







原文地址:http://www.linzichen.cn/article/1582549736064286720
在顺序表中查询效率很高,时间复杂度是O(1),但是其增删的效率是比较低的,因为每一次增删操作都需要伴随着大量元素的移动。如果我们需要经常线性表中的元素做增删操作,可以采用链表结构。
链表简介
链表时一种物理存储单元上非连续、非顺序的存储结构,其物理结构不能表示为数据元素的逻辑结构,数据元素的逻辑顺序是通过链表中的指针连接次序实现的。链表由一系列的结点(每个元素被称为一个结点)组成,结点可以在运行时动态生成。
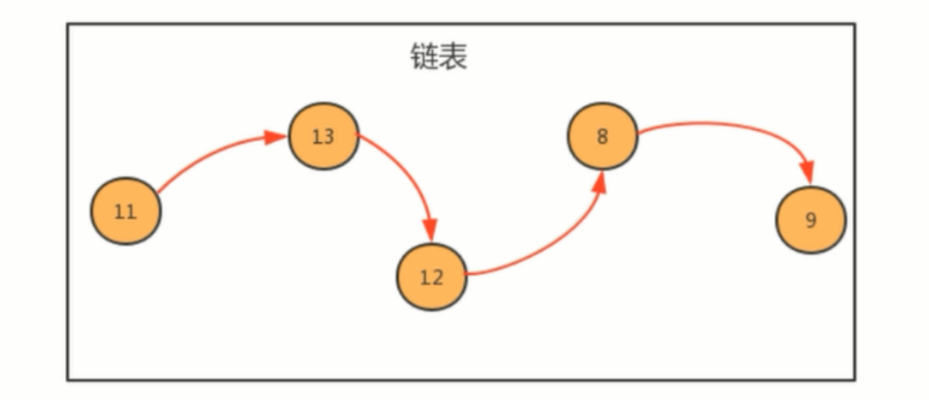
根据上图,元素11的指针指向元素13,如果我们要在 11 和 13 中插入一个元素 22,那我们只需要生成一个 22元素,将 11的指针指向22,将22的指针指向13,以此就完成了链表中插入的动作。
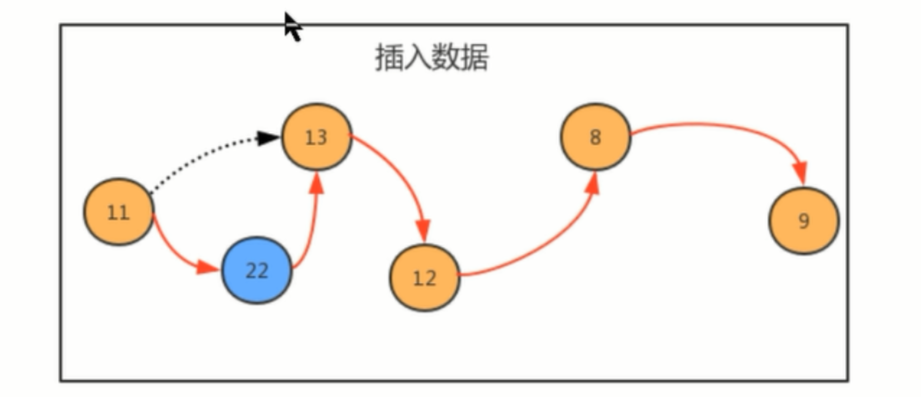
同样的,删除也是同理,只需要修改关联元素之间的指针,就可以实现元素的动态插入和删除。
结点API设计
如何使用链表,根据面向对象思想,我们可以设计一个类来描述结点这个事物,用一个属性描述此结点存储的元素,用另一个属性描述此结点的下一个结点.
