






一.数据操作
二.数据完整性约束
三.达梦数据库单表查询
四.达梦数据库多表查询
五.达梦数据库备份与还原
六.达梦数据库总结
一.数据操作
1.数据插入
(1)插入单条数据
基本语法
INSERT INTO table_name (column1, column2, column3,...)
VALUES (value1, value2, value3,...);
其中,table_name 是要插入数据的表名,column1, column2, column3,... 是要插入值的列名,value1, value2, value3,... 是对应列要插入的具体值 。
示例
假设你有一个名为 employees 的表,包含 id、name、age 和 department 四个列,要插入一条员工信息,可以这样写:
其中,table_name 是要插入数据的表名,column1, column2, column3,... 是要插入值的列名,value1, value2, value3,... 是对应列要插入的具体值 。
INSERT INTO employees (id, name, age, department)
VALUES (1, 'John Doe', 30, 'Sales');
(2)插入多条数据
基本语法
INSERT INTO table_name (column1, column2, column3,...)
VALUES
(value1_1, value1_2, value1_3,...),
(value2_1, value2_2, value2_3,...),
(value3_1, value3_2, value3_3,...), ...;
示例
INSERT INTO employees (id, name, age, department)
VALUES
(2, 'Jane Smith', 25, 'Marketing'),
(3, 'Bob Johnson', 35, 'Engineering'),
(4, 'Alice Williams', 28, 'Finance');
(3)从其他表中插入数据
基本语法:使用 INSERT INTO...SELECT... 语句
INSERT INTO table_name1 (column1, column2, column3,...)
SELECT column1, column2, column3,...
FROM table_name2 WHERE condition;
此语句从 table_name2 中选择满足 condition 的数据,并将其插入到 table_name1 中对应的列。示例
假设有一个名为 employees_temp 的临时表,结构与 employees 表相同,现在要将 employees_temp 中满足一定条件的员工数据插入到 employees 表中,可以这样写:
INSERT INTO employees (id, name, age, department)
SELECT id, name, age, department
FROM employees_temp WHERE age > 25;
(4)使用默认值插入数据
如果表中的某些列定义了默认值,在插入数据时可以不指定这些列的值,数据库会自动使用默认值插入。
示例
假设 employees 表中的 department 列定义了默认值为 'General',插入数据时可以这样写:
INSERT INTO employees (id, name, age)
VALUES (5, 'Tom Brown', 22);
在这条语句中,没有为 department 列指定值,数据库会自动将默认值 'General' 插入该列 。
2.数据更新
基本语法
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
其中,table_name 是要更新数据的表名;column1 = value1, column2 = value2,... 是要更新的列及其对应的新值;WHERE condition 是一个可选的筛选条件,用于指定要更新哪些行,如果不写 WHERE 条件,则会更新表中的所有行 。
示例
假设你有一个名为 employees 的表,包含 id、name、age 和 department 等列,现在要将 id 为 1 的员工的年龄更新为 35,可以使用以下语句:
UPDATE employees
SET age = 35
WHERE id = 1;
3.删除数据
基本语法
DELETE FROM table_name
