







数据来源
1. 抖音40天内的数据交互记录,一行数据就是一个播放记录
2. 近600w条数据
分析目的
抖音是一个面向全年龄的音乐短视频社区平台。目前用户众多,有不少人都成为了网红,聚集了大量粉丝。在此希望能看出一些他们之间的共性,帮助后来人少走一些弯路。并结合实际观察抖音运营存的现状,提出一些建议。
字段说明
- uid:用户id
- user_city:用户所在城市
- item_id:作品id
- author_id:作者id
- item_city:作品城市
- channel:观看到该作品的来源
- finish:是否浏览完作品
- like:是否对作品点赞
- music_id:音乐id
- device:设备id
- time:作品发布时间
- duration_time:作品时长
数据库导入
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False # 正常显示负号数据清洗和处理
数据获取:
data = pd.read_csv('douyin.txt')
print(data.head())
print(data.shape) # (5886702, 12)
print(data.info())结果:
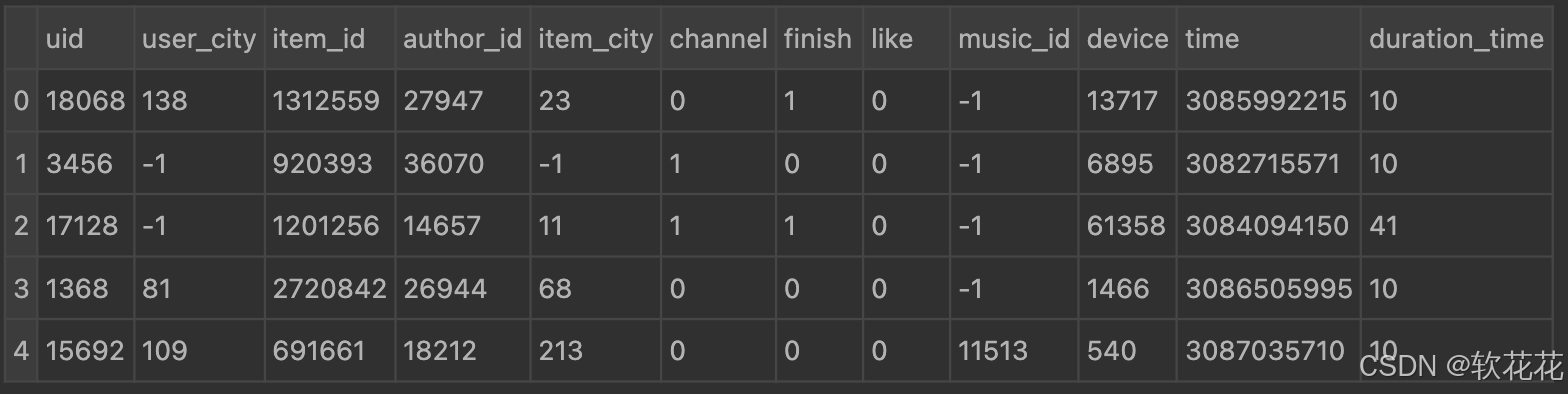
是否存在空值:
print(data.isnull().sum())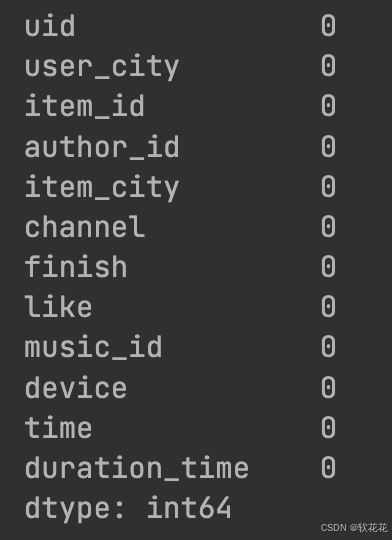
是否存在重复数据:
print(data.duplicated().sum()) # 4924
data.drop_duplicates(inplace=True)
print(data.shape) # (5881778, 12)
# 重置索引
data.reset_index(drop=True, inplace=True)把-1替换成空值:
data.replace(to_replace=-1,value=np.nan, inplace=True)
print(data.isnull().sum())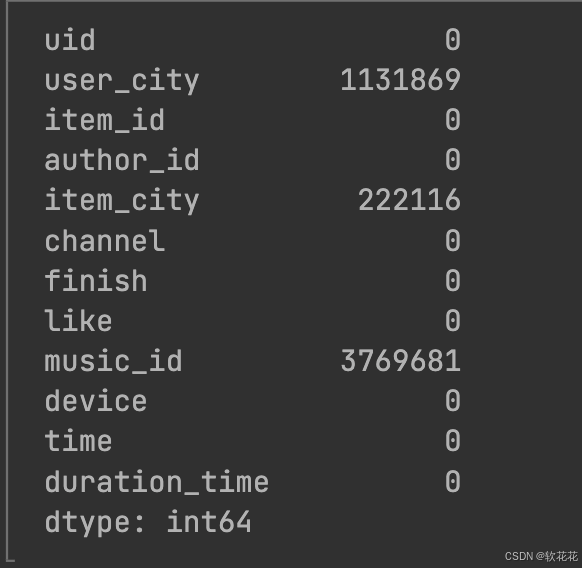
# 去掉空值
data.dropna(axis=0, inplace=True)
