







 本文深入探讨Python中的各种数据结构,如数组、栈、队列、集合、字典和namedtuple,以及排序和查找算法,包括二分查找、冒泡、选择、插入、归并和快速排序。同时,提供了丰富的示例代码和实践应用,帮助读者理解和掌握Python编程的核心概念。
本文深入探讨Python中的各种数据结构,如数组、栈、队列、集合、字典和namedtuple,以及排序和查找算法,包括二分查找、冒泡、选择、插入、归并和快速排序。同时,提供了丰富的示例代码和实践应用,帮助读者理解和掌握Python编程的核心概念。
一些知识点总结和几个例题
一:二分查找法,冒泡、选择、插入、归并、快速排序算法
我把这几个例题中的查找算法和排序算法,把自己对它们的理解总结了一下:
Python 关于下标的运用技巧(二分查找法,冒泡、选择、插入、归并、快速排序算法)
二:数组
import array
array.array(typecode [, initializer])
- typecode:array对象中数据元素的类型
创建array对象时必须指定其元素类型typecode,且其元素只能为该类型,否则将导致TypeError - initializer:为初始化数据序列或可迭代对象
例11.15
>>> import array
>>> a = array.array('b', (1, 2, 3, 4, 5))
>>> a[1] = 66
>>> a[1:]
array('b', [66, 3, 4, 5])
>>> a[0] = 'zgh'
Traceback (most recent call last):
File "<pyshell#29>", line 1, in <module>
a[0] = 'zgh'
TypeError: an integer is required (got type str)
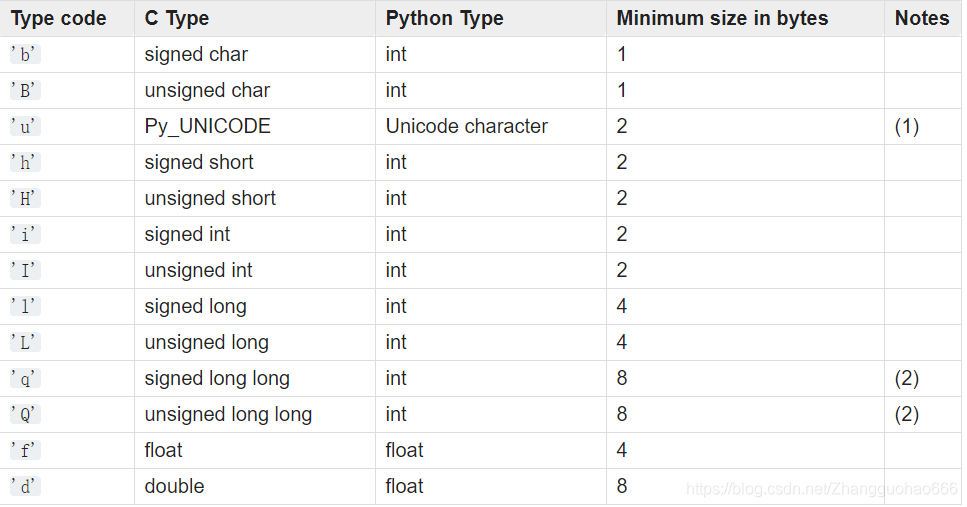
下表来自https://docs.python.org/3.5/library/array.html#module-array
三:栈和队列(collections.deque)
- collections模块中的deque对象:双端队列
支持从任意一端增加和删除元素。 - deque是线程安全的,内存高效的队列,它被设计为从两端追加和弹出都非常快
import collections
collections.deque([iterable [, maxlen]])
- iterable:初始元素
- maxlen:指定队列长度(默认无限制)
| deque对象dq支持的方法: | |
|---|---|
dq.append(x) | 在右端添加元素x |
dq.appendleft(x) | 在左端添加元素x |
dq.pop() | 从右端弹出元素。若队列中无元素,则导致IndexError |
dq.popleft() | 从左端弹出元素。若队列中无元素,则导致IndexError |
dq.extend(iterable) | 在右端添加序列iterable中的元素 |
dq.extendleft(iterable) | 在左端添加序列iterable中的元素 |
dq.remove(value) | 移除第一个找到的x。若未找到,则导致IndexError |
dq.count(x) | 返回元素x在队列中出现的个数 |
dq.clear() | 清空队列,删除所有元素 |
dq.reverse() | 反转 |
dq.rotate(n) | 如果n>0,则所有元素向右移动n个位置(循环),否则向左 |
例11.17(读取文件,返回文件最后的n行内容)
import collections
def tail(filename, n = 10):
'Return the last n lines of a file'
with open(filename) as f:
return collections.deque(f, n)
if __name__ == '__main__':
path = r'test.py'
dq = tail(path, n = 2)
print(dq.popleft())
print(dq.popleft())
输出:
print(dq.popleft())
print(dq.popleft())
若将代码中的这一句改为dq = tail(path, n = 5)
再看输出:
if __name__ == '__main__':
path = r'test.py'
例11.18(deque作为栈)
- 入栈:deque的append()方法
- 出栈:deque的pop()方法
>>> from collections import deque
>>> dq = deque()
>>> dq.append(1)
>>> dq.append(2)
>>> dq.append(3)
>>> dq.pop()
3
>>> dq.pop()
2
>>> dq.pop()
1
例11.16(用列表list实现栈)
list.append()入栈list.pop()出栈
class Stack:
def __init__(self, size = 16):
self.stack = []
def push(self, obj):
self.stack.append(obj)
def pop(self):
try:
return self.stack.pop()
except IndexError as e:
print("stack is empty")
def __str__(self):
return str(self.stack)
def main():
stack = Stack()
#1,2先后入栈
stack.push(1)
stack.push(2)
print(stack)
#出栈
stack.pop()
print(stack)
stack.pop()
print(stack)
stack.pop()
print(stack)
if __name__ == '__main__':main()
输出:
[1, 2]
[1]
[]
stack is empty
[]
例11.19(deque作为队列)
- 进队:deque的append()方法
- 出队:deque的popleft()方法
>>> from collections import deque
>>> dq = deque()
>>> dq.append(1)
>>> dq.append(2)
>>> dq.append(3)
>>> dq.popleft()
1
>>> dq.popleft()
2
>>> dq.popleft()
3
四:集合
- 可变集合对象 set
set()