WHERE condition;
其中,table_name 是要删除数据的表名,WHERE condition 是一个可选的筛选条件,用于指定要删除哪些行,如果不写 WHERE 条件,则会删除表中的所有行。
示例
如果要删除 employees 表中 id 为 2 的员工记录,可以使用以下语句:
DELETE FROM employees
WHERE id = 2;
二.数据完整性约束
1.域完整性
(1)使用数据类型约束
定义合适的数据类型:在创建表时,为每列指定恰当的数据类型,如 INT 用于存储整数,VARCHAR 用于存储可变长度字符串,DATE 用于存储日期等。达梦数据库会根据数据类型自动限制可存储的数据范围和格式。
CREATE TABLE students (
id INT,
name VARCHAR(50),
birth_date DATE );
(2)设置非空约束
确保列值非空:使用 NOT NULL 关键字来指定列不允许为空值。这样在插入或更新数据时,如果该列没有提供值,数据库将报错。
CREATE TABLE employees (
id INT,
name VARCHAR(50) NOT NULL,
age INT );
(3)运用默认值约束
设置默认值:通过 DEFAULT 关键字为列设置默认值。当插入数据时如果未指定该列的值,数据库会自动使用默认值填充。
CREATE TABLE orders (
order_id INT,
order_date DATE DEFAULT SYSDATE,
total_amount DECIMAL(10,2) );
(4)实施唯一性约束
保证列值唯一:使用 UNIQUE 关键字来确保列中的值在表内是唯一的。这可以防止插入重复的值。
CREATE TABLE users (
user_id INT,
username VARCHAR(50) UNIQUE,
password VARCHAR(50) );
(5)添加检查约束
定义取值范围或条件:利用 CHECK 关键字来定义列的取值范围或其他条件。只有满足检查约束条件的数据才能被插入或更新到表中。
CREATE TABLE products (
product_id INT,
product_name VARCHAR(50),
price DECIMAL(10,2) CHECK (price >= 0),
stock_quantity INT CHECK (stock_quantity >= 0) );
(6)使用外键约束
维护表间数据的关联性和一致性:在创建表时通过 FOREIGN KEY 关键字来定义外键,确保子表中的外键值必须在主表的主键值范围内,从而维护了表间数据关联的准确性和域完整性 。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id) );
CREATE TABLE customers ( customer_id INT PRIMARY KEY,
customer_name VARCHAR(50) );
2.实体完整性
(1)使用主键约束
主键的定义:主键是表中的一个或多个字段,其值能够唯一标识表中的每一行记录。在达梦数据库中,通过定义主键约束来确保实体完整性。
创建表时定义主键
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50), age INT );
在上述示例中,id 字段被定义为主键,这意味着 id 字段的值在 employees 表中必须是唯一的,且不能为空,以此来保证每条员工记录的唯一性和可识别性。
为已存在的表添加主键
ALTER TABLE employees
ADD CONSTRAINT pk_employees_id PRIMARY KEY (id);
此语句用于为已创建的 employees 表添加主键约束,其中 pk_employees_id 是主键约束的名称,可根据实际需求自定义,(id) 表示将 id 字段设置为主键。
(2)使用唯一约束
唯一约束的定义:唯一约束确保表中的一个或多个字段的值在表内是唯一的,类似于主键约束,但唯一约束允许字段为空值,且一个表可以有多个唯一约束。
创建表时定义唯一约束
CREATE TABLE students (
student_id INT,
student_name VARCHAR(50) UNIQUE,
major VARCHAR(50) );
在这个例子中,student_name 字段上定义了唯一约束,这就保证了在 students 表中不会出现两个学生的姓名完全相同的情况,从而实现了实体完整性的一部分要求,即通过该字段的值可以唯一区分部分学生记录。
