






哈希的基础知识
在了解一致性哈希算法之前先介绍下哈希的基础知识,有助于后续进阶到具体算法的理解
哈希
哈希(Hash)也称为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,这个输出值就是散列值。
哈希表
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希算法
在介绍一致性哈希算法之前先看简单的取模哈希算法
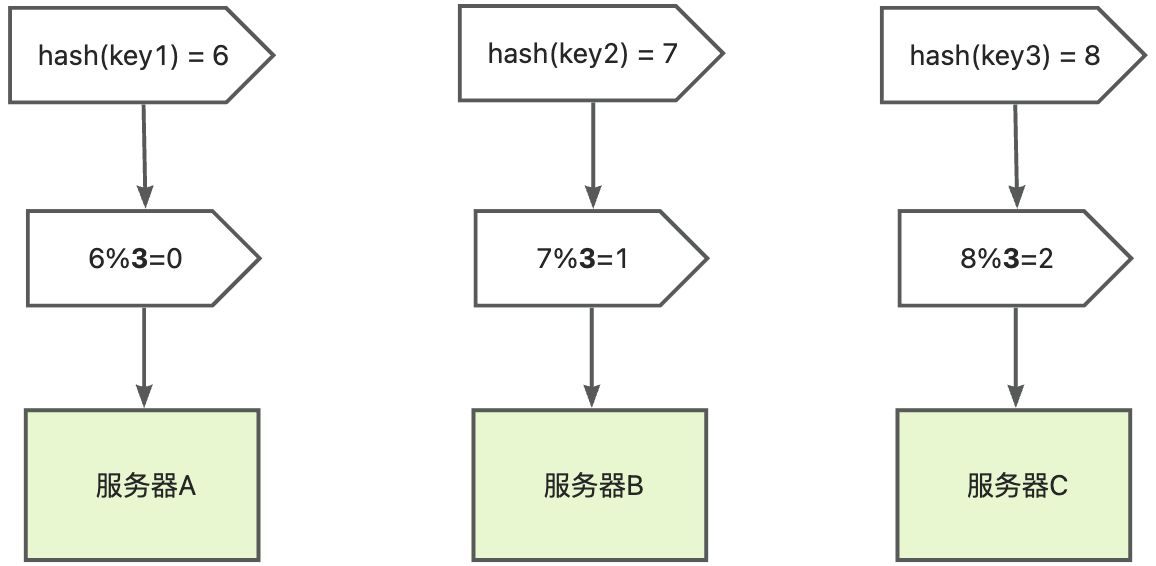
场景:假设现在有三台服务器(分别编号A、B、C)和3000w个key,需要将3000w个key能均匀的分布在这三台机器上,可能想到的方案是 取模算法 hash(key)%n 即:对key进行hash运算后取模,N是服务器的数量
这样对3取模之后的结果一定是 0、1、2,可以分别对应机器A、B、C 刚好达到数据的均匀分布

当需要查询目标数据时,也是通过同样的hash算法定位数据存储的目标服务器:
- 计算hash值
- 取模
- 定位目标服务器
局限
