







系列文章目录
文章目录
前言
前几天我们初步了解了函数,接下来我们再来认识下函数的嵌套调用和链式访问、函数的声明和定义和函数递归等。
1.开胃菜(一道练习)
二分查找法(折半查找法)
题目 写一个函数,实现一个整形有序数组的二分查找
常规做法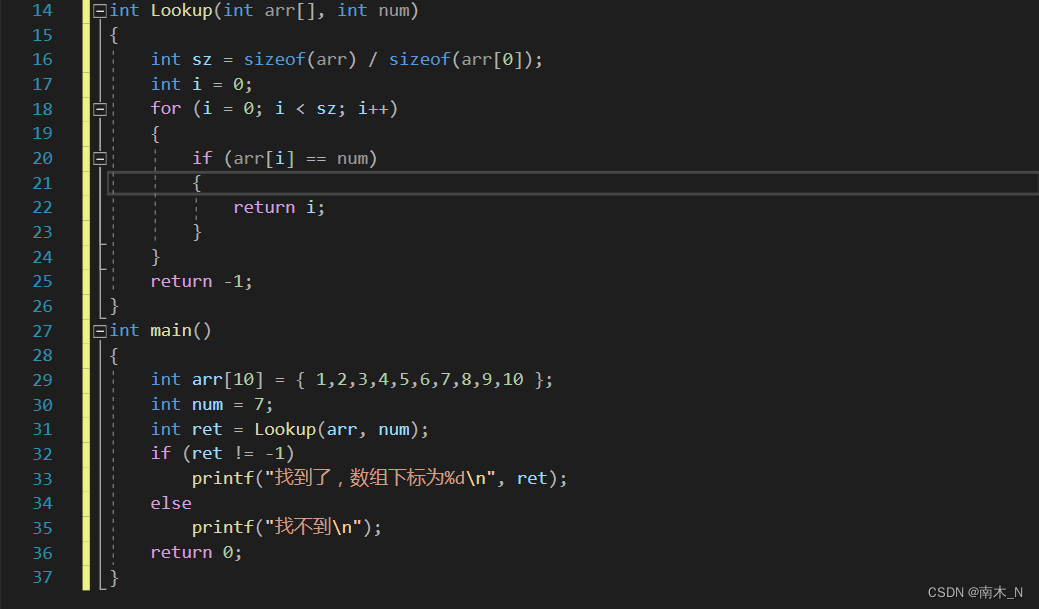
- 在一个数组中查找某个数,找到返回这个数的下标,找不到返回-1。不返回0,是因为0可以是下标。
- 把一个要查找的数和一个数组传给函数,在函数内用一个循环来查找。
- 但这种做法效率太低了,如果我们要查找10或更大的数,那我们就得循环10次。在100或者10000个数查找,我们就得查找更多的次数,那有什么办法可以减少查找次数,提高效率?
二分查找法解题思路
-
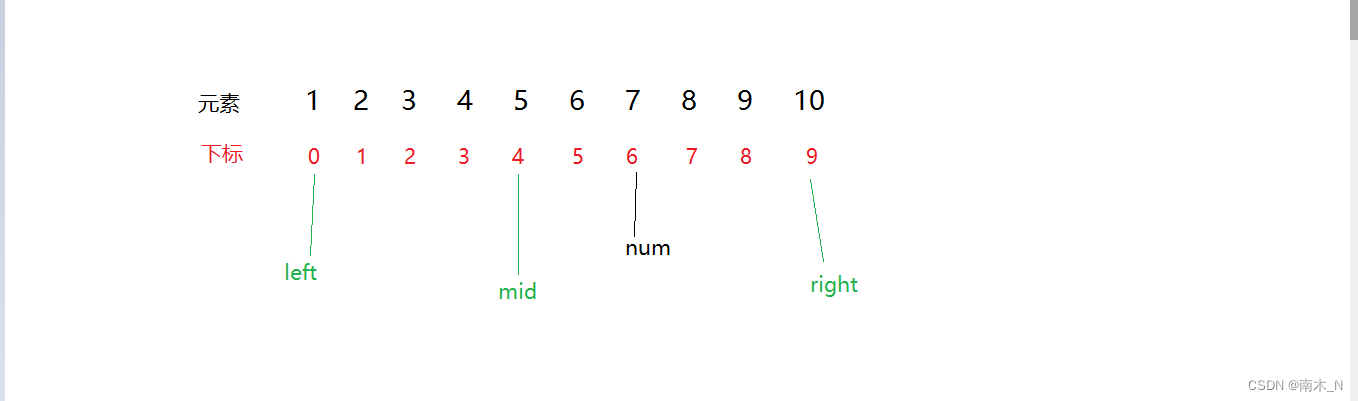
我们可以从数组中间对要查找的数进行比较,因为这个数组是有序数组。
-
因为我们要访问中间元素就得知道中间元素下标,所以得先确定下标。我们将数组第一个元素下标定义为left,最后一个元素下标定义为right,中间元素下标定义为mid。
-
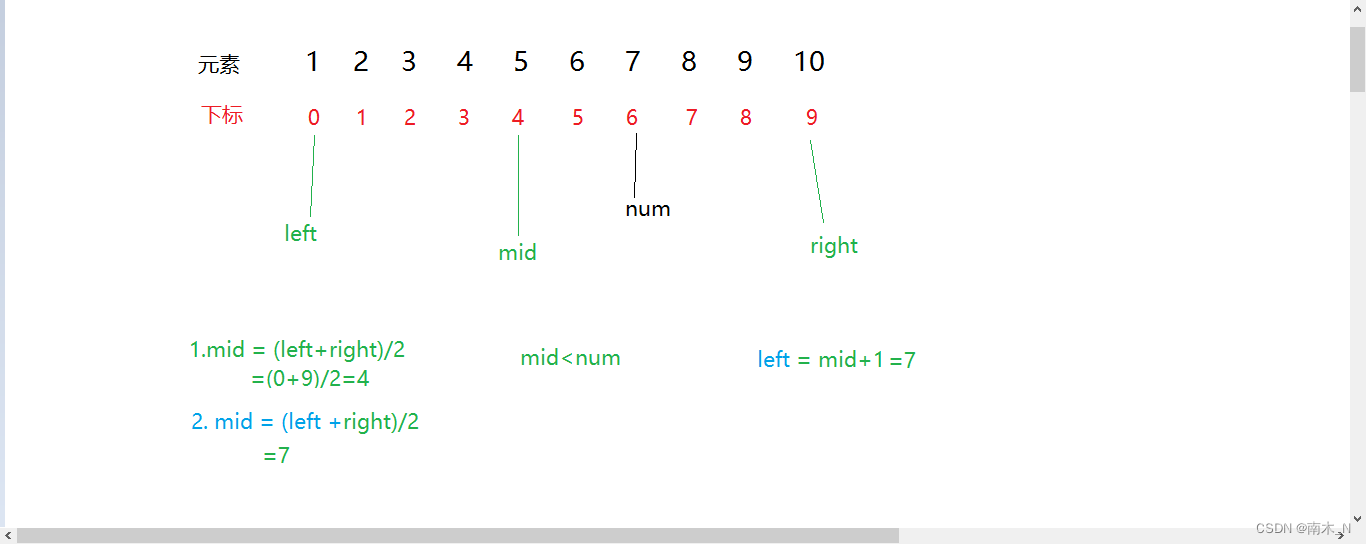
比较mid与要查找的数的大小。如果比mid大,那么mid及mid左边的数就可以全部淘汰掉,同时把left移到mid的下一位,right保持不变。如果比mid小,就把mid及右边的数全部淘汰掉,把right移到mid的前一位,left保持不变。
-
再比较mid与num的大小,重复以上操作。
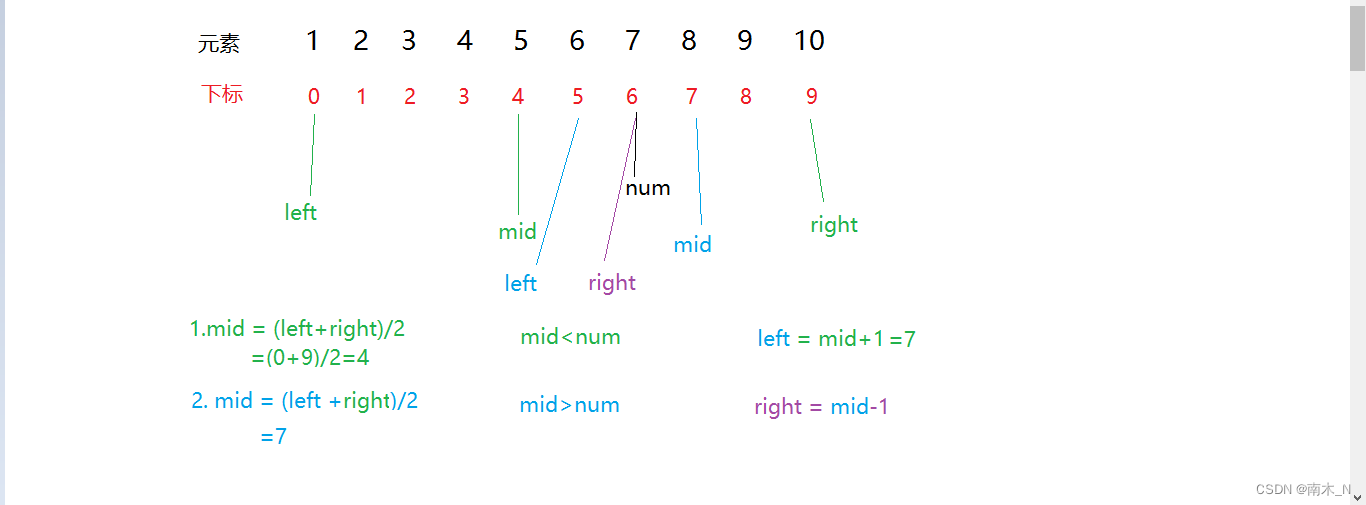
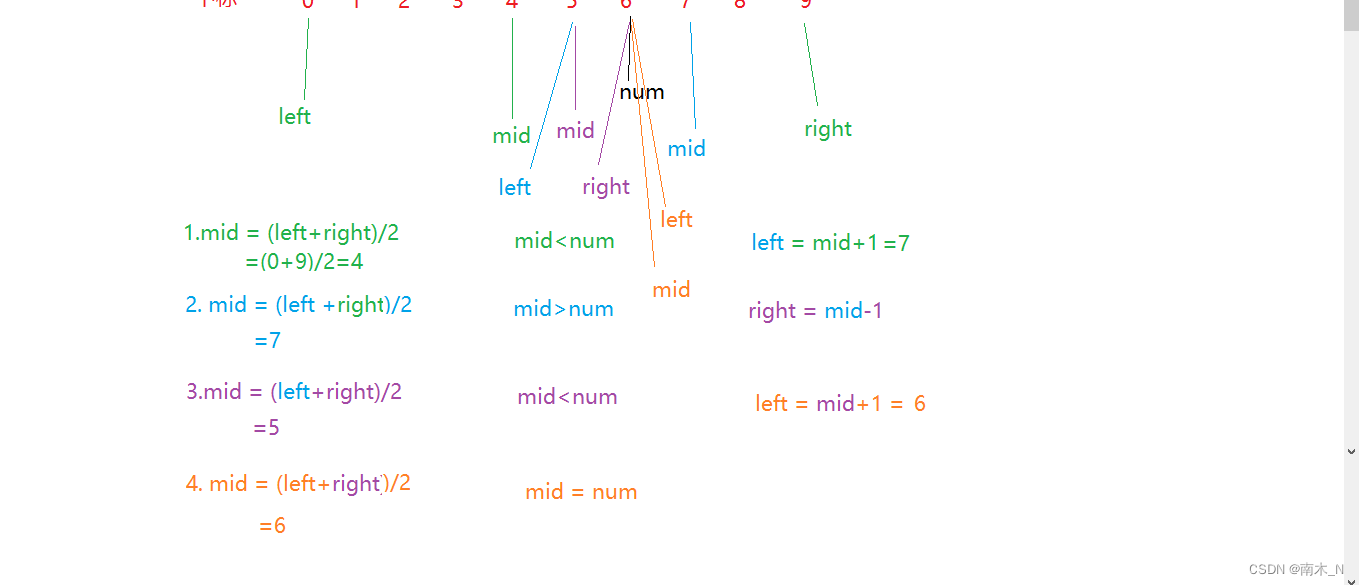
5. 最终我们在四次查找后找到我们想要的值。效率比之前提升了一半,所以叫二分查找法。
二分查找法代码实现
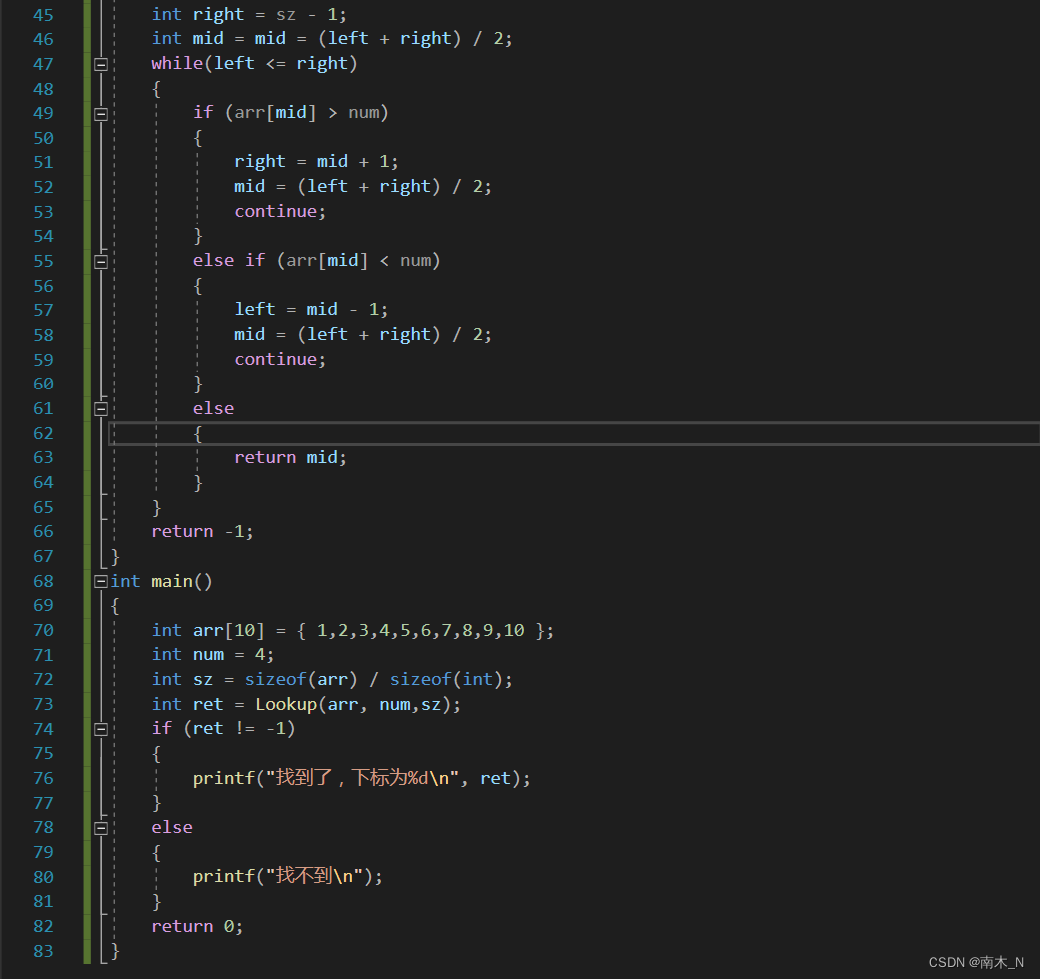
这里有几个细节:
- 用sizeof计算数组元素个数,但只能在主函数计算,为什么?
我们在调用的函数内计算数组,这个数组是主函数传过去的,函数接收数组时可能认定其为指针,而不是整个数组,这样就会导致误差。- 记得不要把数组下标和数组元素弄混了。
2.上节知识点补充
- 函数返回类型不写,默认返回int类型
- 函数返回类型不写,返回最后一条语句的返回值
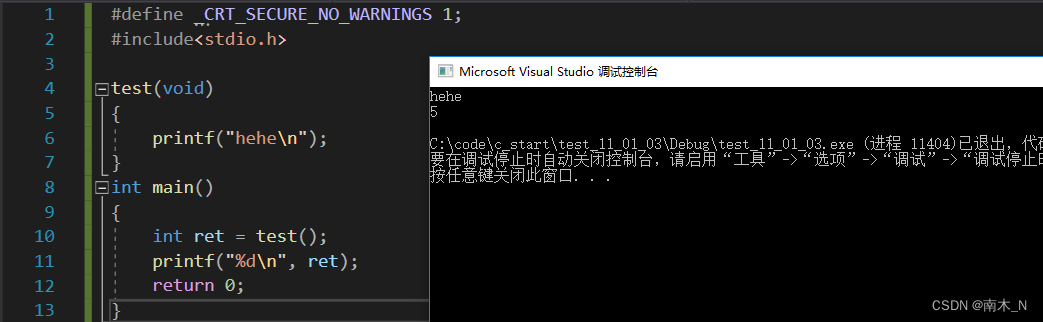
printf返回打印字符的个数,即hehe\n,一共五个字符,\n算一个转义字符。
3.函数的嵌套调用和链式访问
3.1嵌套调用
嵌套调用就是在一个函数内调用另一个函数。
例子
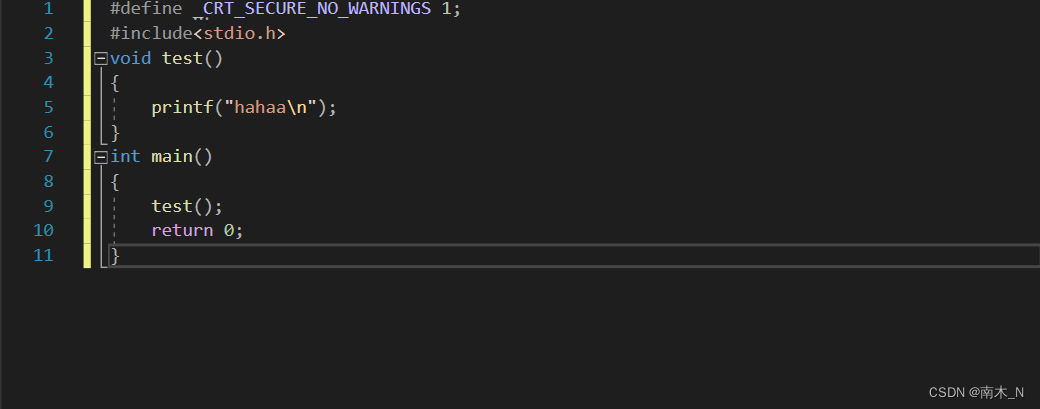
在主函数的调用test函数就是嵌套调用。
注意函数可以嵌套调用,但不能嵌套定义,简单讲就是在函数内定义另一个函数,我们在接下来会讲到。
3.2链式访问
链式访问就是把一个函数的返回值作为另一个函数的参数。
例子
int Max(int x,int y)
{
return x>y?x:y;
}
int main()
{
int a = 1;
int b = 2;
printf("%d\n",Max(a,b));
return 0;
}
函数Max把它的返回值作为printf函数的参数。
有趣的例子
printf("%d\n",printf("%d",printf("%d",43)));
你们觉得这个例子的输出结果是什么?答案是4321。
- 从外面对printf进行打印不行,只能从里面的printf进行打印,所以先打印43。
- 因为他是链式访问,就把最里面的printf的返回值作为参数,printf打印完43后,返回打印到屏幕的字符个数(注:数字也是字符),即返回2,作为第二个printf的参数,所以打印2。
- 接着把第二个printf打印到屏幕的字符个数返回给最外层的printf,返回1作为第一个printf的参数,所以最外层的printf就打印1。
4.函数的声明和定义
4.1函数声明
