









原链接:https://medium.com/@julientregoat/working-with-octet-streams-in-javascript-d43d81ad7f47

如果你一直用JavaScript来处理文件的话,你应该见到过Uint8Array类型数组或者叫做ArrayBuffer的对象,它们经常被用来处理一个很大整数数组,这些整数的范围是从0到255。按照它的字面意思就可以知道,这些numbers是无符号的(也就是说都是非负数)8bit整数。
8bit的整型在计算的历史中占据着重要的地位。如果再往细了说的话,1bit——二进制数字——代表了我们在计算机中常用来计算的最小单元。它只有两个值,0或1。但是一个二进制的序列,就可以表示更大的数了。最开始,计算机使用不同长度的bit来对数据进行编码,这些变长的bit序列,一般被称为字节(bytes)。一个字节被用来对一个符号进行编码。因为bytes是能够使用的最小的bits单元,所以它是计算机中存储数据的核心。
最终,正如我们大家都知道的,8bit的字节成了行业的标准。即使是在现在,人们依然使用多个8bytes来处理数据。
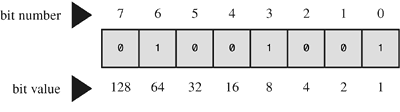
那为什么8bits的值是从0-255呢?n从0开始,第n个位置代表的值为2^n。在位置n上,如果是1的话,最后表示的数,应该加上2^n。你有可能在每个位置上都是1,这个时候,得到的结果为最大值255.
‘application/octet-stream’
回到MIME RFC 2046(Multipurpose Internet Mail Extensions——当时认为emails会成为人们交流的主要方式,AKA 1993,事实证明,技术的发展限制了这波人的想象力)。这个标准非常庞大——最开始这个标准是为邮箱设计的,它主要定义了我们传输数据的标准,当然这个标准我们现在仍然在用,就是我们所熟知的HTTP协议,还有其他的通信协议。我们发送和接收请求的所有头部信息,都是MIME标准下的产物。
这个标准能够让我们指定我们要发送什么内容,接收什么内容。从这个最开始用于邮件的标准,到现在互联网的多媒体文件传输,这个过程不是一蹴而就的。实际上,有些基础性的东西,我们现在还在探索和构建。
一般而言,我们会在’Content-Type’头上准确地标记数据类型。头上可以包含’image/png’,’audio/mp3’,’application/msword’还有’application/octet-stream’。哈哈哈,可能你从来没有听说过octet-stream是什么东东。
好吧好吧,我觉得,我卖关子卖的也够久的了,你也可能大概知道我在说什么东西了。Octet streams就是非常简单地由一系列的8bit整型数字组成。从上面讲过的内容,你可能也猜到了,所有的东西都是8bit组成的,也就是说所有的东西都可以通过Octet streams进行传输。也就是一些8bit的blocks。
然而,在MIME RFC 2046将octet streams描述为’arbitrary binary data’(任意的二进制数据)。这儿说到的意思是,计算机发送的和接收的数据,并不知道这些数据是什么(因为都是二进制的,一堆乱码)。不管怎样,你发送和接收的数据都是原始的二进制数组。
使用JavaScript传输文件
当刚开始在JavaScript中处理文件时,上面说的这些概念的确是非常抽象,实际上,有很多人在解释这些东西,但是又很少被解释清楚。
JavaScript中的FileReader对象,让web应用能够以异步方式读取存储在用户电脑文件中的内容(或者原始的二进制buffers),用File或Blob对象来指定文件或读取数据。[Mozilla FileReader Docs]
Mozilla比较厉害,它们的文档看了之后,没有让我犯过错!这些细节实现,我觉得Mozilla没有必要进行解释,但是吧,新手又对这些比较好奇(哪儿真的特别需要这个技术,这也是我为什么写这篇博客的原因)。
你如果允许用户上传文件,你大概用了表单中的<input type=”file />。然后返回一个File对象。但是,在HTTP请求中,你是不能传输一个File的,因为你并不知道接收这个文件的那一端用的是什么语言;另外,你用的是HTTP!在Internet(或者任何能够接收到请求的环境),你都只能传输一个有序的字符串(这个字符串如何排序,在’Content-Type’中由你指定)。发送一个文件过去,会导致出现奇怪的乱码结果,因为HTTP处理试着去理解你的File对象,并尝试将该对象转化为可读的string。那我们怎么传输文件呢?当然是将File中的内容转化为一般都能够理解的basic blocks(暂且把6bit byte的怪物放在一边)。
我们用FileReader对象来读取文件对象,之后会以8bit整型序列的方式给我们返回结果。一般,我们用FileReader.readAsArrayBuffer()方法能够得到一个ArrayBuffer对象,这个ArrayBuffer只是代表了这里面有一些数据,但是是什么格式的,不知道。为了能够用这个数据,我们需要一个’view’(视图)。你可能会想,这个’view’(视图),是不是前端里的那个’view’(视图),不过在我们的例子中,这个术语说的是类型化数组(typed array),也就是说,这是一系列的数据类型,包含开始的偏移,长度等信息。Mozilla说的一针见血:“A view provides context”。
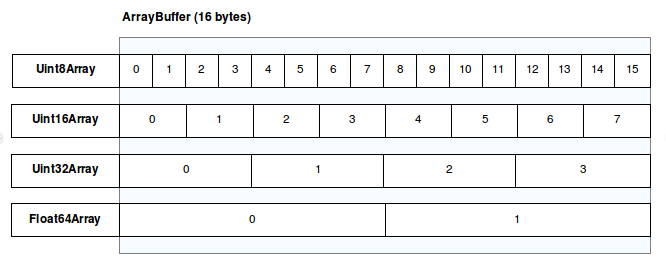
假设你的数据使用octets,使用new UInt8(yourArrayBuffer)来得到一个可变的结构。你可以用Node.js Buffer类来定义,这个类定义了丰富的API来处理数据。你可以将其转化为可读的流式数据(ReadableStream),这对大文件,还有一些不知道大小的文件,很有帮助。此外,你不需要对文件做太多的事情,你可以将这个ReadableStream作为HTTP请求进行发送,也可以直接接收下载,并转化(当然前提是你在’Content-Type’头中指定好了文件类型)。
参考:
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Typed_arrays
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer














 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









