







文章目录
前言
本文要求阅读者拥有一定的Python编程基础,基于Numpy的ndarray数组配合Matplotlib这个Python可视化软件包来完成数据可视化.编程平台使用的是jupyter,因此要求读者拥有anaconda环境,本文的代码均基于anaconda-5.3.0
Numpy篇
Pandas篇
Anaconda下载
图表类型
常见的图表有条形图,直方图,散点图,饼状图等等.不同的图表用于描述不同类型的数据.
例如柱状图用于描述不同类型数据之间的某一属性的关系,直方图用于描述同一类型数据在连续区间上的值的变化.
散点图则更适合反映出变量间的关系.饼状图用于描述某一数据占总和的比率.
什么是Matplotlib?
Matplotlib-API
菜鸟教程-Matplotlib
-
Matplotlib 是 Python 的绘图库,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。
-
Matplotlib 可以用来绘制各种静态,动态,交互式的图表。
-
Matplotlib 是一个非常强大的 Python 画图工具,我们可以使用该工具将很多数据通过图表的形式更直观的呈现出来。
-
Matplotlib 可以绘制线图、散点图、等高线图、条形图、柱状图、3D 图形、甚至是图形动画等等。
-
Matplotlib依托于Python,借助Python强大的可扩展性,使其支持各种平台,并且能够根据Numpy ndarray数组进行图像绘制,且使用简单,代码清晰易懂。
-
Matplotlib基于Matlab并且基于面向对象这一思想。
-
Matplotlib实现了几乎完全是自主控制的图形定义功能。
折线图
首先再jupyter里导入matplotlib和numpy的包(下文统称plt和np)
from matplotlib import pyplot as plt #导入模块
import numpy as np
如果版本不一样,没关系,你可以使用你的版本,当然你也可以在cmd中输入conda update metplotlib进行版本升级

下文有些部分可能会使用这种语法,可能有部分人用的少,我讲解一下
这种语法其实就是:
在for循环中,遍历的索引的值其实是可以作为另一语句的参数的,例如这里 %i 就代表把遍历的i的值作为 '日期%s’的参数传递进去,因此最终循环十次就可以得到下面这种情况

之后就是首先了解一些简单的函数
plot
plot函数用于绘制折线图
plot讲解
plt.plot(x, y, color='red', alpha=0.3,linestyle='-', linewidth=5, marker='o' , markeredgecolor='r', markersize='20’, markeredgewidth=10)
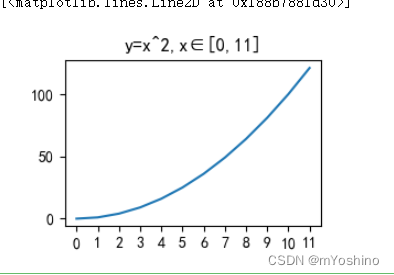
比较特殊的是,plot这个函数并不是必要的一定要传入x,y,也可以之传入一个参数,那么这个参数将会作为y被解析,而x则代表的是y的长度-1,即 x可以省略,默认[0,…,N-1]递增,N为y轴的元素个数例如:
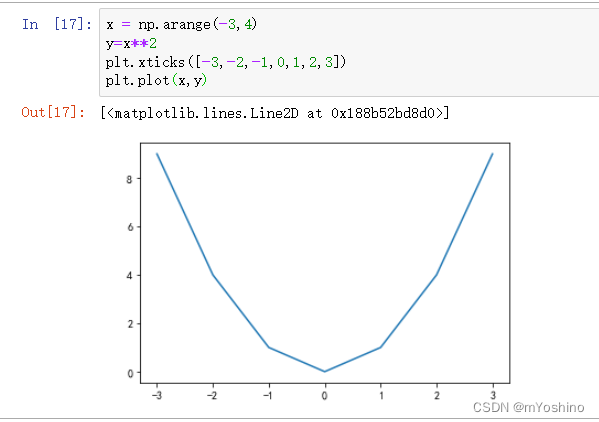
plt.xticks(np.arange(12),np.arange(12))
plt.title('y=x^2,x∈[0,11]')
plt.plot(np.arange(12)**2) # 只传入y
可以发现我并没有传入x,y而可以发现x轴的刻度其实就是y轴上数据个数-1(这里我是用xticks显式标注了一下,你也可以去掉看效果).如果只传入一个参数,那么这个参数被解析为y轴上的值,而不是x轴的,因此这个图他的x轴和y轴表示的分别是:x轴—>len(y轴)-1, y轴—>x^2,x∈[0,11]
rcParams,xlabel,title
rcParams,这是一个参数字典,我们可以对对应的参数进行设置,例如设置字体等
这里重点介绍rcParams
- plt.rcParams[‘figure.figsize’]=(8.0,4.0) #设置figure_size英寸
- plt.rcParams['figure.dpi] = 300 #分辨率
默认的像素:[6.0,4.0],分辨率为72,图片尺寸为432x288·- 指定dpi=100,图片尺寸为600*400
- 指定dpi=300,图片尺寸为1800*1200
xlabel和ylabel则用来设置x和y轴的轴名称
title则用来设置当前画布的名称