set(iterable) - 不可变集合对象 frozenset
frozenset()
frozenset(iterable)
- 集合中的元素不可重复,且无序,其存储依据对象的hash码
hash码是依据对象的值计算出来的一个唯一的值
一个对象的hash值可以使用内置函数hash()获得- 所有的内置不可变对象,都是可hash对象
可hash对象,即实现了__hash__()的对象
bool、int、float、complex、str、tuple、frozenset- 所有内置可变对象,都是非hash对象
list、dict、set
因为可变对象的值可以变化,故无法计算唯一的hash值
在集合中可以包含内置不可变对象,不能包含内置可变对象
例11.20(创建集合对象示例)
集合:无序、不可重复
>>> {1, 2, 1}
{1, 2}
在集合中,重复元素,保留前面的
>>> {'a', 1, True, False, 0}
{False, 1, 'a'}
在集合中可以包含内置不可变对象,不能包含内置可变对象(list、dict、set)
>>> {'zgh', [6,6,6]}
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
{'zgh', [6,6,6]}
TypeError: unhashable type: 'list'
>>> {'zgh', {6, 6, 6}}
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
{'zgh', {6, 6, 6}}
TypeError: unhashable type: 'set'
>>> {'zgh', {'sex':'male'}}
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
{'zgh', {'sex':'male'}}
TypeError: unhashable type: 'dict'
例11.21(集合解析表达式)
>>> {i for i in range(5)}
{0, 1, 2, 3, 4}
>>> {2**i for i in range(5)}
{1, 2, 4, 8, 16}
>>> {x**2 for x in [1, 1, 2]}
{1, 4}
- 判断元素x是否在集合s是否存在:
x in s如果为True,则表示存在x not in s如果为True,则表示不存在
- 集合的运算:并集、交集、差集、对称差集
| 运算符 | 说明 |
|---|---|
s1 | s2 | ... | 返回 s1、s2…的并集 |
s1 & s2 | ... | 返回 s1、s2…的交集 |
s1 - s2 - ... | 返回 s1、s2…的差集 |
s1 ^ s2 | 返回 s1、s2 的对称差集 |
- 集合的对象方法:
| 方法 | 说明 |
|---|---|
s1.union(s2, ...) | 返回集合s1、s2…的并集 |
s1.update(s2, ...) | 返回集合s1、s2…的并集,s1 |= (s2 | ...) (可变集合的方法) |
s1.intersection(s2, ...) | 返回集合s1、s2…的交集 |
s1.intersection_update(s2, ...) | 返回集合s1、s2…的交集,s1 &= (s2 & ...) (可变集合的方法) |
s1.difference(s2, ...) | 返回集合s1、s2…的差集 |
s1.difference_update(s2, ...) | 返回集合s1、s2…的差集,s1 -= (s2 - ...) (可变集合的方法) |
s1.symmetric_difference(s2) | 返回集合s1、s2的对称差集 |
s1.symmetric_difference_update(s2) | 返回集合s1、s2的对称差集,s1 ^= (s2) (可变集合的方法) |
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> '''并集'''
>>> s1 | s2
{1, 2, 3, 4}
>>> s1.union(s2)
{1, 2, 3, 4}
>>> '''交集'''
>>> s1 & s2
{2, 3}
>>> s1.intersection(s2)
{2, 3}
>>> '''差集'''
>>> s1 - s2
{1}
>>> s2 - s1
{4}
>>> s1.difference(s2)
{1}
>>> '''对称差集'''
>>> s1 ^ s2
{1, 4}
>>> s1.symmetric_difference(s2)
{1, 4}
- 集合的比较运算:相等、子集、超集
| 运算符 | 说明 |
|---|---|
s1 == s2 | s1和s2的元素相同 |
s1 != s2 | s1和s2的元素不完全相同 |
s1 < s2 | s1是s2的纯子集 |
s1 <= s2 | s1是s2的子集 |
s1 >= s2 | s1是s2的超集 |
s1 > s2 | s1是s2的纯超集 |
| 方法 | 说明 |
|---|---|
s1.isdisjoint(s2) | 如果集合s1和s2没有共同元素,返回True |
s1.issubset(s2) | 如果集合s1是s2的子集,返回True |
s1.issuperset(s2) | 如果集合s1是s2的超集,返回True |
-
集合的长度、最大值、最小值、元素和
len()
max()
min()
sum()如果元素有非数值类型(数值类型:int、float、bool、complex),则求和将导致TypeError -
可变集合 set 的常用方法:
| set的方法 | 说明 |
|---|---|
s.add(x) | 把对象x添加到集合s |
s.remove(x) | 从集合s中移除对象x,若不存在,则导致KeyError |
s.discard(x) | 从集合s中移除对象x(如果存在) |
s.pop() | 从集合s中随机弹出一个元素,如果s为空,则导致KeyError |
s.clear() | 清空集合s |
五:字典
- 字典(dict)是一组键/值对的数据类型
字典的键必须是可hash对象 - 每个键对应于一个值
- 在字典中,键不能重复,根据键可以查询到值
字典的定义:
dict()
创建一个空字典
>>> {}
{}
>>> dict()
{}
dict(**kwargs)
使用关键字参数创建一个新的字典,此方法最紧凑
>>> dict(baidu = 'baidu.com', google = 'google.com')
{'baidu': 'baidu.com', 'google': 'google.com'}