# 重置索引
data.reset_index(drop=True, inplace=True)
print(data.shape)去掉不必要字段:
data.drop(labels='device', axis=1, inplace=True)
print(data.info())转换时间格式:提取日期和时间
import time
real_time = []
for i in data['time']:
# 将时间转换成日期格式
my_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(i))
real_time.append(my_time)
data['real_time'] = real_time
print(data.head())
print(data.info())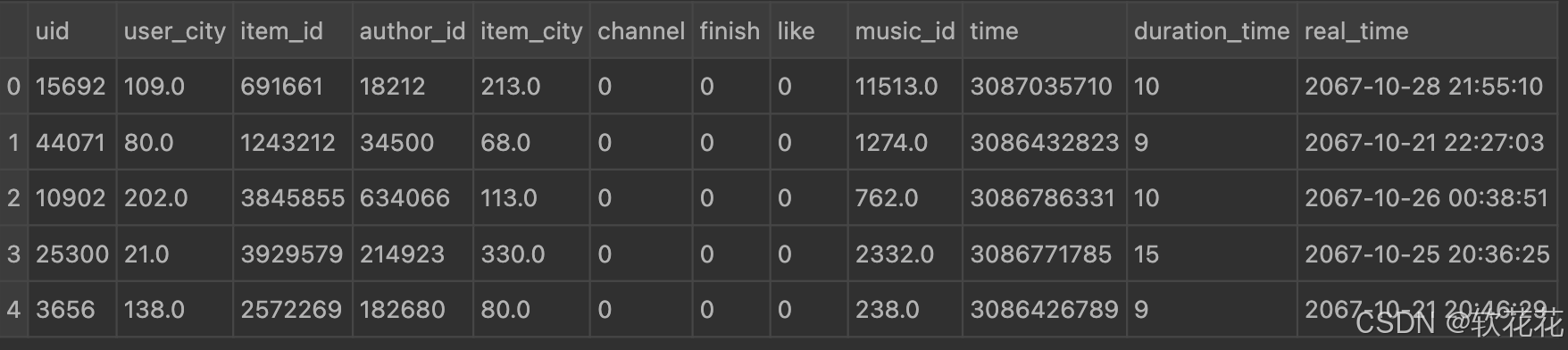
将real_time转换成时间类型,目的就是为了更好的去提取出日期和时间(时间对于分析更有意义)
