









世界是草台班子,这句话视乎很流行! 经历过几家创业公司的项目优化,以及大公司项目. 很多优化非常初级,用心点都能自己找出来! 其实主要原因当初是为了赶进度,能省则省.什么设计啊? 什么性能压测啊. 都省掉吧! 质量都要靠测试人员帮忙找出来,更何况是性能问题呢! 那怕是配齐了测试人员,一上线各种BUG起飞,然后经过个把月打补丁才稳定下来!
各位JAVA大神是不是都是这样的体会! 更何况是全栈JAVA工程师一手操办! 为了降本增效,大量使用插件,自动化工具以及框架.
系统一慢,立马甩锅到数据库上, 这点是酒精考验的真理! 毕竟人家数据库只有一台,而应用使用微服务架构可以N台.
数据库慢,慢在哪里? 为什么以前不慢,现在就慢了呢? 这是经常被拷问的问题
可以说从三个方面探讨数据库慢的原因
1 自然是数量多了,经过1-2年的日积月累
2 用户多了,经过销售和老板的勤奋努力
3 SQL变多了,经过产品经理和开发人员的努力
其实第3点,很多人没有注意到.原本系统的业务开始之处比较少的SQL,后期不断满足需求,自然功能越多,SQL也越多. 这一部分造成单位时间内SQL请求量增多,也就会导致各种资源的
针对 1-2 点 数据库端 可以采用的优化措施是
1 范围分区
2 冷热分表
3 读写分离
4 添加索引
范围分区: 一般情况下大家都是基于时间范围的分区,根据业务查询范围特性,选择合适的时间进行分区;
冷热分表: 这是根据业务时间来说,100%把不需要的数据迁移到历史表中,可以说成归档.
读写分离: 一般情况下数据库还有一台作为灾备的实例,一般情况下都是空闲,自然要利用起来,比如说做些统计查询的工作, 承担业务某些统计的功能.
添加索引:根据SLOW日志 无脑地,或者稍微考虑下添加索引.
数据库我们说完了,应该说JAVA优化了.我只是个DBA,能看懂JAVA代码,自然不会班门弄斧!
JAVA 有模式 M V C 也就是分层. 现在SPRING BOOT 微服务时代,那就是前后端分离.
M 自然是指数据端了.
V 是指 VIEW 前端页面
C 是指控制端,以前处理WEB请求地址的,现在叫后端,主要处理业务逻辑的.
V 前端页面

1 数据缓存, 前端在下不太懂,咨询本公司前端的妹子,VUE可以本地缓存,各种浏览器都有F12查看的
比如微软的新浏览器
在这里先说下我们业务, 电商平台,有商城,有客户,有商户,有银行支付渠道;
那么我们可以把常用的选择项存入缓存中,每个页面就不用去请求接口获得对应的值. 比如说我们的的省份,支付渠道.这些不经常的改变值完全存在前端浏览器内.
2 接口无效调用
一般页面基本分为 上面条件选择,中间查询按钮,下面分页的具体内容,然后下一页的导航条;
很多时候我们JAVA同学喜欢分页插件,其实那个分页插件很弱智,它只要你提供一个主查询SQL,它就在外面包一层用来统计总数
主查询语句, 有的插件还提供LIMIT 选择
SELECT A.*,B.*,C.*
FROM A
LEFT JOIN B ON A.ID=B.ID
LEFT JOIN C ON A.ID=C.ID
WHERE 1=1
AND A.X=?
AND B.Y=?
AND C.Z=?
ORDER BY A.AGE DESC那么统计总数是:
SELECT COUNT(*)
FROM
(
SELECT A.*,B.*,C.*
FROM A
LEFT JOIN B ON A.ID=B.ID
LEFT JOIN C ON A.ID=C.ID
WHERE 1=1
AND A.X=?
AND B.Y=?
AND C.Z=?
ORDER BY A.AGE DESC
) TEMP;
咋一看 插件挺好的,SQL也没有毛病,其实仔细一看也没有毛病,不就是多了个ORDER BY 嘛!
这个先放下说, 此时此刻其实这两个SQL语句可能在两个接口里, 也许是在一个接口里. 如果在两个接口里,使用浏览器的F12功能查看接口调用.要么喊JAVA打印SQL日志.那么我们在点击下一页的时候,你会发现它会再去统计一次.
很显然这个统计是没有必要的,有的同学会找借口说是看实时信息. 实时的信息,需要点击下一页吗?
很显然对方没有对需求做得很清晰! 工作没有做到位!
插件只能统计总数,不能统计其它的,如果你需要统计金额SUM(),平均每单费用. 那么你的另外写个SQL并开发个接口提供前端.也就是前端页面的这部分.
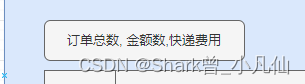
SELECT SUM(A.MONEY),AVG(B.FEE)
FROM
(
SELECT A.*,B.*,C.*
FROM A
LEFT JOIN B ON A.ID=B.ID
LEFT JOIN C ON A.ID=C.ID
WHERE 1=1
AND A.X=?
AND B.Y=?
AND C.Z=?