dict(mapping)
从一个字典对象创建一个新的字典
>>> {'a':'apple', 'b':'boy'}
{'a': 'apple', 'b': 'boy'}
>>> dict({'a':'apple', 'b':'boy'})
{'a': 'apple', 'b': 'boy'}
dict(iterable)
使用序列创建一个新的字典
>>> dict([('id','666'),('name','zgh')])
{'id': '666', 'name': 'zgh'}
>>> dict((('id','666'),('name','zgh')))
{'id': '666', 'name': 'zgh'}
字典的访问操作:
d[key]
返回键为key的value,如果key不存在,则导致KeyError
>>> d = {1:'zgh', 2:'666'}
>>> d
{1: 'zgh', 2: '666'}
>>> d[1]
'zgh'
>>> d[2]
'666'
>>> d[3]
Traceback (most recent call last):
File "<pyshell#43>", line 1, in <module>
d[3]
KeyError: 3
d[key] = value
设置d[key]的值为value,如果key不存在,则添加键/值对
>>> d[3] = 'yes'
>>> d
{1: 'zgh', 2: '666', 3: 'yes'}
del d[key]
删除字典元素,如果key不存在,则导致KeyError
>>> del d[2]
>>> d
{1: 'zgh', 3: 'yes'}
字典的视图对象:
d.keys()
返回字典d的键key的列表
>>> d = dict(name = 'zgh', sex = 'male', age = '18')
>>> d
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> d.keys()
dict_keys(['name', 'sex', 'age'])
d.values()
返回字典d的值value的列表
>>> d.values()
dict_values(['zgh', 'male', '18'])
d.items()
返回字典d的(key, value)对的列表
>>> d.items()
dict_items([('name', 'zgh'), ('sex', 'male'), ('age', '18')])
字典解析表达式:
>>> {key:value for key in "ABC" for value in range(3)}
{'A': 2, 'B': 2, 'C': 2}
>>> d = {'name':'zgh', 'sex':'male', 'age':'18'}
>>> {key:value for key,value in d.items()}
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> {x:x*x for x in range(10) if x%2 == 0}
{0: 0, 2: 4, 4: 16, 6: 36, 8: 64}
判断字典键是否存在:
key in d
如果为True,表示存在
>>> d = dict([('name', 'zgh'), ('sex', 'male'), ('age', '18')])
>>> d
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> 'name' in d
True
key not in d
如果为True,表示不存在
>>> 'names' in d
False
字典对象的长度和比较:
len()
获取字典的长度
虽然,字典对象也支持内置函数max()、min()、sum(),但是它们计算的是字典key,没有意义
>>> d1 = {1:'food'}
>>> d2 = {1:'food', 2:'drink'}
>>> len(d1)
1
>>> len(d2)
2
==,!=
字典支持的比较运算中,只有==,!=有意义
>>> d1 == d2
False
>>> d1 != d2
True
字典对象的方法:
| 字典对象的方法 | 说明 |
|---|---|
d.clear() | 删除所有元素 |
d.copy() | 浅复制字典 |
d.get(k) | 返回键k对应的值,如果key不存在,返回None |
d.get(k,v) | 返回键k对应的值,如果key不存在,返回v |
d.pop(k) | 如果键k存在,返回其值,并删除该项目;否则将导致KeyError |
d.pop(k,v) | 如果键k存在,返回其值,并删除该项目;否则返回v |
d.setdefault(k,v) | 如果键k存在,返回其值;否则添加项目k=v,v默认为None |
d.update([other]) | 使用字典或键值对,更新或添加项目到字典d |
六:collections模块的数据结构
与字典相关
collections.defaultdict(function_factory)
用于构建类似dict的对象defaultdict
与dict的区别是,在创建defaultdict对象时可以使用构造函数参数function_factory指定其键值对中值的类型
import collections
collections.defaultdict([function_factory[, ...]])
- 其中,可选参数
function_factory为字典键值对中值的类型;其他可选参数同dict构造函数 defaultdict实现了__missing__(key),即键不存在时返回值的类型(function_factory)对应的默认值,例如数值为0、字符串为'',list为[]
键不存在时返回:值的类型(function_factory)对应的默认值,例如数值为0
>>> import collections
>>> s = [('r', 1), ('g', 2), ('b', 3)]
>>>> dd = collections.defaultdict(int, s)
>>> dd['r']
1
>>> dd['g']
2
>>> dd['b']
3
>>> dd['z']
0
我们知道,在字典中键是不能重复的,而且键对应一个值
当键有重复的时候,后面的覆盖前面的
>>> s1 = [('r', 1), ('g', 2), ('b', 3), ('r', 4), ('b', 5)]
>>> dict(s1)
{'r': 4, 'g': 2, 'b': 5}
那么,
怎么使字典中的键对应多个值呢?