| 类名 | Node |
|---|---|
| 构造方法 | Node(T t, Node next):创建Node对象 |
| 成员变量 | T t:存储数据 Node next:指向的下一个结点 |
单向链表
单向链表是链表的一种,它由多个结点组成,每个结点都有一个数据域和一个指针域,分别用来存储数据和指向其后继的结点。链表的头结点的数据域不存储数据,指针域指向第一个真正存储数据的结点。

API设计
| 类名 | LinkList |
|---|---|
| 构造方法 | LinkList(int length):创建长度为length的LinkList对象 |
| 成员方法 | 1. public void clear():空置线性表 2. public boolean isEmpty():判断线性表是否为空 3. public int length():获取线性表中元素个数 4. public T get(int i):获取第i个元素的值 5. public void insert(T t, int i):在线性表中第i个元素之前插入 t 元素 6. public void insert(T t):向线性表中添加一个元素 7. public T remove(int i):删除并返回线性表中第i个数据元素 8. public int indexOf(T t):返回线性表中 t 元素首次出现的位置,若不存在返回 -1 |
| 成员内部类 | private class Node:结点类 |
| 成员变量 | 1. private Node head:存储头结点 2. private int N:链表的长度 |
代码实现
/**
* 单向链表
* @param <T>
*/
public class LinkList <T>{
// 记录头结点
private Node head ;
// 记录链表长度
private int N ;
/**
* 结点对象
*/
private class Node {
// 当前结点数据
T t;
// 指向的下一个结点
Node next ;
public Node(T t, Node next) {
this.t = t ;
this.next = next ;
}
}
public LinkList() {
// 初始化链表时,存在一个头结点,但不存储任何数据,
// next指向第一个真实数据结点
this.head = new Node(null, null) ;
this.N = 0 ;
}
/**
* 空置线性表
*/
public void clear() {
head.next = null ;
N = 0 ;
}
/**
* 判断线性表是否为空
* @return
*/
public boolean isEmpty() {
return N == 0 ;
}
/**
* 获取元素个数
* @return
*/
public int length() {
return N ;
}
/**
* 获取线性表中下标为i的元素
* @param i
* @return
*/
public T get(int i) {
// 从头结点开始遍历
Node node = head ;
// i - 1 结点的 next 元素就是 i 处的结点
for (int index = 0 ; index < i ; ++index) {
node = node.next ;
}
return node.t ;
}
/**
* 向线性表中插入元素
* @param t
*/
public void insert(T t) {
Node node = head ;
// 添加到链表的最后一个元素,所以需要找到最后一个结点
// 让最后一个结点的 next = 添加的元素即可
// 最后一个元素的判定条件是 next 为 空
while (node.next != null) {
node = node.next ;
}
Node newNode = new Node(t, null) ;
node.next = newNode ;