ORDER BY A.AGE DESC
) TEMP;
SQL 就这样写,我们都是搬运工而已!
因此这两个接口完全可以合并在一起
SELECT COUNT(*),SUM(A.MONEY),AVG(B.FEE)
FROM
(
SELECT A.*,B.*,C.*
FROM A
LEFT JOIN B ON A.ID=B.ID
LEFT JOIN C ON A.ID=C.ID
WHERE 1=1
AND A.X=?
AND B.Y=?
AND C.Z=?
ORDER BY A.AGE DESC
) TEMP;没有数据的时候 分页SQL接口是否要调用?
在分页插件,那是一定的. 所以我们可以通过统计接口来判断是否有数据,有数据就,无数据就别去查询了,否则那就慢给你看!
因为没有符合条件的数据,MYSQL 会遍历所有,然后返回LIMIT 10给你, 这个遍历那怕是索引也会很久. 好比你明明知道LIST<CHAR>里面没有数字, 你要求LIMIT ,那么它会从头到尾查一个遍给你看.
为什么你会明明知道? 因为COUNT(*)返回是零! 其实你是不知道的,没有意思到而已.
3 默认条件
我们草台班子,急于求成, 一般都会把这个默认条件给忘了. 让用户随意选择时间范围, 数据量一大,基本就是全表扫描,那怕你创建索引也是没有用的!
4 深翻页
有很多技术来解决深翻页情况,实际上没有实际价值. 最好就是明确告诉对方 超过1千行,或者1万行.多余的请通过其它途径,要么导出,要么增加选择条件.
5 默认排序
一般情况下,我们是提供某个时间的倒排序返回数据, 也就是最新的订单时间.
ORDER BY CREATE_TIME DESC LIMIT 0, 10;
有的时候需要支持返回的字段各种排序,就是让用户点击分页上的字段正反去排序.很多时候JAVA同学就直接把字段传回给DB,然后DB去排序
类似如下伪代码:
IF>> VO.CREATE_TIME IS NULL THEN ORDER BY CREATE_TIME DESC <<END IF
IF>> VO.PAY_TIME IS NULL THEN ORDER BY PAY_TIME DESC <<END IF
IF>> VO.SENDGOODS_TIME IS NULL THEN ORDER BY SENDGOODS_TIME DESC <<END IF如同上面的SQL 3个表,返回未知数的字段,那么可以任意个字段可能去排序.
MYSQL排序能力是不强的,它需要借助索引,否则它SORT内存超过了,会使用磁盘文件进行排序.
建索引,你不可能建那么多字段吧?
那么如何解决呢?
方法一 前端页内排序,就是说用户点击其它字段排序的时候,就当前页做排序,下一页不做
这个方法 用户会感觉有点不太好! 因为用户点击的是第一页排序,到了第2页就变回默认的排序字段.
方法 二 页面上只提供默认的几个排序字段 页内不支持其它字段排序. 前提是产品经理做好需求调研.
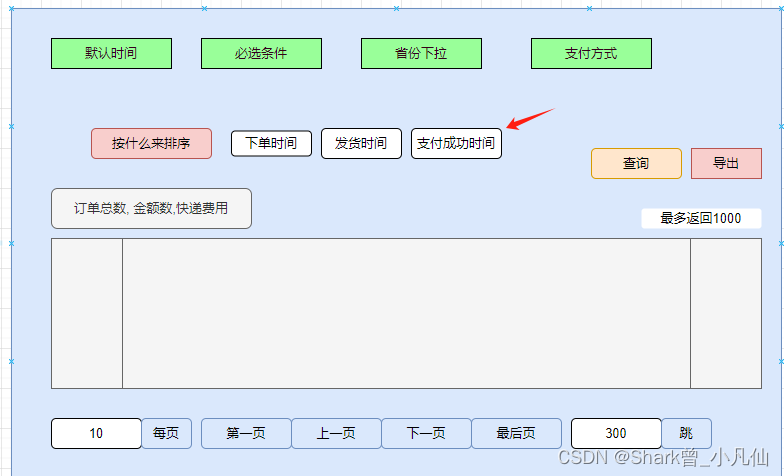
方法 三 数据全拉到前后端排序
因为我们规定了只返回1K,或者1W数据, 那么我们可以在后端进行排序,比如说LIST<MAP> 只要前端页面的PAGE_ID,那么就保留该数据在JVM内. 不过这样设计导致后端有状态化,导致JVM内存占用太多的情况.
那么把数据全拉到前端缓存起来,也是可以的!
C 后端的DAO方法复用
JAVA 如何优化,在下不敢瞎逼逼. 不过遇到DAO方法复用问题. 很多情况下JAVA同学为了赶进度,会无限拔高复用的地位! 导致无法理解复用,为了复用而去复用.视乎违背了面向对象设计思想!
汇编语言有子过程,C语言有函数,C++语言有类, 数据库有存储过程. 这些都是为了重用,复用而实现的. 因为程序都是数据结构+算法. 那么程序的基本结构都是一致的,唯独数据不一样而已 好比说
1+1=2;
2+2=4;
4+4=8;
8+8=16那么抽象成 X+Y=Z
那么我们可以写成C函数如下:
int add(int x, int y)
{
return x+y;
}这样我们就可以重用该函数,当遇到其它数字加法的时候.就可以重用该函数.