data['real_time'] = pd.to_datetime((data['real_time']))
data.info()结果:
将日期和时间分别提取出来
data['H'] = data.real_time.dt.hour
data['date'] = data.real_time.dt.date
data.head()结果:

删除time字段
data.drop(labels='time', axis=1, inplace=True)
data.info()数据分析
分析步骤:
1.抖音98.52%的流量都会流向算法推荐视频,获得算法推荐是获得更多播放的关键所在。
2.最重要的始终是题材的选择,初始流量池大更容易获得算法青睐。
3.除去题材外,投稿的最佳时间日常是在0-5点,有平台活动一定要参与。
4.视频时长最好在7-10s,其次是0-6s及23s以内,最长也不建议超过40s。
5.背景音乐最好选择当下最流行的歌曲。
a.抖音播放量的来源分布
b.视频时长与点赞率之间的关系
1.作品时长与播放量之间的关系
2.作品时长和作品数量之间的关系
3.作品时长和完播率之间的关系
4.作品时长和点赞之间的关系
c.背景音乐与点赞和完播率之间的关系
1.热门音乐ID
2.热门音乐的点赞率与完播率
抖音播放量的来源分布:
channel = data.groupby(by='channel').count()['uid']
print(channel)结果:

作品时长与播放量的关系:
duration = data.groupby(by='duration_time').count()['uid']
print(duration)
plt.plot(duration)
# 限制x轴的大小
plt.xlim(0, 50)
plt.ylabel('播放量')
plt.title('作品时长与播放量之间的关系')
plt.show()结果:

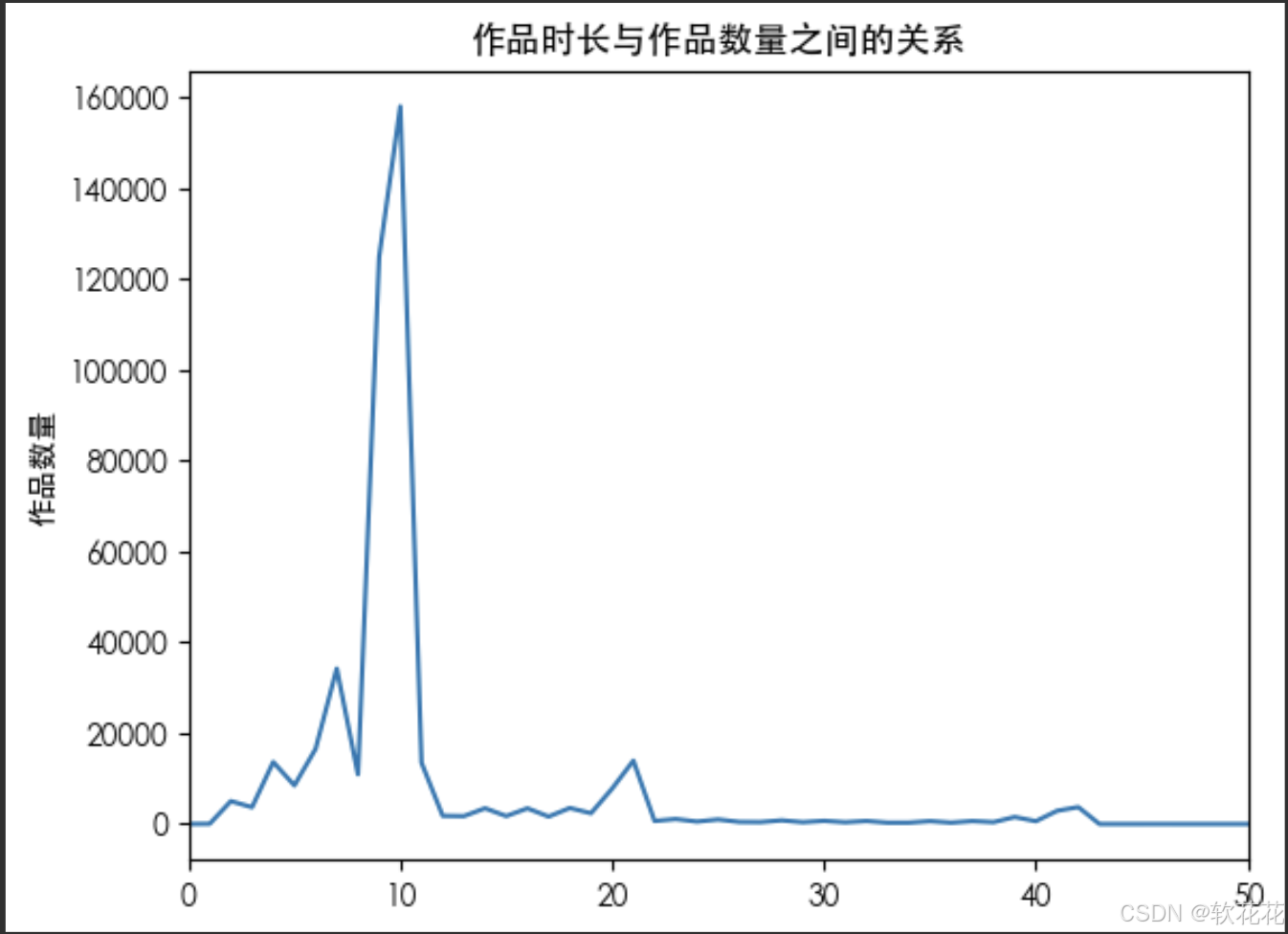
作品时长和作品数量的关系:
duration_nums = data.groupby(by='duration_time')['item_id'].nunique()
print(duration)
# nunique() 对去重以后的数据进行个数统计
plt.plot(duration_nums)