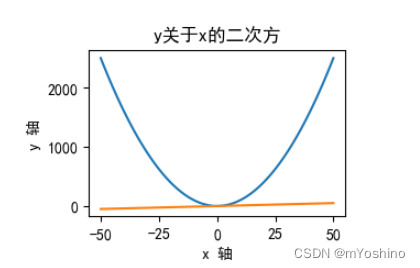
plot用于描绘一个简单的2D关系图
x = np.arange(-50,51)
y=x**2
z=x
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为中文黑体
plt.rcParams['axes.unicode_minus'] = False # 关闭unicode的负号配置 去掉这句话要报错
plt.rcParams['figure.dpi'] = 100 # 分辨率设置
plt.rcParams['figure.figsize'] = (3,2) # 英寸设置
plt.title('y关于x的二次方') # 设置图表名
plt.xlabel('x 轴')
plt.ylabel('y 轴')
plt.plot(x,y) # 第一个matplotlib程序
plt.plot(x,z) # 一个画布中可以描绘多条线
xticks
仅仅使用以上参数,我们将很难表述一些其他关系模型
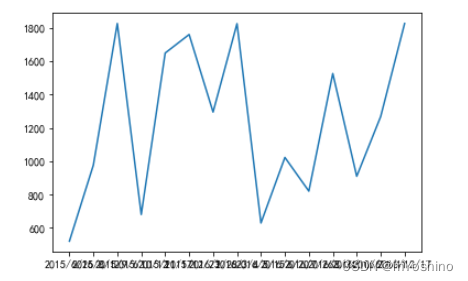
可以发现x轴完全模糊,不知其意,因此我们需要对轴刻度进行设置
设置x轴和y轴的刻度
matplotlib. pyplot.xticks(ticks=None,labels=None,**kwargs)
matplotlib. pyplot.yticks(ticks=None,labels=None,**kwargs)
参数:
ticks:此参数是xticx位置的列表。和一个可选参数。如果将一个空列表作为参数传递,则它将删除所有xticks,其显示的刻度数随传递的数组范围进行变化,列表中的元素的数据将被作为索引来设置x轴刻度,例如传递一个range(0,10,2)
表示的是显示10个刻度,但是每隔1个刻度才会显示一次刻度的名称
label:此参数包含放置在给定刻度线位置的标签。它是一个可选参数。
**kwargs:此参数是文本属性,用于控制标签的外观
rotation:旋转角度如:rotation=45
color:颜色如:color=“red”
#每个时间点的销量绘图
times =['2015/6/26','2015/8/1','2015/9/6','2015/10/12','2015/11/17',' 2015/12/23','2016/1/28','2016/3/4',
'2016/5/15','2016/6/20', '2016/7/26', '2016/8/31', '2016/10/6', '2016/11/11','2016/12/17']
#随机出销量
sales =np. random. randint(500,2000, size=len(times))
# 支出
expend = np.random.randint(700,3000,size=len(times))
plt.xticks(range(0,len(times)),labels=['%s-'%s for s in times],rotation='45') # 显示全部刻度,并且翻转45度
#绘制图形
plt.plot(times, sales,label='收入') # label用于设置图例说明
plt.plot(times,expend,label='支出')
plt.legend(loc='upper left')# 默认会使用每个图形的label值作为图例中的说明
for x,y in zip(times,sales): # zip表示
plt.text(x,y,'%s元'%y)
for x,y in zip(times,expend):
plt.text(x,y,'%s元'%y)
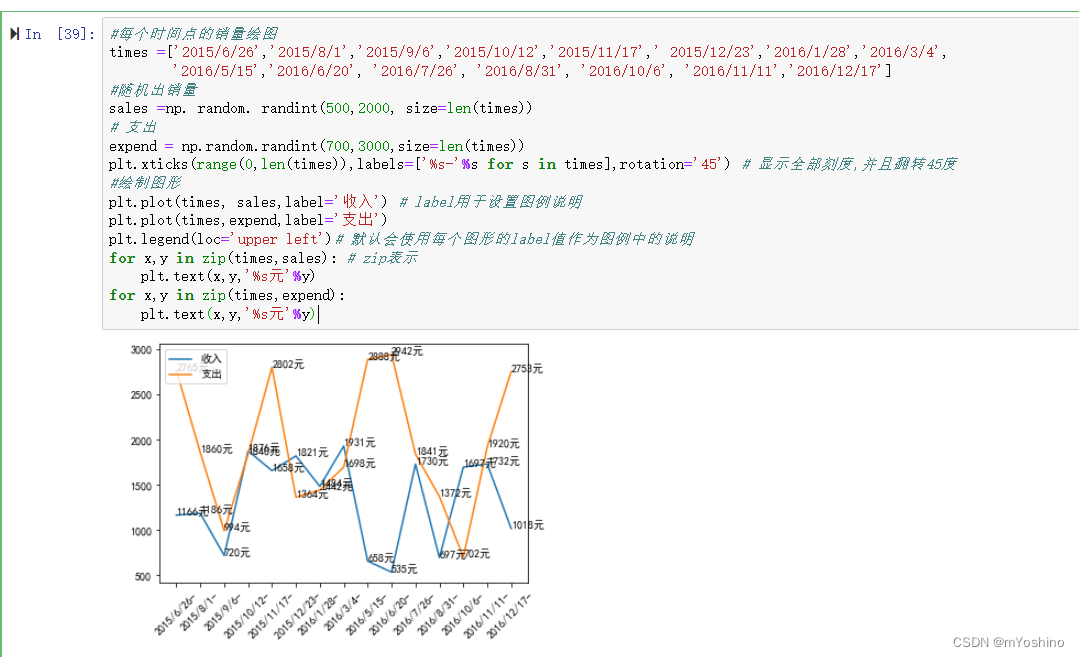
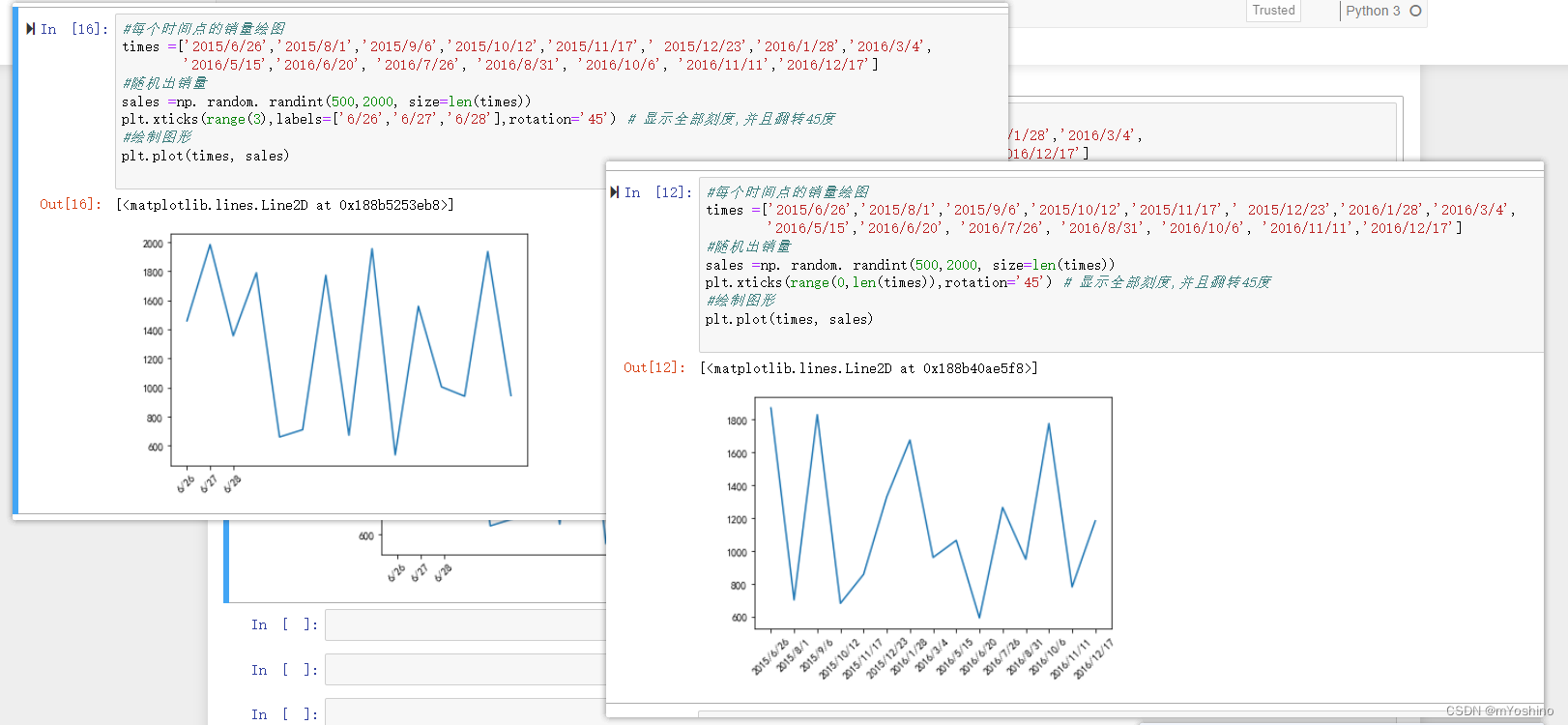
例如这里,第一个参数传递一个数组,这个数组的长度对应的就是刻度数,labels表示的是要显示的刻度的名称,如果不传递,就使用默认的刻度名称,rotation这个代表的是旋转角度
也可以单独传递一个要显示的刻度名称的数组
show
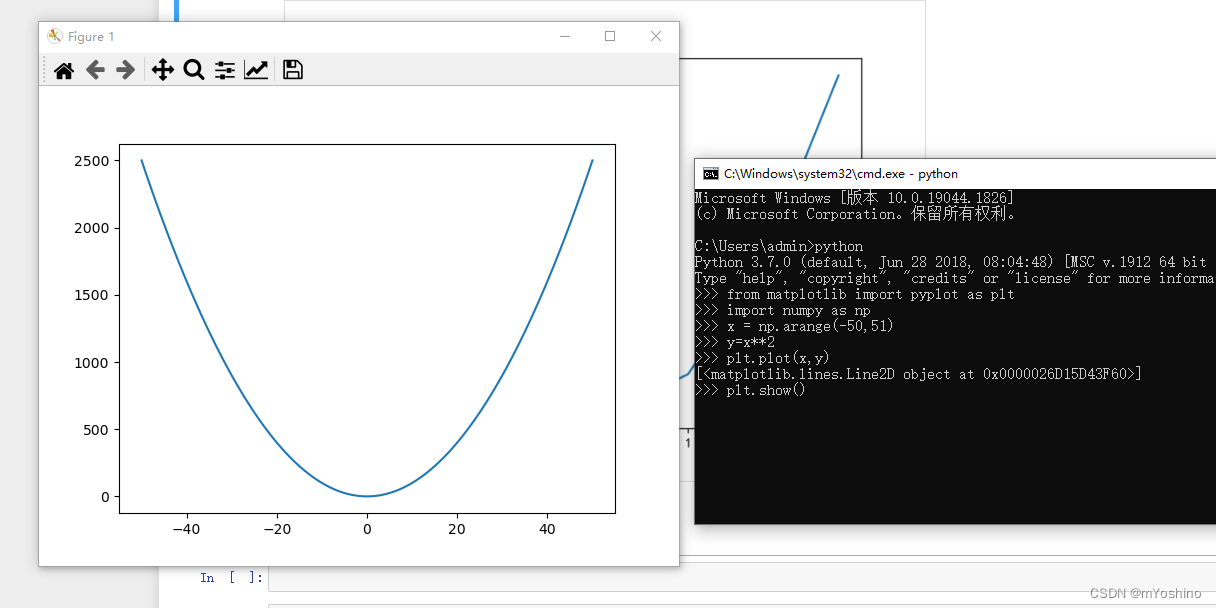
该方法用于显示所有打开的图形,而在jupyter模式下,默认就会给我们显现图形,因此我们不需要手动的调用,但是如果在cmd的环境下,那么我们就需要手动调用这个方法了,可以发现使用show方法调用出来的图像,有许多操作可以执行,放大缩小保存等,那么如何让我们在jupyter这个环境中也拥有这种效果呢?
