






一 导读
如今云计算、大数据发展得如火如荼,PB容量单位早已经进入国内企业存储采购单,DT时代即将来临。Ceph对象存储的优秀特性吸引越来越多开发者,本文对Ceph对象存储进行架构详解。
二 对象存储
文件存储,通常指的是遵循POSIX协议,同时具备并行化访问和冗余机制的存储方式,现在也将非POSIX协议的GFS、HDFS、FastDFS等归为文件存储。同时文件存储引进了目录,十分类似我们平时Windows的文件结构,当单个目录文件数量过大时,文件查找效率会急剧下降。
对象存储是在文件存储的基础上发展而来的,对象存储抛弃了文件存储的命名空间、文件目录等结构。对象存储相比文件存储更加简洁,抛弃了命名空间、文件目录等结构,更加扁平化,在使用、扩展、维护方面更加符合大众化思想。操作主体由文件变为对象,对象的操作主要以Put、Get和Delete为主,十分类似Java的HashMap,只不过对象存储中的对象不支持修改。总体来说,对象存储是为了克服文件存储的缺点,并发挥文件存储的优点而出现的。但对于存储内容而言,文件存储和对象存储并无本质区别,只是存储方式发生了变化。
三 Ceph
Ceph是一个去中心化、强一致性、易扩展性的分布式对象存储系统,并消除了对系统单一中心节点的依赖,从而实现了真正的无中心结构的设计思想,这也是其他分布式存储系统不能比的。目前业界自研商业存储例如阿里云存储、华为云存储、七牛云存储等或多或少都借鉴Ceph的设计思想和物理架构。
3.1 设计思想
Ceph最初针对的应用场景,就是大规模的、分布式的存储系统。所谓大规模和分布式,至少是能够承载PB级别的数据和成千上万的存储节点组成的存储集群
如今云计算、大数据发展得如火如荼,PB容量单位早已经进入国内企业存储采购单,DT时代即将来临。Ceph起源于2004年,那是一个商用处理器以单核为主流,常见硬盘容量只有几十GB的年代。当时SSD也没有大规模商用,正因如此,Ceph之前版本对SSD的支持不是很好,发挥不了SSD的性能。如今Ceph高性能面临的最大挑战正是这些历史原因,目前社区和业界正在逐步解决这些性能上的限制。Ceph的技术特性,总体表现在集群可靠性、集群扩展性、数据安全性、接口统一性4个方面。
3.1.1 集群可靠性
所谓可靠性,首先从用户角度来说数据是第一位的,要尽可能保证数据不会丢失。其次,就是数据写入过程中的可靠性,在用户将数据写入Ceph存储系统的过程中,不会因为意外情况出现而造成数据丢失。最后,就是降低不可控物理因素的可靠性,避免因为机器断电等不可控物理因素而产生的数据丢失。
3.1.2 集群扩展性
这里的可扩展概念是广义的,既包括系统规模和存储容量的可扩展,也包括随着系统节点数增加的聚合数据访问带宽的线性扩展。
3.1.3 数据安全性
所谓数据安全性,首先要保证由于服务器死机或者是偶然停电等自然因素的产生,数据不会丢失,并且支持数据自动恢复,自动重平衡等。总体而言,这一特性既保证了系统的高度可靠和数据绝对安全,又保证了在系统规模扩大之后,其运维难度仍能保持在一个相对较低的水平。
3.1.4 接口统一性
所谓接口统一性,指的是Ceph可以同时支持3种存储,即块存储、对象存储和文件存储,Ceph支持市面上所有流行的存储类型。严格来说,Ceph只支持对象存储,块存储和文件存储也是借助对象存储来实现的。
根据Ceph的技术特性,可以总结出Ceph的设计思路,概述为两点:充分发挥存储本身计算能力和去除所有的中心点。充分发挥存储设备自身的计算能力:其实就是采用廉价的设备和具有计算能力的设备(最简单的例子就是普通的服务器)作为存储系统的存储节点。当前阶段只是将这些服务器当做功能简单的存储节点,从而产生资源过度浪费(如同虚拟化的思想一样,都是为了避免资源浪费)。而如果充分发挥节点上的计算能力,则可以实现前面提出的技术特性。这一点成为了Ceph系统设计的核心思想。去除所有的中心点:如果系统中出现中心点,一方面会引入单点故障,另一方面也必然面临着当系统规模扩大时的可扩展性和性能瓶颈。除此之外,如果中心点出现在数据访问的关键路径上,也必然导致数据访问的延迟增大。虽然在大多数存储软件实践中,单点故障点和性能瓶颈的问题可以通过为中心点增加HA或备份加以缓解,但Ceph系统最终采用CRUSH、Hash环等方法更彻底地解决了这个问题。
3.2 架构设计
Ceph底层核心是RADOS,整体架构如下图。

