURN emp_info; -- return record
END ;
BEGIN
middle_sal := nth_highest_sal(10).salary; -- call function
...
END ;
对于一个无参数的返回类型为记录的函数来说,要使用下面的语法引用记录中的字段:
function_name().field_name -- note empty parameter list
而对于返回类型是一个包含嵌套域的记录的函数来说,引用字段的语法如下:
function_name(parameter_list).field_name.nested_field_name
下面看一个记录包含记录的例子:
DECLARE
TYPE timerec IS RECORD (
minutes SMALLINT ,
hours SMALLINT
);
TYPE agendaitem IS RECORD (
priority INTEGER ,
subject VARCHAR2 (100),
DURATION timerec
);
FUNCTION item(n INTEGER )
RETURN agendaitem IS
item_info agendaitem;
BEGIN
...
RETURN item_info; -- return record
END ;
BEGIN
NULL ;
IF item(3).duration.minutes > 30 THEN ... -- call function
END ;
同样,对于包含在记录中的对象的引用方法也类似:
DECLARE
TYPE flightrec IS RECORD (
flight_no INTEGER ,
plane_id VARCHAR2 (10),
captain employee, -- declare object
passengers passengerlist, -- declare varray
depart_time timerec, -- declare nested record
airport_code VARCHAR2 (10)
);
flight flightrec;
BEGIN
...
IF flight.captain.name = 'H Rawlins' THEN ...
END ;
4、为记录赋控值
要把记录中的所有字段都设置成空值,只需用一个未初始化的同类型记录为它赋值即可,例如:
DECLARE
TYPE emprec IS RECORD (
emp_id emp.empno%TYPE ,
job_title VARCHAR2 (9),
salary NUMBER (7, 2)
);
emp_info emprec;
emp_null emprec;
BEGIN
emp_info.emp_id := 7788;
emp_info.job_title := 'ANALYST' ;
emp_info.salary := 3500;
emp_info := emp_null; -- nulls all fields in emp_info
...
END ;
5、为记录赋值
我们可以把表达式的值赋给记录中特定的域,语法如下:
record_name.field_name := expression;
下例中,我们把雇员的名字转成大写形式:
emp_info.ename := UPPER(emp_info.ename);
除了每个域单独赋值之外,我们还可以一次性为整个记录进行赋值。一次性赋值有两种方法,第一个方法是把同类型的一个记录赋值给另外一个记录:
DECLARE
TYPE deptrec IS RECORD (
dept_num NUMBER (2),
dept_name VARCHAR2 (14)
);
TYPE deptitem IS RECORD (
dept_num NUMBER (2),
dept_name VARCHAR2 (14)
);
dept1_info deptrec;
dept2_info deptitem;
BEGIN
...
dept1_info := dept2_info; -- illegal; different datatypes
END ;
下面再看一个例子,第一个是自定义记录,第二个是使用%ROWTYPE获取的记录,由于这两个记录中的字段数量和顺序相匹配,而且类型兼容,所以可以用其中的一个为另一个赋值:
DECLARE
TYPE deptrec IS RECORD (
dept_num NUMBER (2),
dept_name VARCHAR2 (14),
LOCATION VARCHAR2 (13)
);
dept1_info deptrec;
dept2_info dept%ROWTYPE ;
BEGIN
SELECT *
INTO dept2_info
FROM dept
WHERE deptno = 10;
dept1_info := dept2_info;
...
END ;
一次性赋值的第二个方法就是使用SELECT或FETCH语句把对应的字段值放入记录中去:
DECLARE
TYPE deptrec IS RECORD (
dept_num NUMBER (2),
dept_name VARCHAR2 (14),
LOCATION VARCHAR2 (13)
);
dept_info deptrec;
BEGIN
SELECT *
INTO dept_info
FROM dept
WHERE deptno = 20;
...
END ;
但像下面这样的赋值方法是不允许的:
record_name := (value1, value2, value3, ...); -- not allowed
下面的例子演示了如何把一个嵌套记录赋给另一个,这里要保证的是被嵌套的记录类型是相同的。这样的赋值方法是允许的,即使封闭记录有着不同的数据类型:
DECLARE
TYPE timerec IS RECORD (
mins SMALLINT ,
hrs SMALLINT
);
TYPE meetingrec IS RECORD (
DAY DATE ,
time_of timerec, -- nested record
room_no INTEGER (4)
);
TYPE partyrec IS RECORD (
DAY DATE ,
time_of timerec, -- nested record
place VARCHAR2 (25)
);
seminar meetingrec;
party partyrec;
BEGIN
...
party.time_of := seminar.time_of;
END ;
6、比较记录
记录不能用于空值、等值或不等的比较。例如,下面IF的条件表达式是不允许的:
BEGIN
...