为已存在的表添加唯一约束
ALTER TABLE students
ADD CONSTRAINT uk_student_name UNIQUE (student_name);
这里为已有的 students 表添加了一个名为 uk_student_name 的唯一约束,作用于 student_name 字段上。
3.参照完整性
(1)创建表时定义外键约束
在创建表时,可以使用FOREIGN KEY关键字来定义外键约束,以下是一个示例:
-- 创建主表
CREATE TABLE departments (
department_id INT PRIMARY KEY,
department_name VARCHAR(50) );
-- 创建从表,并定义外键约束
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50), department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id) );
在上述示例中,departments表是主表,其中的department_id字段是主键。employees表是从表,其中的department_id字段是外键,通过FOREIGN KEY约束与主表departments的department_id主键相关联,从而确保employees表中的department_id值必须在departments表的department_id值范围内,实现了参照完整性 。
(2)为已存在的表添加外键约束
如果表已经创建,也可以使用ALTER TABLE语句来添加外键约束,示例如下:
-- 假设已经存在departments表和employees表,且employees表中已有department_id字段,但未设置外键约束
-- 为employees表添加外键约束
ALTER TABLE employees
ADD CONSTRAINT fk_employees_departments
FOREIGN KEY (department_id) REFERENCES departments(department_id);
此语句为employees表添加了一个名为fk_employees_departments的外键约束,将department_id字段与departments表的department_id主键建立了关联,保证了数据的参照完整性。
(3)外键约束的其他选项
级联操作:可以在定义外键约束时指定级联操作,如ON DELETE CASCADE表示当主表中的记录被删除时,从表中与之相关的记录也会自动被删除;ON UPDATE CASCADE表示当主表中的记录被更新时,从表中与之相关的记录也会自动被更新。示例如下:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id) ON DELETE CASCADE ON UPDATE CASCADE );
设置外键约束的名称:在创建外键约束时,可以为其指定一个名称,以便于后续的管理和识别,如上述示例中的fk_employees_departments。
指定外键字段和主键字段的对应关系:当外键字段和主键字段名称不一致时,需要明确指定它们的对应关系。例如,如果employees表中的外键字段是dept_id,而departments表中的主键字段是department_id,则可以这样定义外键约束:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
dept_id INT, FOREIGN KEY (dept_id) REFERENCES departments(department_id) );
三.达梦数据库单表查询
1.基础查询
(1)选择特定列查询
你可以使用 SELECT 语句选择表中的特定列进行查询,语法格式为:SELECT 列名1, 列名2,... FROM 表名;。例如,从名为 employees 的表中查询员工的姓名和年龄:
SELECT name, age FROM employees;
(2)查询所有列
若要查询表中的所有列,可以使用通配符 *,语法为:SELECT * FROM 表名; 。例如:
SELECT * FROM employees;
(3)条件查询
使用 WHERE 子句可以设置查询条件,筛选出符合条件的数据。例如,从 employees 表中查询年龄大于 30 岁的员工:
SELECT * FROM employees WHERE age > 30;
(4)排序查询