# 限制x轴的大小
plt.xlim(0,50)
plt.ylabel('作品数量')
plt.title('作品时长与作品数量之间的关系')
plt.show()结果:
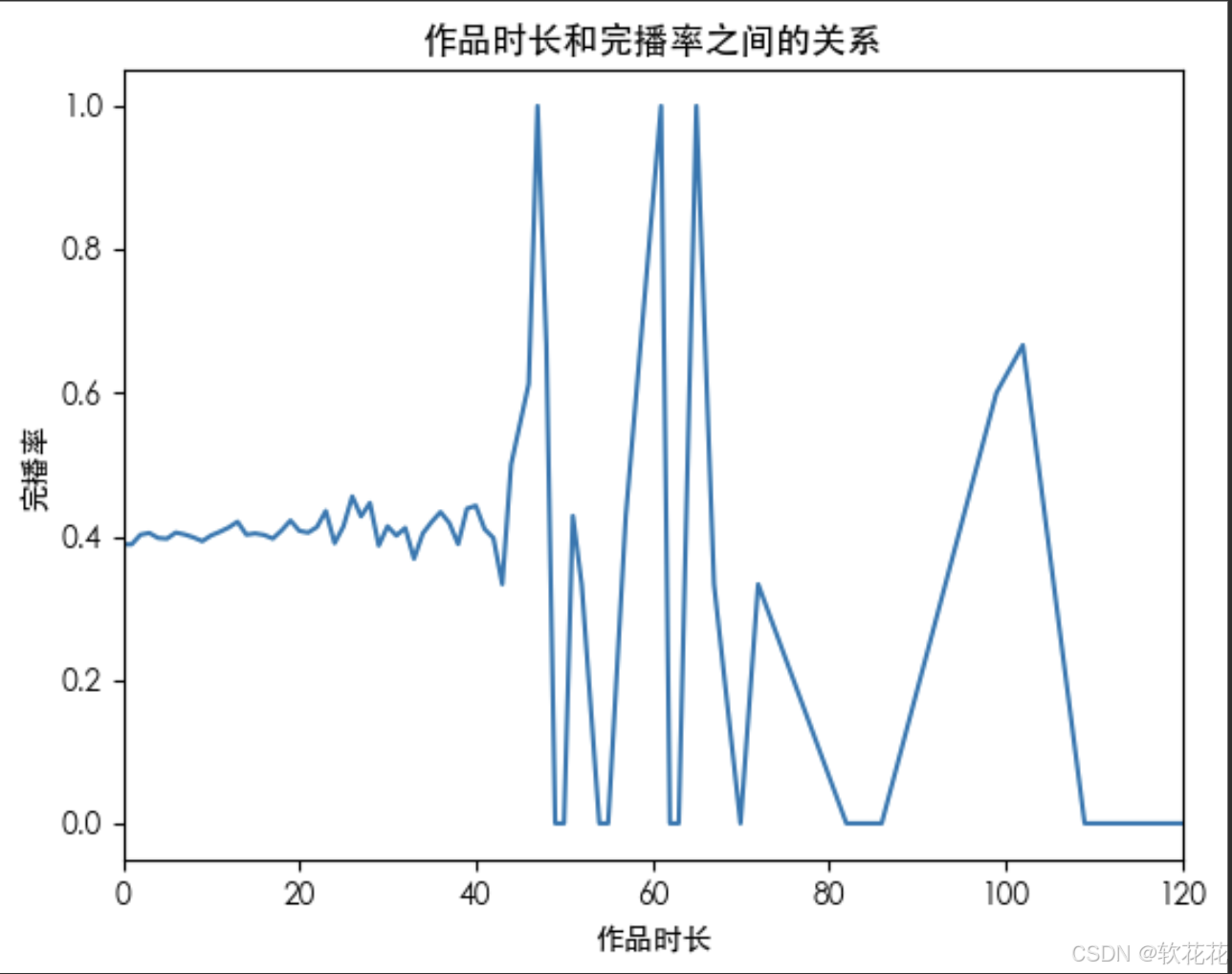
作品时长和完播率的关系:
duration_finish = data.groupby(by='duration_time')['finish'].mean()
plt.plot(duration_finish)
# 限制x轴的大小
plt.xlim(0,120)
plt.xlabel('作品时长')
plt.ylabel('完播率')
plt.title('作品时长和完播率之间的关系')
plt.show()结果:
作品时长和点赞行为的关系:
duration_like = data.groupby(by='duration_time')['like'].mean()
plt.plot(duration_like)
# 限制x轴的大小
plt.xlim(0,50)
plt.xlabel('作品时长')