当业务流量突增数据变多,三台服务器已经无法承载量级时,就需要增加服务器数量,服务器数量从3变成了4,那么hash函数就变成了:hash(key)%4,此时再看上述场景,计算后得到的目标服务器大多数都会发生变化,之前缓存的数据就会失效。如下图:
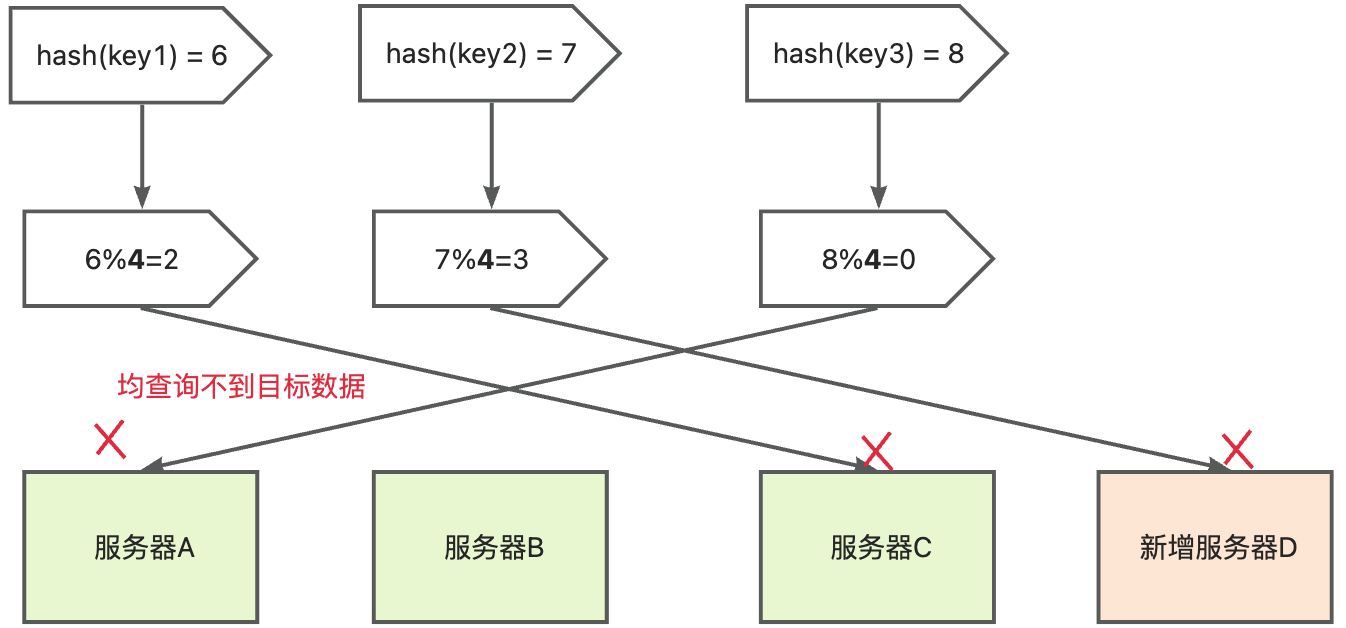
此时就需要将所有缓存数据做迁移, 当大量缓存在同一时间失效,包含非常多热点数据,则会造成缓存雪崩,进而导致整个系统的不可用,这是绝对无法接受的!
如上述的集群扩容,集群收缩也是同样的情况,所以这种对机器数量取模的hash函数,在集群扩容和收缩时都有非常大的局限性,为了解决该问题,一致性哈希算法应运而生~
一致性哈希算法
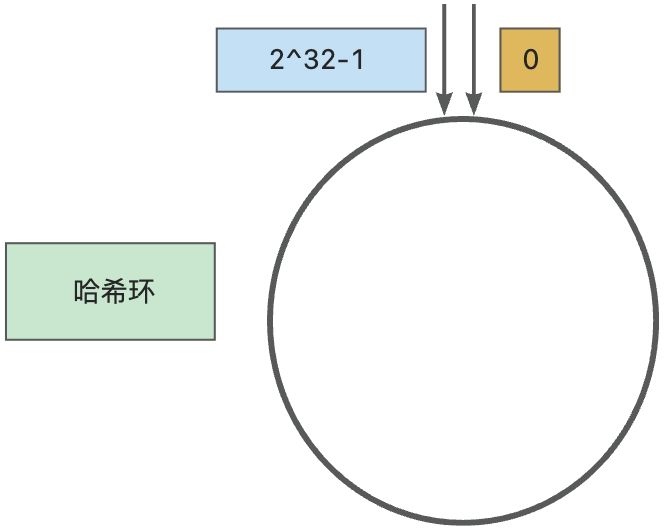
一致性哈希算法本质上也是取模,不过不是对服务器的数量取模,而是对固定值(2^32)进行取模 : hash(key)%2^32
IPv4的地址是4组8位2进制数组成,所以用2^32可以保证每个IP地址会有唯一的映射;
把2^32 抽象成一个环,即hash环:存储节点和数据都会经过hash函数映射到这个收尾相连的hash环中
一致性hash需要有两步hash:
- 对存储节点做hash,也就是对存储数据的服务器的ip地址做哈希,均会落入哈希环中(上面也讲过用2^32可以保证每个ip地址都会有唯一的映射)
- 对要存储的数据做hash,无论是数据的存储还是访问,都需要进行这一步骤
假设现在有三个节点,经过hash计算,映射到如下hash环中:
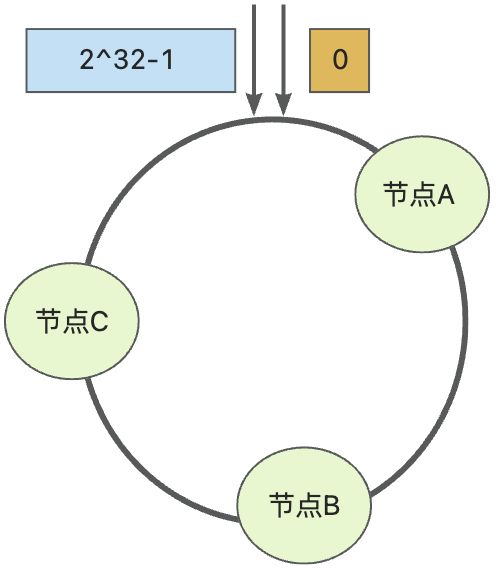
❓❓❓如何确定存储某个数据或访问某个数据的节点?
- 对key进行哈希计算出在哈希环中的位置
- 沿此位置顺时针找到第一个节点,即就是存储该key的服务器节点
假设数据key1、key2、key3经过hash函数计算之后落入哈希环的如下位置,那么按照如上描述的寻址策略则:
key1->节点A,key2->节点B,key3->节点C
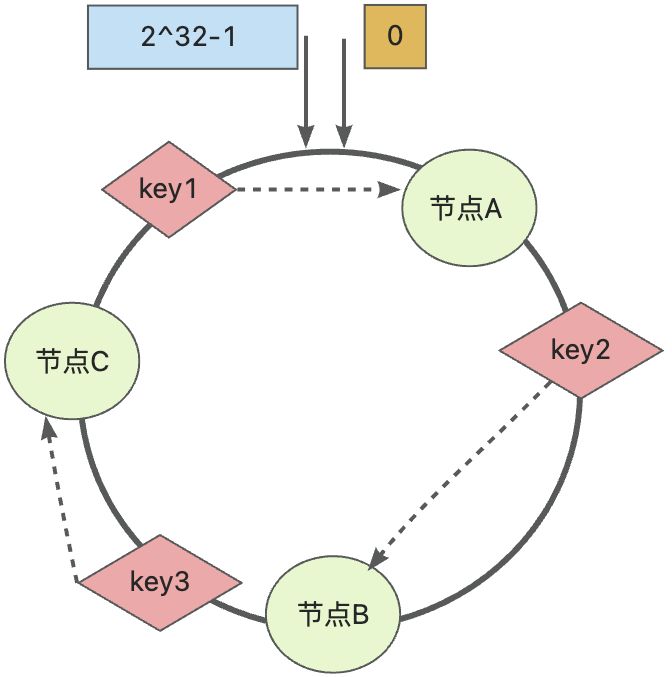
如何解决集群扩容和收缩时数据迁移的问题?
❓❓❓ 那么当集群扩容和收缩时,在该算法下就不会有数据失效?完全不用迁移数据吗?
结论先行:仍然需要迁移数据,不过并不是所有数据失效需要迁移,只是一部分数据需要迁移处理,只会影响哈希环上顺时针相邻的后继节点
📢📢📢扩容:当现在新增节点D时,如下图所示,只会将key2迁移至节点D上,为啥需要这样迁移?