IF emp_info IS NULL THEN ... -- illegal
IF dept2_info > dept1_info THEN ... -- illegal
END ;
十七、操作记录
RECORD类型能让我们把事物的属性信息收集起来。这些信息很容易操作,因为我们在集合中把它们当作一个整体来处理。如下例中,我们可以从数据表asserts和liabilities中收集accounting数,然后用比率分析来比较两个子公司的生产效率:
DECLARE
TYPE FiguresRec IS RECORD (cash REAL , notes REAL , ...);
sub1_figs FiguresRec;
sub2_figs FiguresRec;
FUNCTION acid_test (figs FiguresRec) RETURN REAL IS ...
BEGIN
SELECT cash, notes, ...
INTO sub1_figs
FROM assets, liabilities
WHERE assets.sub = 1
AND liabilities.sub = 1;
SELECT cash, notes, ...
INTO sub2_figs
FROM assets, liabilities
WHERE assets.sub = 2
AND liabilities.sub = 2;
IF acid_test(sub1_figs) > acid_test(sub2_figs) THEN ...
...
END ;
注意,向函数acid_test传递收集到的数字是一件很容易的事情,函数能够计算出一个财务比率。
假设我们在SQL*Plus中定义了对象类型Passenger:
SQL > CREATE TYPE Passenger AS OBJECT(
2 flight_no NUMBER (3),
3 name VARCHAR2 (20),
4 seat CHAR (5));
下一步定义VARRAY类型PassengerList,用来存放Passenger对象:
SQL > CREATE TYPE PassengerList AS VARRAY(300) OF Passenger;
最后创建关系表flights,其中的一个字段的类型为PassengerList:
SQL > CREATE TABLE flights (
2 flight_no NUMBER (3),
3 gate CHAR (5),
4 departure CHAR (15),
5 arrival CHAR (15),
6 passengers PassengerList);
在字段passengers中的每一项都是一个储存给定航班的旅客名单的变长数组。现在,我们为数据表flights添加一些数据:
BEGIN
INSERT INTO flights
VALUES (109, '80' , 'DFW 6:35PM' , 'HOU 7:40PM' ,
passengerlist(passenger(109, 'Paula Trusdale' , '13C' ),
passenger(109, 'Louis Jemenez' , '22F' ),
passenger(109, 'Joseph Braun' , '11B' ), ...));
INSERT INTO flights
VALUES (114, '12B' , 'SFO 9:45AM' , 'LAX 12:10PM' ,
passengerlist(passenger(114, 'Earl Benton' , '23A' ),
passenger(114, 'Alma Breckenridge' , '10E' ),
passenger(114, 'Mary Rizutto' , '11C' ), ...));
INSERT INTO flights
VALUES (27, '34' , 'JFK 7:05AM' , 'MIA 9:55AM' ,
passengerlist(passenger(27, 'Raymond Kiley' , '34D' ),
passenger(27, 'Beth Steinberg' , '3A' ),
passenger(27, 'Jean Lafevre' , '19C' ), ...));
END ;
下例中,我们从数据表flights中取出数据放到记录flight_into中去。那样,我们就可以把一个航班的所有的信息,包括它的旅客名单,作为一个逻辑单元来处理。
DECLARE
TYPE flightrec IS RECORD (
flight_no NUMBER (3),
gate CHAR (5),
departure CHAR (15),
arrival CHAR (15),
passengers passengerlist
);
flight_info flightrec;
CURSOR c1 IS
SELECT *
FROM flights;
seat_not_available EXCEPTION ;
BEGIN
OPEN c1;
LOOP
FETCH c1
INTO flight_info;
EXIT WHEN c1%NOTFOUND;
FOR i IN 1 .. flight_info.passengers.LAST LOOP
IF flight_info.passengers(i).seat = 'na' THEN
DBMS_OUTPUT.put_line(flight_info.passengers(i).NAME);
RAISE seat_not_available;
END IF ;
...
END LOOP ;
END LOOP ;
CLOSE c1;
EXCEPTION
WHEN seat_not_available THEN
...