通过 ORDER BY 子句可以对查询结果按照指定列进行排序。排序方式有升序(ASC,默认)和降序(DESC)两种。例如,对 employees 表中的员工按照年龄升序排列:
SELECT * FROM employees ORDER BY age ASC;
若要按照多个列进行排序,可以在 ORDER BY 子句中列出多个列名,用逗号分隔。例如,先按照部门排序,再按照年龄排序:
SELECT * FROM employees ORDER BY department, age;
(5)去重查询
如果想要查询结果中不包含重复的数据,可以使用 DISTINCT 关键字。例如,从 employees 表中查询所有不同的部门:
SELECT DISTINCT department FROM employees;
(6)限制查询结果数量
使用 LIMIT 子句可以限制查询结果返回的数量。例如,从 employees 表中查询前 5 条记录:
SELECT * FROM employees LIMIT 5;
(7)聚合函数查询
达梦数据库提供了多种聚合函数,如 SUM(求和)、AVG(求平均值)、COUNT(计数)、MAX(求最大值)、MIN(求最小值)等,用于对数据进行统计分析。例如,计算 employees 表中所有员工的平均年龄:
SELECT AVG(age) FROM employees;
计算员工的总人数:
SELECT COUNT(*) FROM employees;
2.条件查询
(1)比较运算符
等于(=):用于精确匹配某个值。例如,从 employees 表中查询出工资等于5000的员工:
SELECT * FROM employees WHERE salary = 5000;
不等于(<> 或!=):用于筛选出与指定值不相等的记录 。例如,查询工资不等于5000的员工:
SELECT * FROM employees WHERE salary <> 5000;
大于(>)和小于(<):用于比较数值大小。比如,查询年龄大于30岁的员工:
SELECT * FROM employees WHERE age > 30;
大于等于(>=)和小于等于(<=):类似大于和小于,包含等于的情况。例如,查询工资在4000到6000之间的员工:
SELECT * FROM employees WHERE salary >= 4000 AND salary <= 6000;
(2)逻辑运算符
AND:表示多个条件同时成立。例如,查询年龄在25到35岁之间且工资大于4000的员工:
SELECT * FROM employees WHERE age >= 25 AND age <= 35 AND salary > 4000;
OR:表示多个条件中只要有一个成立即可。比如,查询年龄小于25岁或者工资大于5000的员工:SELECT * FROM employees WHERE age < 25 OR salary > 5000;
NOT:用于取反条件。例如,查询工资不低于3000的员工:
SELECT * FROM employees WHERE NOT salary < 3000;
(3)特殊运算符
BETWEEN:用于指定一个取值范围,包含边界值。例如,查询年龄在20到30岁之间的员工:
SELECT * FROM employees WHERE age BETWEEN 20 AND 30;
IN:用于判断某个值是否在指定的集合中。例如,查询部门为 '销售部' 或 '市场部' 的员工:
SELECT * FROM employees WHERE department IN ('销售部', '市场部');
LIKE:用于模糊匹配字符串。它支持通配符 %(表示任意多个字符)和 _(表示单个字符)。例如,查询姓名中包含 '张' 的员工:
SELECT * FROM employees WHERE name LIKE '%张%';
IS NULL 和 IS NOT NULL:用于判断某个字段是否为空值。例如,查询没有填写电话号码的员工:SELECT * FROM employees WHERE phone_number IS NULL;
3.高级查询
(1)子查询
子查询是指在一个查询语句中嵌套另一个查询语句。内层查询的结果可以作为外层查询的条件或数据源。
作为条件的子查询:例如,要查询工资高于平均工资的员工信息,可以先使用子查询计算出平均工资,再将其作为外层查询的条件。
SELECT * FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
作为数据源的子查询:可以将子查询的结果作为一个临时表,供外层查询使用。例如,从一个包含员工信息和部门信息的表中,先通过子查询找出每个部门的平均工资,再根据这个结果查询出平均工资高于 5000 的部门的员工信息。