函数的声明是告诉编译器这个函数叫什么,参数是什么,返回类型是什么。但具体存不存在,函数声明决定不了。
例如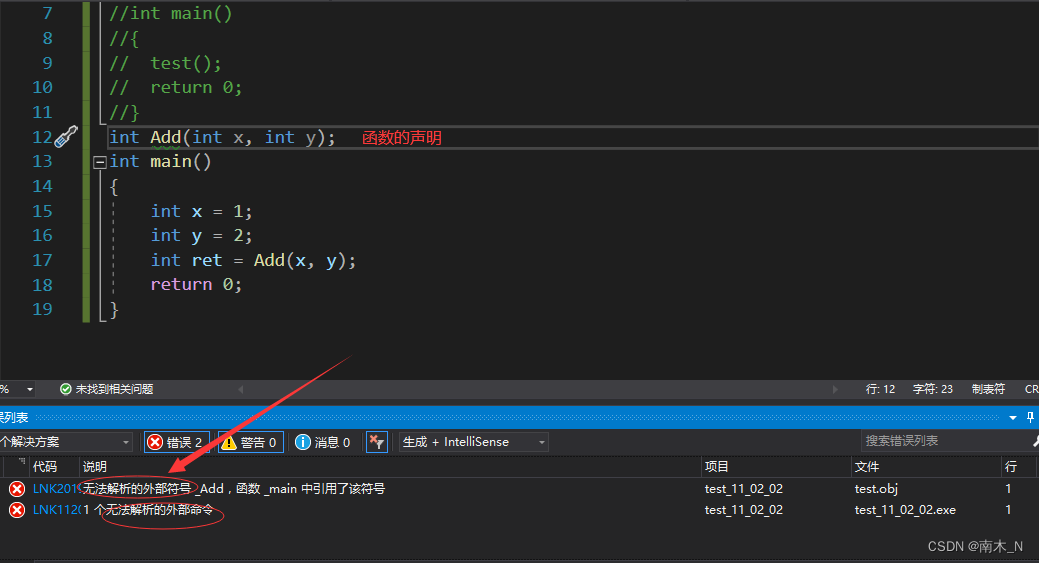
4.2函数定义
函数的定义是指函数的具体实现,交代函数的功能实现。
例如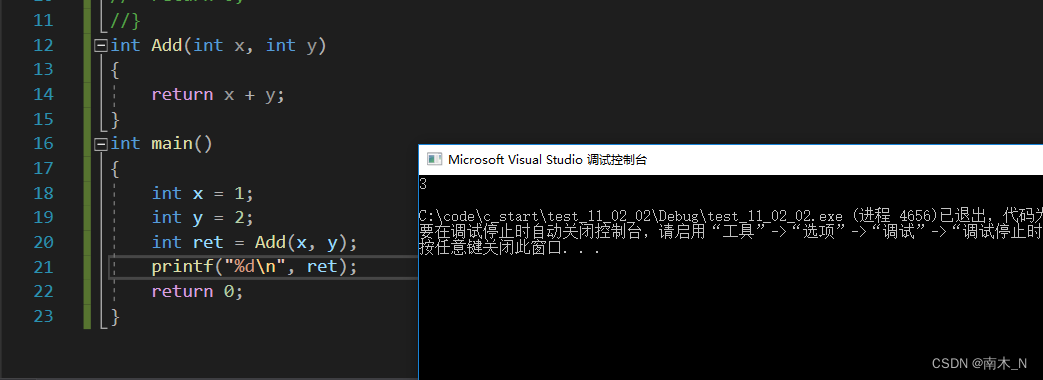
函数定义不同于函数的声明的地方就是它有一个代码块,交代函数的作用。
有人肯定就会问为什么没有函数的声明,只有函数的定义?其实函数的声明放在主函数前就是函数的声明,不然写两遍不显得很冗余。
但我为什么说放在主函数前面?看下面这个例子。
例子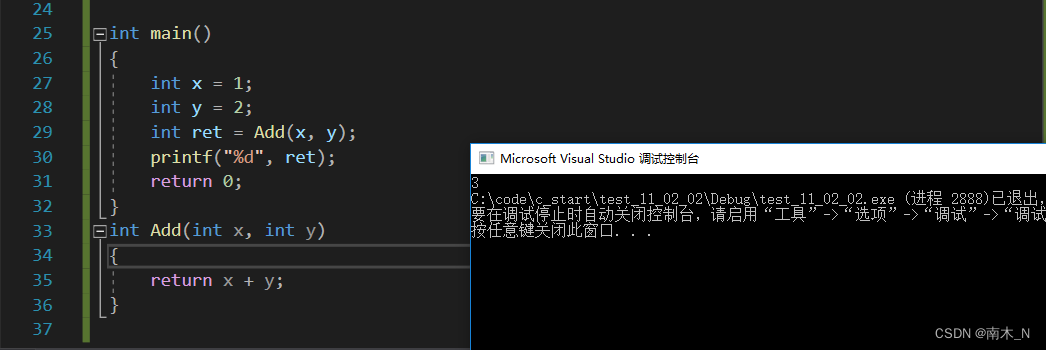
- 很遗憾,我以为会报错。其实编译器是从上到下进行扫描的,在主函数中发现你调用了Add函数,但你没有交代函数的功能,所以就会先报错,即使你在主函数后面补上定义也早已先报错了。
- 但有的编译器就不会,所以为了提高代码的可移植性,我建议大家就是把函数的定义写在你要调用它之前。
- 函数一定要先声明再使用
4.3真正的函数声明和定义
函数一般在头文件中声明,在源文件中定义。
例如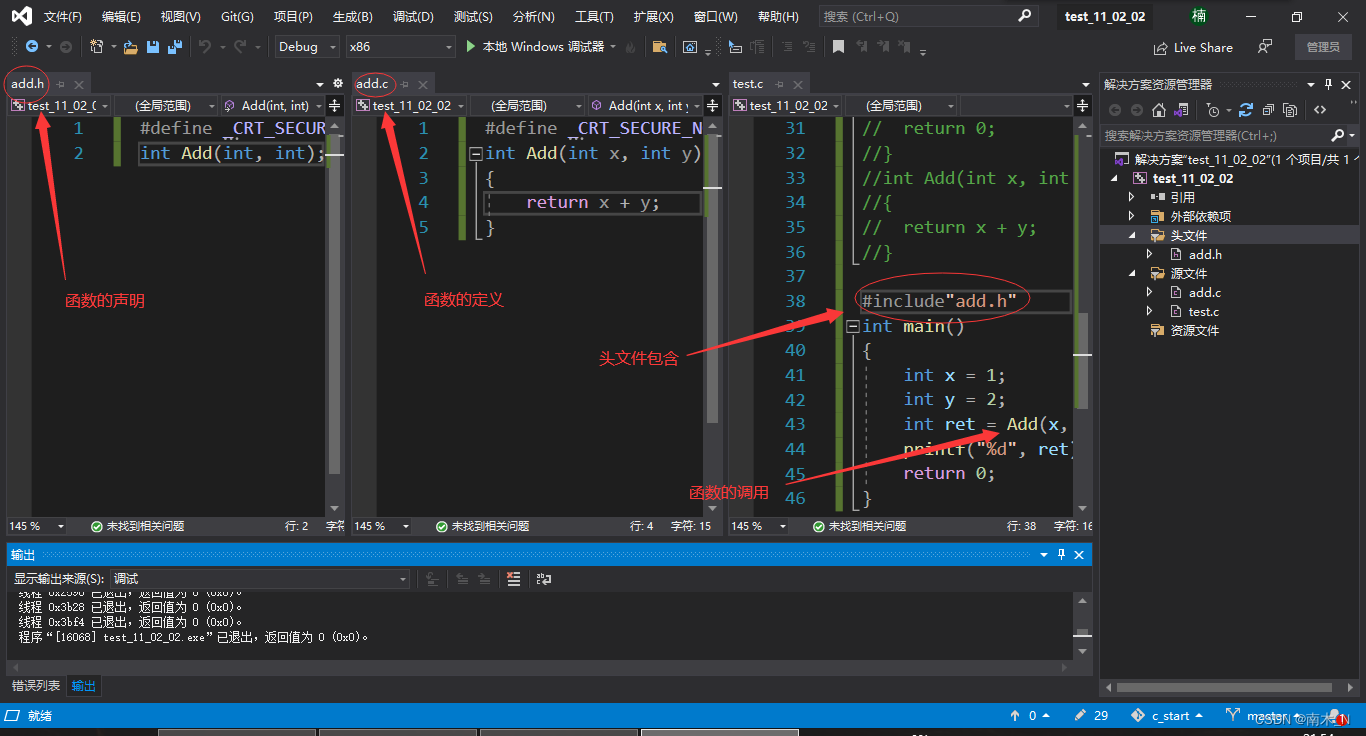
- add.h和add.c叫做一个模块,因为它的功能是加法,所以我们叫它为加法模块,test.c叫做测试模块,我们主要在这个源文件进行测试。
- 我们使用库函数都得包含头文件,那使用自己的函数也得包含头文件,因为是自己创建的,所以得用引号(”“),包含头文件后编译器就会连接两个模块。
- 在一个文件中就可以完成的工作为什么要拆成不同的文件。理由有二:
一就是有利于模块化开发,我们把一个程序分为几个模块(.h和.c),可以提高模块的质量(一个程序员负责一个模块)和效率。
例如制作一个计算器程序,我们可以把加法、减法、除法和乘法分文4个模块,交给4个程序员去完成,遇到问题时也能找出是谁的原因。如果只在一个源文件中写代码就不能同时写,而且还有可以出现冲突。.