>>> import collections
>>> s1 = [('r', 1), ('g', 2), ('b', 3), ('r', 4), ('b', 5)]
>>> dd1 = collections.defaultdict(list)
>>> for k,v in s1:
dd1[k].append(v)
>>> list(dd1.items())
[('r', [1, 4]), ('g', [2]), ('b', [3, 5])]
>>> dd1.items()
dict_items([('r', [1, 4]), ('g', [2]), ('b', [3, 5])])
collections.OrderedDict([items])
是dict的子类,能够记录字典元素插入的顺序
OrderedDict对象的元素保持插入的顺序,在更新键的值时不改变顺序;
若删除项,然后插入与删除项相同的键值对,则置于末尾
除了继承dict的方法外,OrderedDict对象包括以下两个方法:
| OrderedDict对象的方法 | 说明 |
|---|---|
popitem(last=True) | 弹出最后一个元素;如果last=False,则弹出第一个元素 |
move_to_end(key, last=True) | 移动键key到最后;如果last=False,则移动到最前面 |
>>> import collections
>>> od = collections.OrderedDict(sorted(d.items()))
>>> od
OrderedDict([('age', '18'), ('name', 'guohao'), ('sex', 'female')])
>>> od.popitem()
('sex', 'female')
>>> od
OrderedDict([('age', '18'), ('name', 'guohao')])
>>> od['sex'] = 'male'
>>> od
OrderedDict([('age', '18'), ('name', 'guohao'), ('sex', 'male')])
>>> od.move_to_end('name')
>>> od
OrderedDict([('age', '18'), ('sex', 'male'), ('name', 'guohao')])
>>> od.move_to_end('name', False)
>>> od
OrderedDict([('name', 'guohao'), ('age', '18'), ('sex', 'male')])
与map相关
collections.ChainMap( * maps)
用于连接多个map
ChainMap对象内部包含多个map的列表(第一个map为子map,其余map为父map),maps属性返回这个列表。
>>> import collections
>>> m1 = {'a':1, 'b':2}
>>> m2 = {'a':2, 'x':3, 'y':4}
>>> m = collections.ChainMap(m1, m2)
ChainMap对象m除了支持字典映射的属性和方法以外,还包含下列属性和方法:
m.maps
属性,返回m对象内部包含的map的列表
>>> m.maps
[{'a': 1, 'b': 2}, {'a': 2, 'x': 3, 'y': 4}]
m.parents
属性,返回包含其父map的新的ChainMap对象,即ChainMap( * d.maps[1:])
>>> m.parents
ChainMap({'a': 2, 'x': 3, 'y': 4})
m.new_child()
方法,返回新的ChainMap对象,即ChainMap({}, * d.maps)
>>> m.new_child()
ChainMap({}, {'a': 1, 'b': 2}, {'a': 2, 'x': 3, 'y': 4})
- 在查询时,首先查询第一个map,如果没有查到,则依次查询其他map
>>> m['a']
1
>>> m['x']
3
- ChainMap只允许更新第一个map
>>> m['a'] = 99
>>> m['x'] = 10
>>> m
ChainMap({'a': 99, 'b': 2, 'x': 10}, {'a': 2, 'x': 3, 'y': 4})
更新键'x'的值,因为夫map不能更新,故实际上是在子map中插入键值对
collections.Counter([iterable - or - mapping])
可选参数为序列或字典map
创建Counter对象:
c = Counter()
创建空的Counter对象c = Counter('banana')
基于序列创建Counter对象c = Counter({'red':4, 'blue':2})
基于字典映射c = Counter(cats = 4, dogs = 8)
基于命名参数
- Counter对象支持字典映射的属性和方法,但查询时如果键不存在将不会报错,而是返回值0
>>> import collections
>>> c = collections.Counter({'r':3, 'g':2, 'b':1, 'y':4, 'w':3})
>>> c['green']
0
c.elements()
返回元素列表,各元素重复的次数为其计数
>>> c.elements()
<itertools.chain object at 0x000001F92336F8C8>
>>> list(c.elements())
['r', 'r', 'r', 'g', 'g', 'b', 'y', 'y', 'y', 'y', 'w', 'w', 'w']
c.most_common([n])
返回计数值最大的n个元素的元组(元素,计数)列表
>>> c.most_common(2)
[('y', 4), ('r', 3)]
c.subtract([iterable-or-mapping])
元素的计数值减去序列或字典中对应元素的计数
>>> c.subtract('red')
>>> c
Counter({'y': 4, 'w': 3, 'r': 2, 'g': 2, 'b': 1, 'e': -1, 'd': -1})
与元组相关
namedtuple(typename, field_names, verbose = False, rename = False)
typename
返回tuple的子类的类名field_names
是命名元组元素的名称,必须为合法的标识符verbose
当verbose为True时,在创建命名元组后会打印类定义信息rename
当rename为True时,如果field_names包含保留关键字,则自动命名为_1、_2等
tuple是常用的数据类型,但只能通过索引访问其元素
使用namedtuple的构造函数可以定义一个tuple的子类命名元组,namedtuple对象既可以使用元素名称访问其元素,也可以使用索引访问
- 创建的命名元组的类可以通过
_fields返回其字段属性
>>> from collections import namedtuple
>>> p = namedtuple('Point', ['x', 'y'])
>>> print(p._fields)
('x', 'y')
>>> p.x = 11
>>> p.y = 22
>>> p.x + p.y
33
- namedtuple创建的类继承自tuple,包含额外的三个方法:
_make(iterable),从指定序列iterable构建命名元组对象
>>> t = [3, 4]
>>> p1 = p._make(t)
>>> p1
Point(x=3, y=4)
_asdict()
把命名元组对象转换为OrderDict对象
>>> p1._asdict()
OrderedDict([('x', 3), ('y', 4)])
_replace(kwargs())
创建新的命名元组对象,替换指定字段
>>> p1._replace(x=30)
Point(x=30, y=4)
>>> p1
Point(x=3, y=4)
UserDict、UserList和UserString对象
UserDict、UserList和UserString分别是dict、list、str的子类,一般用于创建其派生类
collections.UserDict([initialdata])collections.UserList([list])collections.UserString([sequence])
虽然可以直接基于dict、list、str创建派生类,但UserDict、UserList和UserString包括一个属性成员—data,用于存放内容,因此可以更方便实现
以UserString为例:
>>> from collections import *
>>> us = UserString('zgh')
>>> us.data
'zgh'
以UserList为例:
>>> ul = UserList([1,1,3])
>>> ul.data
[1, 1, 3]
>>> ul.data[0]
1
以UserDict为例:
>>> ud = UserDict({'name':'zgh', 'sex':'male', 'age':'18'})
>>> ud.data
{'name': 'zgh', 'sex': 'male', 'age': '18'}
>>> ud.data['name']
'zgh'
七:基于字典的通讯录
实现一个简单的基于字典数据结构的通讯管理系统,该系统采用JSON文件来保存数据
通讯录设计为字典:{name : tel}
有五个功能:
- 显示通讯录清单
