







批量安装 Python 库
批量安装 Python 库的脚本:提高数据分析效率的一步(附源码)
在现代数据分析领域,Python 已成为一个不可或缺的工具。为了进行数据处理、分析、可视化和建模等任务,Python 社区涌现出了众多强大的库和工具。然而,频繁安装这些库可能会变得繁琐,耗费时间和精力。在本文中,我将分享一个简单而强大的方法,以便一次性批量安装多个 Python 库,从而在数据分析工作中提高效率。
批量安装脚本前提条件
在运行批量安装脚本之前,确保您已经满足以下前提条件:
-
Python 和 pip 安装:请确保您已经正确地安装了 Python 和 pip 包管理工具。您可以在命令行中运行
python --version和pip --version来验证它们的存在。 -
路径配置:确保 Python 和 pip 的可执行文件所在的路径已经正确地添加到系统环境变量中,这样您可以在命令行中直接运行它们。
使用 pip:Python 包管理工具
pip 是 Python 社区广泛使用的包管理工具,它使我们能够轻松安装、升级和管理各种 Python 库。通常,我们会单独使用 pip install 命令来安装单个库,但当我们需要同时安装多个库时,可以通过一个脚本批量处理。
批量安装脚本
以下是一个用于批量安装多个 Python 库的脚本,它使用了 Python 的 os 模块来在命令行中执行 pip install 命令,并通过指定清华大学镜像源来加速下载过程:
import os
required_libraries = [
'numpy', 'pandas', 'matplotlib', 'seaborn', # 数据处理和可视化
'scipy', 'statsmodels', 'scikit-learn', 'xgboost', 'lightgbm', # 数据分析和机器学习
'tensorflow', 'keras', 'pytorch', 'fastai', # 深度学习框架
'beautifulsoup4', 'requests', 'selenium', # 网络数据获取和处理
'jupyter', 'spyder', 'vscode', # 开发环境
'sqlalchemy', 'pymysql', 'psycopg2', 'sqlite', # 数据库连接和操作
'openpyxl', 'xlrd', 'xlwt', 'pandasql', # Excel 和 SQL 数据操作
'pyodbc', 'pandas-profiling', 'missingno', # 数据质量分析和处理
'plotly', 'dash', 'cufflinks', # 交互式数据可视化
'geopandas', 'folium', # 地理数据分析和可视化
'nltk', 'spaCy', 'gensim', # 文本处理和自然语言处理
'networkx', 'igraph', # 图论和网络分析
'statspy', 'pingouin', # 统计分析
'pandasgui', 'dtale', # 数据分析 GUI 工具
'auto_ml', 'tpot', # 自动化机器学习
'vaex', 'dask', # 大数据集处理
'yellowbrick', 'shap', # 可视化模型解释
'sympy', 'quantstats', # 数学和金融分析
'tabulate', 'pandas-flavor', # 数据转换和操作
'arrow', 'zope.interface', # 日期和时间处理
'cryptography', 'paramiko', # 加密和远程连接
]
for i in required_libraries:
code = f"pip install {i} -i https://pypi.tuna.tsinghua.edu.cn/simple" # 可根据自己需求自行变更本行代码,本质就是cmd中输入的内容
os.system('cmd /c "{}"'.format(code))
print('\n')
print(f'==================================')
print(f'============{i}已经安装============')
print(f'==================================')
print('\n')
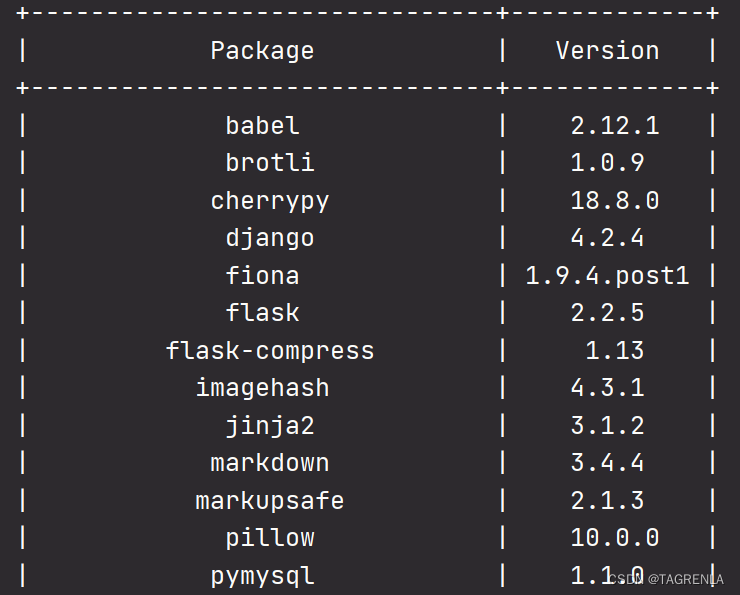
查看当前python解释器中安装的所有的库
import pkg_resources
from prettytable import PrettyTable
installed_packages = pkg_resources.working_set
table = PrettyTable(["Package", "Version"])
for package in installed_packages:
table.add_row([package.key, package.version])
print(table)
上述代码会显示当前 Python 解释器所使用的环境中安装的所有库及其版本。这包括在当前虚拟环境或系统范围内安装的所有库。这将输出当前 Python 解释器所使用的环境中所有已安装的库的列表。如果你在特定的虚拟环境中运行这段代码,它将显示该虚拟环境中的库列表。如果你在全局环境中运行它,它将显示全局 Python 环境中的库列表。















 4335
4335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











