






一、堆
概念:一种有特殊用途的数据结构,用来在一组频繁变化的数据中查找最值。
性质:
1.堆是一个完全二叉树(除叶子节点外,每个节点都含有两个子节点)。
2.堆中某个节点的值总是不大于(大根堆,最大堆)或不小于(小根堆,最小堆)其父节点的值
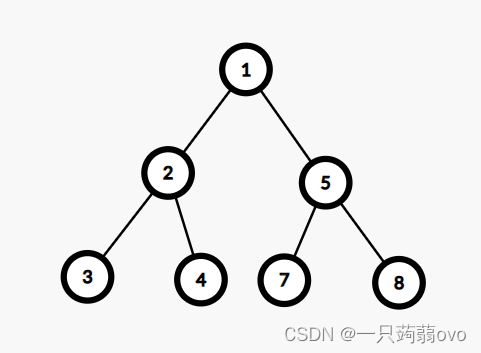
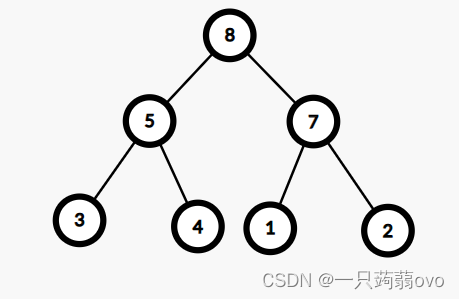
存储方式:
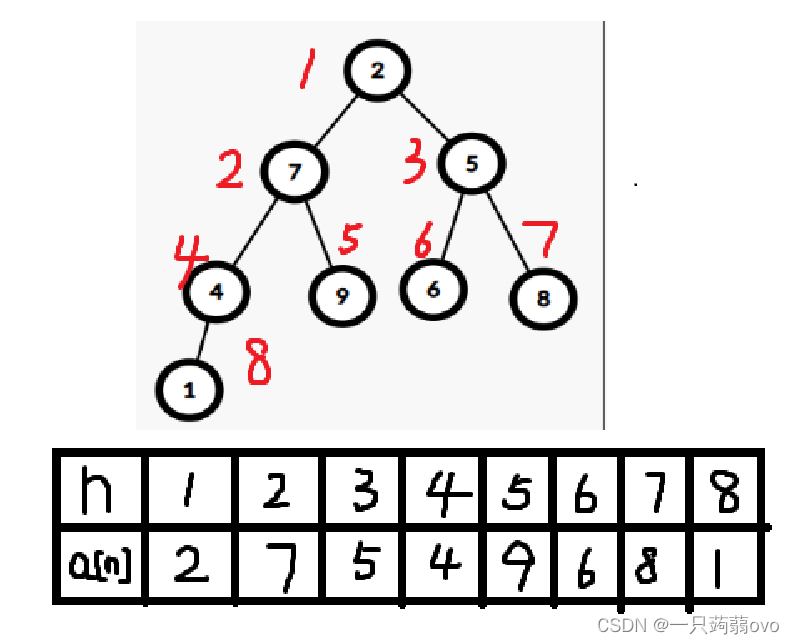
对于一个线性的一维数组,将其转化成完全二叉树。
以线性方式存储完全二叉树,每个节点与其子节点的关系为 :
child1=parent*2,child2=parent*2+1
二、堆的基本操作
1.节点的向下调整
对于一个完全二叉树,当根节点的两个子树都是堆,如何将整个树变化为堆
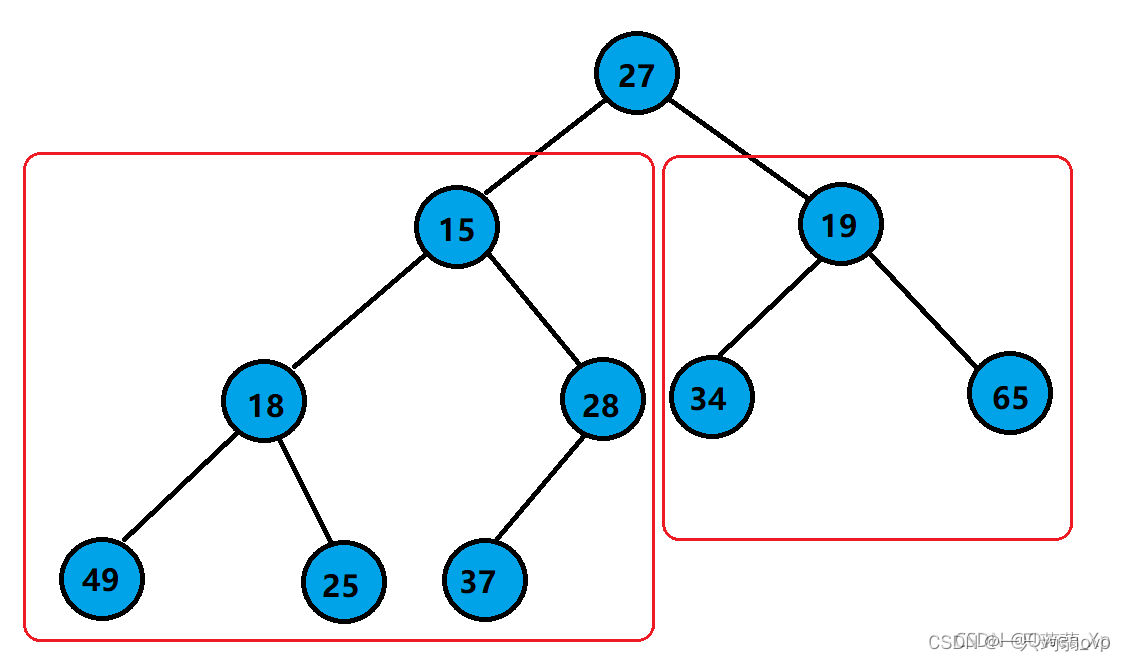
如图,此时根节点的两个子树都是小根堆,要想将整个树变为堆,需要将根节点向下调整
以一般情况考虑节点的向下调整:
①当父节点存在两个子节点:
将左节点与右节点相比较,选出较小的节点 min 与父节点比较交换,并且将此时的父节点移向子节点,继续进行操作,直至无子节点。否则直接返回(此时父节点已经小于子节点了,满足小根堆的性质)
if(a[min]<a[parent])
{
swap(a[min],a[parent]);
parent=min;
}
else return ; ②当父节点有且仅有一个左子节点:
将父节点与左子节点进行比较,同上
if(a[child1]<a[parent])
{
swap(a[child1],a[parent]);
parent=child1;
}
else return ; 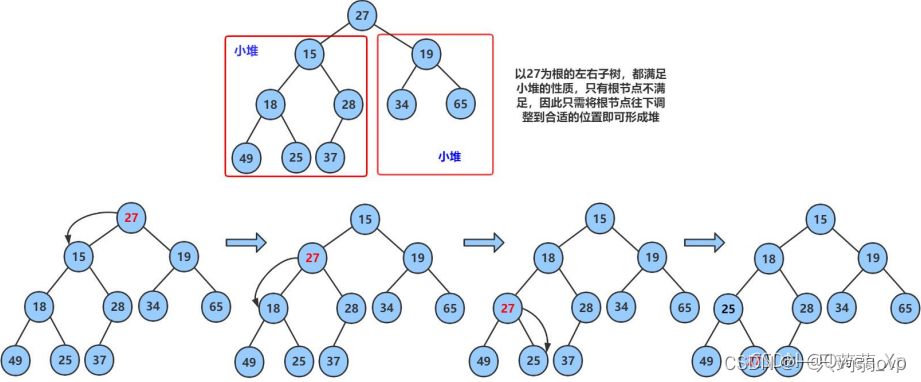
向下操作的伪代码:
void heapdown(int x)// 向下调整
{
while(1)
{
if(x>n) return ;
int child1=x*2;
int child2=x*2+1;