END ;
1、向数据库插入PL/SQL记录
PL/SQL对INSERT语句的唯一的扩展就是能让我们使用一个独立RECORD类型或是%ROWTYPE类型变量,来代替域列表来插入一条数据。这样才可以让我们的代码更具可读性,更容易维护。
记录中域的个数必须和INTO子句后面列出的字段个数相等,对应的域和字段的类型必须兼容。这样可以保证记录与数据表兼容。
- 利用%ROWTYPE插入PL/SQL记录
这个例子用%ROWTYPE声明了一个记录类型变量。我们可以使用这个变量直接插入数据而不用指定字段列表。%ROWTYPE声明能保证记录属性的名称和类型与数据表字段完全一致。
DECLARE
dept_info dept%ROWTYPE ;
BEGIN
-- deptno, dname, and loc are the table columns.
-- The record picks up these names from the %ROWTYPE.
dept_info.deptno := 70;
dept_info.dname := 'PERSONNEL' ;
dept_info.loc := 'DALLAS' ;
-- Using the %ROWTYPE means we can leave out the column list
-- (deptno, dname, loc) from the INSERT statement.
INSERT INTO dept
VALUES dept_info;
END ;
2、使用记录更新数据库
PL/SQL对UPDATE语句的唯一的扩展就是能让我们使用一个独立RECORD类型或是%ROWTYPE类型变量,来代替域列表更新一条数据。
记录中域的个数必须和SET子句后面列出的字段个数相等,对应的域和字段的类型也必须兼容。
- 用记录更新行记录
我们可以使用关键字ROW代表完整的一行数据:
/* Formatted on 2006/08/30 20:27 (Formatter Plus v4.8.7) */
DECLARE
dept_info dept%ROWTYPE ;
BEGIN
dept_info.deptno := 30;
dept_info.dname := 'MARKETING' ;
dept_info.loc := 'ATLANTA' ;
-- The row will have values for the filled-in columns, and null
-- for any other columns.
UPDATE dept
SET ROW = dept_info
WHERE deptno = 30;
END ;
关键字ROW只允许出现在SET子句的左边。
- 不能在子查询中使用SET ROW
我们不能在子查询中使用ROW。例如,下面的UPDATE语句是不允许的:
UPDATE emp SET ROW = (SELECT * FROM mgrs); -- not allowed
- 使用包含对象的记录更新行数据
包含对象类型的记录是可以使用的:
CREATE TYPE worker AS OBJECT(
NAME VARCHAR2 (25),
dept VARCHAR2 (15)
);
/
CREATE TABLE teams (team_no NUMBER , team_member worker);
DECLARE
team_rec teams%ROWTYPE ;
BEGIN
team_rec.team_no := 5;
team_rec.team_member := worker('Paul Ocker' , 'Accounting' );
UPDATE teams
SET ROW = team_rec;
END ;
/
- 使用包含集合的记录更新行数据
记录可以包含集合:
CREATE TYPE worker AS OBJECT(
NAME VARCHAR2 (25),
dept VARCHAR2 (15)
);
/
CREATE TYPE roster AS TABLE OF worker;
/
CREATE TABLE teams (team_no NUMBER , members roster)
NESTED TABLE members STORE AS teams_store;
INSERT INTO teams
VALUES (1,
roster(worker('Paul Ocker' , 'Accounting' ),
worker('Gail Chan' , 'Sales' ),
worker('Marie Bello' , 'Operations' ),
worker('Alan Conwright' , 'Research' )));
DECLARE
team_rec teams%ROWTYPE ;
BEGIN
team_rec.team_no := 3;
team_rec.members := roster(worker('William Bliss' , 'Sales' ),
worker('Ana Lopez' , 'Sales' ),
worker('Bridget Towner' , 'Operations' ),
worker('Ajay Singh' , 'Accounting' ));
UPDATE teams
SET ROW = team_rec;
END ;
/
- 使用RETURNING子句
INSERT,UPDATE和DELETE语句都可以包含RETURNING子句,返回的字段值来自于被影响到的行,它们被放到PL/SQL记录变 量中。这就可以省掉在插入、更新操作之后或删除操作之前执行SELECT查找被影响到的数据。我们只能在对一行数据进行操作时使用这个子句。
下面的例子中,我们更新一个雇员的工资,同时,检索雇员的姓名、职别和把新的工资值放进记录变量:
DECLARE
TYPE emprec IS RECORD (
emp_name VARCHAR2 (10),
job_title VARCHAR2 (9),