若通讯录中无任何用户信息,则提示:通讯录为空 - 查询联系人资料
若并不存在,则提示:是否新建联系人 - 插入新的联系人
若联系人已存在,则提示:是否进行修改 - 删除已有联系人
若不存在此联系人,则提示:联系人不存在 - 退出
保存通讯录字典到addressbook.json中,退出循环
Python代码:
"""简易通讯录程序"""
import os, json
address_book = {}
if os.path.exists("addressbook.json"):
with open(r'addressbook.json', 'r', encoding='utf-8') as f:
address_book = json.load(f)
while True:
print("| --- 欢迎使用通讯录程序 --- |")
print("| --- 1:显示通讯录清单--- |")
print("| --- 2:查询联系人资料 --- |")
print("| --- 3:插入新的联系人 -- |")
print("| --- 4:删除已有联系人 --- |")
print("| --- 0:退出 --- |")
choice = input('请选择功能菜单:')
if choice == '1':
if(len(address_book) == 0):
print("通讯录为空")
else:
for k,v in address_book.items():
print("姓名 = {},联系电话 = {}".format(k, v))
print()
elif choice == '2':
name = input("请输入联系人姓名:")
if (name not in address_book):
yn = input("联系人不存在,是否增加用户资料(Y/N):")
if yn in ['Y', 'y']:
tel = input("请输入联系人电话:")
address_book[name] = tel
else:
print("联系人信息:{} {}".format(name, address_book[name]))
print()
elif choice == '3':
name = input("请输入联系人姓名:")
if (name in address_book):
print("已存在联系人:{} {}".format(name, address_book[name]))
yn = input("是否修改用户资料(Y/N):")
if yn in ['Y', 'y']:
tel = input("请输入联系人电话:")
address_book[name] = tel
else:
tel = input("请输入联系人电话:")
address_book[name] = tel
print()
elif choice == '4':
name = input('请输入联系人姓名:')
if (name not in address_book):
print("联系人不存在:{}".format(name))
else:
tel = address_book.pop(name)
print("删除联系人:{} {}".format(name, tel))
print()
elif choice == '0':
with open(r'addressbook.json', 'w', encoding='utf-8') as f:
json.dump(address_book, f)
break
运行Python模块之前的json文件:
{"zgh": "15272502101", "xy": "110", "lcw": "888", "hq": "120"}
运行过程:
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:1
姓名 = zgh,联系电话 = 15272502101
姓名 = xy,联系电话 = 110
姓名 = lcw,联系电话 = 888
姓名 = hq,联系电话 = 120
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:2
请输入联系人姓名:zgh
联系人信息:zgh 15272502101
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:2
请输入联系人姓名:tf
联系人不存在,是否增加用户资料(Y/N):y
请输入联系人电话:000
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:2
请输入联系人姓名:zwl
联系人不存在,是否增加用户资料(Y/N):n
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:3
请输入联系人姓名:zgh
已存在联系人:zgh 15272502101
是否修改用户资料(Y/N):y
请输入联系人电话:155
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:3
请输入联系人姓名:zgh
已存在联系人:zgh 155
是否修改用户资料(Y/N):n
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:3
请输入联系人姓名:zwl
请输入联系人电话:555
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:4
请输入联系人姓名:zwl
删除联系人:zwl 555
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:1
姓名 = zgh,联系电话 = 155
姓名 = xy,联系电话 = 110
姓名 = lcw,联系电话 = 888
姓名 = hq,联系电话 = 120
姓名 = tf,联系电话 = 000
| --- 欢迎使用通讯录程序 --- |
| --- 1:显示通讯录清单--- |
| --- 2:查询联系人资料 --- |
| --- 3:插入新的联系人 -- |
| --- 4:删除已有联系人 --- |
| --- 0:退出 --- |
请选择功能菜单:0
运行之后的json文件:
{"zgh": "155", "xy": "110", "lcw": "888", "hq": "120", "tf": "000"}
选择题:1~5
1
>>> print(type({}))
<class 'dict'>
2
>>> print(type([]))
<class 'list'>
3
>>> print(type(()))
<class 'tuple'>
4
>>> dict1 = {}
>>>
>>> dict2 = {2:6}
>>>
>>> dict3 = {[1,2,3] : "user"}
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
dict3 = {[1,2,3] : "user"}
TypeError: unhashable type: 'list'
>>>
>>> dict4 = {(1,2,3) : "users"}
字典的键必须是可hash对象:bool、int、float、complex、str、tuple、frozenset
而 list、dict、set 是不可hash的
5
>>> dict1 = {}
>>>
>>> dict2 = {1:8}
>>>>
>>> dict3 = dict([2,4], [3,6])
Traceback (most recent call last):
File "<pyshell#20>", line 1, in <module>
dict3 = dict([2,4], [3,6])
TypeError: dict expected at most 1 arguments, got 2
>>>
>>> dict4 = dict(([2,4], [3,6]))
填空题:1~8
1
>>> print(len({}))
0
2
>>> d = {1:'x', 2:'y', 3:'z'}
>>> del d[1]
>>> del d[2]
>>> d[1] = 'A'
>>> print(len(d))
2
3
>>> print(set([1, 2, 1, 2, 3]))
{1, 2, 3}
4
>>> fruits = {'apple':3, 'banana':4, 'pear':5}
>>> fruits['banana'] = 7
>>> print(sum(fruits.values()))
15
d.values()
返回字典d的值value的列表
5
>>> d1 = {1:'food'}
>>> d2 = {1:'食品', 2:'饮料'}
>>> d1.update(d2)
>>> print(d1[1])
食品
d.update([other])
使用字典或键值对,更新或添加项目到字典d
6
>>> names = ['Amy', 'Bob', 'Charlie', 'Daling']
>>> print(names[-1][-1])
g
names[-1] = ‘Daling’
names[-1][-1] = ‘Daling’[-1] = ‘g’
7
>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>>
>>> s1.update(s2)
>>> s1
{1, 2, 3, 4, 5}
>>>
>>> s1.intersection_update(s2)
>>> s1
{3, 4, 5}
>>>
>>> s1.difference_update(s2)
>>> s1
set()
>>>