plt.ylabel('点赞')
plt.title('作品时长和点赞之间的关系')
plt.show()结果:
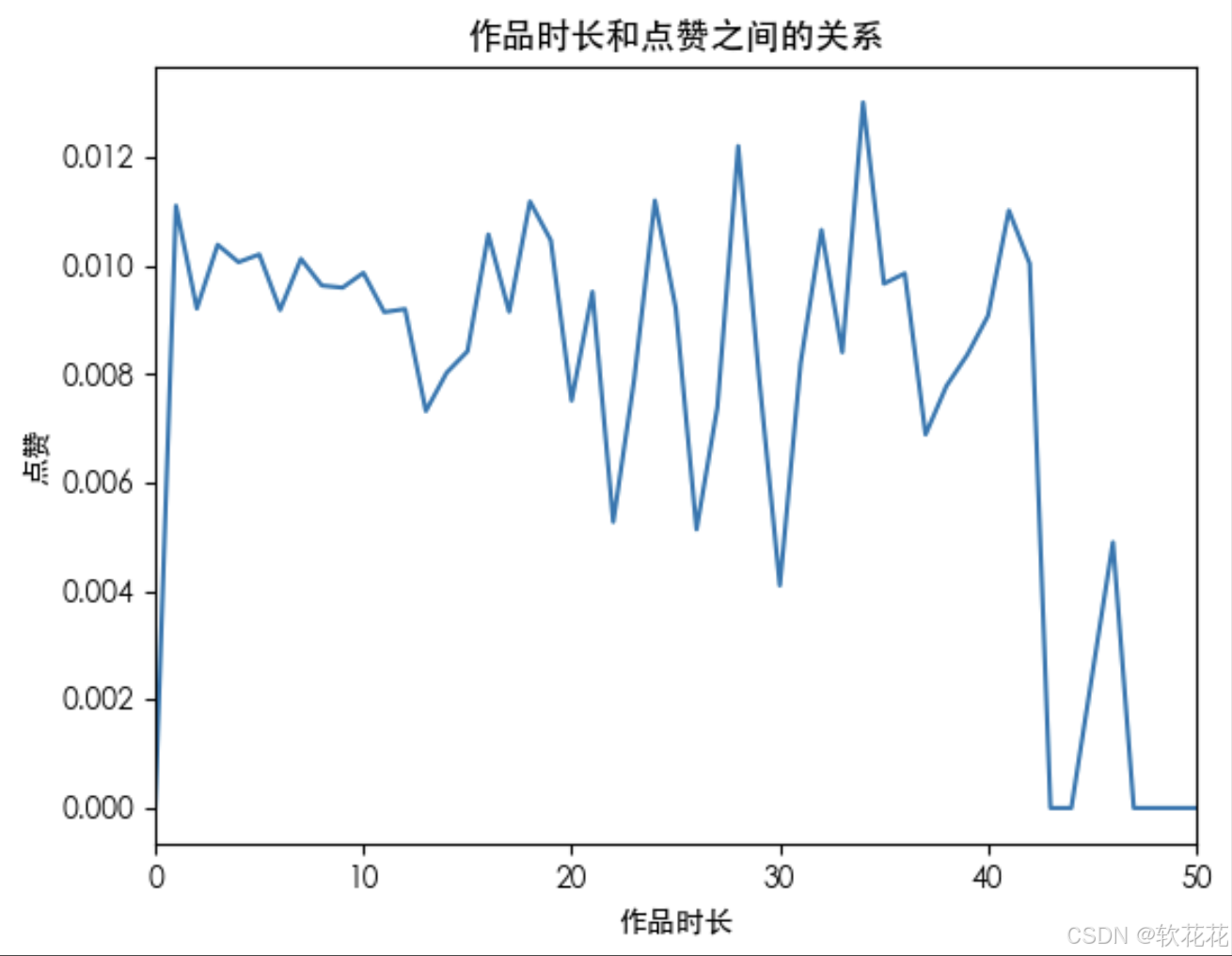
观察结果:
1.大部分作品分布在0-13S中, 总体来说0s-23s之间都有一定数量的投稿,23秒之后就比较少了
2.播放量的分布与作品数量成完全正相关
3.完播率0-47s内总体在40%左右,47s之后开始剧烈波动,无可参考性
4.点赞率0-22s内总体在1%左右,22s之后开始剧烈波动,无可参考性
背景音乐与点赞和完播率的关系:
music = data.groupby('music_id').count()['finish']
print(music)
plt.plot(music)
# 限制x轴的大小
plt.xlim(0, 125)
plt.xlabel('音乐ID')
plt.ylabel('完播率')
plt.title('音乐ID和完播率之间的关系')
plt.show()结果:
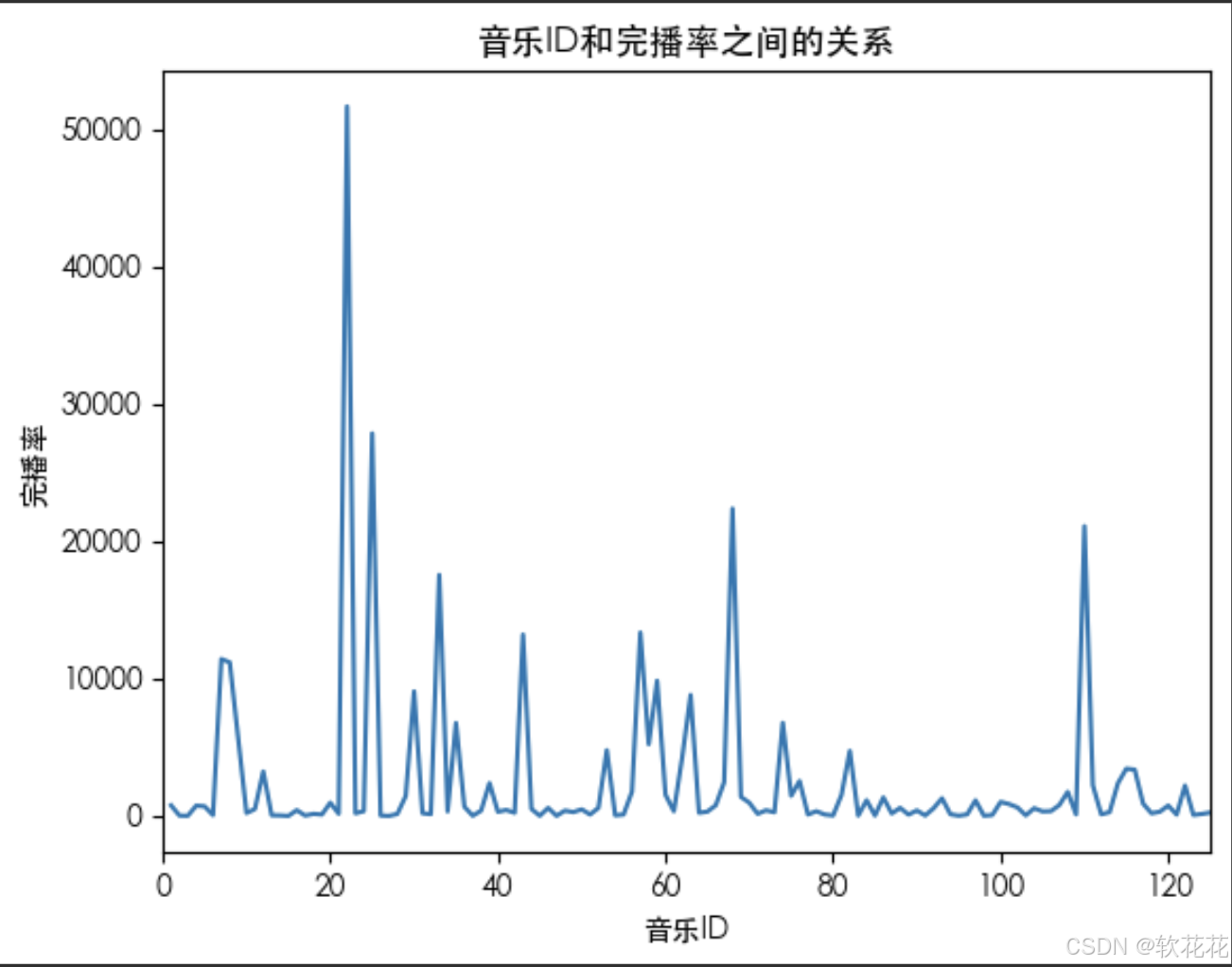
排名前十的热门音乐ID
