



ktransformers 是一个专为大语言模型优化的高性能推理框架,致力于在异构硬件环境(CPU+GPU)上实现高效、灵活的模型部署。该框架通过自定义算子、内存优化和设备调度,显著提升大模型的推理性能,尤其将专家计算卸载到CPU并利用intel的AMX特性使得其更加适合需要低延迟或资源受限的场景。
本篇文章主要介绍如何在KOS操作系统上部署ktransformers以及进行基准性能测试和AMX性能测试。
环境
系统环境
操作系统:KOS 5.8SP2U1
GPU:NVIDIA GeForce RTX 4090
CPU:Intel(R) Xeon(R) Gold 5418Y
Cuda:12.8
GPU dirver:570.86.15
部署方案:采用docker镜像部署
首先要确认CPU是否支持AMX特性

添加图片注释,不超过 140 字(可选)
Docker镜像
拉取docker images
docker pull nvidia/cuda:12.8.0-devel-ubuntu22.04
启动docker
![]()
添加图片注释,不超过 140 字(可选)
编译
一键部署
-
进入容器:docker exec –it ubuntu22.04-cuda-12.8 bash
-
拉取一键部署脚本: git clone https://github.com/maaaxinfinity/ktrun.git 注:该脚本会自动下载编译依赖包和更新子模块源码
-
编译KT:
cd ktrun
bash run.sh
待上述脚本执行完毕后进入ktransformers安装目录,重新执行以下命令
MAX_JOBS=56 USE_BALANCE_SERVE=1 bash ./install.sh
备注:
Ktransformers源码:https://github.com/kvcache-ai/ktransformers.git
Branch: main
Comit:90888fee0d424763e4069f5c81dd26e4012ed085
测试
测试模型:Qwen3-30B-A3B-GGUF/BF16
测试工具:chatbox
启动大模型
![]()
添加图片注释,不超过 140 字(可选)
备注:
--cpu_infer:启用的CPU核数,根据实际填写,必须大于等于2
--backend_type:后端类型,目前只有balance_serve能跑AMX
配置chatbox
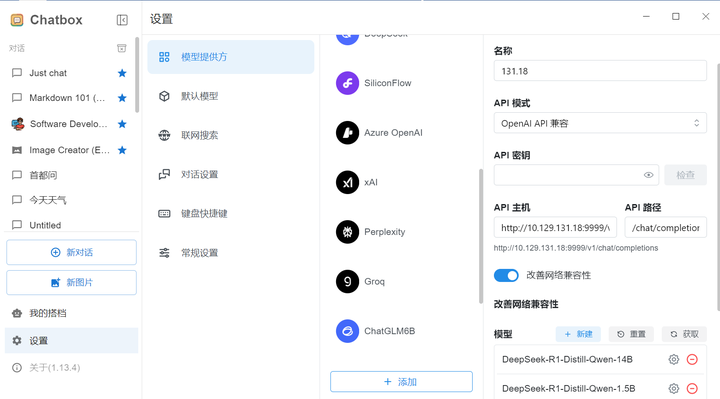
添加图片注释,不超过 140 字(可选)
设置->模型提供方->添加
名称:自定义
API模式:OpenAI API兼容
API主机:填写提供模型服务地址以及端口
模型:点击新建,填写模型名称,与模型启动--model_name指定名称相同
新建对话->输入问题可以看到正常运行
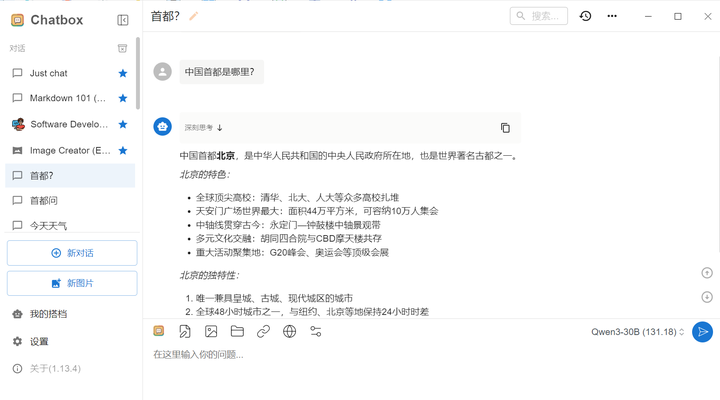
添加图片注释,不超过 140 字(可选)
性能测试
测试工具:双击以下html设置相应的参数后点击开始测试

添加图片注释,不超过 140 字(可选)
启用AMXBF16:配置文件采用Qwen3Moe-serve-amx.yaml
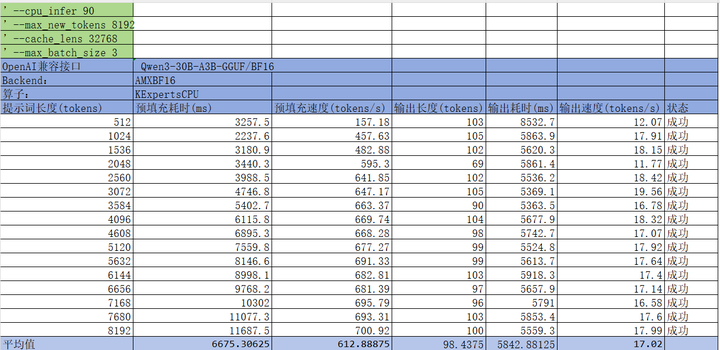
添加图片注释,不超过 140 字(可选)
启用llamafile:配置文件采用Qwen3Moe-serve.yaml或者直接修改Qwen3Moe-serve-amx.yaml文件中的backend为"llamafile"
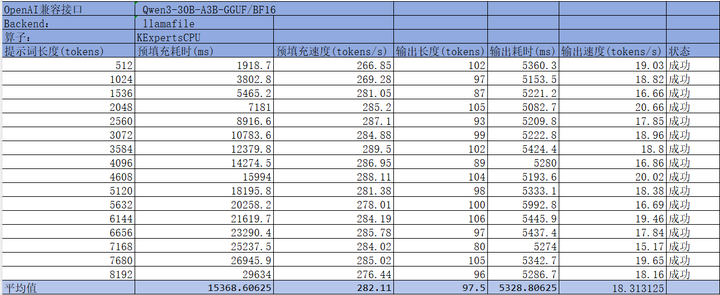
添加图片注释,不超过 140 字(可选)
通过以上数据对比可以明显看到在相同参数配置下AMXBF16推理性能提升大约2~3倍。
常见问题
-
TBB
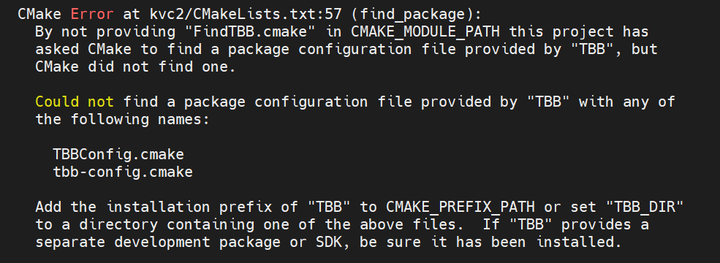
添加图片注释,不超过 140 字(可选)
解决:缺少TBB开发包 apt install libtbb-dev
-
GLIBCXX_3.4.29' not found
解决:更新glib,命令:conda install -c conda-forge libstdcxx-ng -y

















 6983
6983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