二是代码的隐藏。当你想把一个文件卖给一个厂商时,你不想要你的源码被看到,这时你就可以把文件置为静态库(.lib),变成二进制,这样双方都看不懂了,就可以卖给厂商了。或你也可以把头文件卖了,因为里面只是函数的声明,商家也不知道函数具体是怎么实现的,他只需导入静态库,就可以使用你的代码了。
4.4拓展:变量的声明和定义
- 在使用全局变量时,我们需要在先声明再定义
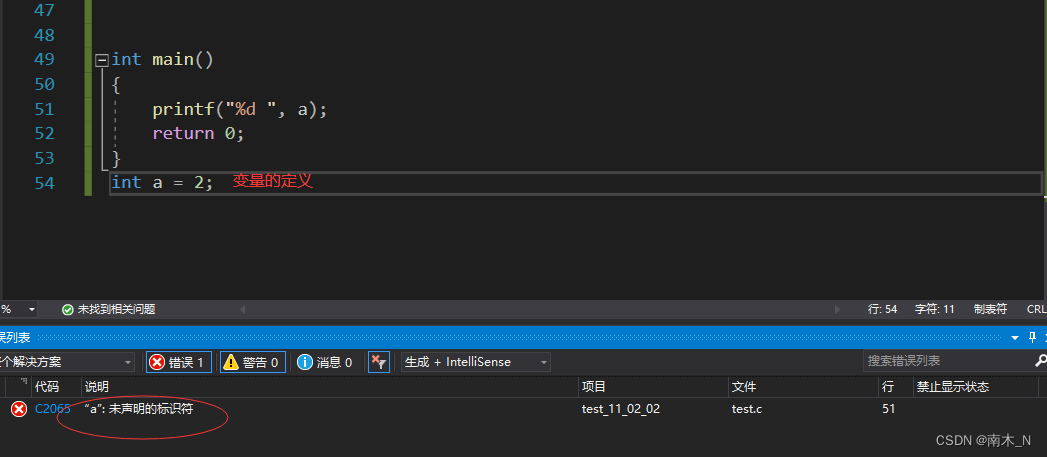
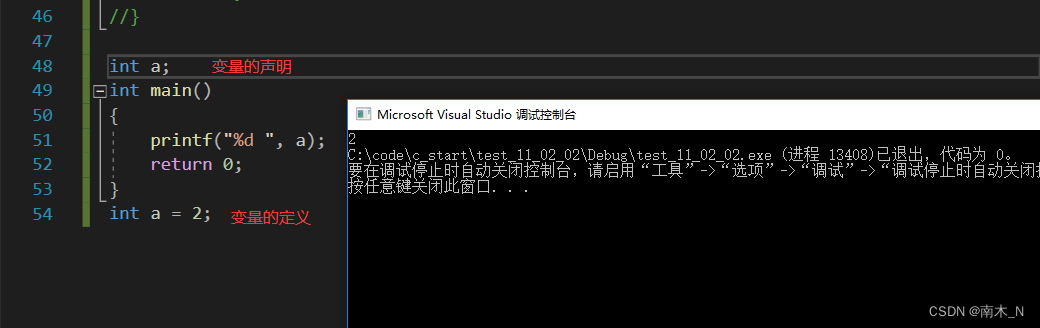
- 变量的声明类似于函数的声明,都是没有具体内容的,也就是说变量的声明是不赋值的。
- 全局变量只声明不定义时,全局变量默认初始化为0。
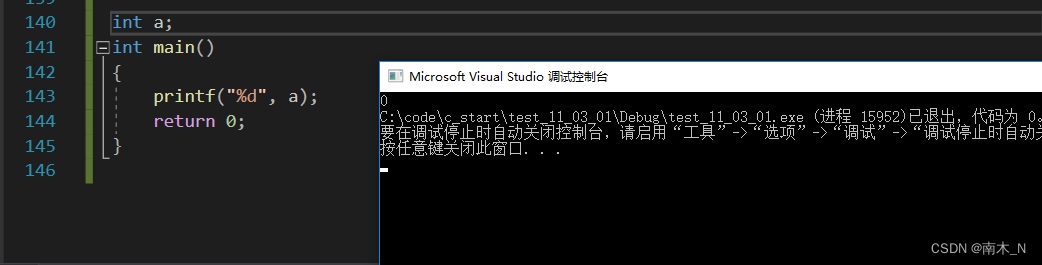
5.函数递归
定义程序调用自身的编程技巧称为递归( recursion)。
应用递归做为一种算法在程序设计语言中广泛应用。 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解。
作用递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。
特点大事化小。
简单讲递归就是不断调用自己,类似于循环
例1
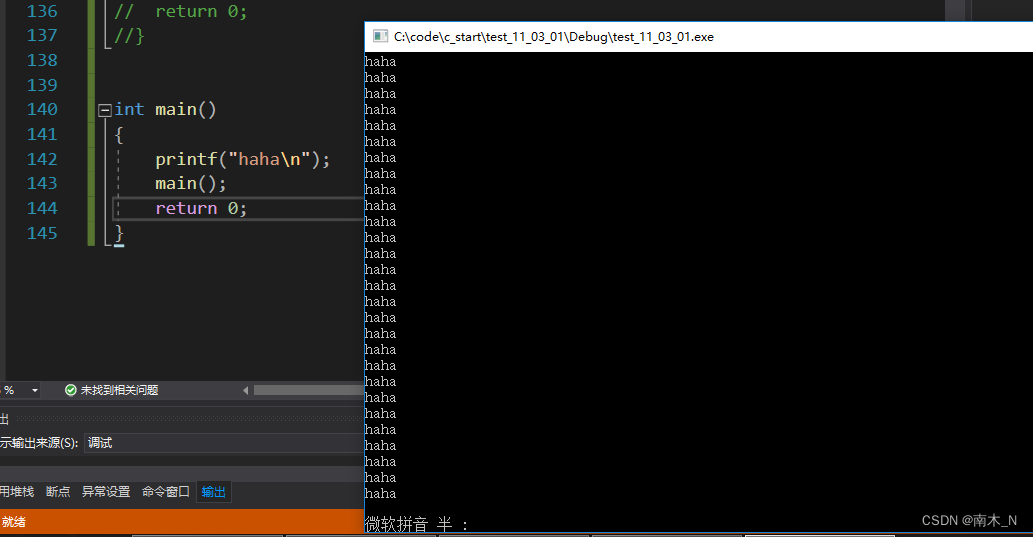
这就是一个递归。main自己调用自己,但最终陷入死循环。
栈溢出
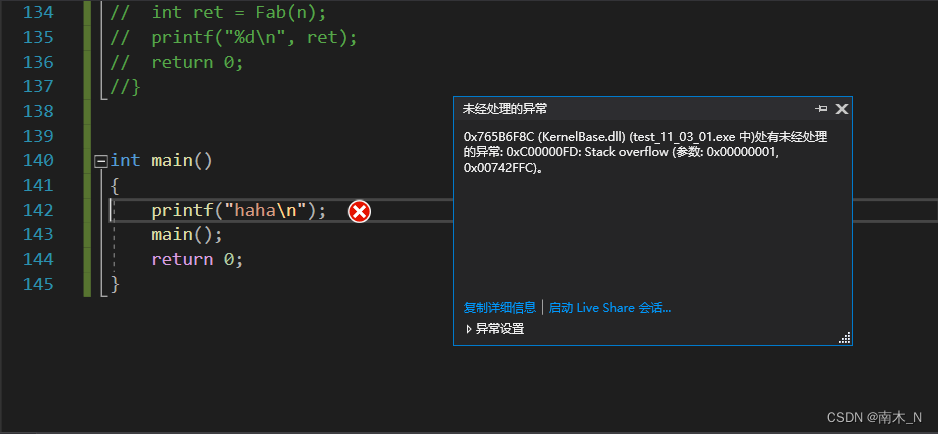
什么是栈溢出?系统分配给程序的栈空间是有限的,但是如果出现了死循环,或者(死递归),这样有可能导致一直开辟栈空间,最终产生栈空间耗尽的情况,这样的现象我们称为栈溢出。
简单讲就是内存不足。
由函数栈帧的创建和销毁(下节博客会讲到)可知,我们可以知道每一次调用函数,都会为本次函数在内存的栈区开辟一块内存空间,而开辟太多就会把栈区用完。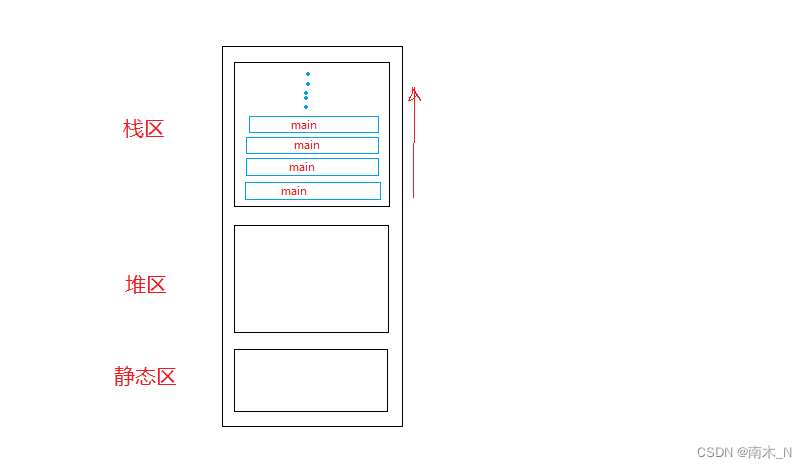
那该如何解决这个问题?