SELECT *
FROM employees
WHERE department IN
(SELECT department
FROM (SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department) AS temp
WHERE avg_salary > 5000);
(2)分组查询
使用 GROUP BY 子句可以按照一个或多个列对数据进行分组,然后可以对每个分组进行聚合操作。
基本分组查询:例如,要统计每个部门的员工人数,可以使用以下查询语句。
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department;
分组筛选:使用 HAVING 子句可以对分组后的结果进行筛选。例如,要查询员工人数大于 5 人的部门,可以在分组查询的基础上添加 HAVING 子句。
SELECT department, COUNT(*) AS
employee_count
FROM employees
GROUP BY department HAVING COUNT(*) > 5;
(3)连接查询
连接查询用于将多个表中的数据按照一定的条件进行关联和合并。虽然这里讨论的是单表查询,但在某些情况下,可以将一个表与自身进行连接查询,以实现一些特殊的需求。
自连接:例如,在一个存储员工信息和上级领导信息的表中,如果要查询每个员工及其直接上级的姓名,可以使用自连接。
SELECT e.name AS employee_name, m.name
AS manager_name FROM employees e
JOIN employees m ON e.manager_id = m.employee_id;
(4)窗口函数查询
窗口函数用于在查询结果的基础上进行额外的计算和分析,它可以在不改变原始查询结果集的情况下,为每一行数据添加一个或多个计算列。
基本窗口函数:例如,要查询每个员工的工资以及该员工所在部门的平均工资,可以使用窗口函数。
SELECT name, salary, AVG(salary) OVER (PARTITION BY department) AS avg_department_salary FROM employees;
排序窗口函数:窗口函数还可以与排序结合,实现一些复杂的分析需求。例如,要查询每个员工在其所在部门中的工资排名,可以使用以下查询语句。
SELECT name, salary, RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS salary_rank FROM employees;
(5)分页查询
当查询结果集较大时,为了方便查看和管理,可以使用分页查询,每次只返回一部分数据。达梦数据库支持 LIMIT 子句来实现分页查询。
基本分页查询:例如,每页显示 10 条记录,要查询第 2 页的记录,可以使用以下查询语句。
SELECT * FROM employees LIMIT 10 OFFSET 10;
其中,OFFSET 关键字用于指定偏移量,表示从结果集的第几行开始返回
4.分组查询
(1)基本语法
分组查询的基本语法是在 SELECT 语句中使用 GROUP BY 子句。GROUP BY 子句后面跟着要分组的列名或列表达式。例如,从 employees 表中按照部门 department 对员工进行分组:
SELECT department
FROM employees
GROUP BY department;
上述查询会返回 employees 表中所有不同的部门名称,每个部门名称只出现一次,相同部门的员工被归为一组。
(2)聚合函数的使用
分组查询通常与聚合函数一起使用,以对每个分组进行计算和统计。常用的聚合函数包括:
COUNT(*):计算每个分组中的行数,即该分组的记录数。例如,统计每个部门的员工人数:
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department;
SUM(column_name):计算每个分组中指定列的总和。例如,计算每个部门的工资总和:
SELECT department, SUM(salary) AS total_salary
FROM employees
GROUP BY department;
AVG(column_name):计算每个分组中指定列的平均值。例如,计算每个部门的平均工资:
SELECT department, AVG(salary) AS average_salary