类和对象也是这样,抽取共同拥有的方法和属性,
然而 DAO方法复用却走了极端. 如果只是简单地把表当作一个类,每行数据当成一个类的实例化对象,好像没有什么问题!
问题在于把多表关联后的结果当作个VIEW OBJECT对象. 那问题有点大!
比如说 用户查看订单, 商家查看订单,商城查看订单, 都是以订单对象为主, 除了订单对象外还要LEFT JOIN 其它的表. 假设拿商城看订单情况,假设是5张表的话,
SELECT A1.*,A2.*,A3.*,A4.*,A5.*
FROM A1
LEFT JOIN A2 ....
LEFT JOIN A3 ...
LEFT JOIN A5 ....
WHERE 1=1
AND A1.X=?
....
AND A5.Z=?
ORDER BY A1.CREATE_TIEM DESC
LIMIT 0,10;通过MYBAITS新功能自由地把结果集映射到VIEW OBJECT对象上. 那么这就是某个DAO方法之一
然后用户也用该方法,商家也用该DAO的方法,返回的属性,大部分不用,只用其中某些属性,然后打包成JSON格式返回给前端. 也许直接丢给前端,然后前端自己裁剪.
这有什么问题吗?
1 用户和商家查询次数,自然是比商城多得多,那么造成无用的数据来回传来删减.
数据从DB拉到应用端什么时候才释放?
(1)ResultSet关闭:一旦ResultSet关闭,JDBC驱动会释放与该ResultSet相关的资源,包括内存。
(2)web请求结束,栈空间自动释放,产生的对象在堆内存中,大概率是在新生代,直到被jvm yonggc回收。
数据库查询返回100个字段,DAO映射了50个字段,另外50个字段会怎么样?
(1)网络传输:所有返回的100个字段数据都会通过网络传输到应用服务器,这里有mysql的内存占用,cpu计算,以及网络消耗(2)在JDBC层面,ResultSet会包含所有100个字段的数据,这些数据会暂时保存在内存中,直到被消费或ResultSet被关闭。这里占用的jvm堆内存中的新生代中,直到被jvm yonggc回收。
(3)DAO只会映射其中的50个字段,剩下的50个字段不会被映射到对象中。但由于数据已经被传输到应用服务器,因此这些未映射的字段依然会占用的jvm堆内存中的新生代中,直到被jvm yonggc回收。
DAO方法返回50个字段,一个服务只要10个字段,那么另外40个字段会怎么样?
包含50个字段的对象会被创建并保留,在jvm 堆内存中的新生代中。这些对象在内存中占用的空间包括所有50个字段的空间。
从上面情况来说 造成 DB端内存浪费,网络包大,JVM 结果集内存占用,如果开启了1-2级别缓存下;
然后 LIST数组内存变大.
2 LEFT JOIN 不必要化
MYSQL 阿里规范要求不超过5个表关联,为什么呢? 主要是因为MYSQL多表个关联能力很弱,所以速度会直线下降. 虽然后期MYSQL8得到了改进. 好像说到这没有问题,多个表就多个表,没啥关系!
问题在于有些查询不需要多个表,比如用户来说他只需要2个表关联,那么多余的3个表会怎么样呢?
那怕WHERE没有提供A3,A4,A5的条件呢? MYSQL依旧去做关联运算,
3 反对SELECT 星
以前SPRING MVC MYBAITS 时候 如果SELECT * 后, DB添加字段会让JAR自动报错.
那个时候是禁止SELECT *的. 可是现在SPRING BOOT 微服务时代,不知道咋的,SELECT * 后DB添加字段,也不报错,可以正确匹配到旧字段. 这样JAVA同学开心得很.
总的来说这就是挖了性能的坑, 影响DB,影响网络,影响JVM内存.
主要的是DB一般就一台,顶多主从读写分离两台来工作, 或许搞个微服务,多台DB来承担.只不过性能的坑继续延后爆发而已.
为什么我比较讨厌复用呢? 因为不好优化SQL啊, 如果要改写SQL,你说怎么改? 一个DAO的方法被复用了,你不知道哪些服务使用了该方法, 要在上面加个FORCE INDEX 索引提示, 有些服务因为加了提升从而导致更加的慢!
其实这DAO复用走了极端, 违背了JAVA的高内聚,低耦合的要求! 成了诗山代码. 本来DAO方法就是个SQL模版, 要加上条件再加上具体值才能形成具体的SQL.MYSQL只能对具体的SQL进行优化分析. ORACLE就不一样,它可以对加了条件的SQL模版优化. 并且自动分析没有必要的LEFT JOIN.
所以在此建议JAVA同学放弃这种DAO复用. 不过就是复制粘贴然后删除没有必要的字段和LEFT JOIN表就是. 再新建个VIEW OBJECT对象来映射结果集. 这样确实工作量有些大, 但是这样业务流程明确,方便日后更改















 3998
3998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