>>> s1.symmetric_difference_update(s2)
>>> s1
{3, 4, 5}
>>>
>>> s1.add('x')
>>> s1
{3, 4, 5, 'x'}
>>>
>>> s1.remove(1)
Traceback (most recent call last):
File "<pyshell#67>", line 1, in <module>
s1.remove(1)
KeyError: 1
>>>
>>> s1.discard(3)
>>> s1
{4, 5, 'x'}
>>>
>>> s1.clear()
>>> s1
set()
思考题:1~15
1
>>> list1 = {}
>>> list1[1] = 1
>>> list1['1'] = 3
>>> list1[1] += 2
>>> sum = 0
>>> for k in list1:
sum += list1[k]
>>> print(sum)
6
2
>>> d = {1 : 'a', 2 : 'b', 3 : 'c'}
>>> del d[1]
>>> d[1] = 'x'
>>> del d[2]
>>> print(d)
{3: 'c', 1: 'x'}
3
>>> item_counter = {}
>>> def addone(item):
if item in item_counter:
item_counter[item] += 1
else:
item_counter[item] = 1
>>> addone('Apple')
>>> addone('Pear')
>>> addone('apple')
>>> addone('Apple')
>>> addone('kiwi')
>>> addone('apple')
>>> print(item_counter)
{'Apple': 2, 'Pear': 1, 'apple': 2, 'kiwi': 1}
4
>>> numbers = {}
>>> numbers[(1,2,3)] = 1
>>> numbers
{(1, 2, 3): 1}
>>> numbers[(2,1)] = 2
>>> numbers
{(1, 2, 3): 1, (2, 1): 2}
>>> numbers[(1,2)] = 3
>>> numbers
{(1, 2, 3): 1, (2, 1): 2, (1, 2): 3}
>>> sum = 0
>>> for k in numbers:
sum += numbers[k]
>>> print(len(numbers),' ',sum,' ', numbers)
3 6 {(1, 2, 3): 1, (2, 1): 2, (1, 2): 3}
提示:
>>> (1,2) == (1,2)
True
>>> (1,2) == (2,1)
False
5
>>> d1 = {'a' : 1, 'b' : 2}
>>> d2 = d1
>>> d1['a'] = 6
>>> sum = d1['a'] + d2['a']
>>> print(sum)
12
d2 = d1
d1,d2指向同一个地址
6
>>> d1 = {'a' : 1, 'b' : 2}
>>> d2 = dict(d1)
>>> d1['a'] = 6
>>> sum = d1['a'] + d2['a']
>>> print(sum)
7
d2 = dict(d1)
d1,d2指向是不同的地址
7
>>> from collections import *
>>> m1 = {1 : 'a', 2 : 'b'}
>>> m2 = {2 : 'a', 3 : 'x', 4 : 'y'}
>>> m = ChainMap(m1, m2)
>>> print(m.maps, m.parents, m.new_child())
[{1: 'a', 2: 'b'}, {2: 'a', 3: 'x', 4: 'y'}] ChainMap({2: 'a', 3: 'x', 4: 'y'}) ChainMap({}, {1: 'a', 2: 'b'}, {2: 'a', 3: 'x', 4: 'y'})
>>> print(m[1], m[3])
a x
>>> m[1] = 'A'
>>> m[3] = 'X'
>>> print(m)
ChainMap({1: 'A', 2: 'b', 3: 'X'}, {2: 'a', 3: 'x', 4: 'y'})
m.maps
属性,返回m对象内部包含的map的列表m.parents
属性,返回包含其父map的新的ChainMap对象,即ChainMap( * d.maps[1:])m.new_child()
方法,返回新的ChainMap对象,即ChainMap({}, * d.maps)- 在查询时,首先查询第一个map,如果没有查到,则依次查询其他map
- ChainMap只允许更新第一个map
8
>>> from collections import *
>>> c1 = Counter()
>>> print(c1)
Counter()
>>>
>>> c2 = Counter('banana')
>>> print(c2)
Counter({'a': 3, 'n': 2, 'b': 1})
>>>
>>> c3 = Counter({'R':4, 'B':2})
>>> print(c3)
Counter({'R': 4, 'B': 2})
>>>
>>> c4 = Counter(birds = 2, cats = 4, dog = 8)
>>> print(c4)
Counter({'dog': 8, 'cats': 4, 'birds': 2})
>>>
>>> print(c4['flowers'], c4['cats'])
0 4
>>>
>>> print(list(c3.elements()))
['R', 'R', 'R', 'R', 'B', 'B']
>>>
>>> print(c4.most_common(2))
[('dog', 8), ('cats', 4)]
>>>
>>>> c3.subtract('RGB')
>>> print(c3)
Counter({'R': 3, 'B': 1, 'G': -1})
创建Counter对象:
c = Counter()
创建空的Counter对象c = Counter('banana')
基于序列创建Counter对象c = Counter({'red':4, 'blue':2})
基于字典映射c = Counter(cats = 4, dogs = 8)
基于命名参数
- Counter对象支持字典映射的属性和方法,但查询时如果键不存在将不会报错,而是返回值0
c.elements()
返回元素列表,各元素重复的次数为其计数c.most_common([n])
返回计数值最大的n个元素的元组(元素,计数)列表c.subtract([iterable-or-mapping])
元素的计数值减去序列或字典中对应元素的计数
9
>>> from collections import *
>>> dq = deque()
>>> dq.append('a')
>>> dq.append(2)
>>> dq.append('c')
>>> data = iter(dq)
>>> while True:
try: i = next(data)
except StopIteration: break
print(i, end=' ')
a 2 c
>>> print(dq.pop(), dq.pop(), dq.pop())
c 2 a
dq.append(x)
在右端添加元素xdq.pop()从右端弹出元素。
若队列中无元素,则导致IndexErrordq.popleft()
从左端弹出元素。若队列中无元素,则导致IndexError- 使用内置函数
iter(obj)可以返回一个迭代器 - 使用内置函数
next()可以依次返回迭代器对象的下一个项目值
10
>>> from collections import *
>>> dq = deque()
>>> dq.append('a')
>>> dq.append(2)
>>> dq.append('c')
>>> print(dq.popleft(), dq.popleft(), dq.popleft())
a 2 c
11
>>> from collections import defaultdict
>>> s = [('r', 3), ('g', 2), ('b', 1)]
>>> dd = defaultdict(int, s)
>>> print(dd['b'], dd['w'])
1 0
>>>
>>> s1 = [('r', 3), ('g', 2), ('b', 1), ('r', 5), ('b', 4)]
>>> dd1 = defaultdict(list)
>>> for k,v in s1:
dd1[k].append(v)
>>> print(list(dd1.items()))
[((1, 2), []), ('r', [3, 5]), ('g', [2]), ('b', [1, 4])]
- 与dict的区别是,在创建
defaultdict对象时可以使用构造函数参数function_factory指定其键值对中值的类型 defaultdict实现了__missing__(key),即键不存在时返回值的类型(function_factory)对应的默认值,例如数值为0、字符串为'',list为[]
此处,保有疑问,个人觉的print(list(dd1.items()))的运行结果应该是[ ('r', [3, 5]), ('g', [2]), ('b', [1, 4])],没有弄懂((1, 2), [])从何处来?
