







线程栈(线程的工作内存)保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图副描述这写交互
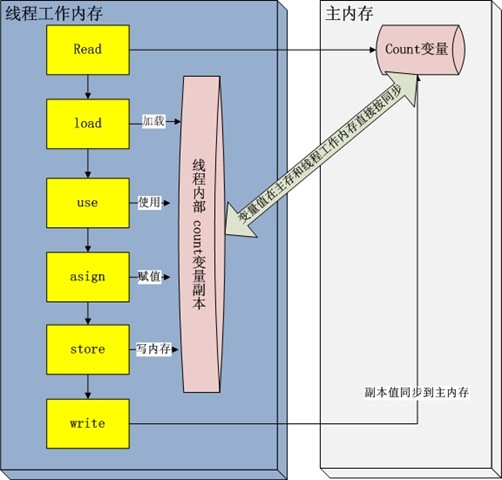
read and load 从主存复制变量到当前工作内存
use 代码中使用值
assign 改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
总结:关键字上使用voildate之后,每一次use之前一定要read和load,这样就保证了可见性,其他线程
指令重排序
总结:jvm会对指令执行的顺序进行优化,这样是为了提高执行的效率。但是在单线程的情况下指令的执行先后没有关系,但是在多线程的情况下这些指令的执行顺序就是对其他线程产生很大的影响。
很多介绍JVM并发的书或文章都会谈到JVM为了优化性能,采用了指令重排序,但是对于什么是指令重排序,为什么重排序会优化性能却很少有提及,其实道理很简单,假设有这么两个共享变量a和b:
private int a;
private int b;
在线程A中有两条语句对这两个共享变量进行赋值操作:
a = 1;
b = 2;
假设当线程A对a进行复制操作的时候发现这个变量在主内存已经被其它的线程加了访问锁,那么此时线程A怎么办?等待释放锁?不,等待太浪费时间了,它会去尝试进行b的赋值操作,b这时候没被人占用,因此就会先为b赋值,再去为a赋值,那么执行的顺序就变成了:
b = 2;
a = 1;
对于在同一个线程内,这样的改变是不会对逻辑产生影响的,但是在多线程的情况下指令重排序会带来问题,看下面这个情景:
在线程A中:
context = loadContext();
inited = true;
在线程B中:
while(!inited ){
sleep
}
doSomethingwithconfig(context);
假设A中发生了重排序:
inited = true;
context = loadContext();
那么B中很可能就会拿到一个尚未初始化或尚未初始化完成的context,从而引发程序错误。
想到有一条古老的原则很适合用在这个地方,那就是先要保证程序的正确然后再去优化性能。此处由于重排序产生的错误显然要比重排序带来的性能优化要重要的多。要解决重排序问题还是通过volatile关键字,volatile关键字能确保变量在线程中的操作不会被重排序而是按照代码中规定的顺序进行访问,同时使用synchronized 关键字,里面也不会进行指令重排序。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