3.2.1 RADOS
RADOS具备自我修复等特性,提供了一个可靠、自动、智能的分布式存储,是Ceph存储集群的基础。Ceph中的一切都以对象的形式存储,而RADOS就负责存储这些对象,而不考虑它们的数据类型。RADOS确保数据一致性和可靠性,对于数据一致性,它执行数据复制、故障检测和恢复,还包括数据在集群节点间的Recovery。

OSD,数据存储单元,主要功能包括数据存储、数据复制、数据恢复、数据回补、数据平衡等功能,并将一些相关数据提供给Monitor,例如OSD心跳等。一般情况下,一块磁盘对于一个OSD。对于整个存储集群,需要多个OSD,只有当OSD数量足够多时,Ceph的虚随机算法才能实现数据均匀分布。
Monitor,监视器,主要功能是维护整个集群健康状态,提供一致性决策。Ceph需要多个Monitor组成小集群,它们通过Paxos同步数据,用来保存OSD的元数据。Monitor同时维护着Ceph集群中的各种Map图,比如OSD Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和ObjectId等计算出数据最终存储的位置。
3.2.2 LIBRADOS
对RADOS进行抽象和封装,简化访问RADOS的一种方法,并向上层提供API,以便直接基于RADOS进行应用开发,API目前支持PHP、Ruby、Java、Python、C和C++语言。它提供了Ceph 存储集群的一个本地接口RADOS ,并且是其他服务(如RBD 、RGW)的基础,以及为Ceph FS提供POSIX接口。LIBRADOS API支持直接访问RADOS ,使得开发者能够创建自己的接口来访问Ceph集群存储。
3.2.3 RBD
Ceph块设备,对外提供块存储。可以像磁盘一样被映射、格式化已经挂载到服务器上,支持快照,常用于虚拟化场景。
3.2.4 RGW
提供与Amazon S3和Swift兼容的RESTful API的网关,以供相应的对象存储应用开发使用。RGW提供的API抽象层次更高,但在类S3或Swift LIBRADOS的管理比便捷,因此,开发者应针对自己的需求选择使用。
3.2.5 Ceph FS
提供了一个任意大小且兼容POSlX的分布式文件系统(类似TFS、HDFS、FastDFS等文件系统),Ceph FS依赖元数据服务Ceph MDS来跟踪文件层次结构。
3.3 智能分布
数据分布是分布式存储系统的一个重要部分,数据分布算法至少要考虑以下3个因素。故障隔离:同份数据的不同副本分布在不同的故障域,降低数据损坏的风险。负载均衡:数据能够均匀地分布在磁盘容量不等的存储节点,避免部分节点空闲,部分节点超载,从而影响系统性能。数据迁移:控制节点加入离开时引起的数据迁移量。当节点离开时,最优的数据迁移是只有离线节点上的数据被迁移到其他节点,而正常工作的节点的数据不会发生迁移。
对象存储中一致性Hash和CRUSH算法是使用比较多的数据分布算法。在Aamzon的Dyanmo键值存储中采用一致性Hash算法,并且对它做了很多优化。OpenStack的Swift对象存储中也使用了一致性Hash算法。
CRUSH(Controlled Replication Under Scalable Hashing)是一种基于伪随机控制数据分布、复制的算法。Ceph是为大规模分布式存储系统(PB级的数据和成百上千台存储设备)而设计的,在大规模的存储系统里,必须考虑数据的平衡分布和负载(提高资源利用率)、最大化系统的性能,以及系统的扩展和硬件容错等。CRUSH就是为解决以上问题而设计的。在Ceph集群里,CRUSH只需要一个简洁而层次清晰的设备描述,包括存储集群和副本放置策略,就可以有效地把数据对象映射到存储设备上,且这个过程是完全分布式的,在集群系统中的任何一方都可以独立计算任何对象的位置。另外,大型系统存储结构是动态变化的(存储节点的扩展或者缩容、硬件故障等), CRUSH能够处理存储设备的变更(添加或删除),并最小化由于存储设备的变更而导致的数据迁移。
简单来说,CRUSH算法的核心意义在于,在存储策略不变、PG和OSD数量足够多的情况下,均匀选择一个PG。因为PG管理存储集群所有的OSD,因此均匀选择一个PG,等价于选择一组OSD。
3.3.1 数据寻址
分布式存储系统,必须要能够解决两个最基本的问题,即现在应该把数据写到什么地方与之前把数据写到什么地方了,因此会涉及数据如何寻址的问题。Ceph数据寻址要经历以下三个阶段:
3.3.1 File -> Object映射
Ceph条带化之后,将获得N个带有唯一OID的Object。OID是进行线性映射生成的,即由File的元数据INO以及Ceph条带化产生的Object序号ONO连缀而成,举例而言,如果1个ID为Filename的File被切分为3个Object,则Object序号依次为0、1和2,最终得到的OID依次为Filename0、Filename1和Filename2。
3.3.2 Object -> PG映射
在File被映射为一个或者多个Object之后,接下来就需要将每个Object独立地映射到PG中,这个映射过程也很简单,其计算公式PG ID=Hash(OID)&Mask,其中Mask=PG总数-1,PG总数需要设置为2的整数幂。当有足够数量的Object,PG被选中的概率近似均匀。
3.3.3 PG -> OSD映射
在得到PG ID之后,就需要将PG映射到数据实际存储单元OSD上,其计算过程CRUSH(PG ID)=(OSD1,OSD2,OSD3)。CRUSH算法的结果是得到一组OSD,在PG数量、OSD数量、以及存储策略不变的情况下,其结果一般不会变化。