12
>>> from collections import *
>>> d = {'red' : 3, 'green' : 4, 'blue' : 1}
>>> print(d.items(), sorted(d.items()))
dict_items([('red', 3), ('green', 4), ('blue', 1)]) [('blue', 1), ('green', 4), ('red', 3)]
>>>
>>> od = OrderedDict(sorted(d.items()))
>>> print(od.popitem(), od.popitem(False))
('red', 3) ('blue', 1)
- 除了继承dict的方法外,OrderedDict对象有一个方法:
popitem(last=True)
弹出最后一个元素;如果last=False,则弹出第一个元素 |
13
>>> from collections import *
>>> p = namedtuple('Point', ['x', 'y'])
>>> p.x = 1
>>> p.y = 2
>>> print(p._fields, p.x, p.y)
('x', 'y') 1 2
>>>
>>> t = [10, 20]
>>> p1 = p._make(t)
>>> print(p1._asdict())
OrderedDict([('x', 10), ('y', 20)])
>>>
>>> print(p1._replace(x=100), p1.x, p1.y)
Point(x=100, y=20) 1 2
- 创建的命名元组的类可以通过
_fields返回其字段属性 - namedtuple创建的类继承自tuple,包含额外的三个方法:
_make(iterable),从指定序列iterable构建命名元组对象 _asdict()
把命名元组对象转换为OrderDict对象_replace(kwargs())
创建新的命名元组对象,替换指定字段
14
>>> import array
>>> arr1 = array.array('i', (1, 2, 3, 4, 5))
>>> arr1[1] = 22
>>> print(arr1, arr1[2:], type(arr1[1]))
array('i', [1, 22, 3, 4, 5]) array('i', [3, 4, 5]) <class 'int'>
>>> del arr1[2:]
>>> print(arr1, arr1.typecode, arr1.itemsize)
array('i', [1, 22]) i 4
15
>>> import array
>>> a = array.array('b', (3, 2))
>>> a.append(3)
>>> a.extend((3, 5))
>>> print(a, a.count(3))
array('b', [3, 2, 3, 3, 5]) 3
>>> a.frombytes(b'A1')
>>> a.fromlist([8, 9])
>>> print(a, a.index(3))
array('b', [3, 2, 3, 3, 5, 65, 49, 8, 9]) 0
>>> a.insert(0, 1)
>>> a.pop()
9
>>> a.remove(2)
>>> a.reverse()
>>> print(a.tolist())
[8, 49, 65, 5, 3, 3, 3, 1]
上机实践:2~13
对于书中给的查找算法和排序算法
- 查找算法:二分排序法
- 排序算法:冒泡,选择,插入,归并,快排
我突发奇想,写了以上算法中是如何玩转下标的
Python 关于下标的运用技巧(二分查找法,冒泡、选择、插入、归并、快速排序算法)
2. 修改例11.3,在列表中顺序查找特定数值的程序,设法从命令行参数中获取要查询的数据
import sys
def sequentialSearch(alist, item):
pos = 0
found = False
while pos < len(alist) and not found:
if alist[pos] == item:
found = True
else:
pos += 1
return found
if __name__ == '__main__':
testlist = [1, 3, 33, 8, 37, 29, 32, 15, 5]
item = float(sys.argv[1])
print(sequentialSearch(testlist, item))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
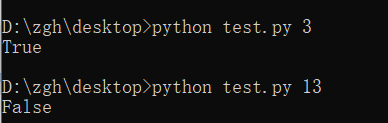
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
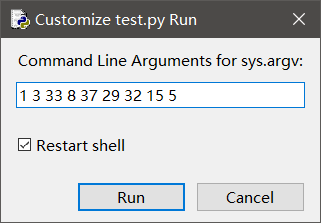
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:

点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
3. 修改例11.4,在列表中顺序查找最大值和最小值的示例程序,设法从命令行参数中获取测试列表的各元素
import sys
def max1(alist):
pos = 0
iMax = alist[0]
while pos < len(alist):
if alist[pos] > iMax:
iMax = alist[pos]
pos += 1
return iMax
def min1(alist):
pos = 0
iMin = alist[0]
while pos < len(alist):
if alist[pos] < iMin:
iMin = alist[pos]
pos += 1
return iMin
if __name__ == '__main__':
alist = []
for i in range(1, len(sys.argv)):
alist.append(float(sys.argv[i]))
print("最大值 = ", max1(alist))
print("最小值 = ", min1(alist))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)

- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
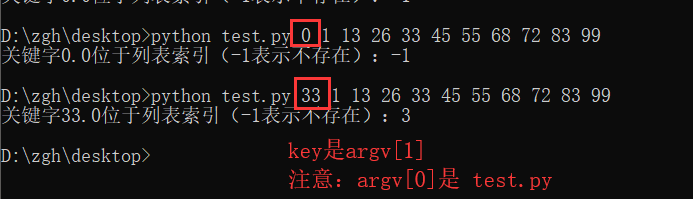
4. 修改例11.5,二分查找法的递归程序,设法从命令行参数中获取测试列表的各元素以及所要查找的关键字
怎么理解二分查找法的递归实现和非递归实现等算法,可以看一我的这篇文章
Python 关于下标的运用技巧(二分查找法,冒泡、选择、插入、归并、快速排序算法)
import sys
def _binarySearch(key, a, lo, hi):
if lo >= hi:
return -1
mid = (lo + hi) // 2
if(key < a[mid]):
return _binarySearch(key, a, lo, mid)
elif(key > a[mid]):
return _binarySearch(key, a, mid+1, hi)
else:
return mid
def binarySearch(key, a):
return _binarySearch(key, a, 0, len(a))
if __name__ == '__main__':
a = []
key = float(sys.argv[1])
for i in range(2, len(sys.argv)):
a.append(float(sys.argv[i]))
print("关键字{0}位于列表索引(-1表示不存在):{1}".format(key, binarySearch(key, a)))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可

5. 修改例11.6,二分查找法的非递归程序,设法从命令行参数中获取测试列表的各元素以及所要查找的关键字
import sys
def binarySearch(key, a):
low = 0
high = len(a) -1
while low <= high:
mid = (low + high)//2
if(key > a[mid]):
low = mid +1
elif(key < a[mid]):
high = mid -1
else:
return mid
return -1
if __name__ == '__main__':
a = []
key = float(sys.argv[1])
for i in range(2, len(sys.argv)):
a.append(float(sys.argv[i]))
print("关键字{0}位于列表索引(-1表示不存在):{1}".format(key, binarySearch(key, a)))