Jupyter Notebook %matplotlib notebook魔法命令
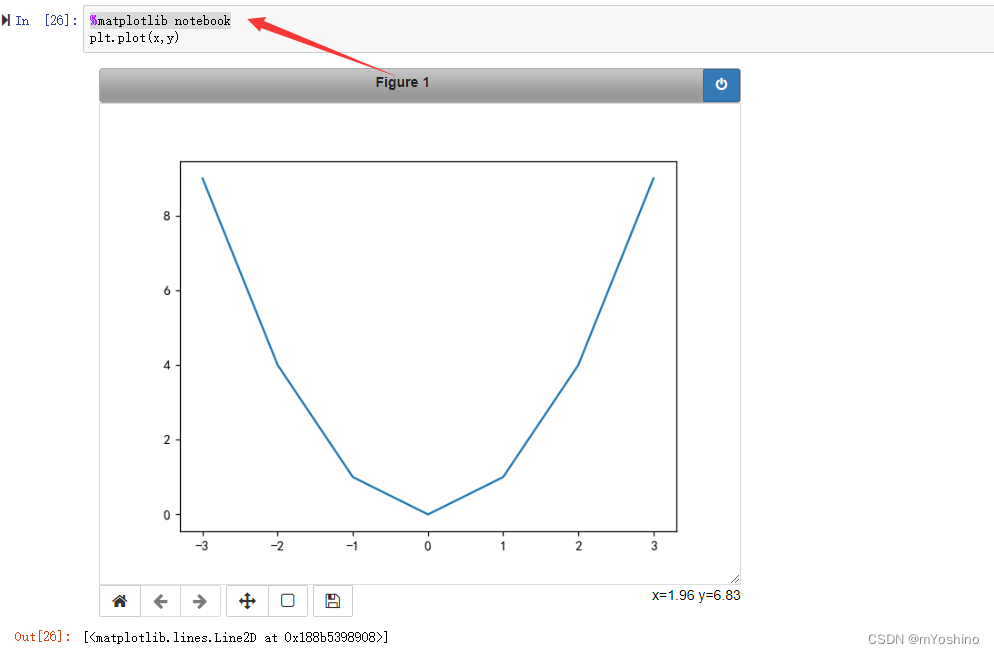
%matplotlib notebook
legend
plt.legend(loc)
- loc表示图例显示的位置
什么是图例?
图例是集中于地图一角或者一侧的地图上各种符号和颜色所代表内容与指标的说明,有助于更好的认识地图.
#每个时间点的销量绘图
times =['2015/6/26','2015/8/1','2015/9/6','2015/10/12','2015/11/17',' 2015/12/23','2016/1/28','2016/3/4',
'2016/5/15','2016/6/20', '2016/7/26', '2016/8/31', '2016/10/6', '2016/11/11','2016/12/17']
#随机出销量
sales =np. random. randint(500,2000, size=len(times))
# 支出
expend = np.random.randint(700,3000,size=len(times))
plt.xticks(range(0,len(times)),rotation='45') # 显示全部刻度,并且翻转45度
#绘制图形
plt.plot(times, sales,label='收入') # label用于设置图例说明
plt.plot(times,expend,label='支出')
plt.legend()# 默认会使用每个图形的label值作为图例中的说明
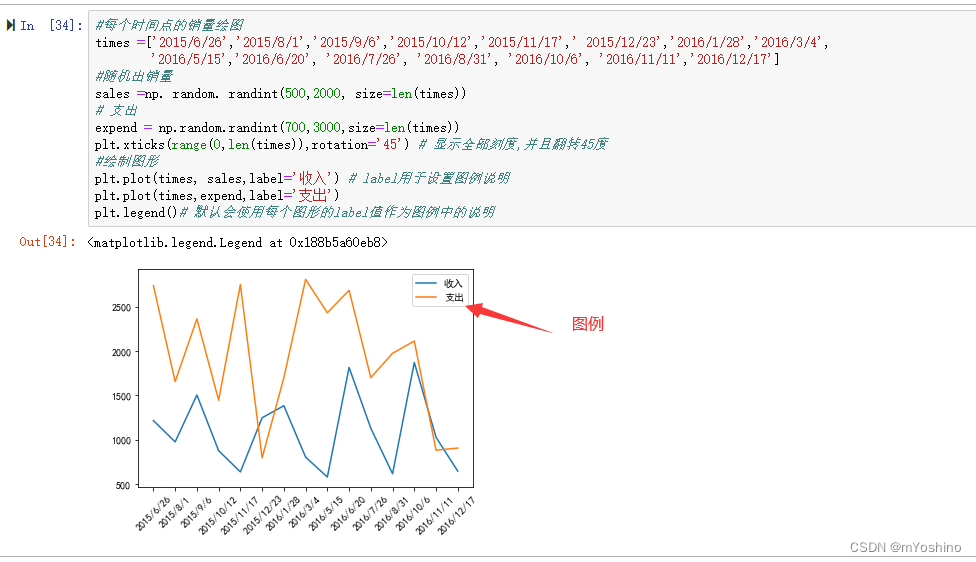
我们还能对图例所存在的位置进行设置
plt.legend(loc='upper left')# 设置图例位置为左上角
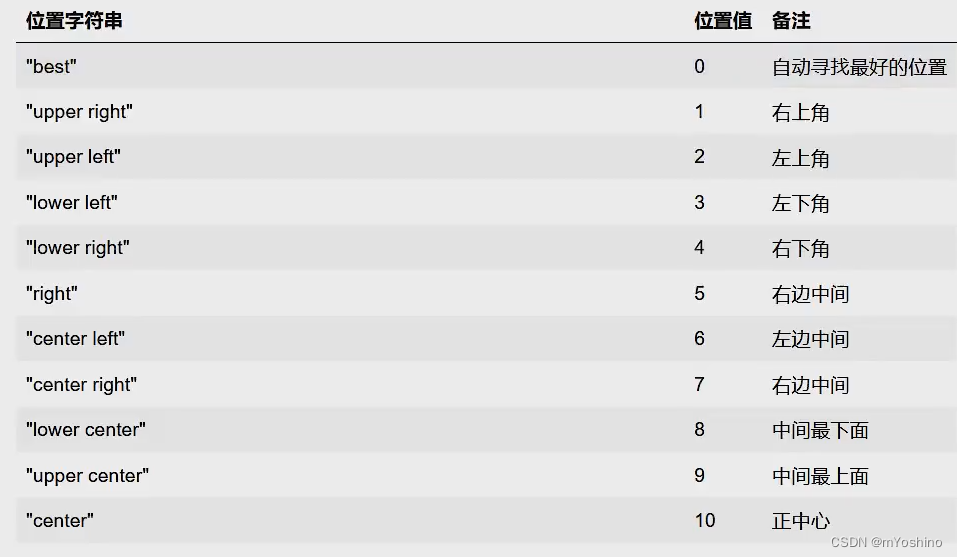
loc代表了图例在整个坐标轴平面中的位置(一般选取’best’这个参数值)
- 第一种:默认是"best",图例自动安家’在一个坐标面内的数据图表最少的位置
- 第二种: loc = 'XXX’分别有0: ‘best’(自动寻找最好的位置)
text
plt. text(x,y,string, fontsize=15, verticalalignment="top", horizontalalignment="right")
- x,y:表示坐标值上的值
- string:表示说明文字
- fontsize:表示字体大小
- verticalalignment: (va)垂直对齐方式,参数:[ ‘center’ i ‘top’ | ‘bottom’ / ‘baseline’]
- horizontalalignment: (ha)水平对齐方式,参数:[ ‘center’ | ‘right’ | ‘left’ ]
当前函数用于设置每个点上显示的数据,首先前两个参数用于指定到某一个具体的点上,然后string参数表示这个点要显示的值
python的for循环中的zip
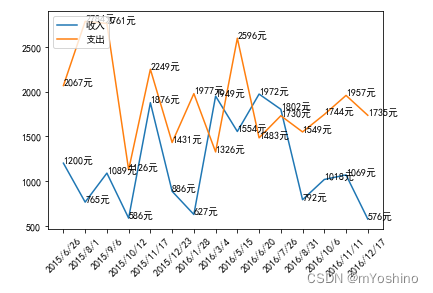
#每个时间点的销量绘图
times =['2015/6/26','2015/8/1','2015/9/6','2015/10/12','2015/11/17',' 2015/12/23','2016/1/28','2016/3/4',
'2016/5/15','2016/6/20', '2016/7/26', '2016/8/31', '2016/10/6', '2016/11/11','2016/12/17']
#随机出销量
sales =np. random. randint(500,2000, size=len(times))
# 支出
expend = np.random.randint(700,3000,size=len(times))
plt.xticks(range(0,len(times)),rotation='45') # 显示全部刻度,并且翻转45度
#绘制图形
plt.plot(times, sales,label='收入') # label用于设置图例说明
plt.plot(times,expend,label='支出')
plt.legend(loc='upper left')# 默认会使用每个图形的label值作为图例中的说明
for x,y in zip(times,sales): # zip表示
plt.text(x,y,'%s元'%y) # %进行格式化取值
for x,y in zip(times,expend):
plt.text(x,y,'%s元'%y)
grid
plt. grid(True,linestyle = " --" ,color = "gray", linewidth = "0.5", axis = 'x')
显示网格
- linestyle:线型
- color:颜色
- linewidth:宽度
- axis: x,y, both,显示x/y两者的格网
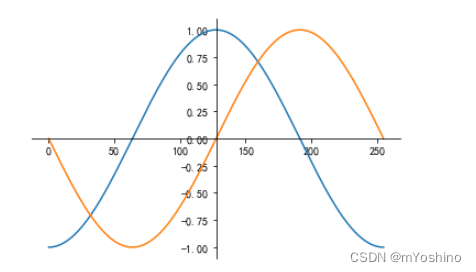
x = np.linspace(-np.pi,np.pi,256,endpoint=True)
c,s = np.cos(x),np.sin(x)
plt.plot(c)
plt.plot(s)
plt.grid(True,linestyle="-",color='gray',linewidth='0.5',axis='both')
# 显示网格
# linestyle:线性
# color:颜色
# linewidth:宽度
# axis:x,y,both,显示x/y两者的网格
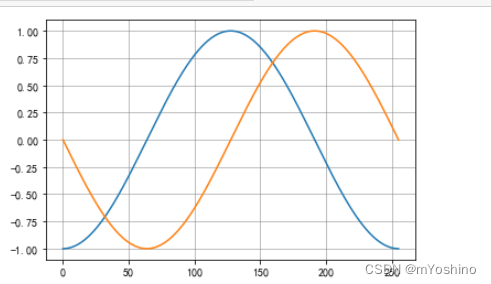
gca(get current axes)
当前方法用于获取matplotlib中的坐标轴,也就是上图中对应的四条把cosx和sinx框起来的线.