salary NUMBER (7, 2)
);
emp_info emprec;
emp_id NUMBER (4);
BEGIN
emp_id := 7782;
UPDATE emp
SET sal = sal * 1.1
WHERE empno = emp_id
RETURNING ename,
job,
sal
INTO emp_info;
END ;
3、记录类型插入/更新操作的约束
- 记录类型变量只在下面几种情况下才允许使用:
- 在UPDATE语句中SET子句的右边
- 在INSERT语句中VALUES子句的后面
- 在RETURNING语句中INTO子句的后面
- 关键字ROW只允许在SET子句的左面出现,并且不能和子查询连用。
- UPDATE语句中,如果使用了ROW关键字,那么SET就只能使用一次。
- 如果一个INSERT语句的VALUES子句中包含了记录变量,那么就不允许出现其他变量或值。
- 如果RETURNING语句的INTO子句中包含了记录变量,那么就不允许出现其他变量或值。
- 下面三种情况是不能使用记录的:
- 含有记录嵌套。
- 函数返回记录类型。
- 记录的插入/更新是用EXECUTE IMMEDIATE语句完成的。
4、用查询结果为记录类型的集合赋值
PL/SQL的绑定操作可以分为三类:
- 定义:使用SELECT或FETCH语句为PL/SQL变量或主变量赋值。
- 内绑定:用INSERT语句插入的或UPDATE语句更新的数据库值。
- 外绑定:用INSERT、UPDATE或DELETE语句的RETURNING子句把值返回到PL/SQL变量或主变量中。
PL/SQL支持使用DML语句对记录类型的集合进行批量绑定。一个"定义"或"外绑定"变量可以是记录类型的集合,"内绑定"值可以保存到记录类型的集合中的。语法如下:
SELECT select_items BULK COLLECT
INTO record_variable_name
FROM rest_of_select_stmt
FETCH { cursor_name
| cursor_variable_name
| :host_cursor_variable_name}
BULK COLLECT INTO record_variable_name
[LIMIT numeric_expression];
FORALL index IN lower_bound..upper_bound
INSERT INTO { table_reference
| THE_subquery} [{column_name[, column_name]...}]
VALUES (record_variable_name(index)) rest_of_insert_stmt
FORALL index IN lower_bound..upper_bound
UPDATE {table_reference | THE_subquery} [alias]
SET (column_name[, column_name]...) = record_variable_name(index)
rest_of_update_stmt
RETURNING row_expression[, row_expression]...
BULK COLLECT INTO record_variable_name;
上面每个语句和子句中,记录变量存储一个记录类型的集合。记录中的域个数必须和SELECT、INSERT INTO、UPDATE ... SET或RETURNING相对应的列的个数相同。并且相对应的域和字段必须类型兼容。下面是几个例子:
CREATE TABLE tab1 (col1 NUMBER , col2 VARCHAR2 (20));
/
CREATE TABLE tab2 (col1 NUMBER , col2 VARCHAR2 (20));
/
DECLARE
TYPE rectabtyp IS TABLE OF tab1%ROWTYPE
INDEX BY BINARY_INTEGER ;
TYPE numtabtyp IS TABLE OF NUMBER
INDEX BY BINARY_INTEGER ;
TYPE chartabtyp IS TABLE OF VARCHAR2 (20)
INDEX BY BINARY_INTEGER ;
CURSOR c1 IS
SELECT col1, col2
FROM tab2;
rec_tab rectabtyp;
num_tab numtabtyp := numtabtyp(2, 5, 8, 9);
char_tab chartabtyp := chartabtyp('Tim' , 'Jon' , 'Beth' , 'Jenny' );
BEGIN
FORALL i IN 1 .. 4
INSERT INTO tab1
VALUES (num_tab(i), char_tab(i));
SELECT col1,
col2
BULK COLLECT INTO rec_tab
FROM tab1
WHERE col1 < 9;
FORALL i IN rec_tab.FIRST .. rec_tab.LAST
INSERT INTO tab2
VALUES rec_tab(i);
FOR i IN rec_tab.FIRST .. rec_tab.LAST LOOP
rec_tab(i).col1 := rec_tab(i).col1 + 100;
END LOOP ;
FORALL i IN rec_tab.FIRST .. rec_tab.LAST
UPDATE tab1
SET (col1, col2) = rec_tab(i)
WHERE col1 < 8;
OPEN c1;
FETCH c1
BULK COLLECT INTO rec_tab;
CLOSE c1;
END ;















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