递归的条件
递归有两个条件:
- 存在限制条件,当满足这个限制条件的时候,递归便不再继续。
- 每次递归调用之后越来越接近这个限制条件。
例2
输入一个整形,输出整形的每一位,要求顺序输出。
例如输入1234,输出1 2 3 4。
常规做法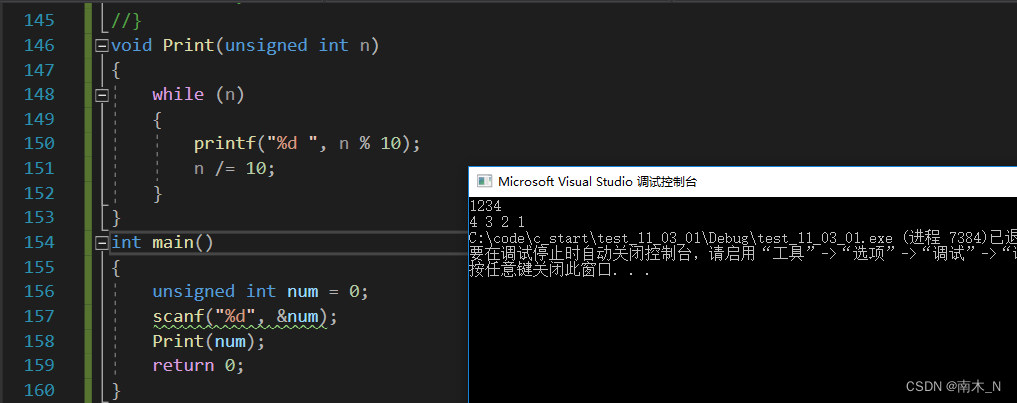
但没顺序输出。我们可以试试递归。
递归
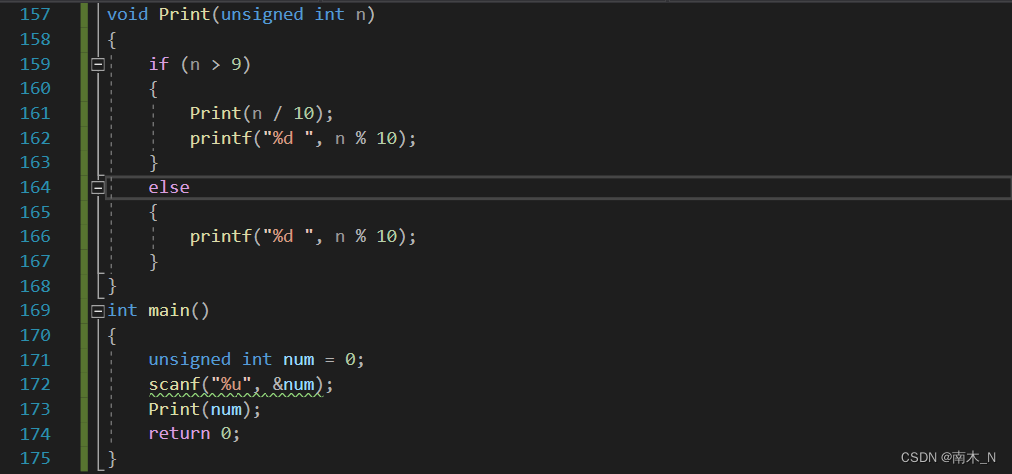
if是递归的判断条件,而调用函数中n的不断减小则是不断逼近限制条件。
接下来我们来画图分析下
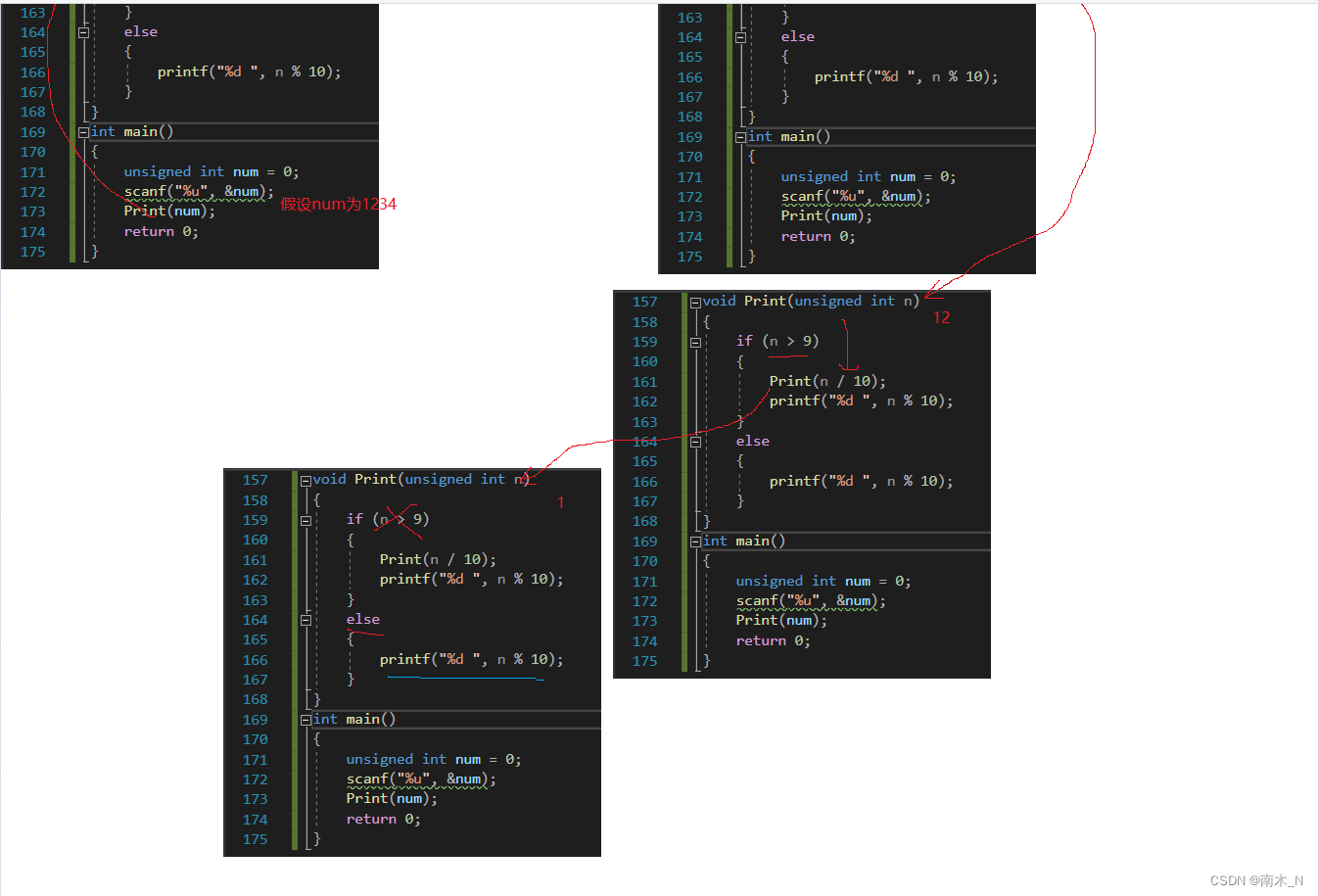
红色是递归调用函数的路径,当n<9时,函数开始回归。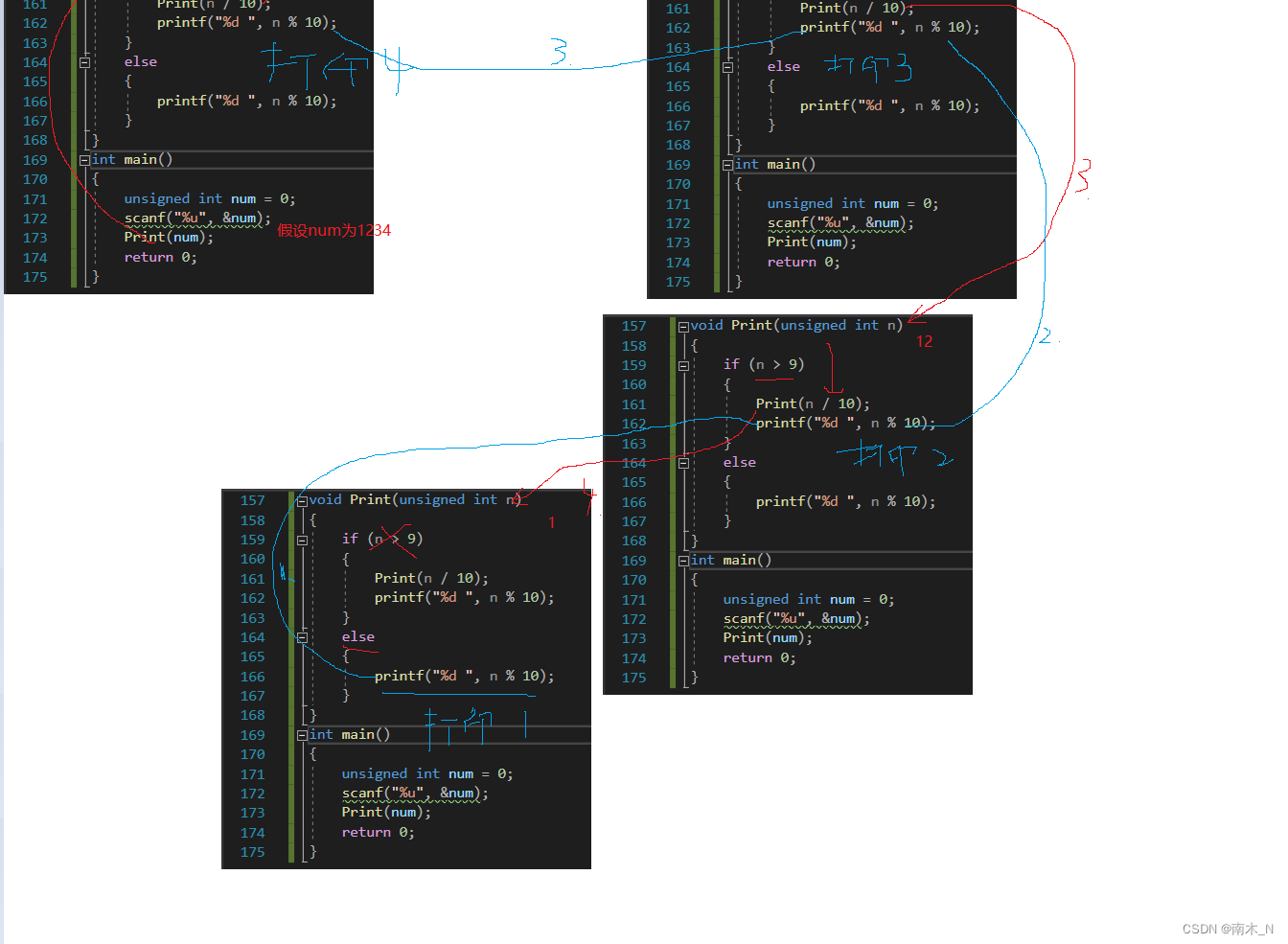
蓝色是递归回归的路径。
如果还不能理解,那就记得递归的本质就是大事化小,如图。
一步一步往下分,直到逼近限制条件。
例3写一个递归函数,求字符串的长度,返回字符串的长度,不能创建临时变量。