N += 1 ;
}
/**
* 向线性表中 i 位置插入元素
* 1、找到原 i 处的前一个结点:pre
* @param t
* @param i
*/
public void insert(T t ,int i) {
// 1、找到原 i 处的前一个结点:pre
Node pre = head ;
for (int index = 0 ; index < i ; ++index) {
pre = pre.next ;
}
// 2、获取 原 i 处的结点
Node oldINode = pre.next ;
// 3、生成新的结点,并且next 指向原 i 处的结点
Node newNode = new Node(t, oldINode) ;
// 4、让 i -1 处的结点next 指向新的结点
pre.next = newNode ;
N += 1 ;
}
/**
* 删除并返回线性表中第 i 个元素
* 就是让 i -1 处元素的 next 指向 i + 1 位置的元素
* @param i
* @return
*/
public T remove(int i) {
// 1、获取 i - 1 处的结点
Node pre = head ;
for (int index = 0 ; index < i ; ++index) {
pre = head.next ;
}
// 2、获取 i 结点
Node iNode = pre.next ;
// 3.让 i -1 的 next 指向 i 的 next
pre.next = iNode.next ;
N -= 1 ;
return iNode.t ;
}
/**
* 返回线性表中 t 元素首次出现的位置
* 若没有,返回 -1
* @param t
* @return
*/
public int indexOf(T t) {
Node node = head ;
for (int i = 0 ; node.next != null ; ++i) {
node = node.next ;
if (node.t.equals(t)) {
return i ;
}
}
return -1 ;
}
}
链表反转
现有一个链表结构如下:
head-> 1 -> 2 -> 3 -> 4
我们希望反转后的结构如下:
head-> 4 -> 3 -> 2 -> 1
方案一:遍历

思路:
由上图可知,我们需要遍历每一个结点,然后将当前结点指向其前驱结点,当遍历完成后,需要将 head头结点指向遍历的最后一个结点,即可实现反转。
步骤:
1). 需要定义两个变量 pre 和 next ,分别记录当前正在遍历结点的前驱元素 和 后继元素,初始值为 null。
2). 从 第一个结点(head.next)开始遍历,条件为当前遍历允许不为 null。
3). 将当前结点的next赋值给 next。
4). 将当前结点的 next重新指向 pre 。
5). 准备开始为下轮遍历构建条件,所以需要将 当前结点 赋值给 pre ,以作为下次遍历结点的 前驱元素。
6). 把 next 元素赋值给 当前元素。
7). 循环结束后, head 指向最后遍历的结点。
代码:
/**
* 遍历反转
*/
public void reverse() {
// 前驱元素
Node pre = null ;
// 当前元素
Node current = head.next ;
// 后继元素
Node next = null ;
while (current != null) {
// 记录结点的下个元素
next = current.next ;
// 让本结点指向上一个结点
current.next = pre ;
// 让上一个结点变成本结点
pre = current ;
// 让本结点变成下一个结点,再去循环
current = next ;
}
// 循环结束后,head指向最后的元素
head.next = pre;
}
方案二:递归

思路步骤:
1). 调用 reverse(Node current) 方法反转每一个结点,从a结点开始。