使用gca可以对这四根线进行各种操作
x = np.linspace(-np.pi,np.pi,256,endpoint=True)
c,s = np.cos(x),np.sin(x)
# 获取坐标轴对象
axes = plt.gca()
#通过坐标轴spines,确定top,bottom,left,right(分别表示上下左右)
axes.spines['right'].set_color('none')
axes.spines['top'].set_color('none')
# axes:0.0-1.0之间的值,整个轴上的比例
axes.spines['left'].set_position(('axes',0.5))
#移动下轴到指定位置
# 'data'表示按数值挪动,其后数字代表挪动到Y轴的刻度值
axes.spines['bottom'].set_position(('data',0.0))
plt.plot(c)
plt.plot(s)
图形对象的创建
plt.figure(num=None,figsize=None,dpi=None,facecolor=None,edgecolor=None,frameon=True,**kwargs)
参数说明:
num:图像编号或名称,数字为编号,字符串为名称
figsize:指定figure的宽和高,单位为英寸;
dpi:定绘图对象的分辨率,即每英寸多少个像素,缺省值为72
facecolor:背景颜色
edgecolor:边框颜色
frameon:是否显示边框
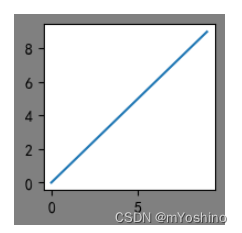
在Matplotlib中,面向对象编程的核心思想是创建图形对象(figure object)。通过图形对象来调用其它的方法和属性,这样有助于我们更好地处理多个画布。在这个过程中,pyplot 负责生成图形对象,并通过该对象来添加一个或多个axes对象(即绘图区域)。
Matplotlib-提供了matplotlib.figure图形类模块,它包含了创建图形对象的方法。通过调用pyplot模块中 figure()函数来实例化figure 对象。
x=np.arange(10)
y=x
plt.figure('f1',figsize=(2,2),dpi=100,facecolor='gray')
plt.plot(x,y)
绘制子图
figure是绘制对象(可理解为一个空白的画布),一个figure对象可以包含多个Axes子图,一个Axes是一个绘图区域,不加设置时,Axes为1,且每次绘图其实都是在figure上的Axes上绘图。
接下来将学习绘制子图的几种方式:
- add_axes():添加区域
- subplot():均等地划分画布,只是创建一个包含子图区域的画布,(返回区域对象)
- subplots():既创建了一个包含子图区域的画布,又创建了一个figure图形对象.(返回图形对象和区域对象)
add_axes
添加区域
Matplotib定义了一个axes类(轴域类),该类的对象被称为axes对象(即轴域对象),它指定了一个有数值范围限制的绘图区域。在一个给定的画布(figure)中可以包含多个axes对象,但是同一个axes对象只能在一个画布中使用。
add_axes(rect)
该方法用来生成一个axes轴域对象,对象的位置由参数rect决定
rect是位置参数,接受一个由4个元素组成的浮点数列表,形如[left, bottom, width, height],它表示添加到画布中的矩形区域的左下角坐标(x, y),以及宽度和高度。
fig = plt.figure(figsize=(4,2),facecolor='gray')
f1 = fig.add_axes([0,0,1,0.5])
f2 = fig.add_axes([0.5,0.5,0.2,0.2])
f1.plot([[1,2,3,4,5],[2,3,4,5,6]]) # 指定在f1上绘制
f2.plot([[1,2,3,4,5],[2,3,4,5,6]]) # 指定在f2上绘制
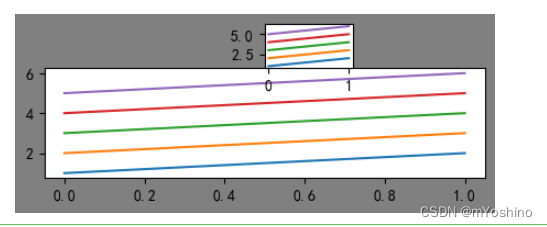
fig = plt.figure(figsize=(4,2),facecolor='gray')
f1 = fig.add_axes([0,0,1,0.5])
f2 = fig.add_axes([0.5,0.5,0.2,0.2])
plt.plot([[1,2,3],[2,3,4]]) # 由于f2后赋值
plt.plot([[3,2,1],[-4,-3,-2]]) # 因此全都在f2中绘制
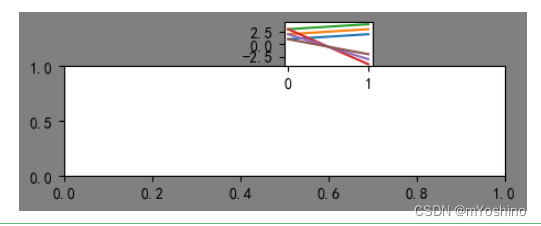
fig = plt.figure() # 获取图形对象
ax = plt.gca() # 获取画布
ax.plot() # 可以在gca返回的画布上进行作画
fig.plot() # 不可以在图像对象想进行plot操作

subplot
该函数用于均匀的划分画布
参数格式如下:
ax = plt.subplot(nrows,ncols,index,*args,**kwargs)
- nrows行
- ncols 列 index:索引
- kwargs: title/xlabel/ylabel等.……
也可以直接将几个值写到一起,如:subplot(233)
返回:区域对象
nrows与ncols表示要划分几行几列的子区域(nrows*nclos表示子图数量),index的初始值为1,用来选定具体的某个子区域。例如: subplot(233)表示在当前画布的右上角创建一个两行三列的绘图区域(如下图所示),同时,选择在第3个位置绘制子图。
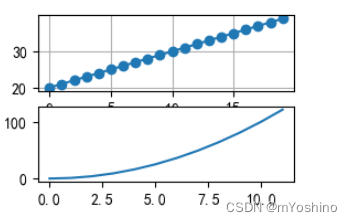
# 默认画布分割为2行1列,当前所在第一个区域
plt.subplot(211)
# x可以省略,默认[0,....,N-1]递增,N为y轴的元素个数
plt.plot(range(20,40),marker='o')
plt.grid()
#默认画布分割为2行1列,当前所在第二个区域
plt.subplot(212)
plt.plot(np.arange(12)**2)
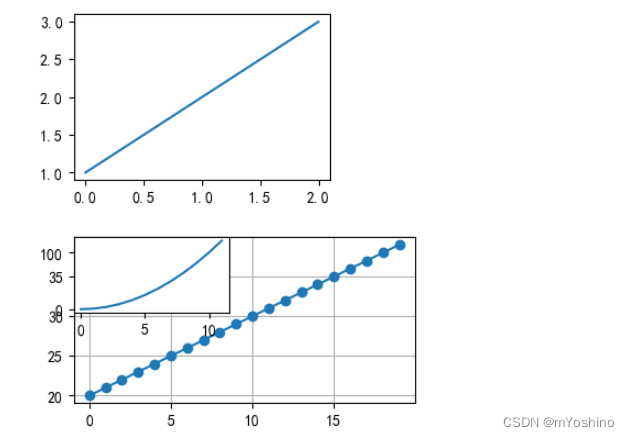
同时,如果新建的子图与现有的子图重叠,那么重叠部分的子图会被自动删除,因为他们不可以共享绘图区域.