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)

- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
6. 修改例11.8,冒泡排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def bubbleSort(a):
for i in range(len(a)-1, -1, -1):
for j in range(i):
if a[j] > a[j+1]:
a[j],a[j+1] = a[j+1],a[j]
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
bubbleSort(a)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)

- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
7. 修改例11.9,选择排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def selectionSort(a):
for i in range(0, len(a)-1):
for j in range(i+1, len(a)):
if(a[j] < a[i]):
a[i],a[j] = a[j],a[i]
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
selectionSort(a)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
8. 修改例11.10,插入排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def insertSort(a):
for i in range(1, len(a)):
for j in range(i, 0, -1):
if(a[j-1] > a[j]):
a[j-1],a[j] = a[j],a[j-1]
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
insertSort(a)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
9. 修改例11.11,归并排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def merge(left, right):
merged = []
i, j = 0, 0
left_len, right_len = len(left), len(right)
while i < left_len and j < right_len:
if left[i] <= right[j]:
merged.append(left[i])
i += 1
else:
merged.append(right[j])
j += 1
merged.extend(left[i:])
merged.extend(right[j:])
return merged
def mergeSort(a):
if len(a) <= 1:
return a
mid = len(a) // 2
left = mergeSort(a[:mid])
right = mergeSort(a[mid:])
return merge(left, right)
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
print(mergeSort(a))
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
10. 修改例11.12,快速排序算法程序,设法从命令行参数中获取测试列表的各元素
import sys
def quickSort(a, low , high):
i = low
j = high
if i >= j:
return a
key = a[i]
while i < j:
while i < j and a[j] >= key:
j -= 1
a[i] = a[j]
while i < j and a[i] <= key:
i += 1
a[j] = a[i]
a[i] = key
quickSort(a, low, i-1)
quickSort(a, j+1, high)
def main():
a = []
for i in range(1, len(sys.argv)):
a.append(float(sys.argv[i]))
quickSort(a, 0, len(a)-1)
print(a)
if __name__ == '__main__':main()
涉及到命令行参数,一般有两种执行方式
- 通过控制台(cmd)
- 通过编辑器(就是你写python代码的工具)
我写这些小玩意,使用的是python自带的IDLE,
以IDLE(使用其他编辑器的,自己百度一下怎么执行时输入命令行参数)为例:
点击Run,然后Run…Customized(有快捷键:shift+F5)
输入命令行参数即可
输出:
[1.0, 3.0, 13.0, 26.0, 33.0, 45.0, 55.0, 68.0, 72.0, 83.0, 99.0]
11. 参考例11.42,实现namedtuple对象应用程序,读取成绩文件scores.csv的内容(学员、ID、语文、数学、外语和信息),显示学员ID和平均成绩
自己写一个scores.csv文件:
csv文件:推荐以逗号分隔
zgh, 1, 100, 100, 100, 100
xy, 2, 99, 98, 90, 85
hq, 3, 90, 98, 80, 96
lcw, 4, 85, 88, 65, 90
python代码:
from collections import *
import csv
Score = namedtuple('Score', 'name, id, chinese, math, english, computer')
for stu in map(Score._make, csv.reader(open("scores.csv", encoding = 'utf-8'))):
score_average = (float(stu.chinese) + float(stu.math) + float(stu.math) + float(stu.computer)) / 4
print(stu.id, score_average)
运行结果:
1 100.0
2 95.0
3 95.5
4 87.75
12. 创建由‘Monday’~‘Sunday’7个值组成的字典,输出键列表、值列表以及键值列表
d = {1:'Monday', 2:'Tuesday', 3:'Wednesday', 4:'Thursday', 5:'Friday', 6:'Saturday', 7:'Sunday'}
#print(d.keys())
for k in d.keys():
print(k, end=' ')
print()
#print(d.values())
for v in d.keys():
print(v, end=' ')
print()
#print(d.items())
for i in d.items():
print(i, end=' ')
运行结果:
1 2 3 4 5 6 7
1 2 3 4 5 6 7
(1, 'Monday') (2, 'Tuesday') (3, 'Wednesday') (4, 'Thursday') (5, 'Friday') (6, 'Saturday') (7, 'Sunday')
13. 随机生成10个0(包含)~10(包含)的整数,分别组成集合A和集合B,输出A和B的内容、长度、最大值、最小值以及它们的并集、交集和差集
import random
def func():
l = []
for j in range(5):
x = random.randint(1,10)
l.append(x)
return set(l)
A = func()
B = func()
print("集合的内容、长度、最大值、最小值分别为:")
print(A, len(A), max(A), min(A))
print(B, len(B), max(B), min(B))
print("A和B的并集、交集和差集分别为:")
print(A|B, A&B, A-B)
某次运行效果:
集合的内容、长度、最大值、最小值分别为:
{2, 4, 5, 7, 9} 5 9 2
{2, 4, 5, 8, 10} 5 10 2
A和B的并集、交集和差集分别为:
{2, 4, 5, 7, 8, 9, 10} {2, 4, 5} {9, 7}

















 3522
3522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