3.4 冗余方式
数据冗余能在分布式系统发生故障时起到恢复数据的作用,也是分布式系统可靠性的常用手段。数据冗余方式有两种,一种是多副本,一种是纠删码。Ceph因为能同时支持多副本与纠删码,因此是多数商业存储公司首选的技术方案。
3.4.1 多副本
多副本是分布式系统常见的冗余方式,简单易用,可靠性极高。多副本相对纠删码更加成熟、稳定,也是大部分中间件冗余数据的常见手段,例如Kafka分区副本。缺点是磁盘利用率低,在N副本模式下,磁盘利用率只有1/N。在分布式存储中,除了可靠性要考虑之外,磁盘利用率也是要考虑的一个指标。
3.4.2 纠删码
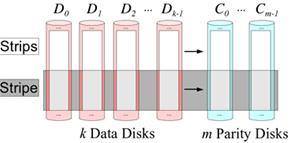
纠删码主要是通过利用算法将原始的数据进行编码得到校验,并将数据和校验一并存储起来,以达到容错的目的。其基本思想是将K块原始数据元素通过一定的编码计算,得到M块校验元素。当其中任意m块元素出错(包括数据和校验出错),均可以通过对应的重构算法恢复出原来的K块数据。生成校验的过程被成为编码,恢复丢失数据块的过程被称为解码。
纠删码能够基于更少的冗余设备,提供和多副本近似的可靠性,但是纠删码也带来了计算量和网络负载的额外负担,磁盘利用率越高,就需要花费更多的计算量和网络负载。在对象存储中,需要在磁盘利用率和可靠性之间做一个平衡。在纠删码模式下,磁盘利用率为K/(K+M),远比多副本1/N高。一般而言,纠删码模式下,磁盘利用率推荐在75%(K=9,M=3)较为合适,磁盘利用率更高的话,可靠性会进一步降低,进而影响对象存储的稳定性。可以归纳为:纠删码是一种用计算换存储空间的存储方式,相比多副本能节省非常多的磁盘空间,但是在数据恢复的时候代价比多副本大得多。
在对象存储实际生产环境中,对于热数据会使用多副本策略来冗余,冷数据使用纠删码来冗余。
四 结语
存储方式没有好坏之分,只有适合与不适合之分,满足当前业务系统需求的存储方式就是最好的存储方式。并不能说Ceph对象存储就一定比TFS、HDFS、FastDFS优秀。这就好像现在机械硬盘已经存在这么多年了,磁带仍然没有消失的原因,因为它用一种最廉价的方式解决了大容量离线数据的存储问题,尽管它是很慢的。















 2433
2433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