plt.plot([1,2,3]) # 这个会被后面两个子图覆盖
# 默认画布分割为2行1列,当前所在第一个区域
plt.subplot(211)
# x可以省略,默认[0,....,N-1]递增,N为y轴的元素个数
plt.plot(range(20,40),marker='o')
plt.grid()
#默认画布分割为2行1列,当前所在第二个区域
plt.subplot(212)
plt.plot(np.arange(12)**2)
# 此代码的运行效果如上
如果想要原来的画布不被覆盖,那么就应该新建一个画布,也就是使用figure新建画布
plt.plot([1,2,3])
fig = plt.figure(figsize=(4,2)) # 新建画布
# 默认画布分割为2行1列,当前所在第一个区域
fig.add_subplot(111) # 为新建的画布添加子图
# x可以省略,默认[0,....,N-1]递增,N为y轴的元素个数
plt.plot(range(20,40),marker='o') # plt.plot此时认为画布为fig这个画布
plt.grid()
#默认画布分割为2行1列,当前所在第二个区域
fig.add_subplot(221)
plt.plot(np.arange(12)**2)
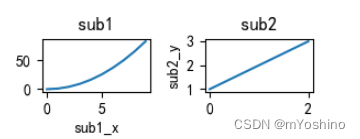
同时我们也可以在subplot内部添加一些title,xlabel的参数
plt.subplot(221,title='sub1',xlabel='sub1_x')
plt.plot(np.arange(10)**2)
plt.subplot(222,title='sub2',ylabel='sub2_y')
plt.plot([1,2,3])
plt.tight_layout() # 紧凑布局 防止标签重叠
具体参数可以在subplot参数处按下shift+tab建查看

也可以通过创建区域,然后通过区域的set方法进行设置
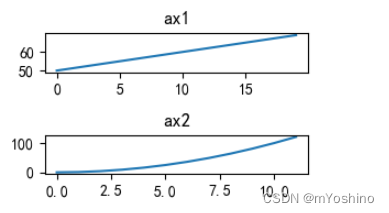
# 对返回的区域设置
ax1 = plt.subplot(211)
ax2 = plt.subplot(212)
ax1.set_title('ax1')
ax1.plot(range(50,70))
ax2.set_title('ax2')
ax2.plot(np.arange(12)**2)
plt.tight_layout()
subplots
matplotlib.pyplot模块提供了一个subplots()函数,它的使用方法和subplot()函数类似。其不同之处在于,subplots()既创建了一个包含子图区域的画布,又创建了一个 figure图形对象,而subplot()只是创建一个包含子图区域的画布。
subplots的函数格式如下:
fig , axes = plt.subplots(nrows,ncols)
nrows 与ncols表示两个整数参数,它们指定子图所占的行数、列
函数的返回值是一个元组,包括一个图开附象和所有的 axs对象。其中axes对象的数量等于nrows * ncols,且每个axes 对象均可通过索引值访问(从0开始),如下2行2列数据:
# 创建2行2列的子图,返回图形对象(画布),所有子图的坐标轴
fig,axes = plt.subplots(2,2)
# 第一个区域ax1
ax1 = axes[0][0]
# x轴
x = np.arange(1,5)
# 绘制平方函数
ax1.plot(x,x*x)
ax1.set_title('square')
# 绘制平方根图像
axes[0][1].plot(x,np.sqrt(x))
axes[0][1].set_title('sqrt')
# 绘制指数函数
axes[1][0].plot(x,np.exp(x))
axes[1][0].set_title('exp')
# 绘制对数函数
axes[1][1].plot(x,np.log10(x))
axes[1][1].set_title('log')
# 处理标题遮挡问题
plt.tight_layout()

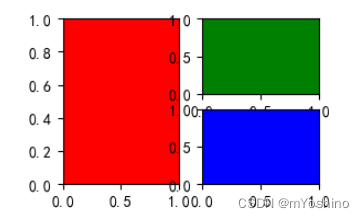
# 绘制1行2列子图中的第1个子图
plt.subplot(121,facecolor='r')
# 绘制2行2列子图中的第2个子图
plt.subplot(222,facecolor='g')
# 绘制2行2列子图中的第3个子图
plt.subplot(224,facecolor='b')
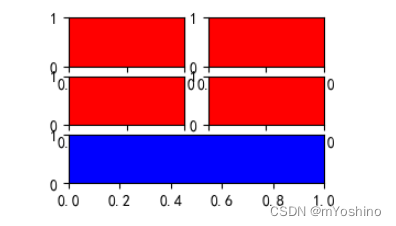
plt.subplot(321,facecolor='r')
plt.subplot(322,facecolor='r')
plt.subplot(323,facecolor='r')
plt.subplot(324,facecolor='r')
plt.subplot(313,facecolor='b')
柱状图
柱状图是一种用矩形柱来表示数据分少的图表。
柱状图可以垂直绘制,也可以水平绘制。
它的高度与其所表示的数值成正比关系。
柱状图显示了不同类别之间的比较关系,图表的水平轴X指定被比较的类别,垂直轴Y则表示具体的类别值
bar
matplotlib.pyplot.bar(x,height,width:float = 0.8, bottom = None,*, align: str = ‘center’, data = None,**kwargs)
- x表示x坐标,数据类型为float类型,一般为np.arange()生成的固定步长列表
- height 表示柱状图的高度,也就是y坐标值,数据类型为float类型,一般为一个列表,包含生成柱状图的所有y值.
- width表示柱状图的宽度,取值在0~1之间,默认值为0.8
- bottom柱状图的起始位置,也就是y轴的起始坐标,默认值为None.
- align柱状图的中心位置,“center”,"lege"边缘,默认值为’center’. color柱状图颜色,默认为蓝色
- alpha透明度,取值在0~1之间,默认值为1.
- label标签,设置后需要调用plt.legend()生成. edgecolor 边框颜色(ec)
- linewidth边框宽度,浮点数或类数组,默认为None (lw)
- tick _label:柱子的刻度标签,字符串或字符串列表,默认值为None.
- linestyle :线条样式(ls)
这里要求data的数量与x的数量保持一致,否则报错
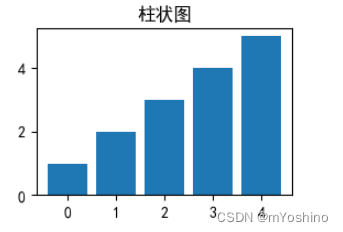
先来一个简单的柱状图程序
x = range(5) # x坐标
data = [1,2,3,4,5] # y轴对应数据
plt.title('柱状图') # 设置标题
plt.xticks(x) # 设置刻度为x
plt.bar(x,data) # 显示柱状图
现在来介绍不太好理解的参数,bottom,这个参数代表的是柱状图的底部距离x轴的距离
例如bottom为3,那么对应的柱子的起始位置为3而不是0,注意这里的bottom接受的是一个数组,也就是每一个数据对应的离x轴的距离
x = range(5) # x坐标
data = [1,2,3,4,5] # y轴对应数据
bottom = [4,5,6,7,8]
color = ['r','g','b'] # 循环使用三种颜色
plt.title('柱状图') # 设置标题
plt.xticks(x) # 设置刻度为x
plt.bar(x,data,bottom=bottom,color=color,ec='black',ls='--',lw=2) # 显示柱状图

其次由于柱状图主要用于比较数据大小,因此多数据柱状图非常常见,如下
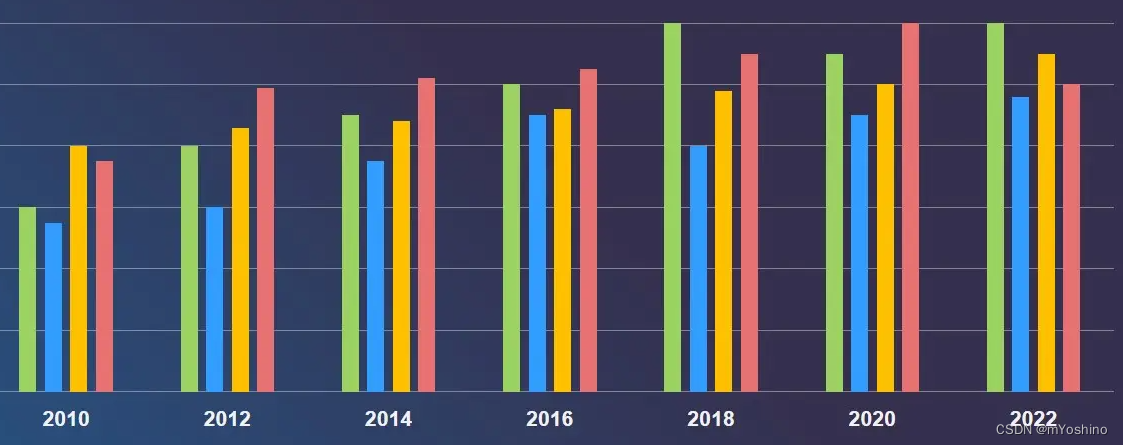
对于这种柱状图需要做到
- x轴不固定,可能是文字,也可能是数字,因此需要对x轴进行转换
- 确定同一x轴中,每个柱状图x轴的起始位置
- 设置图形的宽度
- 图形2的起始位置=图形2起始位置+图形的宽度
- 图形3的起始位置=图形3起始位置+2倍图形宽度
- 需要给每个柱状图循环显示文本内容
- 显示图例,使得每个颜色的柱子代表的是某种分类
years = ['2010','2012','2014','2016','2018','2020','2022']
plt.figure(figsize=(5,4))
one = [12,7,8,4,9,10,15]
two = [13,4,9,3,2,1,7]
three = [7,4,8,0,1,5,6]
four = [9,4,1,4,1,7,5]
x = np.arange(len(years))
width=0.2
one_x = x
two_x = x + 0.2
three_x = x + 0.2 * 2
four_x = x + 0.2 * 3
plt.xticks(x+width+0.1,labels=years) # 设置x轴名称
for i in range(len(years)):
plt.text(x[i],one[i],one[i],va='bottom',ha='center')