int min=child1;
if(child1>n) return ; // 无子节点
if(child2>n) // 无右节点,只考虑左节点
{
if(a[min]<a[x]) // 小堆
{
int t=a[min]; //swap(a[child1],a[x]);
a[min]=a[x];
a[x]=t;
x=min;
}
else return ;
}
else
{
if(a[child1]>a[child2]) min=child2;
if(a[min]<a[x]) // 小堆
{
int t=a[min]; //swap(a[child1],a[x]);
a[min]=a[x];
a[x]=t;
x=min;
}
else return ;
}
}
}2.堆的创建
根据以上将一维数组转化为完全二叉树,再将该二叉树变化成堆(大根堆,小根堆均可),下面以小根堆为例创建。
从上述来看,当完全二叉树变得非常混乱时(根节点与子节点没有规律的大小关系),可以采用递推的想法,从叶子节点的父节点开始向下调整,这样当某层的节点都进行了向下调整的操作时,该层的每个节点都是一个以自己为根节点的小根堆,一直推导到二叉树的根节点。
for(int i=n/2;i>=1;i--) heapdown(i); //从叶子节点的父节点开始,往上每个节点都进行一次向下操作3.堆的插入操作
在堆中插入一个新的元素,并通过操作保持堆的性质(以小根堆为例)
①将堆的元素个数加1,并且将插入的元素放入二叉树尾端
②将该节点向上调整,保持堆的性质
关于向上调整
本质和向下调整一样,都是为了保持堆的性质,只不过是向下调整的逆向
这里与向下调整有不同的地方:因为向下调整操作对子节点是未知的(不知道是否存在某个子节点,需要判断边界和左右节点),而向上调整都是已知的,不需要判断边界,更简便些。
void heapup(int x) // 向上调整
{
int parent=x/2; // 找到父节点
while(parent>0)
{
if(a[parent]<a[x]) return; //比较
int t=a[x];a[x]=a[parent];a[parent]=t;
