









用汇编分析C++程序
O 、引言
学C++也有很长一段时间了,也写过一些程序。但学着学着,总被她强大的语法等等搞晕。以前用起来从不犹豫的东西,用着用着有时候就感到非常不确定。如果能看看编译器所对应生成的汇编代码,就会对此有深入的理解。让我们通过对C++程序对应生成汇编的分析,来了解C++的语法。也可知她与C的异同。
我们想通过对C++程序得到汇编代码,可通过编译得到。介绍几种常用编译器的获取汇编码的方法,比如我们的源文件是 Test.cpp:
1. Microsoft Visual C++:cl /FAs Test.cpp
也可以通过加上优化选项 /O1 、 /O2等得到优化后的汇编代码。
2. Borland C++: bcc32 –S Test.cpp
3. Gcc/G++: g++ -o AssemFile.asm -S Test.cpp
对于前两种,默认在当前目录下,获得与源文件相同名,以.asm为后缀的MASM汇编文件。对于G++,得到的文件名可–o 选项后所跟的文件名相同的汇编文件。
当然,你的编译器是安装好的。Borland C++与 MSVC++生成的汇编文件大致兼容,但G++生成的PowerPC汇编代码与前两种生成的不同。本例中我们用MSVC++所生成的汇编代码来分析。
如果你的MSVC++环境变量没有设置好,我们写一个BAT文件:
因为我的MSVC++9.0根目录在D:/Program Files/Microsoft Visual Studio 9.0/VC下,所以你的VC9DIR可根据你的实际情况更改之。在命令行下运行这个BAT,然后可以用MSVC++的命令行模式了。一切准备就绪,我们切入正题。
一、 引用
“引用”是C++中引入的重要概念之一。指针的不安全使人们对它诟病颇多,C++引用机制恰如其分的解决了这一问题。在C++语法上,引用和指针是不同的,但在内部实现机制上,它们是完全相同的——所以,引用和指针在机器码层次没有效率高下。
来个例子,先分析之。我们有一个Test.cpp文件如下:
我们编译之:cl /FAs Test.cpp。便在当前目录下获得 Test.asm 汇编文件。打开之,如下:
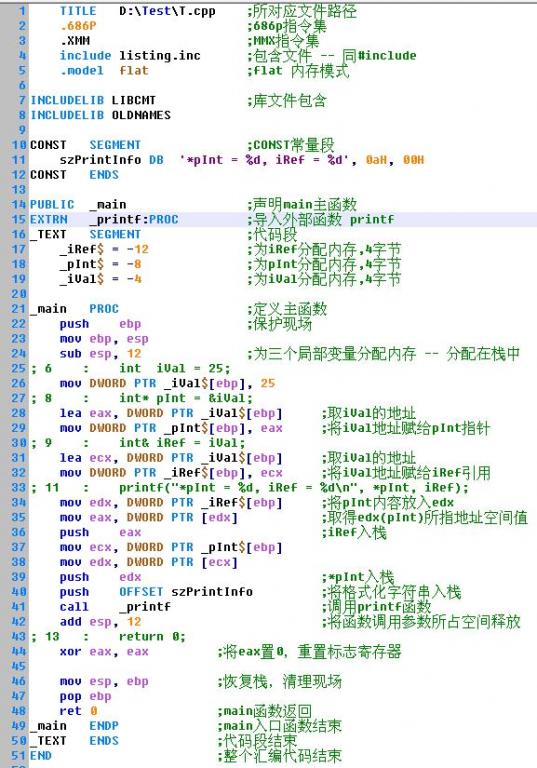
为了容易理解,我将部分稍微改动了下。但有详尽的注释,相信很容易理解。我们看到,程序将局部自动变量分配在栈中。而将常量字面值字符串放入CONST段。代码很显然在_TEXT段。在使用外部函数时,需用exrern导入。就像printf——为什么我们不用std::cout实现输入呢?因为这样生成的汇编文件确实有点大,因为会导入很多的库函数,可能只这些导入代码就得200多行!为了理解简便,我们用printf替代之——反正效果一样!
我们稍微分析下,就可以看到iVal、pInt和iRef所占空间都是4字节。很容易理解,因为我的机子系统是32位WinXP。其余不重要,唯有27~42行是重点。对照注释,我们发现,对pInt指针和iRef引用的实现代码一模一样!都将它们用iVal的地址初始化:
而在使用它们时,采取措施也一模一样!都是先取得其所存放地址值,然后通过这个地址取得相对应DWORD双字int值!由此看见:在内部实现上,指针和引用完全一样!
既然指针和引用实现机制完全一样,为什么在C++中还要引入“引用”的概念呢?引用是对程序员来说的,我们可以通过引用,写出更安全、更健壮的程序来。我们接着看:
二、 结构
我们接着看结构在内存中的存放方式和其使用。依然看程序:
呃,很简单的程序。但可以反映出很多的知识来!依然cl /FAs Test.cpp,我们挑重要的代码段来看:
1. Main函数对应汇编代码:

有详尽的注释,看懂应该不难。可见,在调用函数f之前,分配了两个临时变量用以复制传递函数返回值!因为在函数调用时,栈的某处已经存放的是临时变量temp1的指针(看69和70行),在函数f中,最后返回时,将Re的值全部复制到temp1中——当然是通过这个指针来作为桥梁实现的。
2. f函数对应的汇编代码:

在_TEXT代码段中,我们可以发现这样的函数。首先用public声明函数f,然后为局部变量Re分配12字节空间。等等!!我们的结构中只有2个int占4字节,ch占1字节,总共9字节。为什么给Re分配了12字节?!!这就是编译器的高深之处了。数据结构中的数据变量都是按定义的先后顺序来排放的,第一个数据变量的起始地址就是数据结构的起始地址,结构体的成员变量要对齐排放。所以编译器自动帮你实现了内存对齐——为ch扩展了3个字节的对齐空间。保证它们都对齐在以4为边界的内存处。
在49行,函数返回时,首先将临时变量指针存入eax所以在main函数那张图上对应74行之下代码都可以顺利执行。通过此例看出,对一个结构的返回,来来回回需复制3次!——这是不优化的情况。其实对于这种情况,再优化也得复制2次!!对于这样的小结构来说还不算什么,但对庞大的结构来说,就必须考虑其开销了——不管是空间还是时间开销!这也是为什么鼓励通过指针或引用来传递返回值获传递参数的原因了。
注意:对于稍大的结构来说,通过传递指针或引用来调用参数是肯定没错的。但对像int、float、char等等单个变量,用引用或指针来传递参数或返回值,是得不偿失的!因为只需用一个寄存器便可完成传递,而不必再执行开辟局部变量、临时返回变量空间,对指针进行操作等等繁杂的步骤了。
三、 类
接着我们看类的实现。依然是例子。
代码依然很简单。我们分别用struct和class声明了两个类:_A和 _B。有什么区别吗?_A是用struct声明的,成员函数f是非虚的;_B是用class声明的,成员函数f是虚函数,除此无他。接下来的事情变得简单有趣:依然 cl /FAs Test.cpp。获得汇编文件Test.asm。打开之,呃,汇编代码有些长。
我们曾经在书本上这样学:“struct和class都可以声明类,除了struct的成员默认是public的,class声明的成员默认是private的之外,并无区别。”这句话非常对。我们看其汇编代码(有些地方我为了理解方便,把那些诸如“@??_C@_06PHGHDMGF@?$CFd?0?5?$CFd?$AA”吓人的字符串改为相对应有意义的字符串了):
1. Main函数:

依然_TEXT代码段中。开始处有三个public函数声明。通过详尽的注释,可以轻易看出它们分别是类_A、_B的成员函数及构造函数——但是我们并没有给_B声明构造函数啊!我们已经知道,类如果没有构造函数,则编译器会为它自动生成一个无参数构造函数。但为什么_B自动生成了,而_A却没有呢?噢!_A中的f函数不是虚函数(这与是用struct还是class声明类无关)。
然后为局部自动变量a、b分配空间。a有8字节,b有12字节。等等,_A和_B的数据成员一模一样,我们知道,成员函数是不占用类对象存放空间的,那为什么b的空间比a多呢?显然这儿不是为内存对齐而准备的!仔细一瞧,_B的f函数有virtual关键字——这就决定了_B声明的对象都会自带一个虚函数表指针(VfTable),我们知道指针占4字节,所以b对象就比a对象多了4字节空间。
通过注释C++代码看出,然后构造了两个变量。通过汇编看出,a对象没有任何操作——因为它没有缺省构造函数,编译器也不会为其生成。而通过我给出的汇编注释可看出,对b对象的构造,先将b的地址放入ecx,然后调用其构造函数。我们只需记住:“在调用对象的成员函数之前,必先将对象指针放入ecx,然后紧接着调用函数!”在成员函数中,ecx中的指针就被当做this指针。简单而深刻!
接下来的代码简单易懂——分别为a、b成员赋值。然后分别调用a和b的成员函数f——首先将对象地址放入ecx,接着调用。Main函数很是简单。我们接着一一解析其余三个函数。
2. _B::_B:编译器自动生成的构造函数

先为this指针在栈中分配4字节空间。将ecx中的this指针保存到栈中。然后再184行设置其虚函数表。这个__B@@VfTable是什么呢?稍前我们可以看到:

可以看到,在虚函数表中只有169的一项:__B@@f即是_B的成员函数f了。其实,除了虚函数
表外,还有其他的东西。比如RTTI运行时信息、类继承等等信息。你可以自己看下。通过这儿,
我们理解了为什么编译器非要给没有构造函数的类生成构造函数的原因——因为它要进行虚函
数表、设置RTTI信息等等一系列操作!
3. _A::f函数

通过注释,很容易理解。76行的szPrintInfo就是字符串“%d, %d”。其余均无难度。
4. _B::f函数

和_A::f的实现并无多大区别。
通过上面一系列犀利的操作,我们可以得出下面结论:
1> 类的数据成员在内存中的存放是连续的,存放次序与类体中的声明次序一模一样。
2> 类的数据成员如果没有对齐,有的编译器会为之自动对齐——注意,这儿是“有的编译器”!
3> 如果类没有任何构造函数,且它有虚函数时,编译器必须为之自动生成一个默认无参数构造函数。否则,不进行任何自动生成操作。
4> 类的构造函数(无论是自己写的还是编译器自动生成的)中,都会先设置虚函数表——如果此类有虚函数的话。
5> 类的所有成员函数(包括构造与析构),都不占用对象的存储空间——因为它们都是在外部的。
6> 如果一个类有虚函数(可以是多个),则其声明的对象在开头4字节有一个虚函数表指针(VfTable)。当类没有虚函数时,并不会有虚函数表产生。
7> 类对象在调用成员函数(包括构造与析构)时,必先将对象地址存放到ecx中,紧接着(注意这三个字)调用其成员函数。
8> 在类的成员函数中,函数通过传递来的存放于ecx中的this指针来引用数据成员。
我的总结就是这些。你可以通过查看继承、模板、RTTI、多态等等C++机制的汇编代码可以获得其实现机制——强烈建议你这么做,这样,我们学到的不只是怎样用这门优雅的语言,而更会了解其本质!
四、 小结
整整一个下午,终于将这篇帖子写完了。近来看《编程卓越之道——运用底层语言思想编写高级语言代码》,看不到几页,便顿足长叹——不仅是为其中各种语言的神奇玄妙而感叹,更为作者敏捷的才思、无处不在的智慧所赞叹!不管你用不用汇编,不管你用不用C++,不管你是否想了解语言的本质,我还是强烈建议你看看这本书,它带来的不仅是对高级语言的汇编底层解释,更是展示给了我们更深、更玄奥、更神奇的东西!!
我们在写代码的时候,如果不了解其最终生成的东西是怎样的,便不会写出更好的代码来。我非常庆幸自己遇到了这本书,它彻底解决了我以前的种种疑惑,更教会了我怎样通过挖掘高级语言代码的底层实现,来发掘高级语言中隐藏在深处的宝藏!!!
就这样。如果还有什么疑惑,非常愿意和你交流。我的联系方式:
--Time: 2010.6.7
--Email:zyfgood12@163.com
--Blog:http://blog.csdn.net/ZhangYafengCPP
【转载请注明出处】















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