for i in range(len(years)):
plt.text(x[i]+0.2,two[i],two[i],va='bottom',ha='center')
for i in range(len(years)):
plt.text(x[i]+0.2*2,three[i],three[i],va='bottom',ha='center')
for i in range(len(years)):
plt.text(x[i]+0.2*3,four[i],four[i],va='bottom',ha='center')
plt.bar(one_x,one,width=width)
plt.bar(two_x,two,width=width)
plt.bar(three_x,three,width=width)
plt.bar(four_x,four,width=width)
va和ha代表的分别是vertical和horizental,也就是垂直的和水平的位置
这里需要讲解的首先是xticks为什么要这么写,首先xticks如果不设置,那么默认的x轴刻度名称出现的位置是蓝色柱子的中间,这就是默认的设置,因此为了让图形看起来和谐,需要将下面的刻度移动到四根柱子的中间,那么如果每根柱子的width=0.2,那么要移动到中间,就应该是width+width/2=0.3,因为默认刻度是在中间的,移动到下一根需要width/2
其次就是text的使用,text(x,y,str),首先其实蓝色柱子的x位置还是x这个数组中对应的,我们移动的只是刻度而已,因此需要在蓝色柱子上加上数值标注,需要遍历的是x,而其他颜色的柱子,就需要添加偏移量了.
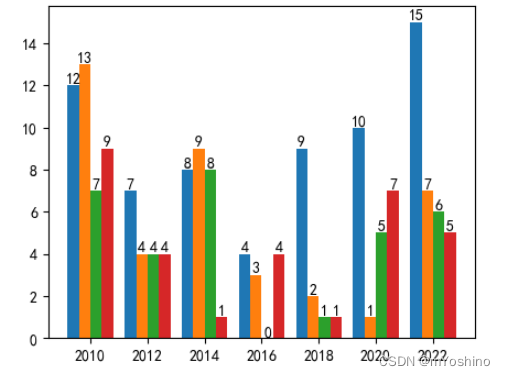
years = ['2010','2012','2014','2016','2018','2020','2022']
plt.figure(figsize=(5,4))
one = [12,7,8,4,9,10,15]
two = [13,4,9,3,2,1,7]
three = [7,4,8,0,1,5,6]
four = [9,4,1,4,1,7,5]
x = np.arange(len(years))
width=0.2
plt.xticks(x,labels=years) # 设置x轴名称
total=0
plt.bar(x,one,width=width)
# for i in range(len(one)):
three_b = np.zeros(len(one))
for i in range(len(one)):
three_b[i]=one[i]+two[i]
plt.bar(x,two,bottom=one,width=width)
plt.bar(x,three,bottom=three_b,width=width)
four_b = np.zeros(len(one))
for i in range(len(one)):
four_b[i]=one[i]+two[i]+three[i]
plt.bar(x,four,bottom=four_b,width=width)
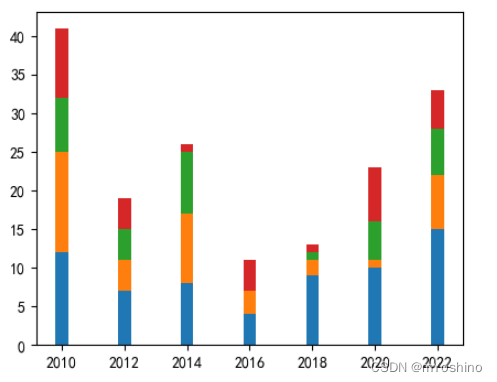
barh
plt.barh(y,width,height=0.8, left=None,*, align='center,**kwargs)
该函数用于生成水平柱状图
barh()函数的用法与bar()函数的用法基本一样,只是在调用barh()函数时使用y参数传入Y轴数据,使用width参数传入代表条柱宽度的数据,left参数类似于bar函数的bottom,只不过这里代表的是柱子离左侧的距离
one = [12,7,8,4,9,10,15]
years = ['2010','2012','2014','2016','2018','2020','2022']
plt.barh(years,one)

years = ['2010','2012','2014','2016','2018','2020','2022']
plt.figure(figsize=(5,4))
one = [12,7,8,4,9,10,15]
two = [13,4,9,3,2,1,7]
three = [7,4,8,0,1,5,6]
y = np.arange(len(years))
y_2 = y + 0.2
y_3 = y + 0.2 * 2
height=0.2
plt.yticks(y+0.2,years)
plt.barh(y,one,height=height)
plt.barh(y_2,two,height=height)
plt.barh(y_3,three,height)
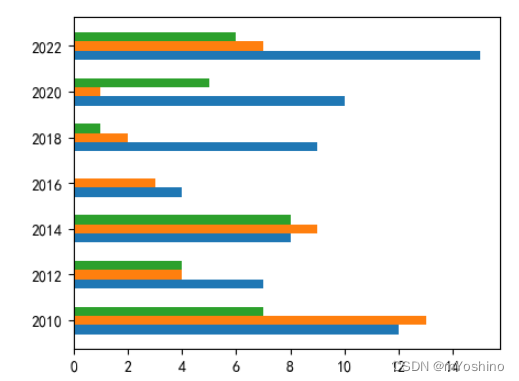
这里也可以自己练习一下,使用text为每一行表上值
直方图 hist
直方图(Histogram),又称质量分布图,它是一种条形图的一种,由一系列高度不等的纵向线段来表示数据分布的情况。直方图的横轴表示数据类型,纵轴表示分布情况。
首先,我们需要了解柱状图和直方图的区别。直方图用于概率分布,它显示了一组数值序列在给定的数值范围内出现的概率,其x轴是连续的;而柱状图则用于展示各个类别的频数。
plt. hist(x, bins=None,range=None,density=None,weights=None,cumulative=False, bottom=None,histtype=' bar',aligne'mid', orientation='vertical',rwidth=None,log=False,color=None,label=None,stacked=False,normed=None,*, data=None,**kwargs)
- x:作直方图所要用的数据,必须是一维数组;多维数组可以先进行扁平化再作图;必选参数
- bins:直方图的柱数,即要分的组数,默认为10;
- weights与x形状相同的权重数组;将x中的每个元素乘以对应权重值再计数;如果normed或density取值为True,则会对权重进行归一化处理。这个参数可用于绘制已合并的数据的直方图;
- density:布尔,可选。如果"True"”,返回元组的第一个元素将会将计数标准化以形成一个概率密度,也就是说,直方图下的面积(或积分)总和为1。这是通过将计数除以数字的数量来实现的观察乘以箱子的宽度而不是除以总数数量的观察。如果叠加也是“真实”的,那么柱状图被规范化为1。(替代normed)
- bottom:数组,标量值或None;每个柱子底部相对于y=0的位置。如果是标量值,则每个柱子相对于y=0向上/向下的偏移量相同。如果是数组,则根据数组元素取值移动对应的柱子;即直方图上下便宜距离;
- histtype: {‘bar’, barstacked’, ‘step’, 'stepfiled}; bar’是传统的条形直方图; ‘barstacked’是堆叠的条形直方图; ‘step’是未填充的条形直方图,只有外边框; ‘stepfilled’是有填充的直方图;当histtype取值为’step或’steprilled’,width设置失效,即不能指定柱子之间的间隔,默认连接在一起;
- align:{‘left’, ‘mid , right}; "left’:柱子的中心位于bins的左边缘;'mid ': 柱子位于bins左右边缘之间;'right: 柱子的中心位于bins的右边缘;
- color:具体颜色,数组(元素为颜色)或None。
- label:字符串(序列)或None;有多个数据集时,用label参数做标注区分;
- normed:是否将得到的直方图向量归一化,即显示占比,默认为0,不归一化;不推荐使用
建议改用density参数; - edgecolor:直方图边框颜色;
- alpha:透明度;
x = np.random.randint(50,101,100)
plt.xticks(np.arange(50,101,5))
plt.hist(x,bins=10,edgecolor='white')
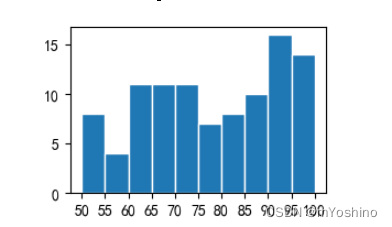
同时直方图函数拥有返回值
- n:数组或数组列表
直方图的值 - bins:数组
返回各个bin的区间范围 - patches : 返回每个bin里面包含的数据,是一个list
n,bins,patches = plt.hist(x,bins=10,edgecolor='white')
print('n是分组区间对应的频率',n,end='\n')
print('bins是分组时的间隔值',bins,end='\n')
print('patches是值直方图中列表对象',type(patches),end='\n')
for i in patches:
print(i)
print(i.get_x())
print(i.get_y())
print(i.get_height())
饼状图 pie
pyplot.pie(x,explode=None,labels=None,colors=None,autopct=None)
饼状图用来显示一个数据系列,具体来说,饼状图显示一个数据系列中各项目的占项目总和的百分比.