FROM employees
GROUP BY department;
MAX(column_name) 和 MIN(column_name):分别获取每个分组中指定列的最大值和最小值。例如,找出每个部门中工资最高和最低的员工:
SELECT department, MAX(salary) AS max_salary, MIN(salary) AS min_salary
FROM employees
GROUP BY department;
(3)多列分组
可以按照多个列对数据进行分组,只需在 GROUP BY 子句中列出多个列名,用逗号分隔。例如,按照部门和性别对员工进行分组,统计每个部门男女员工的人数:
SELECT department, gender, COUNT(*)
AS employee_count FROM employees
GROUP BY department, gender;
(4)分组筛选
使用 GROUP BY 进行分组后,可以使用 HAVING 子句对分组后的结果进行筛选,以过滤掉不符合条件的分组。HAVING 子句与 WHERE 子句类似,但 WHERE 子句是在分组之前对原始数据进行筛选,而 HAVING 子句是在分组之后对分组结果进行筛选。例如,查询员工人数大于 5 人的部门:
SELECT department, COUNT(*) AS employee_count
FROM employees
GROUP BY department HAVING COUNT(*) > 5;
(5)分组排序
虽然 GROUP BY 子句本身主要用于分组,而不是排序,但可以在分组查询的基础上使用 ORDER BY 子句对分组结果进行排序。例如,按照部门的员工平均工资对部门进行排序:
SELECT department, AVG(salary) AS average_salary
FROM employees
GROUP BY department
ORDER BY average_salary DESC;
四.达梦数据库多表查询
- 连接查询
- 内连接(INNER JOIN)
- 内连接返回两个表中满足连接条件的行。例如,有两张表
表A(id, name)和表B(id, age),通过id字段进行连接,查询同时存在于两张表中的记录。 - 示例代码如下:
- 内连接返回两个表中满足连接条件的行。例如,有两张表
- 内连接(INNER JOIN)
SELECT 表A.name, 表B.age
FROM 表A
INNER JOIN 表B ON 表A.id = 表B.id;
- 左连接(LEFT JOIN)
- 左连接返回左表中的所有行以及右表中满足连接条件的行。如果右表中没有匹配的行,则对应的列显示为
NULL。 - 假设还是上述的
表A和表B,示例代码如下:
- 左连接返回左表中的所有行以及右表中满足连接条件的行。如果右表中没有匹配的行,则对应的列显示为
SELECT 表A.name, 表B.age
FROM 表A
LEFT JOIN 表B ON 表A.id = 表B.id;
- 右连接(RIGHT JOIN)
- 右连接与左连接相反,它返回右表中的所有行以及左表中满足连接条件的行。如果左表中没有匹配的行,则对应的列显示为
NULL。 - 示例代码如下:
- 右连接与左连接相反,它返回右表中的所有行以及左表中满足连接条件的行。如果左表中没有匹配的行,则对应的列显示为
SELECT 表A.name, 表B.age
FROM 表A
RIGHT JOIN 表B ON 表A.id = 表B.id;
- 全连接(FULL JOIN)
- 全连接返回左右表中的所有行。如果某一行在另一个表中没有匹配的行,则对应的列显示为
NULL。不过达梦数据库可能不直接支持FULL JOIN关键字,你可以通过UNION来模拟全连接。 - 示例代码如下:
- 全连接返回左右表中的所有行。如果某一行在另一个表中没有匹配的行,则对应的列显示为
SELECT 表A.name, 表B.age
FROM 表A
LEFT JOIN 表B ON 表A.id = 表B.id
UNION
SELECT 表A.name, 表B.age
FROM 表A
RIGHT JOIN 表B ON 表A.id = 表B.id;
2.子查询
- 标量子查询
- 标量子查询返回单个值,它可以用在
SELECT、WHERE、HAVING等子句中。例如,查询表A中年龄大于平均年龄的人员信息,先通过子查询计算平均年龄,再在主查询中使用这个结果。 - 假设
表A(id, name, age),示例代码如下:
- 标量子查询返回单个值,它可以用在
SELECT *
FROM 表A