2). 如果发现 current 还有下一个结点,则递归调用 reverse(current.next) 对下一个结点先进行反转。
3). 最终递归的出口是d结点,因为它没有后继元素了,所以此时需要让 head 指向元素d结点。
4). 让递归开始返回。
代码:
/**
* 递归调用
*/
public void reverse() {
if (isEmpty()) {
return ;
}
Node node = reverse(head.next);
System.out.println("最后的结点:" + node.t);
}
public Node reverse(Node current) {
if (current.next != null) {
// 开始压栈,出栈的时候,oldNext 一定是 d 元素
// 递归3次:oldNext 为 d,current 为 c
// 递归2次,oldNext 为 c,current 为 b
// 递归1次,oldNext 为 b,current 为 a
// 调用方法,返回的 current 为 a
Node oldNext = reverse(current.next) ;
oldNext.next = current ;
current.next = null ;
return current ;
} else {
head.next = current ;
return current ;
}
}
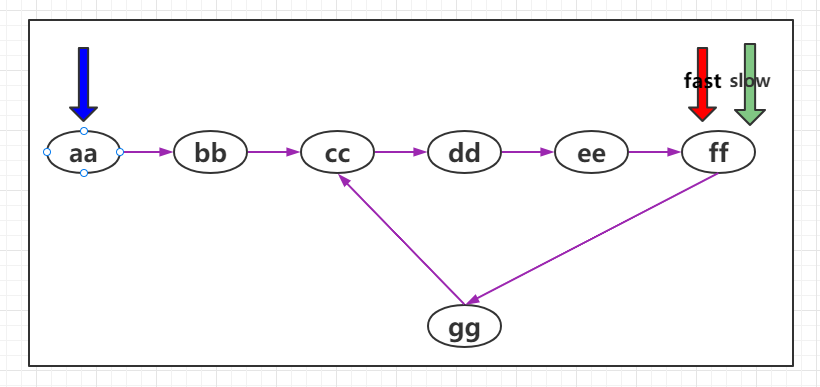
快慢指针
快慢指针指的是定义两个指针,这两个指针的移动速度一块一慢,以此来制造出自己想要的差值,这个差值可以让我们找到链表上相应的结点。一般情况下,快指针的移动步长为慢指针的两倍。
中间值问题
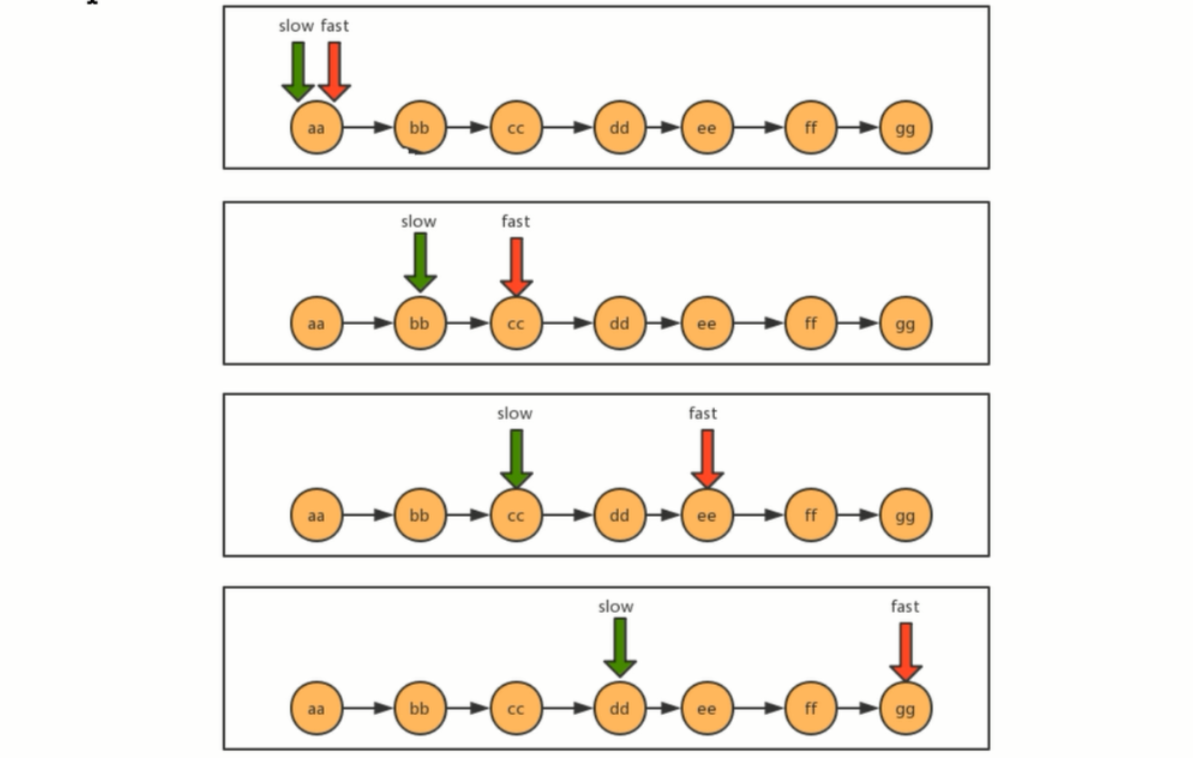
如果要查找链表中的中间值,我们就可以用快慢指针。利用快慢指针,可以把链表看成一个跑到,假设 a 的速度是 b 的两倍,那么当 a 跑完全程后,b 刚好跑一半,以此来达到找到中间结点的目的。
如下图,最开始 slow 和 fast 指针都指向链表的第一个结点,然后slow 每次移动一个指针,fast 每次移动两个指针。
/**
* 获取中间值
* @return
*/
public T getMid() {
Node fast = head.next ;
Node slow = head.next ;
while (fast != null && fast.next != null) {
// 变化 fast 和 slow 的值
fast = fast.next.next ;
slow = slow.next ;
}
return slow.t ;
}
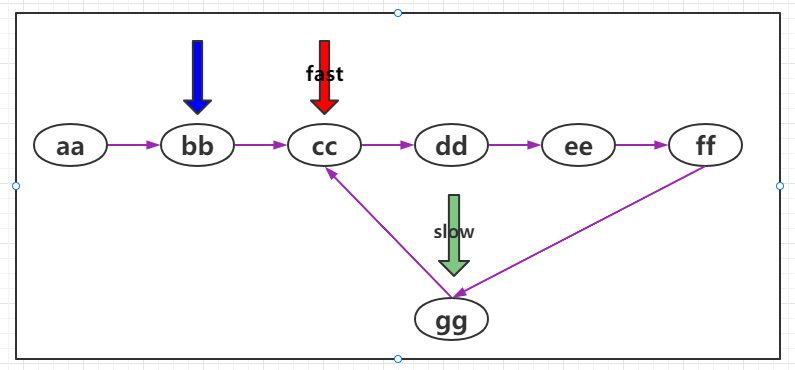
单向链表是否有环
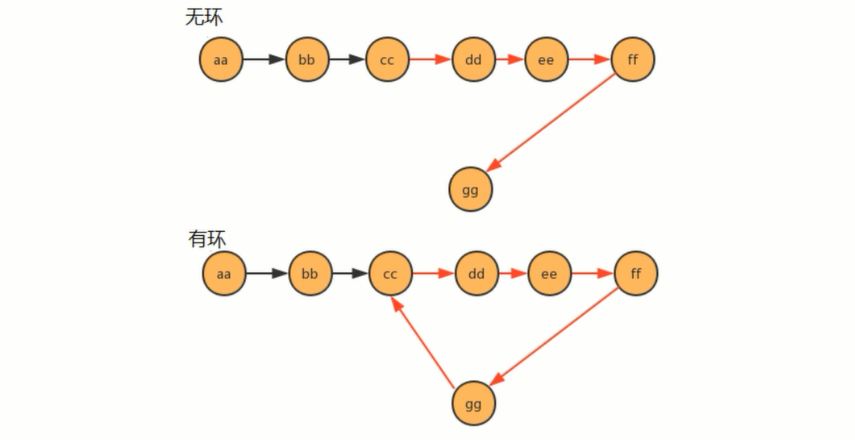
使用快慢指针的思想,还是把链表比作一条跑道,链表中有环,那么这条跑道就是一条圆环跑道,在一条圆环跑道中,两个人有速度差,那么迟早两个人会相遇,只要相遇那么就说明有环。
/**
* 链表是否有环
* @return
*/
public boolean isCircle() {
Node fast = head.next ;
Node slow = head.next ;
while (fast != null && fast.next != null) {
// 变化 fast 和 slow 的值
fast = fast.next.next ;
slow = slow.next ;
//if (fast.compareTo(slow) == 0) {
if (fast.equals(slow)) {
return true ;
}
}
return false ;
}
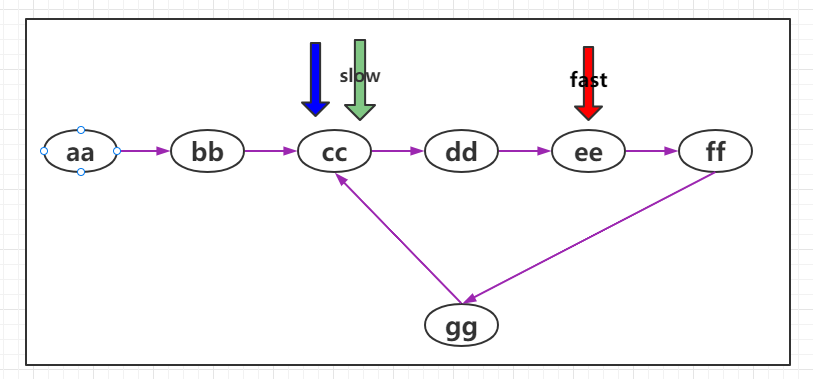
单向链表入口问题