tip10_music = data.groupby('music_id')['uid'].count().sort_values(ascending=False).iloc[:10]
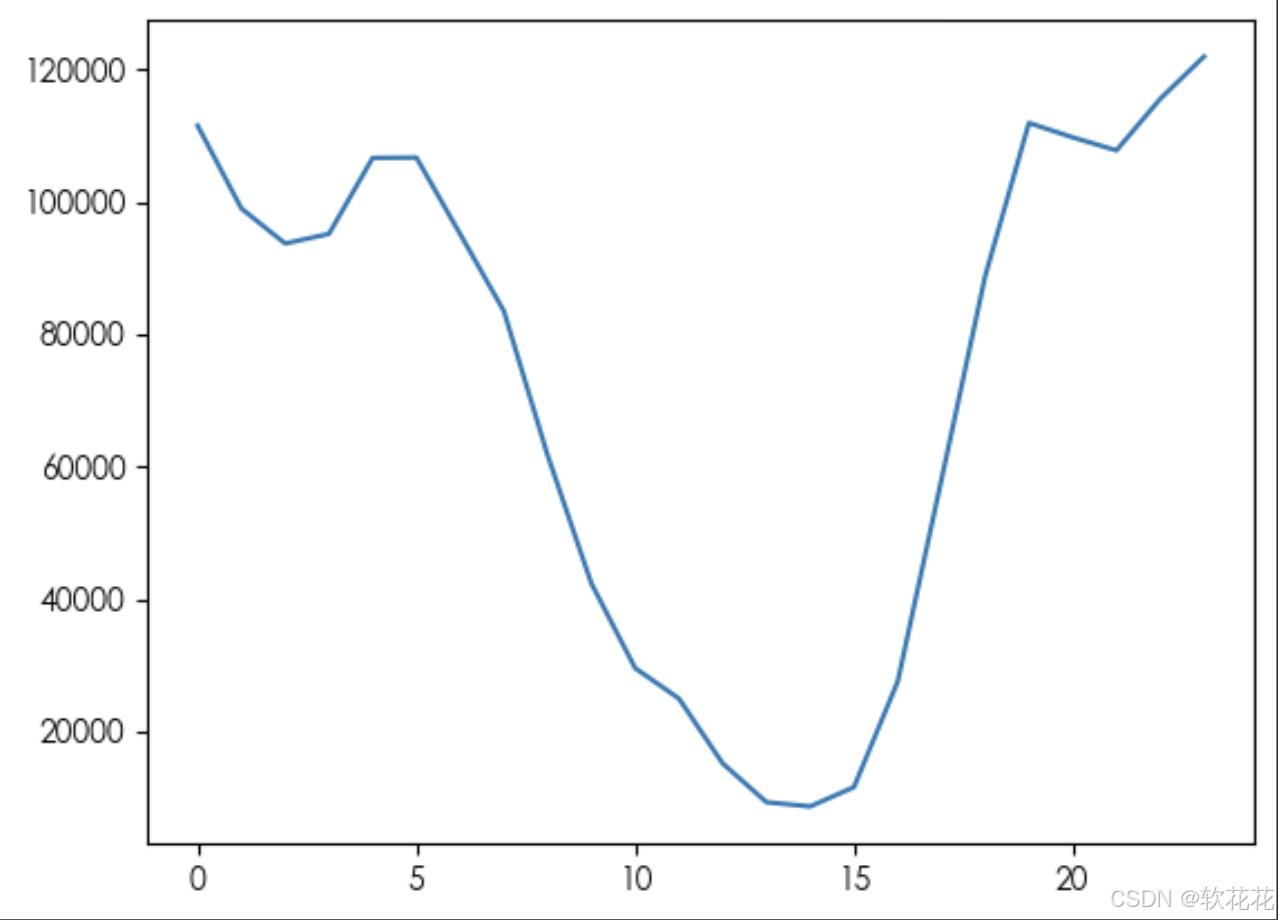
print(tip10_music)发布作品的时间和播放量之间的关系:
time_plays = data.groupby(by='H')['uid'].count()
plt.plot(time_plays)
plt.show()结果: 下午三点到凌晨5点的播放量较高
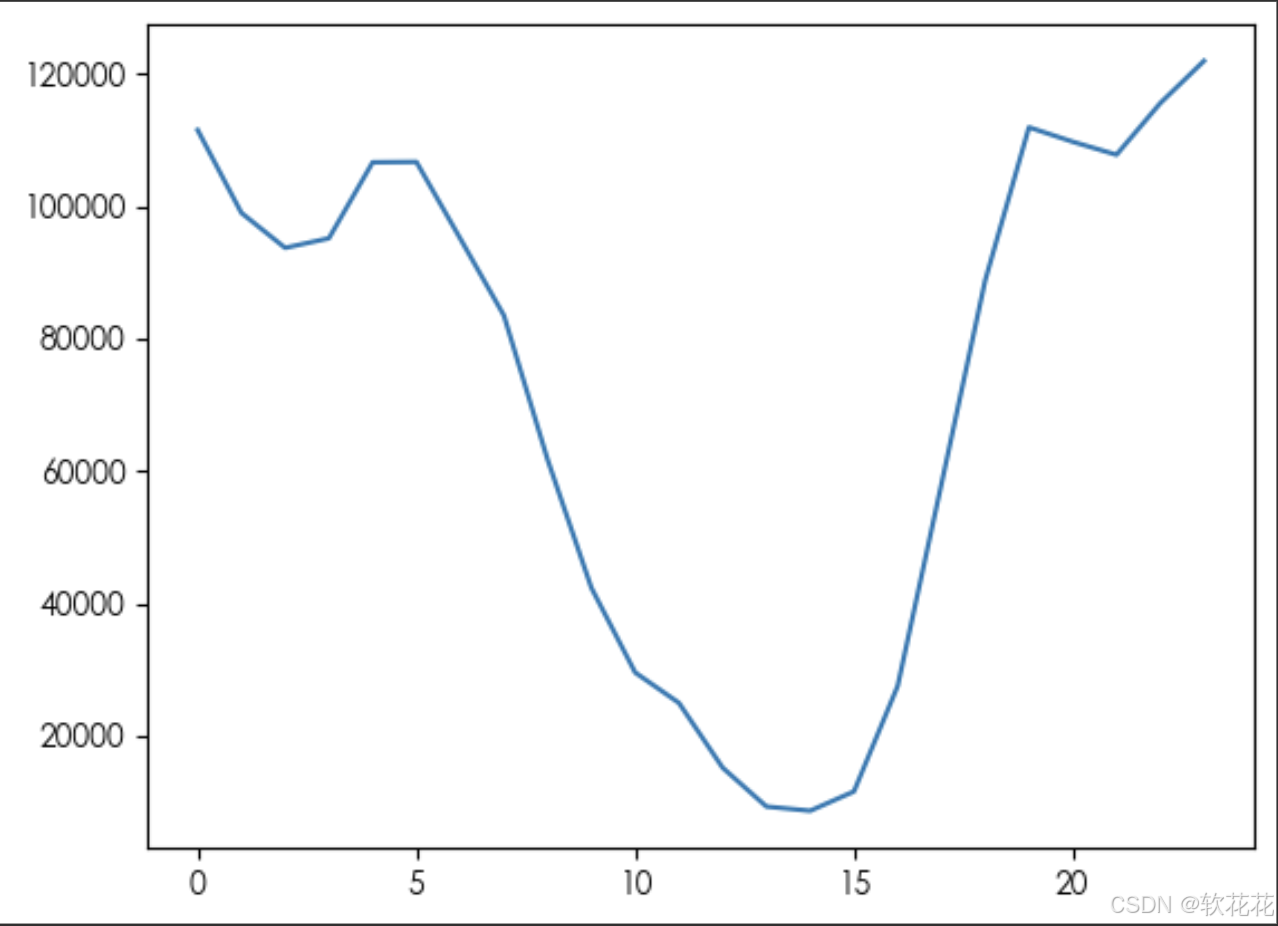
发布作品的时间和点赞行为的关系:
time_plays = data.groupby(by='H')['like'].count()
plt.plot(time_plays)
plt.show()结果:下午三点到凌晨5点的点赞行为较多



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









