







Kafka知识整理系列一
Kafka生产者

我们用java去写一个kafka生产者,通常有以下步骤及参数需要设置
- 配置Properties参数。Properties相当于一个配置文件,配置信息都以key-value的形式进行存储。
Properties properties = new Properties(参数名,参数值);
- 构建KafkaProducer。顾名思义是一个kafka生产者,把第一步的配置文件放到里面,会根据配置信息创建一个producer
KafkaProducer producer = new KafkaProducer(properties);
- 构建待发送的消息ProducerRecord。并指定一个topic,把消息send出去
producer.send(new ProducerRecord<String,String>(发送的目的topic,发送的消息));
- 关闭producer
producer.close();
这是构建一个生产者的必要步骤
重点来了,这是一些必要的参数设置,意思是一定要配置:
- bootstrap.server:配置kafka集群地址。
- key.serializer以及value.serializer:配置转换字节数组所需要的序列化器(消息发送出去,存储到kafka当中,肯定是需要经过序列化的,就好像java当中,把对象信息存储到mysql当中)
例子:

一个简单的生产者demo
kafka生产者消费者代码网上有很多,我这里给出一个简单的配置:
首先是pom:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
生产者代码:
package com.pro.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class Test {
public static void main(String[] args) {
// 第一步,创建配置文件并把配置信息放入进去
Properties properties = new Properties();
// 设置集群地址,value用ip:9092的形式
properties.put("bootstrap.servers", "node1:9092");
// 设置应答机制,all是需要等待所有副本节点的应答
properties.put("acks", "all");
// 消息发送最大尝试次数
properties.put("retries", "0");
// 处理一批消息的大小
properties.put("batch.size", "16384");
// 请求延时
properties.put("linger.ms", "1");
// 发送缓存区内存大小
properties.put("buffer.memory", "33554432");
// key序列化,序列化器可使用StringSerializer
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化,序列化器可使用StringSerializer
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 第二步,根据配置文件创建一个KafkaProducer
KafkaProducer producer = new KafkaProducer(properties);
// 第三步,模拟发送消息
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<String, String>("test", "hello" + i));
}
// 第四步,关闭producer
producer.close();
}
}
生产者的几种发送模式以及重要参数
- fire-and-forget:只管发送,不关系消息是否到达目的地。
- sync(同步):send()调用之后,会返回一个Future类型的对象,可以通过get()来阻塞任务发送的结果,并做出相应的处理。
Future future = producer.send(new ProducerRecord<String,String>(发送的目的topic,发送的消息));
// 这里就可以获得任务发送的一个结果
Object data = future.get();
- async(异步):通过向Future注册一个回调函数Callback。
重要参数:

Kafka消费者
消费者和消费者组的概念
首先消费者不同于生产者,需要注意以下两点:
- 消费者具有消费组的这么一个概念。
- 每个分区只能被一个消费者组的一个消费者消费。
- 消费者是一个实际的应用实例,可以作为一个线程or一个进程。
- 同组内的消费者是竞争关系。
消费者的消费步骤:
- 配置参数(Properties)参考生产者。
- 创建一个KafkaConsumer实例。
- 订阅主题topic。
- 拉去消息并消费。
- 提交消费位移(offset)。
- 关闭实例。
同样,消费者也有必须要配置的信息:
- bootstrap.servers:集群broker的地址
- group.id:消费者组的id
- key/value.deserializer:反序列化器
其他的重要参数:

Kafka消息的存储
消息存储的方式:

kafka的消息,以topic为单位进行归类
总结为以下几点:
- topic与partition(分区)为一对多的关系。
- 每个分区可以看做一个可追加的日志文件。(新加的消息从尾巴添加)
- 消息在追加到分区的时候,会分配一个偏移量(offset 一个唯一标识)
- kafka通过偏移量来保证消息在分区内的一个顺序(但是只能够保证分区有序,而不能保证topic有序,也因此上文中,kafka消费消息后,offset需要提交消费位移offset)
存储的地址
kafka把消息发送到broker(一个节点上)后,将消息存储到磁盘上,通过日志的方式来持久化信息。
目录的名称有一定的规律,格式为 [topic名称]-[分区号],如图:
顺便一提,存放地址可以通过配置server.properties文件来更改:

存放文件目录的组成
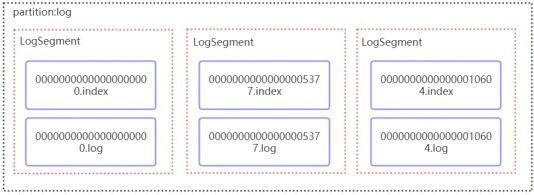
打开上图一个分区目录,进去查看目录结构:

发现了有两种文件:
- .index文件:存储索引的文件
- .log文件:存储数据
kafka通过分段的方式将数据分为LogSegment,而每一个LogSegment就包括一个index文件和一个log文件。并且每一个Segment文件的命名也有一定的规则,末尾的数字就是这个消息的offset值(并且由上一个Segment中最后一条消息的offset值决定)
kafka查看日志的命令
如果直接用cat命令或者vi命令去查看肯定是不行的,会乱码,最好用kafka自带的脚本去查看:
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /日志地址/xxx.log --print-data-log

具体参数的意义:
| 单词 | 意义 |
|---|---|
| position | 偏移量 |
| magic | 消息格式版本号 |
| compresscodec | 压缩编码 |
| playload | 偏移数据 |
| offset | 记录号 |
另外,每个索引会对应着一个数字,而这个数字是这条消息在日志文件当中的位置,相当于一个映射

Partition如何根据offset去查找信息
- 根据offset值,查找segment段中的index索引文件,使用二分查找去定位索引文件的位置。
- 找到索引后,通过offset寻找对应匹配的偏移量position
- 得到position后,到目标对应的log文件中,从position(一个数字)处开始,查找offset对应的消息。
举个例子:
再把上文的图拿来用一用:

比如此处,我需要查找offset=2490的消息
步骤如下:
- 先找到00000xxx.index索引文件
- 找到[2487,49111]这一行索引(图中第三行),此时得到position为49111
- 到对应的00000xxx.log文件中,从49111处开始查找,比较每条消息的offset是不是为2490
- 如果是,则返回
kafka副本机制
kafka有一个多副本机制:
- 也就是说,一个分区会在多个副本中存储相同的信息,并且副本与副本之间存在主从关系。
- 有一个副本作为主副本,负责读和写,另外的从副本只有读的功能,只负责备份。
- 从副本在主副本挂的时候,可以成为竞争为主副本。
一些kafka专业术语
副本术语
| 缩写 | 意义 |
|---|---|
| ISR | 由与leader保持一定程度的同步关系的副本组成 |
| OSR | 由同步之后,剩下的的副本组成Out-Of-Sync Replica |
| AR | 分区中所有的副本称为AR |
偏移量术语
| 缩写 | 意义 |
|---|---|
| LEO | 标识当前分区下一条待写入消息的offset(Log End Offset) |
| HW | 高水位,consumer只能拉取到此offset之前的消息(High WaterMark) |
kafka副本的作用有哪些
看下副本的图:

上图大概意思是:
- 每个topic有多个分区
- 每个分区有多个副本
- 副本之间又存在主从副本
- 副本又分布在不同的broker上。
副本的解释:
- kafka中的副本,本质上是一个能够追加写消息的日志。
- 同一个分区下的所有副本保存相同的消息序列。
- 分工明确,一个主副本,负责接收处理某一个分区下的所有读写请求。
- 从副本不对外提供服务,唯一的任务就是与leader 副本同步数据
副本的具体作用:
- 提供数据的冗余,实现高可用。(这个不难理解,毕竟有备份)
- 方便实现Read-yours-writes:即生产者成功向kafka中写入消息的时候,马上使用消费者去读取刚刚生产的消息
(如果允许从副本提供服务,那么由于kafka数据的同步是异步的,所以无法保证client从 从副本中获取的数据为最新的,也因此只能够运行从主副本中读取数据) - 方便实现单调读Monotonic Reads:对于一个消费者而言,在多次消费消息的时候,不会看到某一个消息时而在时而不在的情况
这里假设:允许从副本提供服务,并假设有两个从副本,分别叫做A和B副本,他们异步拉去leader主副本的数据,放图(手画的不好,将就下)

因此出现数据消费结果不一致的情况,也因此,所有请求都交给leader去处理。即实现了单调读一致性,















 6506
6506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