当快慢指针相遇时,我们可以判断到链表中有环,这时重新设定一个新指针指向链表的起点,且步长与慢指针一样为1,则慢指针与“新"指针相遇的地方就是环的入口。
/**
* 查找有环链表中环的入口结点
* @return 环的入口结点
*/
public static Node getEntrance() {
//定义快慢指针
Node<String> fast = head.next;
Node<String> slow = head.next;
Node<String> temp = null;
//遍历链表,先找到环(快慢指针相遇),准备一个临时指针,指向链表的首结点,继续遍历,直到慢指针和临时指针相遇,那么相遇时所指向的结点就是环的入口
while(fast!=null && fast.next!=null){
//变换快慢指针
fast = fast.next.next;
slow = slow.next;
//判断快慢指针是否相遇
if (fast.equals(slow)){
temp = first;
continue;
}
//让临时结点变换
if (temp!=null){
temp = temp.next;
//判断临时指针是否和慢指针相遇
if (temp.equals(slow)){
break;
}
}
}
return temp;
}
//结点类
private static class Node<T> {
//存储数据
T item;
//下一个结点
Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
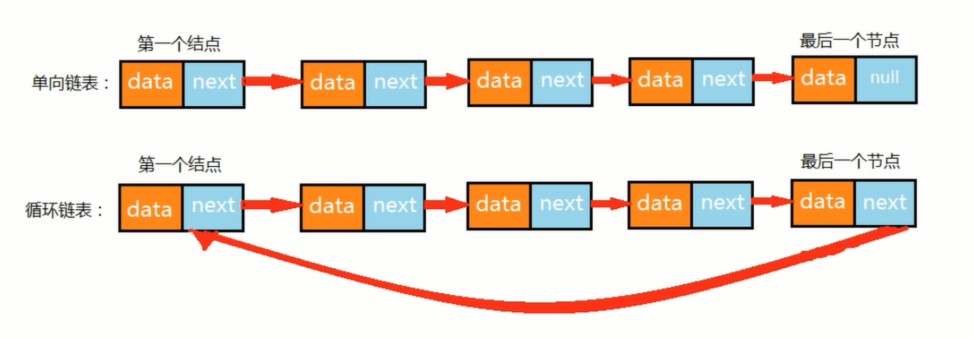
循环链表
循环链表,顾名思义,链表整体要形成一个圆环状。在单向链表中,最后一个结点的指针为null ,不指向任何结点,因为没有下一个元素了。要实现循环链表,我们只需要让单向链表的最后一个结点的指针指向头结点即可。
约瑟夫问题
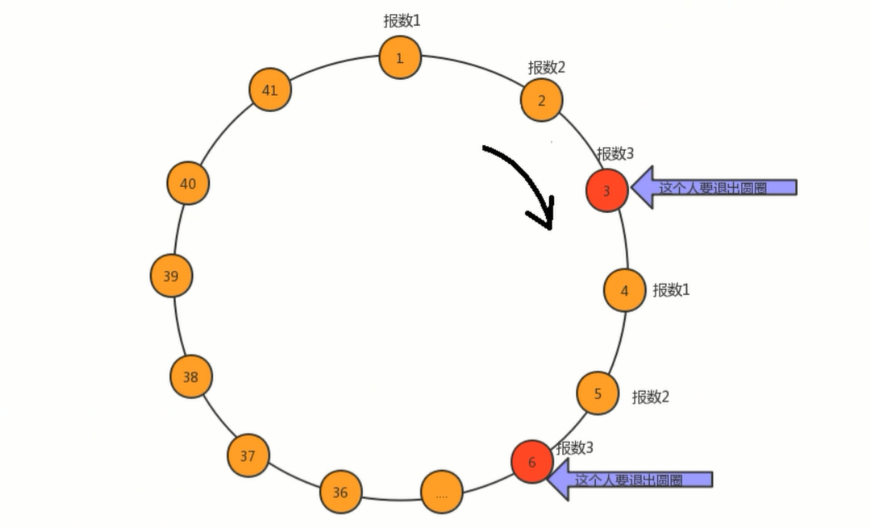
问题描述︰
传说有这样一个故事,在罗马人占领乔塔帕特后,39个犹太人与约瑟夫及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,第一个人从1开始报数,依次往后,如果有人报数到3,那么这个人就必须自杀,然后再由他的下一个人重新从1开始报数,直到所有人都自杀身亡为止。然而约瑟夫和他的朋友并不想遵从。于是,约瑟夫要他的朋友先假装遵从,他将朋友与自己安排在第16个与第31个位置,从而逃过了这场死亡游戏。
问题转换︰
41个人坐一圈,第一个人编号为1,第二个人编号为2,第n个人编号为n。1.编号为1的人开始从1报数,依次向后,报数为3的那个人退出圈;⒉.自退出那个人开始的下一个人再次从1开始报数,以此类推;3.求出最后退出的那个人的编号。
图示:
代码实现:
public class JosephTest {
public static void main(String[] args) {
//解决约瑟夫问题
//1.构建循环链表,包含41个结点,分别存储1~41之间的值
//用来就首结点
Node<Integer> first = null;
//用来记录前一个结点
Node<Integer> pre = null;
for(int i = 1;i<=41;i++){
//如果是第一个结点
if (i==1){
first = new Node<>(i,null);
pre = first;
continue;
}
//如果不是第一个结点
Node<Integer> newNode = new Node<>(i, null);
pre.next=newNode;
pre=newNode;
//如果是最后一个结点,那么需要让最后一个结点的下一个结点变为first,变为循环链表了
if (i==41){
pre.next=first;
}
}
//2.需要count计数器,模拟报数
int count=0;
//3.遍历循环链表
//记录每次遍历拿到的结点,默认从首结点开始
Node<Integer> n = first;