WHERE age > (SELECT AVG(age) FROM 表A);
- 列子查询
- 列子查询返回一列值,它通常用在
WHERE子句的IN、ANY、ALL等操作符中。例如,查询表A中id在另一个查询结果集中的记录。 - 假设有
表B(id),示例代码如下:
- 列子查询返回一列值,它通常用在
SELECT *
FROM 表A
WHERE id IN (SELECT id FROM 表B);
- 行子查询
- 行子查询返回一行数据,它用于比较多个列的值。例如,查询
表A中与某一行数据匹配的记录。 - 假设
表A(id, name, age),示例代码如下:
- 行子查询返回一行数据,它用于比较多个列的值。例如,查询
SELECT *
FROM 表A
WHERE (id, age) = (SELECT 1, 20 FROM DUAL); //DUAL是一个虚拟表,这里只是示例,根据实际情况修改子查询返回值。
- 合并结果集(UNION 和 UNION ALL)
- UNION
UNION操作符用于合并两个或多个SELECT语句的结果集,它会去除重复的行。这些SELECT语句必须有相同数量的列,并且对应列的数据类型要兼容。- 例如,有
表A(id, name)和表C(id, address),将它们的部分列合并。 - 示例代码如下:
- UNION
SELECT id, name
FROM 表A
UNION
SELECT id, NULL AS name
FROM 表C;- UNION ALL
UNION ALL和UNION类似,但它不会去除重复的行,只是简单地将所有结果集合并在一起,因此在性能上可能比UNION更好,当你确定结果集中没有重复行或者不需要去重时可以使用。- 示例代码如下:
SELECT id, name
FROM 表A
UNION ALL
SELECT id, NULL AS name
FROM 表C;4.
- 将查询结果存入表中
- 创建新表并插入查询结果
- 可以使用
CREATE TABLE... AS SELECT...语句来创建一个新表并将查询结果插入其中。例如,将表A和表B连接后的结果存入一个新表表D。 - 示例代码如下:
- 可以使用
- 创建新表并插入查询结果
CREATE TABLE 表D AS
SELECT 表A.name, 表B.age
FROM 表A
INNER JOIN 表B ON 表A.id = 表B.id;
- 插入到已存在的表中
- 如果表已经存在,可以使用
INSERT INTO... SELECT...语句将查询结果插入已有的表中。假设表E(name, age)已经存在,将表A和表B连接后的结果插入表E。 - 示例代码如下:
- 如果表已经存在,可以使用
INSERT INTO 表E(name, age)
SELECT 表A.name, 表B.age
FROM 表A
INNER JOIN 表B ON 表A.id = 表B.id;
请注意,以上代码中的表名和列名等都是示例,你需要根据实际的数据库结构和需求进行修改。同时,达梦数据库在一些语法细节和函数使用上可能与其他数据库有差异,在实际应用中要参考达梦数据库的官方文档。
五.达梦数据库备份与还原
(一)、前言
(二)、数据库备份还原
1、使用DM控制台工具进行脱机备份还原

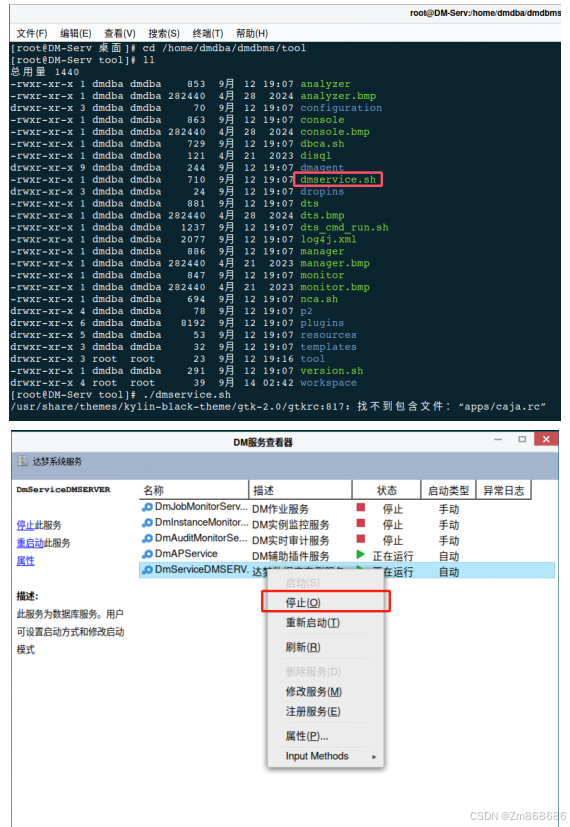
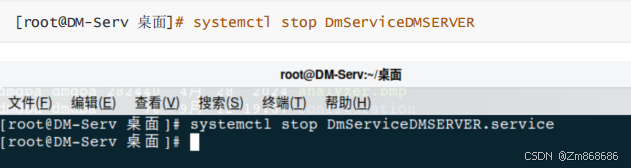
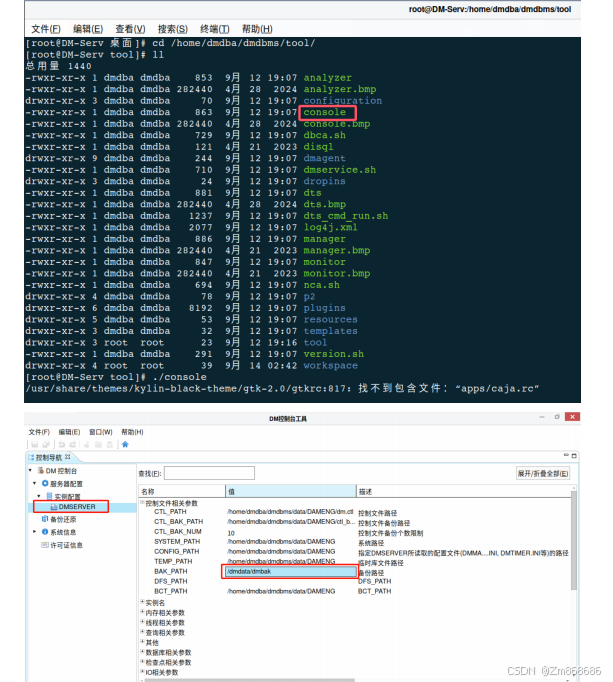
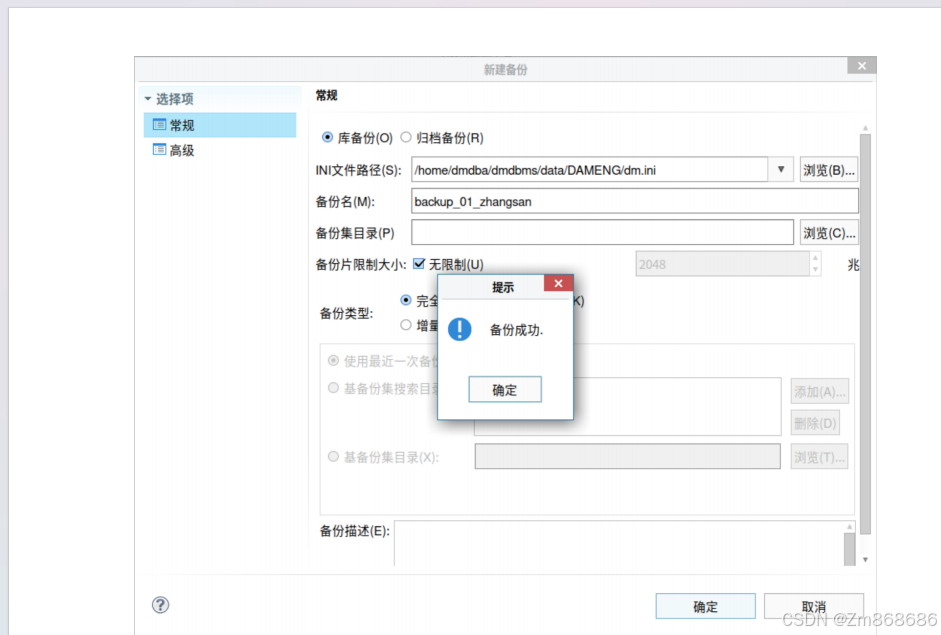
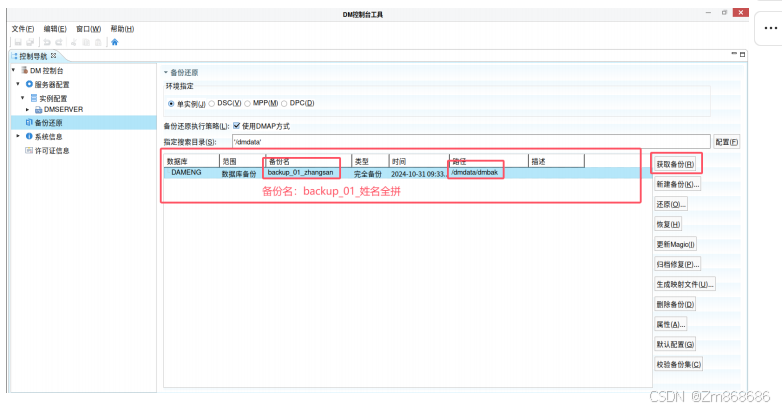
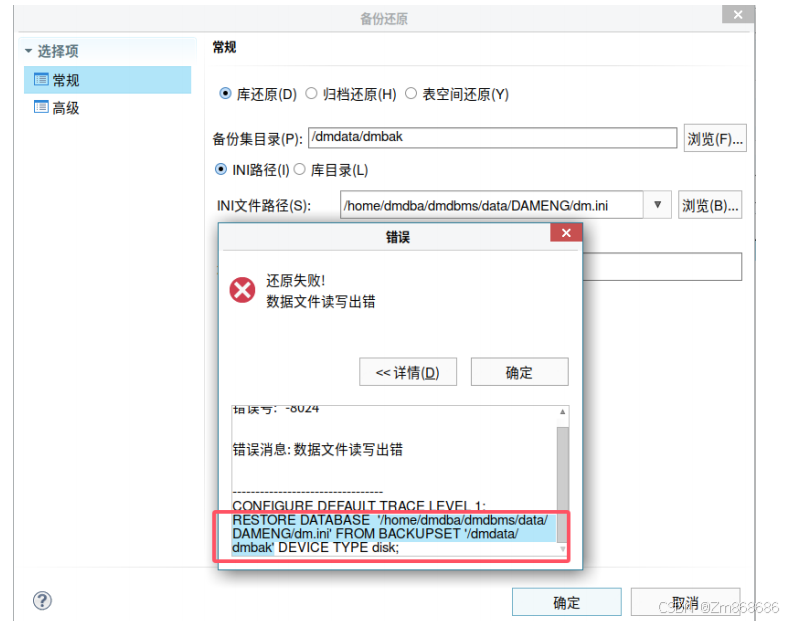
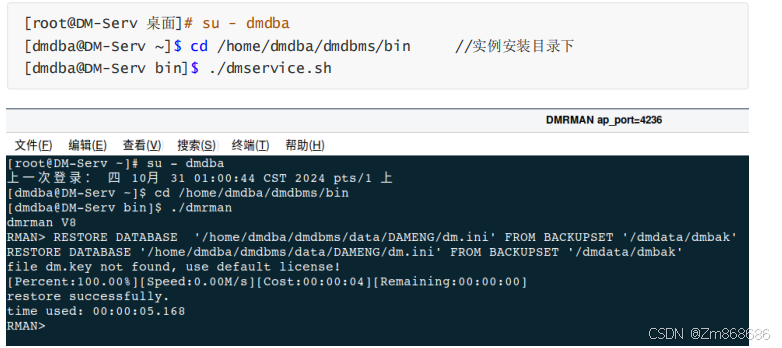
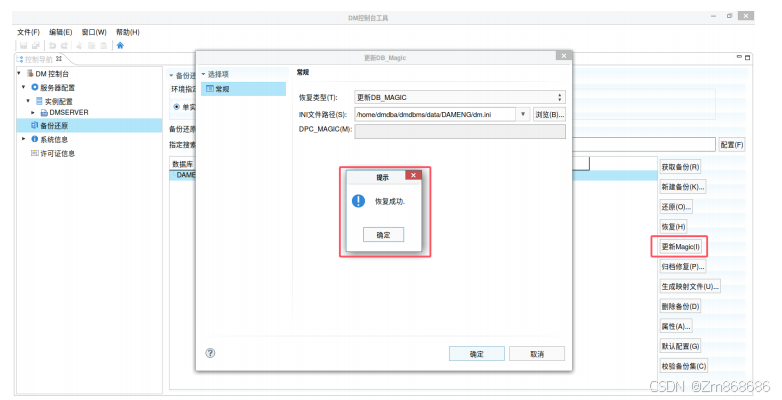
2、使用 DM 管理工具进行联机备份还原
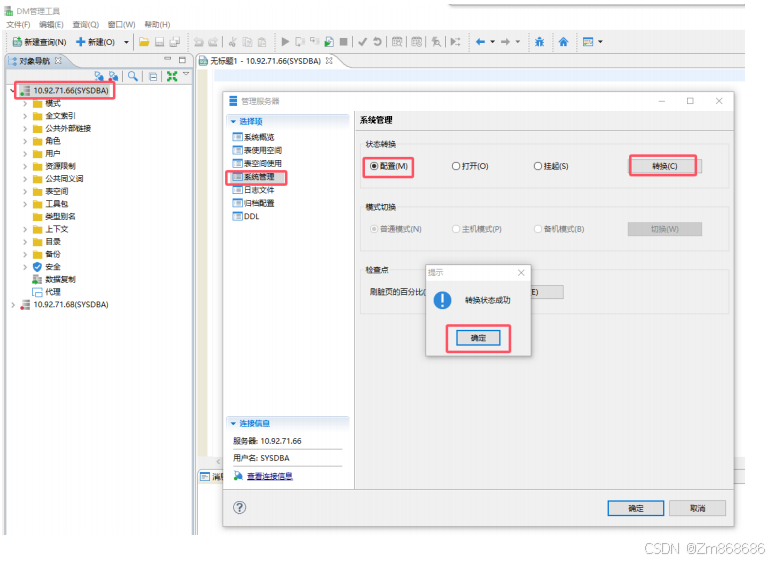
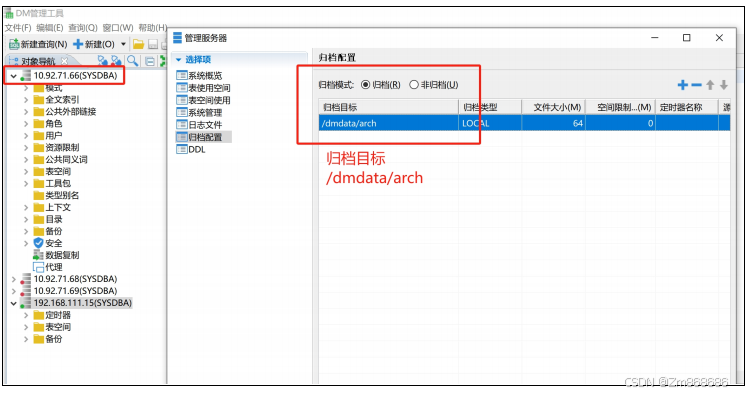
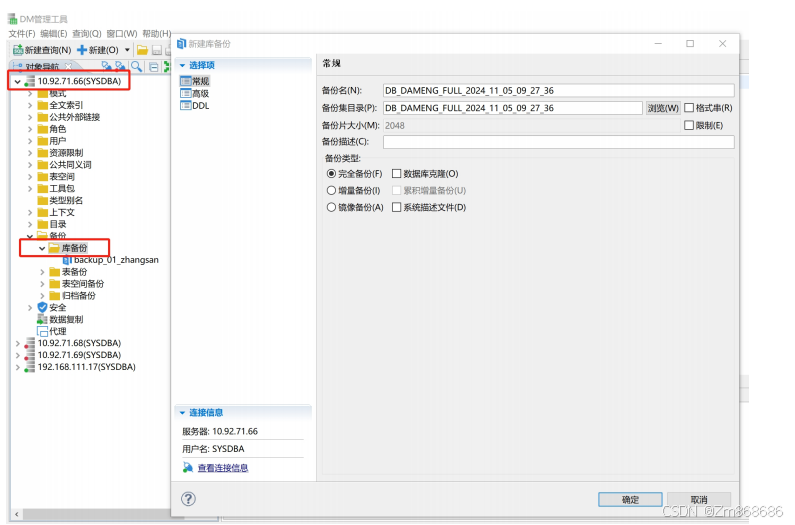
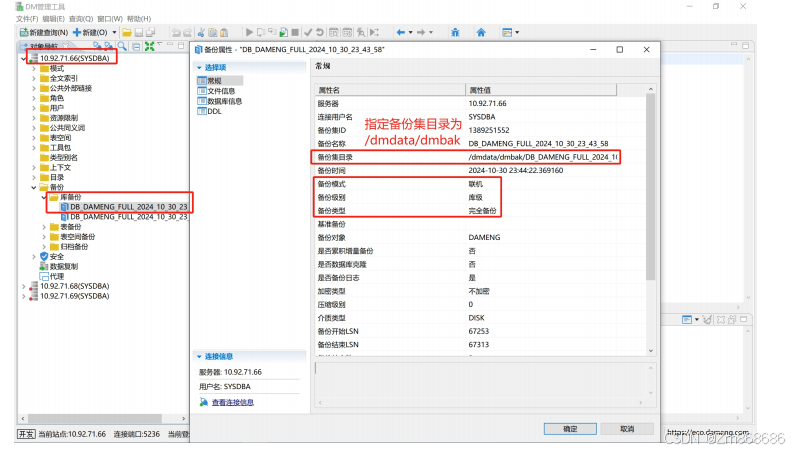
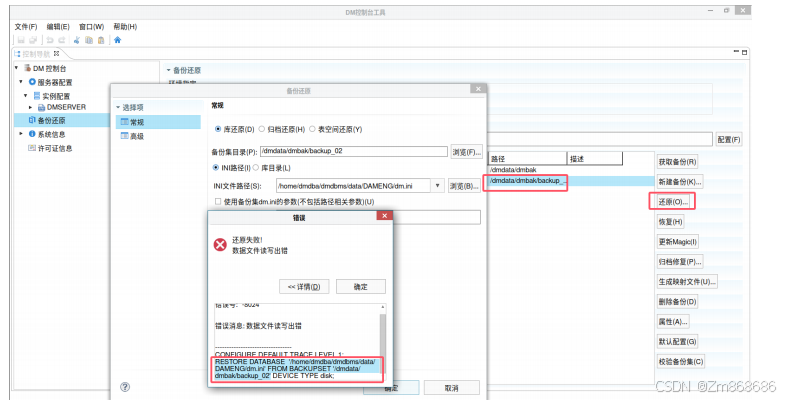
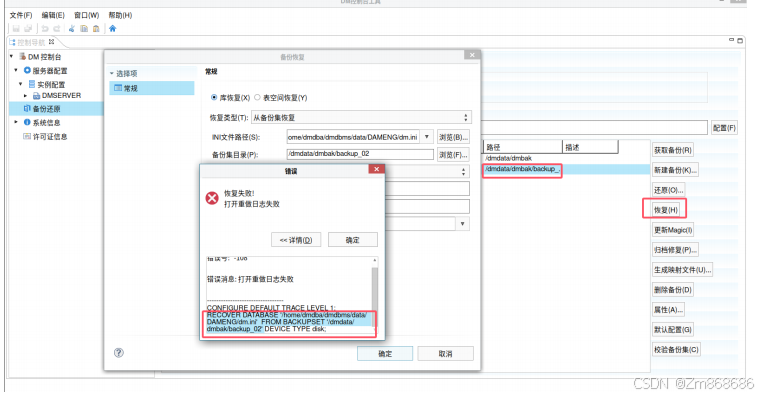