Matplotlib 提供了一个pie()函数,该函数可以生成数组中数据的饼状图。您可使用xlsum(x)来计算各个扇形区域占饼图总和的百分比。pie()函数的参数说明如下:
- x:数组序列,数组元素对应扇形区域的数量大小。
- labels:列表字符串序列,为每个扇形区域备注一个标签名字
- colors;为每个扇形区域设置颜色,默认按照颜色周期自动设置。
- autopct:格式化字符串"fmt%pct",使用百分比的格式设置每个扇形区的标签,并将其放置在扇形区内。
- pctdistance:设置百分比标签与圆心的距离;
- labeldistance:设置各扇形标签(图例)与圆心的距离;
- explode:指定饼图某些部分的突出显示,即呈现爆炸式;
- shadow:是否添加饼图的阴影效果
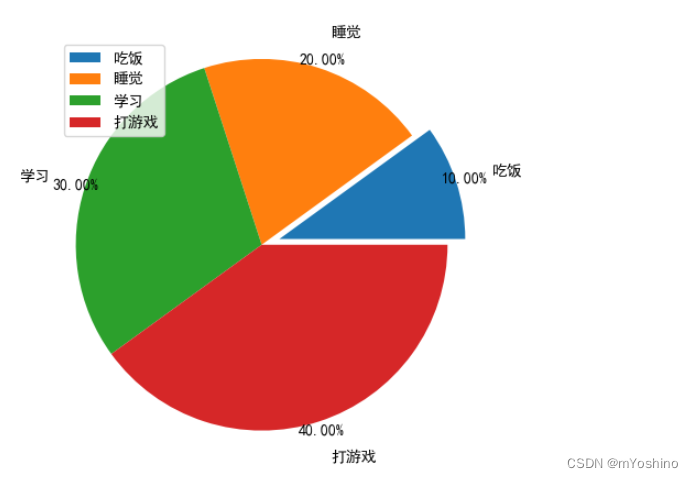
plt.rcParams['figure.figsize']=(5,5)
labels=['吃饭','睡觉','学习','打游戏'] # 数据标签
x = [100,200,300,400] # 数据占比
explode = [0.1,0,0,0] # 设置离圆心的距离
plt.pie(x,labels=labels,autopct='%.2f%%',explode=explode,labeldistance=1.2,pctdistance=1.05)
plt.axis('equal') # 设置图形为正圆
plt.legend() # 开启图例
散点图scatter
matplotlib.pyplot.scatter(x,y, s=None, c=None, marker=None,cmap=None, norm=None,
vmin=None,vmax=None, alpha=None, linewidths=None, , edgecolors=None, plotnonfinite=Falsedata=None, *kwargs)
散点图也叫X-Y图,它将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定。
通过观察散点图上数据点的分布情况,我们可以推断出变量间的相关性。如果变量之间不存在相互关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据点就会相对密集并以某种趋势呈现。
数据的相关关系主要分为:正相关(两个变量值同时增长)、负相关(一个变量值增加另一个变量值下降)、不相关、线性相关、指数相关等,表现在散点图上的大致分布如下图所示。那些离点集群较远的点我们称为离群点或者异常点。
- x,y→散点的坐标
- s→散点的面积
- c→散点的颜色(默认值为蓝色,‘b’,其余颜色同plt.plot( ))
- marker →散点样式(默认值为实心圆, ‘o’,其余样式同plt.plot( ))
- alpha→散点透明度([0,1]之间的数,0表示完全透明,1则表示完全不透明)
- linewidths→散点的边缘线宽
- edgecolors→散点的边缘颜色
- cmap →Colormap,默认None,标量或者是一个colormap的名字,只有c是一个浮点数数组的时才使用
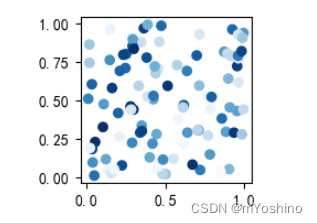
plt.figure(figsize=(2,2))
x = np.array([1,2,3,4,5,6])
y = [1,2,3,4,5,6]
s=np.array([1,2,3,4,5,6])
# plt.scatter(x,y,s=s**2,alpha=0.9,c=np.random.randint(90,100,6))
plt.scatter(np.random.rand(100),np.random.rand(100),cmap='Blues',c=np.random.rand(100))
# plt.plot(x,y)
箱线图boxplot
**matploti.pyplot.boxplot(x, notch=None, sym=None, ert=None, whis=None, postions=None, widths=None, patch_artist=None,bootstrap=None,usermedians=None,conf_intervals=None, meanline=None, showmeans=None, showcaps=None,showbox=None,showiers=None, boxprops=None,labels=None, fierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None,** manage_ticks=Ture,autorange=False,zorder=None, *, data=None)
箱线图(Boxplot)是一种用作显示一组数据分散情况资料的统计图表
箱线图,又称箱形图(boxplot)或盒式图,不同于一般的折线图、柱状图或饼图等图表,其包含一些统计学的均值、分位数、极值等统计量,该图信息量较大,不仅能够分析不同类别数据平均水平差异,还能揭示数据间离散程度、异常值、分布差异等。
- x:输入数据。类型为数组或向量序列。必备参数。
- notch:控制箱体中央是否有V型凹槽。当取值为True时,箱体中央有V型凹槽,凹槽表示中位数的置信区间;取值为Fase时,箱体为矩形。类型为布尔值,默认值为False。可选参数。
- vert: 箱体的方向,当取值为True时,绘制垂直箱体,当取值为False时,绘制水平箱体。类型为布尔值,默认值为True。可选参数
- positions:指定箱体的位置。刻度和极值会自动匹配箱体位置。类型为类数组结构。可选参数。默认值为range(1,N+1),N方为箱线图的个数
- widths:箱体的宽度。类型为浮点数或类数组结构。默认值为0.5或0.15*极值间的距离。
- labels:每个数据集的标签,默认值为’None’。类型为序列。可选参数。
- autorange:类型为布尔值,默认值为False。可选参数。当取值为True且数据分布满足上四分位数(75%)和下四分位数(25%)
- showmeans:是否显示算术平均值。类型为布尔值,默认值为False。可选参数。
- meanline:均值显示为线还是点。类型为布尔值,默认值为False。可选参数。当取值为True,且showmeans、
shownotches参数均为Tue,时显示为线 - capprops:箱须横杠的样式。类型为字典,默认值为None。可选参数。
- boxprops:箱体的样式。类型为字典,默认值为None。可选参数
- whiskerprops:箱须的样式。类型为字典,默认值为None。可选参数。
- flierprops:离群点的样式。类型为字典,默认值为None。可选参数。
- medianprops:中位数的样式。类型为字典,默认值为None。可选参数。
- meanprops:算术平均值的样式。类型为字典,默认值为None。可选参数。
图片保存