x=parent;
parent=x/2;
}
}
4.堆的删除操作
①堆的删除都是根节点删除,将最尾端的元素与根节点交换。
②再进行根节点的向下调整
a[1]=a[n];
n--;
heapdown(1); // 向下调整操作三、堆的应用
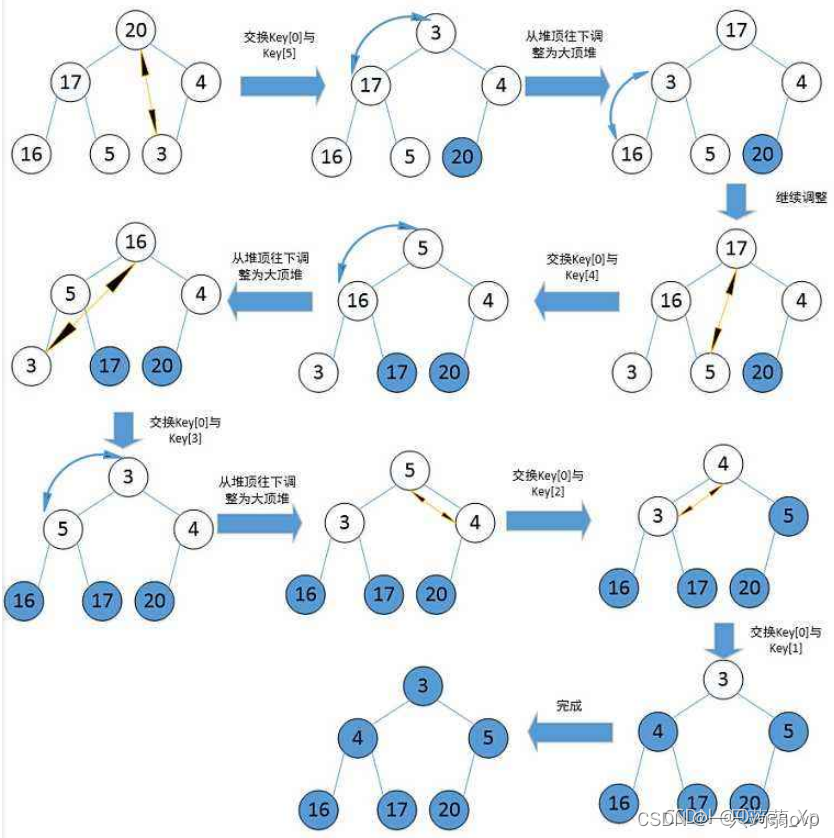
1.堆排序
排序分为升序(从小到大)和降序(从大到小),分别运用大根堆和小根堆。
这里以升序,运用大根堆为例。
主要思想:由于每个大根堆的根节点值最大,则将其删除后(a[1]与a[n]交换),再一次从根节点向下调整为一个新的堆时,新根节点(次大值)为新大根堆的最大值,再次进行删除根节点操作(a[1]与a[n-1]交换),共进行(n-1)次重复操作时,此时的堆即为升序排列。
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
for(int i=n/2;i>=1;i--) heapdown(i); // 构建大根堆
int n1=n;
for(int i=1;i<n1;i++) // 进行 (n-1)次重复操作
{
int t=a[n]; a[n]=a[1];a[1]=t; n--;
heapdown(1); // 从根节点向下调整
}
for(int i=1;i<=n1;i++) printf("%d ",a[i]);2. top-k问题
要从N个数字中取得最小的K个数字,则需要创建元素大小为K的大堆来获取。
要从N个数字中取得最大的K个数字,则需要创建元素大小为K的小堆来获取。
以取N个数字中取得最小的K个数字,创建大根堆为例
主要思想:
① 先将数组中n个元素放入堆中,保持大根堆的性质。
②将新的元素插入堆中,通过向上调整保持大根堆的性质。
③将根节点删除(根节点最大),保持大根堆里面的前K个元素是当前最小的K个元素。
④重复操作②和③,直至无新元素插入堆中。
学习文章:














 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