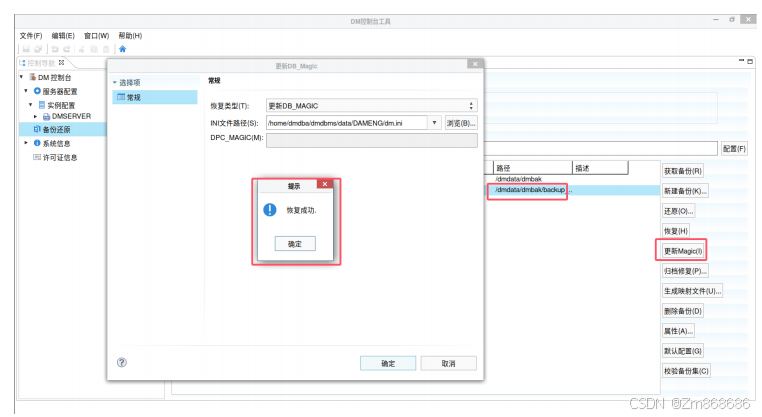
(三)、表空间备份还原
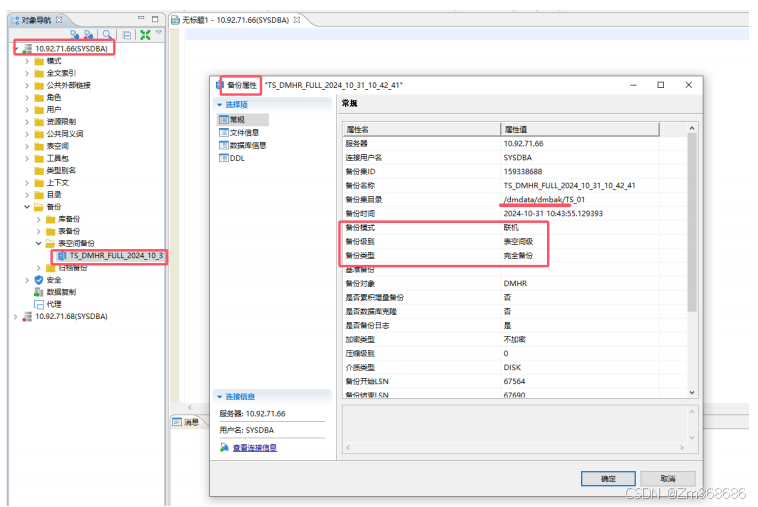
1、使用 DM 管理工具进行表空间备份还原
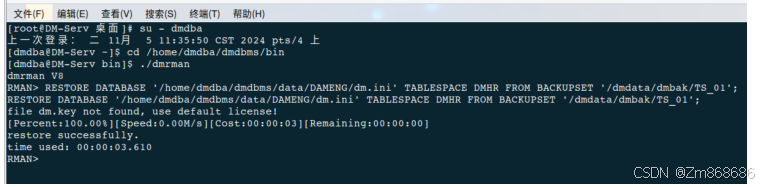
(四)、表备份还原
1、使用 DM 管理工具进行表备份还原
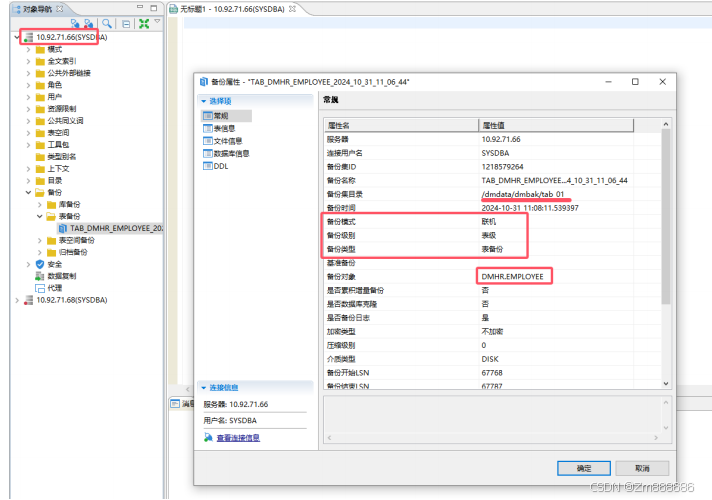
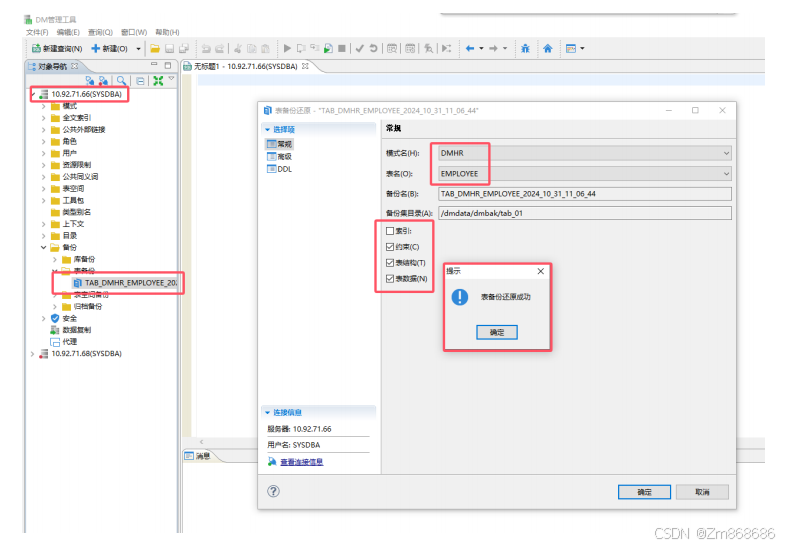
六.达梦数据库总结
特点
- 高性能
- 达梦数据库采用了多种优化技术,如查询优化器、缓存管理、存储引擎优化等,能够快速处理大量并发数据请求,满足企业级应用对高并发、低延迟的要求。
- 支持行存储和列存储两种存储模式,可以根据不同的应用场景选择合适的存储方式,进一步提高数据处理效率。
- 高可靠性
- 具备完善的备份与恢复机制,支持全量备份、增量备份、日志备份等多种备份方式,以及基于备份的即时恢复和时间点恢复功能,确保数据的安全性和可恢复性。
- 提供了数据复制、集群等功能,实现数据的冗余存储和故障自动切换,提高系统的可用性和容错能力。
- 兼容性好
- 支持多种操作系统,包括 Windows、Linux、Unix 等,方便在不同的平台上进行部署和使用。
- 对主流的编程语言和开发框架具有良好的兼容性,如 Java、C++、Python、.NET 等,便于开发人员进行应用开发。
- 遵循 SQL 标准,与其他主流数据库在语法和功能上有较高的相似性,降低了用户的学习成本和迁移成本。
- 功能丰富强大
- 支持多种数据类型,包括常规的数值型、字符型、日期型等,还支持大对象类型、空间数据类型、多媒体数据类型等特殊数据类型,满足不同应用领域的需求。
- 提供了丰富的数据库对象,如数据表、视图、存储过程、函数、索引、触发器等,支持复杂的数据库设计和应用开发。
- 具备强大的事务处理能力,支持 ACID 特性,保证数据的一致性和完整性。
- 安全性高
- 提供了多层次的安全机制,包括用户认证、权限管理、数据加密、审计等功能,防止数据泄露和非法访问。
- 支持国产密码算法,满足国内对信息安全的特殊要求。
应用场景
- 企业级应用
- 适用于各类企业的核心业务系统,如财务管理、人力资源管理、供应链管理、客户关系管理等,能够满足企业对数据处理和管理的高要求。
- 金融领域
- 在银行、证券、保险等金融机构中,可用于存储和处理大量的客户信息、交易数据、账务数据等,其高可靠性和安全性能够保障金融业务的稳定运行。
- 电子政务
- 政府部门的办公自动化系统、行政审批系统、电子证照系统等,使用达梦数据库可以实现数据的集中管理和高效共享,提高政务服务的效率和质量。
- 电信运营商
- 用于存储和管理用户信息、通话记录、流量数据等,其高性能和大规模数据处理能力能够满足电信业务的需求。
- 智能制造
- 在工业自动化、智能工厂等领域,可用于存储和分析生产设备数据、生产流程数据、质量检测数据等,为企业的生产决策提供支持。
发展历程与现状
- 达梦数据库的发展历程可以追溯到上世纪 80 年代,经过多年的技术积累和产品研发,不断推出新的版本和功能,产品逐渐成熟和完善。
- 目前,达梦数据库在国内市场已经取得了广泛的应用和认可,在政府、金融、电信、能源等关键领域拥有众多客户,市场份额逐年增长。同时,也在积极拓展海外市场,提升产品的国际竞争力。
挑战与机遇
- 面临的挑战
- 与国际知名数据库品牌相比,达梦数据库在品牌知名度和市场份额方面仍存在一定差距,需要进一步加强市场推广和品牌建设。
- 数据库技术发展迅速,需要不断投入研发资源,跟进技术发展趋势,如分布式数据库、大数据处理、人工智能等领域,以保持产品的竞争力。
- 生态系统相对薄弱,需要与更多的合作伙伴建立合作关系,完善产业链上下游的合作,共同推动达梦数据库的发展。
- 发展机遇
- 随着国家对信息技术自主创新的重视和支持,国产数据库迎来了良好的发展机遇,达梦数据库作为国产数据库的代表之一,有望获得更多的政策支持和市场机会。
- 数字化转型的加速推进,企业对数据的依赖程度越来越高,对数据库的需求也日益增长,达梦数据库凭借其高性能、高可靠性等特点,能够满足企业的需求,拓展市场空间。
- 云计算、大数据、人工智能等新兴技术的发展,为数据库技术带来了新的发展方向和应用场景,达梦数据库可以与这些技术相结合,推出更多创新的解决方案,实现差异化发展。

















 3085
3085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