抛开最后一句,我们先用常规做法。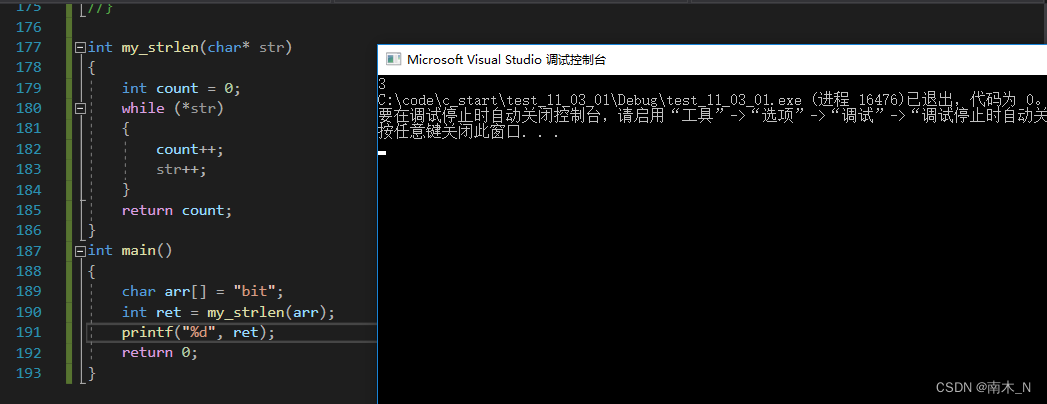
虽然有效,但题目要求不能创建临时变量,我们已经创建了count,那该如何修改,这就用到递归的知识。
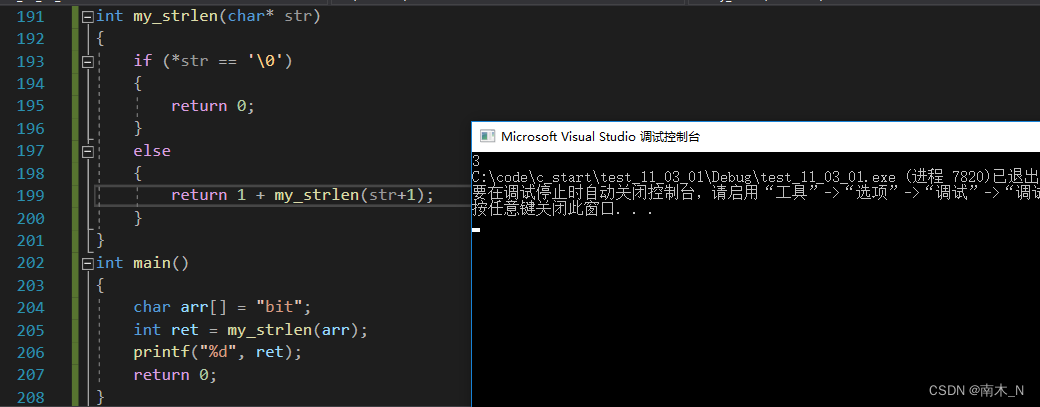
递归
首先,我们要想到递归的两个条件,一是限制条件,二是靠近限制条件。
这道题要求求字符串的长度,求字符串长度的结束标志是什么?是\0。就是说当计算到\0时,递归就停止,开始返回。如图。
具体代码
画图分析
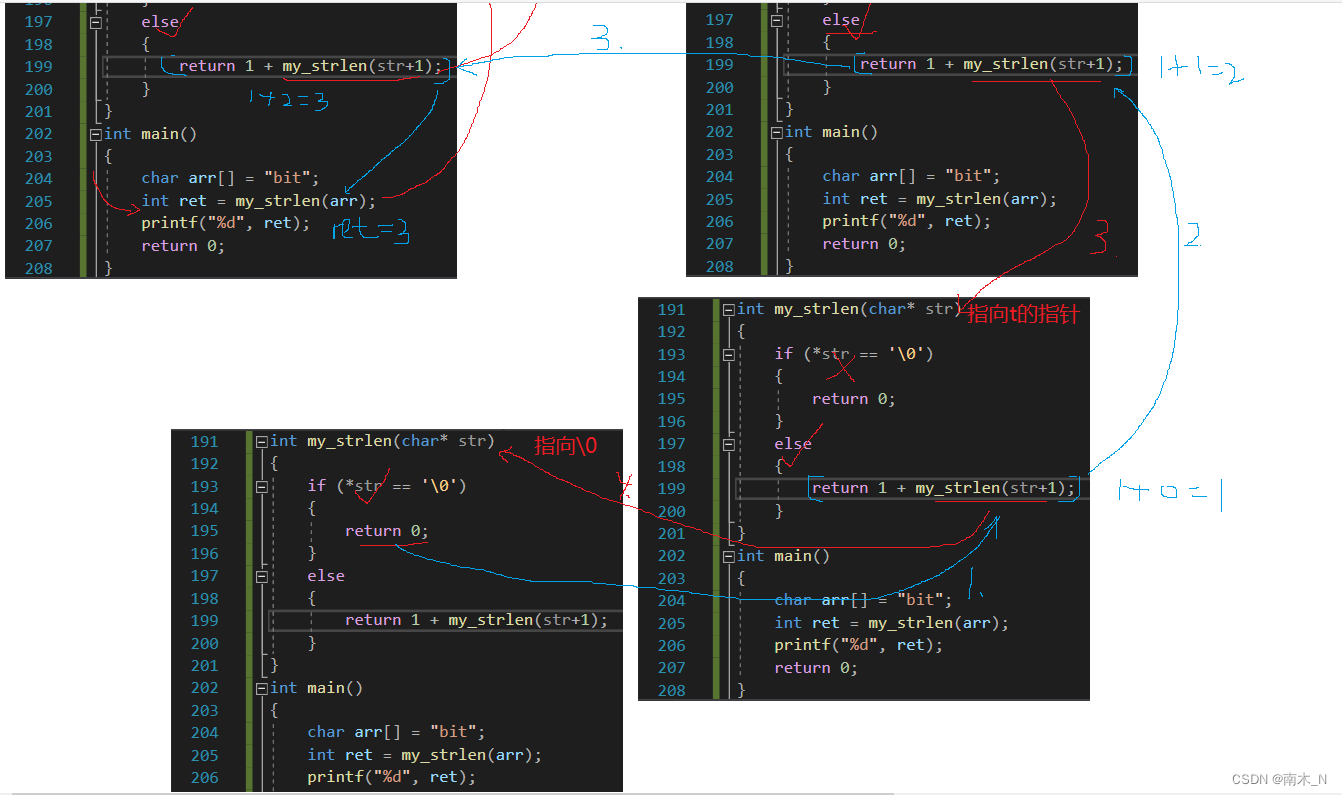
同样,红色是递归调用,蓝色是递归返回。
注递归很难,第一次看肯定看不懂,只有多做题,才能慢慢理解。
6.递归与迭代
例1求n的阶乘n!。
- 递归做法
限制条件是当n=1时,返回1。
思路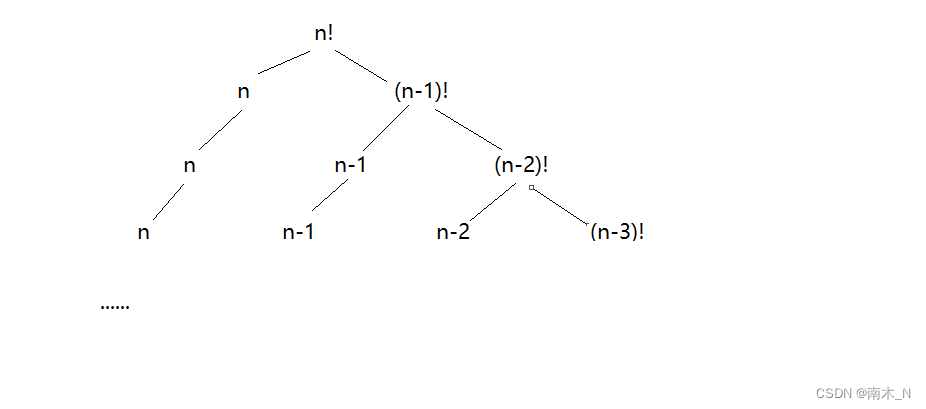
代码实现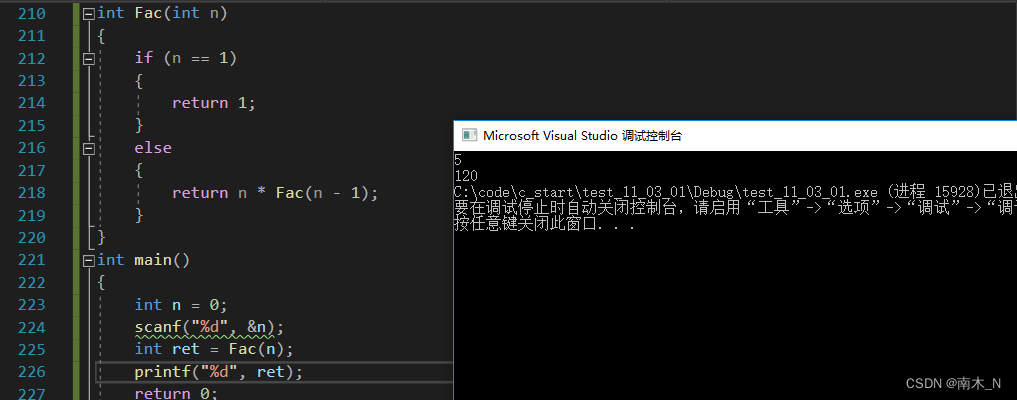
画图分析
递归的调用路径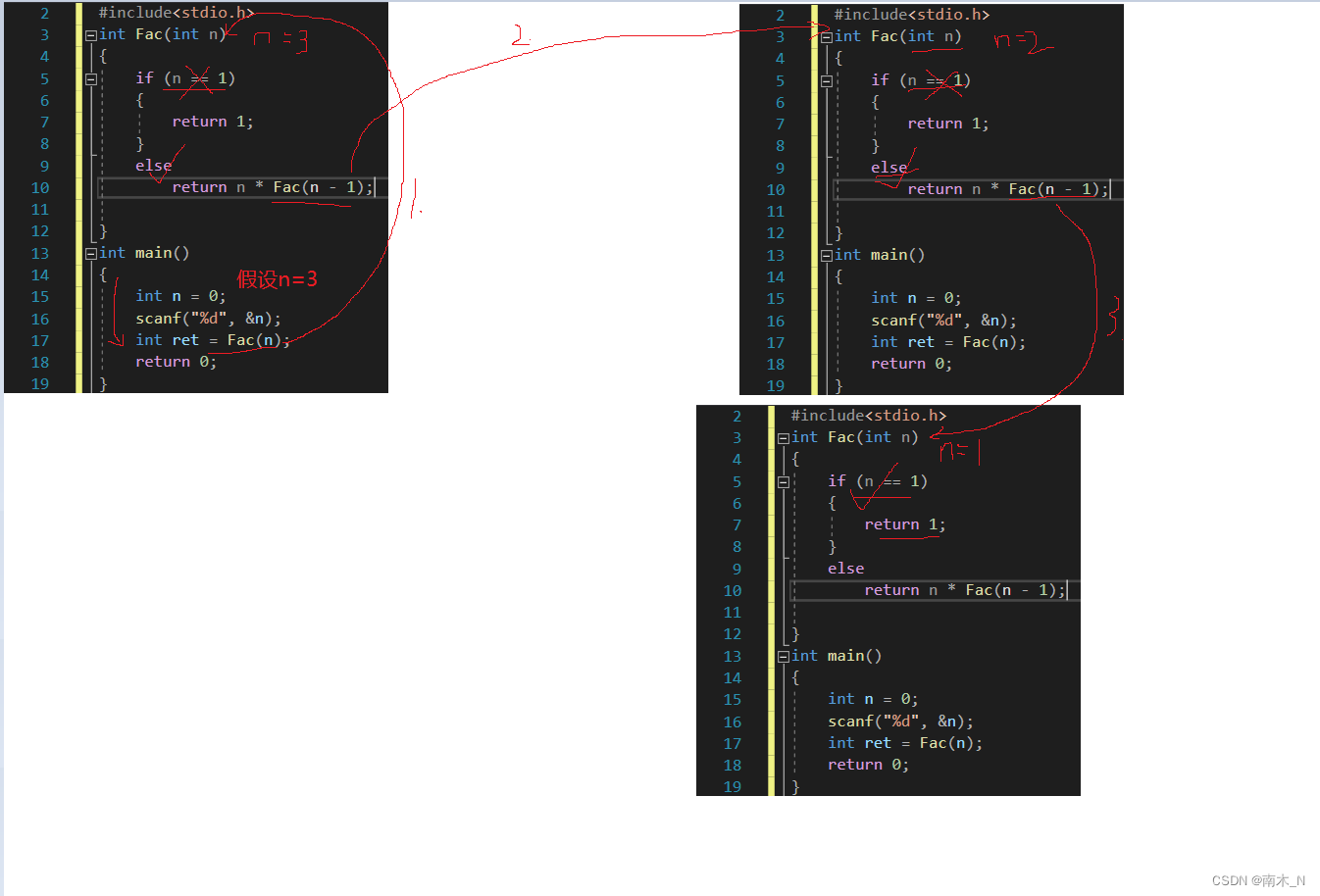
