







1.准确的问题描述:
输入:一个最多包含n个正整数的文件,每个数都小于n,n=10^7。如果在输入文件中有任何整数重复出现就是致命错误,且没有其他的数据与该整数相关联。
输出:按升序排列的输入整数的序列
约束:最多有1MB的内存空间可用,有充足的磁盘存储空间可用。运行时间最多几分钟,运行时间为10秒就不需进一步优化了。
2.程序设计:
现有以下两种简单排序方式:
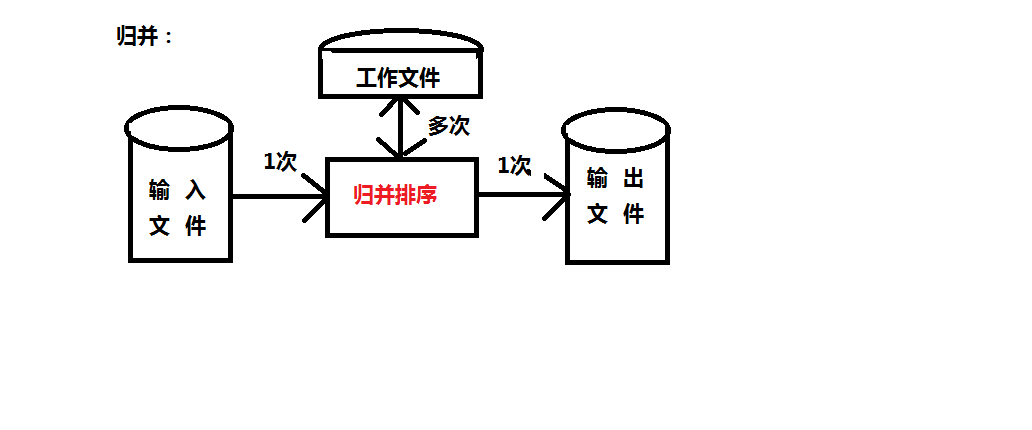
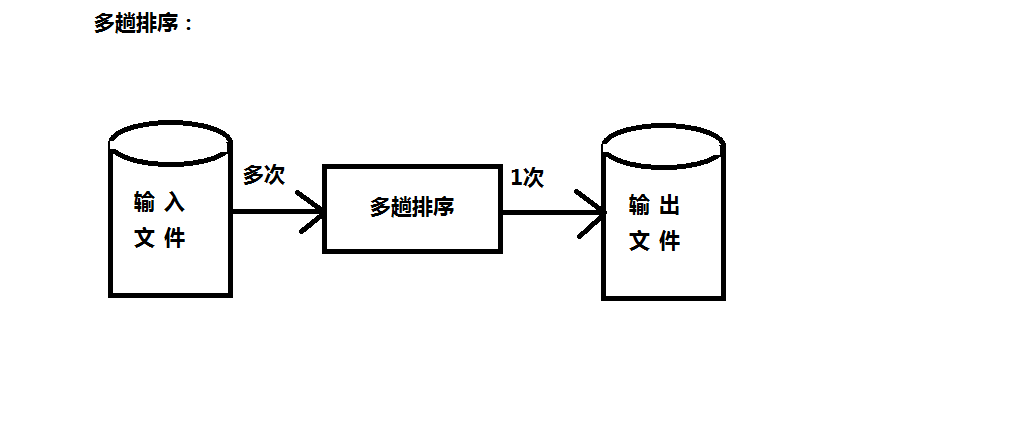
但实际上,我们会发现两种方式都各有缺陷,第一种方式会多次与工作文件进行交互,而多趟排序则要将输入文件进行多次操作。
因此,我们考虑用一种神奇排序,实现两种排序的优点,取长补短。
如图:

3.实现概要:
由此,我们可以使用位图或位向量表示集合。
可用一个20位长的字符串来表示一个所有元素都小于20的简单的非负整数集合。例如,集合{1,2,3,5,8,13}:
0 1 1 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0
代表集合中数值的位都置为1,其他所有的位都置为0。
注:
这种实现方式取决于该程序的特殊性:
输入数据限制在相对较小的范围内;数据没有重复;而且对于每条记录而言,除了单一整数外,没有任何其他关联数据。(然而实际上和三个属性在排序问题中是不常见的)
所以,我们可以利用上述方式去表示我们的数据记录。
分为三个阶段实现:
第一:将所有位置为0,即初始化集合为空。
第二:通过读入文件中的每个整数来建立集合。
第三:检验每一位,如果该位为1,就输出对应的整数,由此产生有序的输出文件。
伪代码:
/* phase 1: initialize set to empty*/
for i=[0,n)
bit[i]=0
/* phase 2:insert present elements into the set */
for each i in the input file
bit[i]=1
/* phase 3:write sorted output */
for i=[0,n)
if bit[i]=1
write i on the output file
C代码实现:
#include<stdio.h>
int main()
{
int n=100;
int a[5]={1,3,99,50,33},b[100]={0};
// phase 2:insert present elements into the set //
for(int j=0;j<5;j++)
{
b[a[j]]=1;
}
// phase 3:get the output //
for(int i=0;i<n;i++)
{
if(b[i]==1)
printf("%d\n",i);
}
return 0;
}















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