savefig(fname,dpi=None, facecolor=' w', edgecolor='w' , orientation=’portrait’,papertype=None,format=None,transparent=False, bbox_inches=None,pad_inches=0.1,frameon=None,metadata=None)
- fname:(字符串或者仿路径或仿文件)如果格式已经设置,这将决定输出的格式并将文件按fname来保存。如果格式没有设置,在fname有扩展名的情况下推断按此保存,没有扩展名将按照黑人格式存储为“png"格式,并将适当的扩展名添加在fname后面。
- dpi:分辨率,每英寸的点数
- facecolor(颜色或" auto”,默认值是“auto")︰图形表面颜色。如果是“auto”,使用当前图形的表面颜色。
- edgecolor(颜色或" auto”,默认值: “auto"):图形边缘颜色。如果是“auto”,使用当前图形的边缘颜色。
- format(字符串)︰文件格式,比如"png",“pdf",“svg"等,未设置的行为将被记录在fname中。
- transparent:用于将图片背景设置为透明。图形也会是透明,除非通过关键字参数指定了表面颜色和/或边缘
特别主意:
第一个参数frame就是保存的路径,如果路径中包含未创建的文件夹就会报错,该方法只能用来创建文件,不会自动创建文件夹.同时,该方法必须要在show方法调用之前执行
plt.figure(figsize=(2,2))
x = np.array([1,2,3,4,5,6])
y = [1,2,3,4,5,6]
s=np.array([1,2,3,4,5,6])
plt.scatter(np.random.rand(100),np.random.rand(100),cmap='Blues',c=np.random.rand(100))
plt.savefig('photo.png') # savefig方法必须写在show方法前面
plt.show()

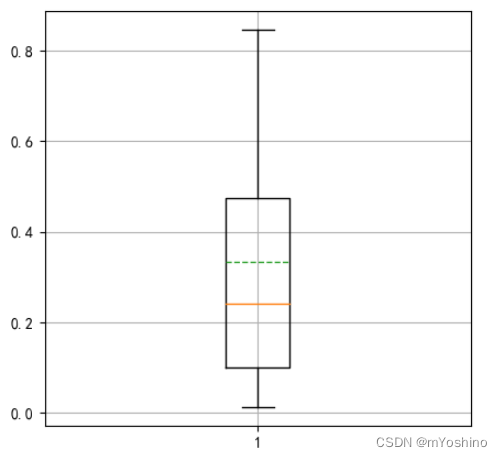
x = np.random.rand(20)
plt.boxplot(x,showmeans=True,meanline=True)
plt.grid()
plt.show()
词云图
wordcloud
wordcloud用于进行词云图的绘制
首先需要进行安装,方式为pip/conda install jieba
from wordcloud import WordCloud
with open('./learn/test.txt',encoding='utf-8') as file:
txt = file.read()
# 如果数据文件中包含中文,那么font_path必须指定字体,否则中文会乱码
wordcloud = WordCloud(font_path = 'C:/Windows/Fonts/simfang.ttf',
collocations=False,background_color='black',
width=800,
height=600,
max_words=50).generate(txt)
# 生成图片
image = wordcloud.to_image()
# 展示图片
image.show()
# 写入文件
wordcloud.to_file('./wordcloud.jpg')

jieba
jieba用于进行分词
如果没有安装,那么可以通过pip/conda install jieba进行安装
import jieba # 导入jieba进行分词
seg_list = jieba.cut('我来自东北呀,你来自哪里',cut_all=True)
print('全模式 '+' '.join(seg_list))
seg_list = jieba.cut('我来自东北亚,你来自哪里',cut_all=False)
print('精确模式 '+' '.join(seg_list))

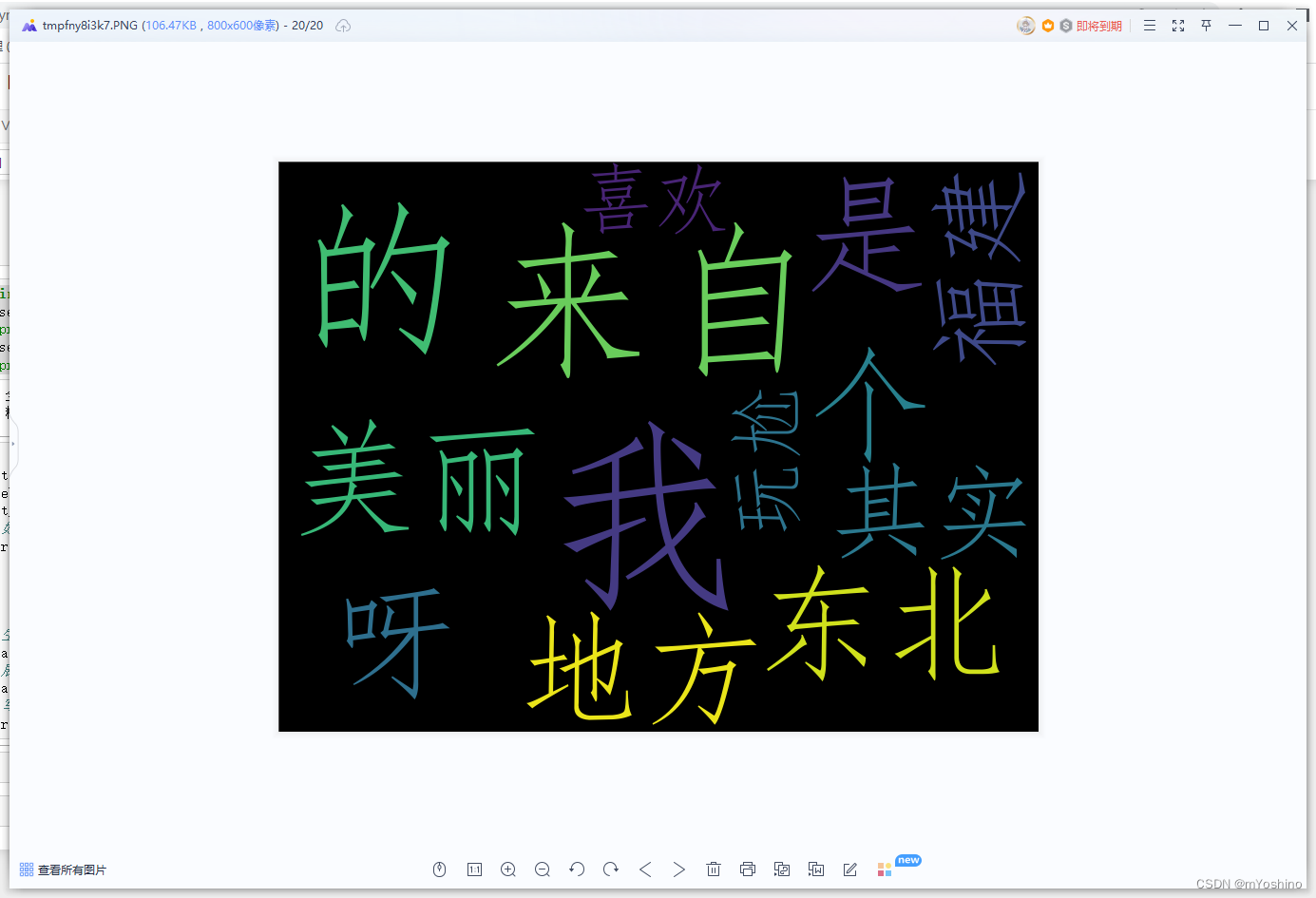
txt = '我来自东北呀,是个美丽的地方,其实我来自福建,我喜欢玩尬的'
jieba_list = jieba.cut(txt)
txt_list = " ".join(jieba_list)
# 如果数据文件中包含中文,那么font_path必须指定字体,否则中文会乱码
wordcloud = WordCloud(font_path = 'C:/Windows/Fonts/simfang.ttf',
collocations=False,background_color='black',
width=800,
height=600,
max_words=50).generate(txt_list)
# 生成图片
image = wordcloud.to_image()
# 展示图片
image.show()
# 写入文件
wordcloud.to_file('./jieba.jpg')
jieba.analyse
作用为提取关键字
- 第一个参数:待提取关键词的文本
- 第二个参数 topK:返回关键词的数量,重要性从高到低排序
- 第三个参数withWeight:是否同时返回每个关键词的权重
- 第四个参数allowPOS=():词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词,查看:jieba词性表.txt
import jieba
import jieba.analyse
text = '真的编不出什么话了,但是如果你认为本文有用的话请点赞吧,球球了,好的,非常感谢你,中国软件开发社区'
set_list = jieba.analyse.extract_tags(text,allowPOS=('n'))
print(str(set_list))
txt = " ".join(set_list)
# 如果数据文件中包含中文,那么font_path必须指定字体,否则中文会乱码
wordcloud = WordCloud(font_path = 'C:/Windows/Fonts/simfang.ttf',
collocations=False,background_color='black',
width=800,
height=600,
max_words=50).generate(txt) # 要求传入一段话
# 生成图片
image = wordcloud.to_image()
# 展示图片
image.show()
# 写入文件
wordcloud.to_file('./jieba.jpg')

报错解决
x.label调用出现TypeError: ‘str’ object is not callable
中文显示错误以及负号无法显示
考核
试用matplotlib绘制笛卡尔♥型曲线
笛卡尔♥型曲线
















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