递归返回路径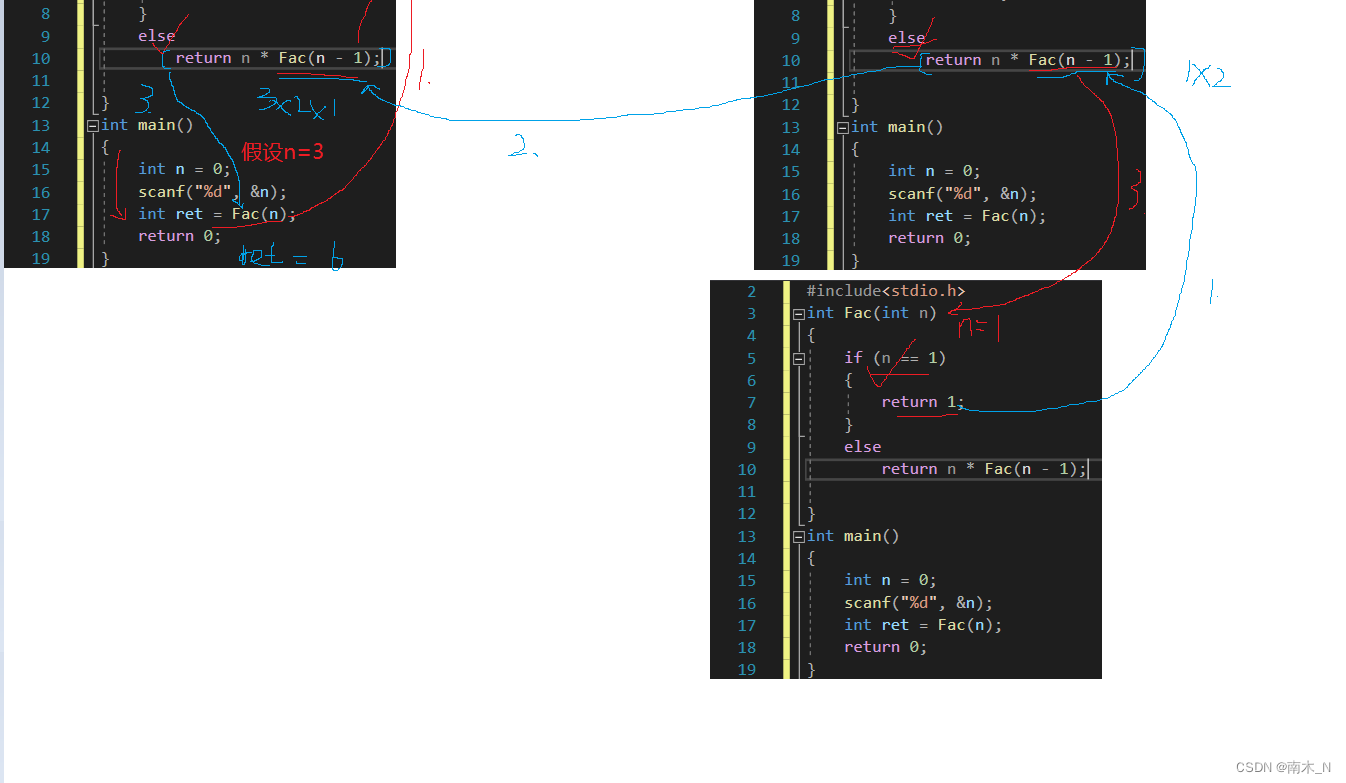
- 迭代(循环)做法
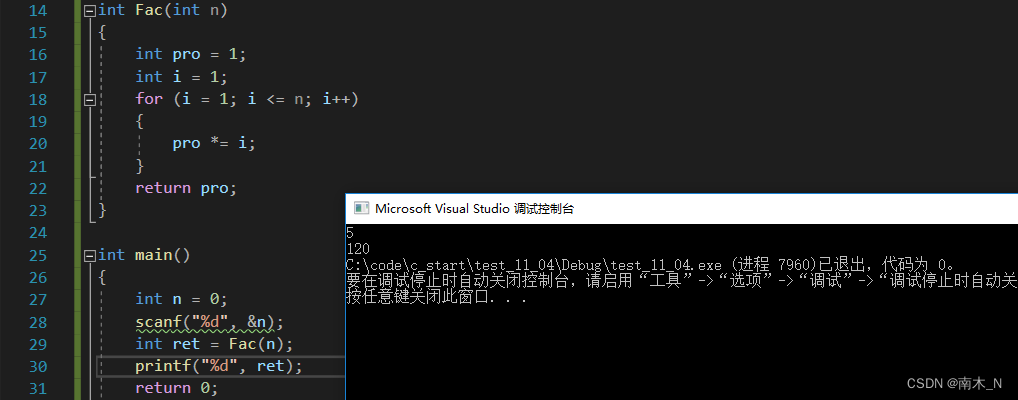
当n的值过大时(如10000),递归会出现栈溢出,循环会因为pro存储不下返回0。
例2求第n个斐波那契数(用函数Fib表示)
斐波那契数:1,1,2,3,5,8,13,21,34,55,……。从第三项起,每一项等于前两项的和。
- 递归
限制条件:当n<=2时,返回1。
思路
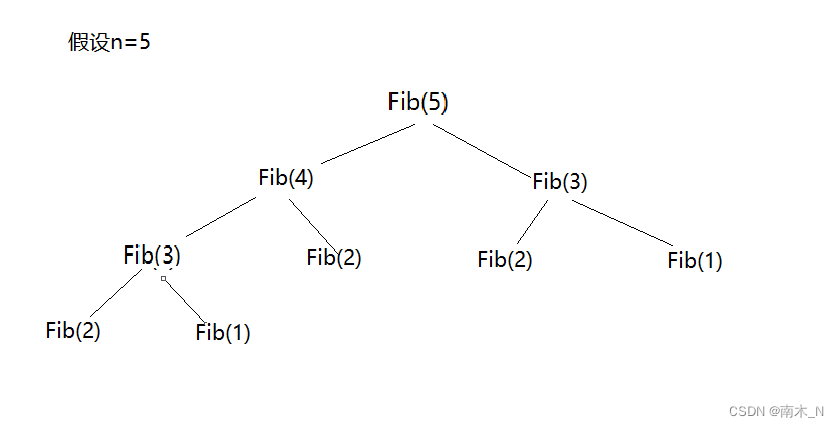
代码实现
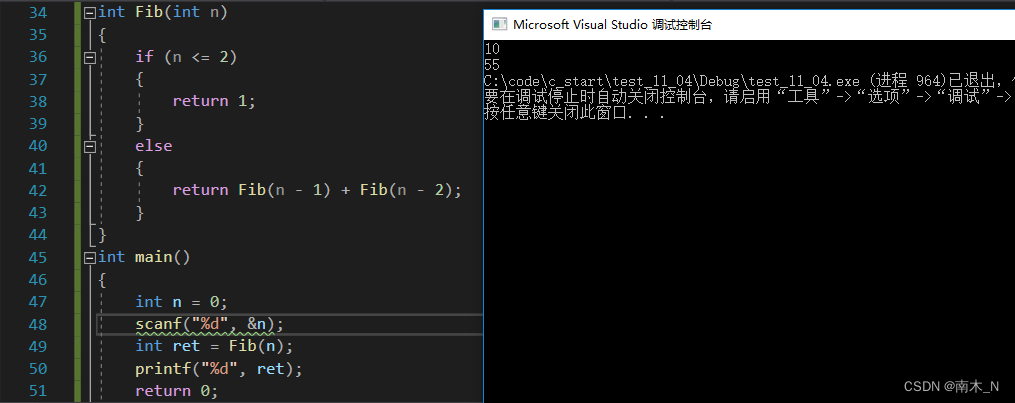
递归虽然很容易实现,只用寥寥几行代码就可以实现阶乘,但我们发现里面会有很多重复的计算,并且当递归层次过深时,它的执行时间会很长,执行效率会很低。
当n=50时,你会发现它被计算了几分钟,因为里面有大量重复的计算。我们可以看看当n=20和n=40时,Fib(2)被计算了多少次。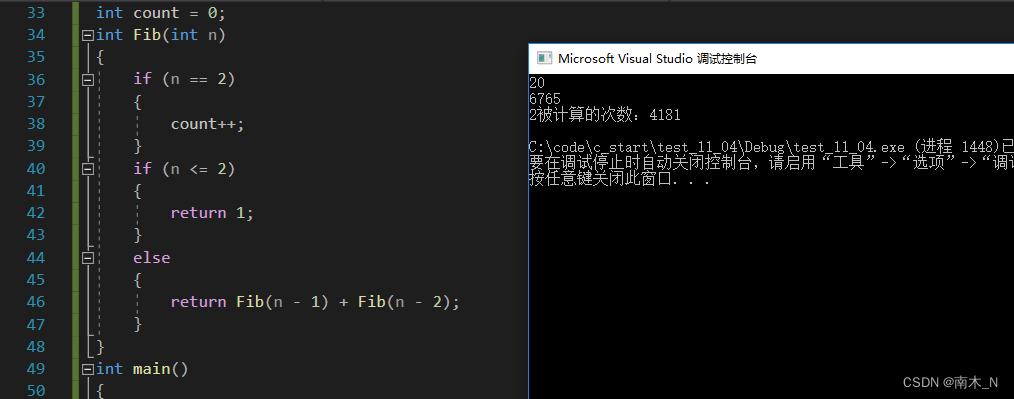