//记录当前结点的上一个结点
Node<Integer> before = null;
while(n!=n.next){
//模拟报数
count++;
//判断当前报数是不是为3
if (count==3){
//如果是3,则把当前结点删除调用,打印当前结点,重置count=0,让当前结点n后移
before.next=n.next;
System.out.print(n.item+",");
count=0;
n=n.next;
}else{
//如果不是3,让before变为当前结点,让当前结点后移;
before=n;
n=n.next;
}
}
//打印最后一个元素
System.out.println(n.item);
}
//结点类
private static class Node<T> {
//存储数据
T item;
//下一个结点
Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
}
双向链表
双向链表也叫双向表,是链表的一种,它由多个结点组成,每个结点都由一个数据域和两个指针域组成,数据域用来存储数据,其中一个指针域用来指向其后继结点,另一个指针域用来指向前驱结点。链表的头结点的数据域不存储数据,指向前驱结点的指针域值为null,指向后继结点的指针域指向第一个真正存储数据的结点。

实现
双向链表的API 及实现方式跟单向链表很像,就多维护了一个结点而已,这里不过多的去聊,直接贴上代码:
import java.util.Iterator;
public class TowWayLinkList<T> implements Iterable<T> {
//首结点
private Node head;
//最后一个结点
private Node last;
//链表的长度
private int N;
//结点类
private class Node{
public Node(T item, Node pre, Node next) {
this.item = item;
this.pre = pre;
this.next = next;
}
//存储数据
public T item;
//指向上一个结点
public Node pre;
//指向下一个结点
public Node next;
}
public TowWayLinkList() {
//初始化头结点和尾结点
this.head = new Node(null,null,null);
this.last=null;
//初始化元素个数
this.N=0;
}
//清空链表
public void clear(){
this.head.next=null;
this.head.pre=null;
this.head.item=null;
this.last=null;
this.N=0;
}
//获取链表长度
public int length(){
return N;
}
//判断链表是否为空
public boolean isEmpty(){
return N==0;
}
//获取第一个元素
public T getFirst(){
if (isEmpty()){
return null;
}
return head.next.item;
}
//获取最后一个元素
public T getLast(){
if (isEmpty()){
return null;
}
return last.item;
}
//插入元素t
public void insert(T t){
if (isEmpty()){
//如果链表为空:
//创建新的结点
Node newNode = new Node(t,head, null);
//让新结点称为尾结点
last=newNode;
//让头结点指向尾结点
head.next=last;
}else {
//如果链表不为空
Node oldLast = last;
//创建新的结点
Node newNode = new Node(t, oldLast, null);