迁移规则还是遵从上述的寻址规则,key2会沿着顺时针找到第一个节点就确定为其的数据存储结点,当新增节点D后,就会去节点D中查询key2数据,但是key依然存储在节点B中,所以需要将key2数据从节点B迁移到节点D中
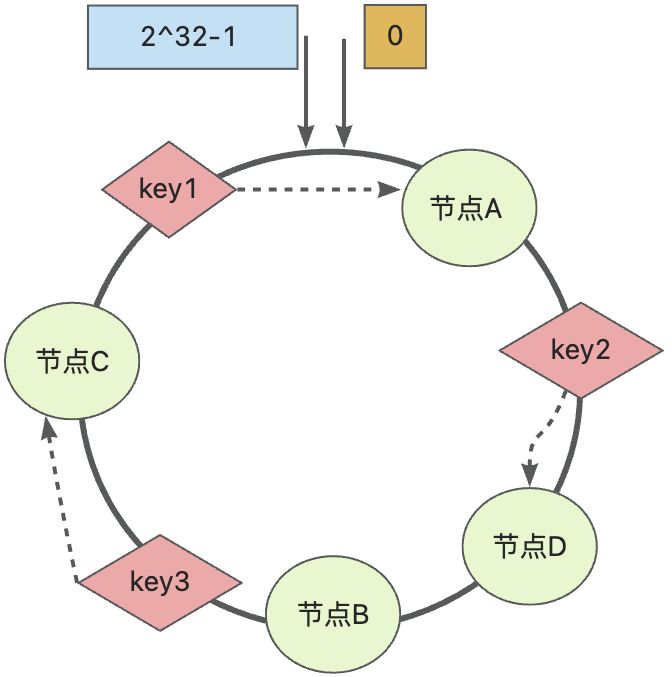
📢📢📢收缩:当下线节点B时,如下图所示,只会将key2迁移至节点C上,迁移规则何扩容同理
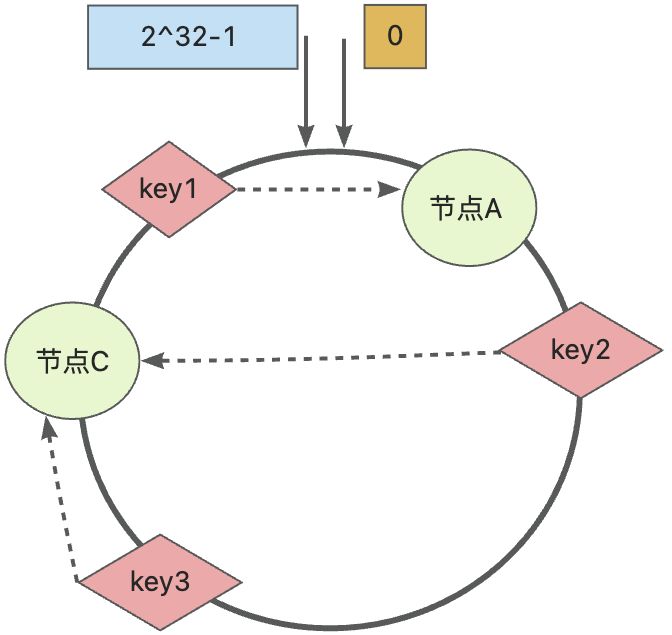
如何提高均衡度?