递归的执行效率太低,该怎么提高执行效率?
可以用static修饰函数内的局部变量变成静态变量,放在静态区,从而缓解栈区的压力,不过这种方法治标不治本。
另一种方法就是使用非递归(迭代)。
- 迭代
代码实现
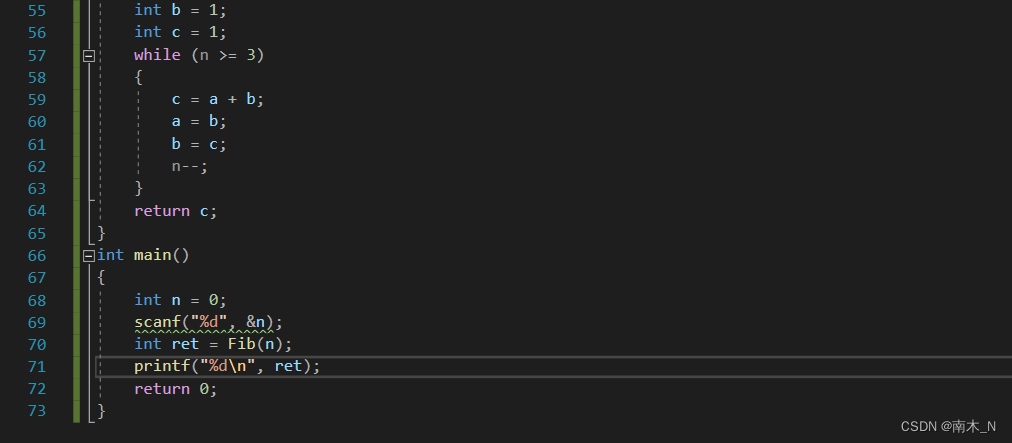
思路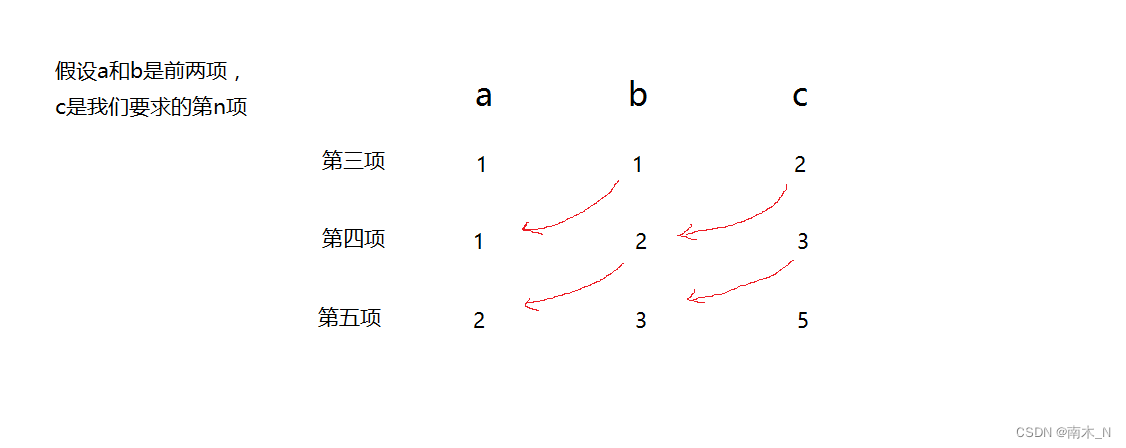
利用循环来实现,每次循环都把后两项往前移,前一项丢弃。
你会发现当n=40时,执行时间很短,效率更高。当n过大时,会出现负值,是因为c的类型是整形,存储不了那么大的值。
总结:当要求程序的执行效率时i,我们通常选择迭代,虽然它的可读性较差。当问题相当复杂时,我们就可以使用递归,因为其较简洁且足以弥补它运行时带来的开销。
总结
函数篇基本讲完了,如果后面发现有遗漏的知识点,会立马补充。
如果发现有讲错的,请一定帮忙指出,我会积极修改。感谢!














 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