//让当前的尾结点指向新结点
oldLast.next=newNode;
//让新结点称为尾结点
last = newNode;
}
//元素个数+1
N++;
}
//向指定位置i处插入元素t
public void insert(int i,T t){
//找到i位置的前一个结点
Node pre = head;
for(int index=0;index<i;index++){
pre=pre.next;
}
//找到i位置的结点
Node curr = pre.next;
//创建新结点
Node newNode = new Node(t, pre, curr);
//让i位置的前一个结点的下一个结点变为新结点
pre.next=newNode;
//让i位置的前一个结点变为新结点
curr.pre=newNode;
//元素个数+1
N++;
}
//获取指定位置i处的元素
public T get(int i){
Node n = head.next;
for(int index=0;index<i;index++){
n=n.next;
}
return n.item;
}
//找到元素t在链表中第一次出现的位置
public int indexOf(T t){
Node n = head;
for(int i=0;n.next!=null;i++){
n=n.next;
if (n.next.equals(t)){
return i;
}
}
return -1;
}
//删除位置i处的元素,并返回该元素
public T remove(int i){
//找到i位置的前一个结点
Node pre = head;
for(int index=0;index<i;index++){
pre=pre.next;
}
//找到i位置的结点
Node curr = pre.next;
//找到i位置的下一个结点
Node nextNode= curr.next;
//让i位置的前一个结点的下一个结点变为i位置的下一个结点
pre.next=nextNode;
//让i位置的下一个结点的上一个结点变为i位置的前一个结点
nextNode.pre=pre;
//元素的个数-1
N--;
return curr.item;
}
@Override
public Iterator<T> iterator() {
return new TIterator();
}
private class TIterator implements Iterator{
private Node n;
public TIterator(){
this.n=head;
}
@Override
public boolean hasNext() {
return n.next!=null;
}
@Override
public Object next() {
n=n.next;
return n.item;
}
}
}
链表复杂度分析
ge(int i):每一次查询,都需要从链表的头部开始,依次向后查找,随着数据元素N的增多,比较的元素越多,时间复杂度为O(n);
insert(int i,T t);每一次插入,需要先找到位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n);
remove(int i)每一次移除,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为O(n);
相比较顺序表,链表插入和删除的时间复杂度虽然一样,但仍然有很大的优势,因为链表的物理地址是不连续的,它不需要预先指定存储空间大小,或者在存储过程中涉及到扩容等操作…同时它并没有涉及的元素的交换。
相比较顺序表,链表的查询操作性能会比较低。因此,如果我们的程序中查询操作比较多,建议使用顺序表,增删操作比较多,建议使用链表。















 6253
6253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