引入哈希算法是为了实现数据的均衡分配,但是当节点过少时,就会出现如下图所示的严重不均衡:
这种虽然有三个节点,但所有数据都存储在节点C上,一点也不均衡,当集群扩容或收缩时,受影响的数据过多,相当于退化为了普通哈希,如果节点C被移除了,那么根据规则节点C上的数据就会迁移到节点B上,若数据量过多超过了节点B的处理上限,那么节点B就会出问题,以此类推可能出现一连串的系统瓶颈问题,直到整个系统瘫痪
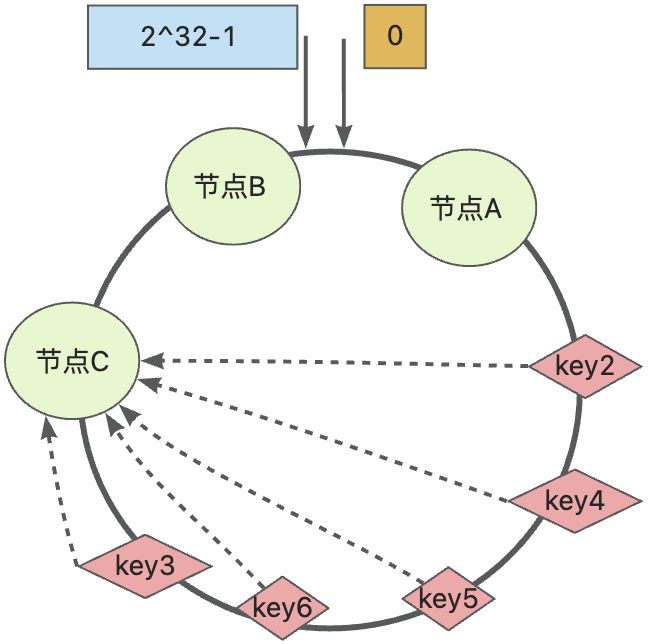
其实这个问题只有当节点过少的时候才会出现,如果节点很多,那么节点在整个hash环上的分布就会比较均匀,那么数据的分布也会变得均衡,所以就需要加入大量的节点,但在实际场景中,很难避免节点很多的情况,所以就加入了虚拟节点,即真实节点的副本
不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,虚拟节点再映射到真实节点上,所以这里有两层映射关系:真实节点 <-> 虚拟节点 <-> 哈希环
数据寻址步骤:数据 -> 哈希环 -> 虚拟节点 -> 真实节点
比如对每个节点分别设置 3 个虚拟节点:
- 对节点 A 加上编号来作为虚拟节点:A1、A2、A3
- 对节点 B 加上编号来作为虚拟节点:B1、B2、B3
- 对节点 C 加上编号来作为虚拟节点:C1、C2、C3
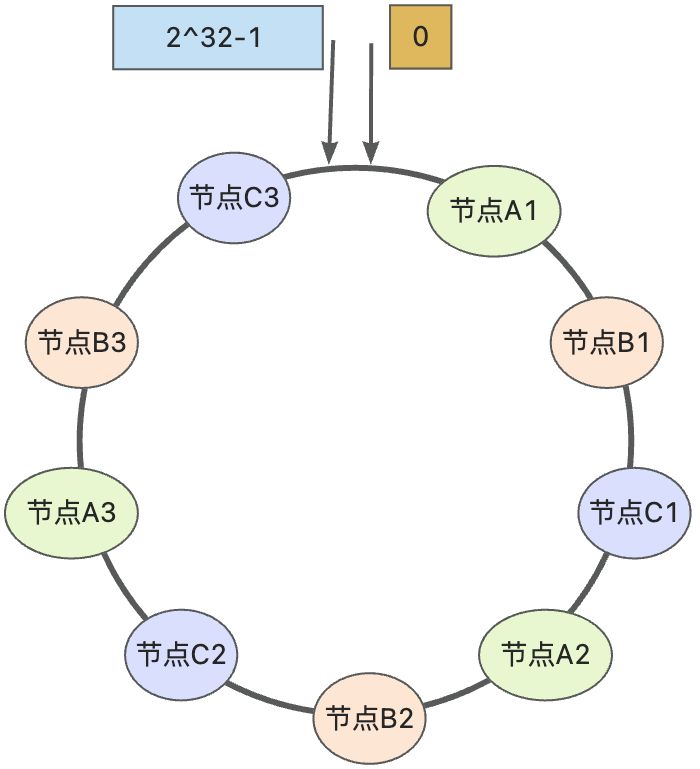
如图所示,通过增加虚拟节点即可使得节点均匀的分布在哈希环上,从而使得数据均匀分配。
另外我设置3个虚拟节点只是举个栗子,在大部分实际场景中,3个还是远远不够的,请大家以实际应用场景而定

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









