









推荐阅读:
MySQL概述
什么是数据库?数据库的种类有哪些?
数据库:
高效的存储和处理数据的介质(主要分为磁盘和内存两种)
关系型数据库:
- 大型:Oracle、DB2 等;
- 中型:SQL Server、MySQL、PostgreSQL等;
- 小型:Access 等。
非关系型数据库:
Memcached、MongoDB、Redis、Elasticserach等。
MySQL数据库
关系数据库管理系统,开放源码软件,目前属于 Oracle 旗下产品。C\S结构的软件
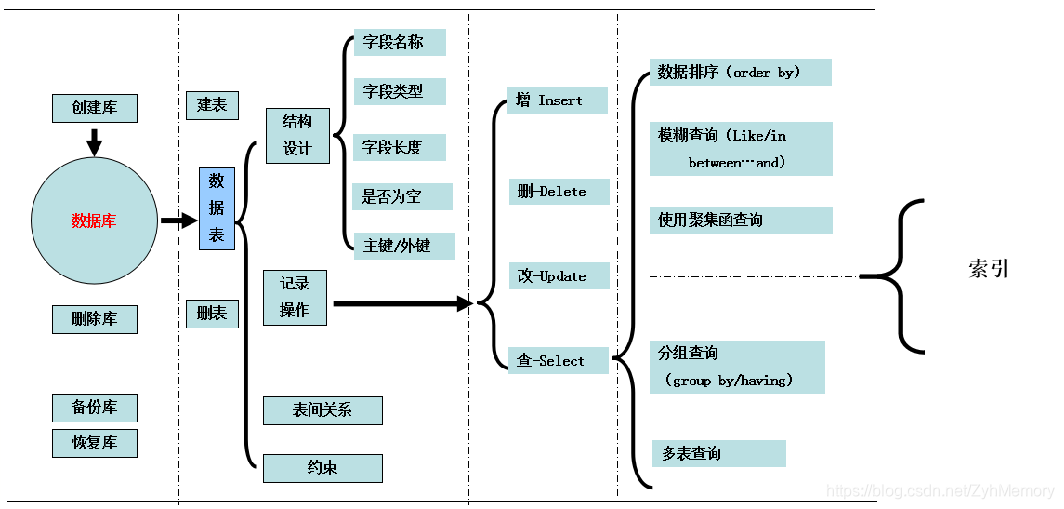
体系结构
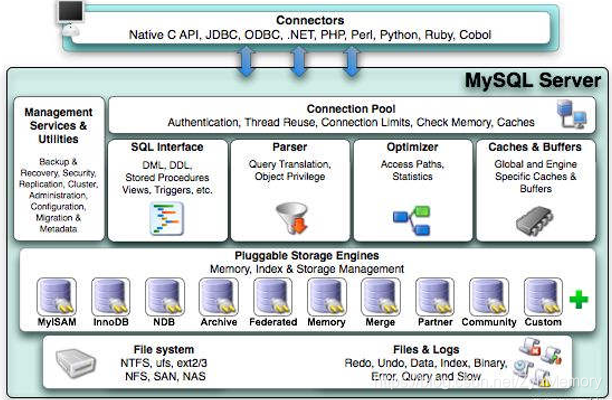
一条select的生存周期
结构化查询语言
- 数据查询语言DQL:用于检索数据库中数据记录等,如SELECT
select name,age from students; - 数据操纵语言DML:用于改变数据库中的数据记录等,如INSERT、UPDATE 、DELETE
insert into students (name,age,sex,classid) values (’小明’,20,’男’,1); - 数据定义语言DDL:用于建立,修改,删除数据库中的各种对象如表、视图、索引等,如CREATE、 TABLE/VIEW/INDEX/SYN/CLUSTER、ALTER、DROP
alter table student add index idx_cid (classid); - 数据控制语言DCL:用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等,如GRANT、REVOKE、COMMIT
grant select on *.* to readonly@’%’;
连接使用
前提:MySQL服务、客户端工具、合法的账号
MySQL系统库
information_schema、performance_schema、sys、mysql
# mysql -h192.168.2.1 -P3306 -root -ppassword [DB]
> show databases;
> create database test;
> use test;
> create table test (
id int(10) not null auto_increment,
name varchar(20) not null default '' comment '名称',
note varchar(10) not null default '' comment '备注',
primary key(id),
key idx_name(name)
)engine=innodb auto_increment=1 default charset utf8 comment '测试表';
> inser into test (name,note) values ('Tom','student'),('Jim','student');
> select name,note from test;
JAVA
jdbc.driver=com.mysql.jdbc.Driver
jdbc.user=root
jdbc.password=root
jdbc.className=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/bookstore
Python
mysql+pymysql://root:root@127.0.0.1:3306/flask?charset=utf8
注:个人账号和应用账号及连接数据库使用域名
库表操作
创建数据库
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
查看建库语句
SHOW CREATE DATABASE db_name;
显示所有的数据库
SHOW DATABASES;
删除数据库
DROP DATABASE db_name;
数据类型
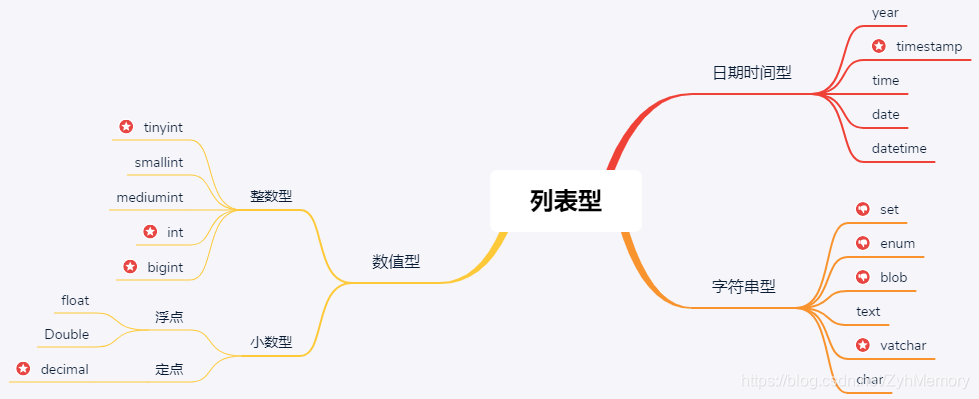
新建规范
CREATE TABLE tb_student (
id BIGINT UNSIGNED NOT NULL auto_increment,
-- 必须要有主键,必须有注释
snum INT NOT NULL DEFAULT 0 COMMENT '学号',
-- 不允许存在NULL值
NAME VARCHAR (10) NOT NULL DEFAULT '' COMMENT '学生姓名',
-- 给默认值
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
sex VARCHAR (2) NOT NULL DEFAULT '' COMMENT '性别',
class_id INT NOT NULL DEFAULT 0 COMMENT '班级id',
PRIMARY KEY (id),
KEY idx_sname (class_id) -- 一切外键关系必须在应用层解决
) ENGINE = INNODB DEFAULT CHARSET utf8 COMMENT '学生表';
更改表
ALTER TABLE tb_name [ADD | DROP | MODIFY ...] COLUMN ...
ALTER TABLE test ADD date BIGINT NOT NULL DEFAULT 0 COMMENT '时间',
MODIFY NAME NAME VARCHAR (30) NOT NULL DEFAULT '' COMMENT '名称';
-- 同一个表的多个涉及到字段的操作,放到一个SQL里面完成
增删改
INSERT
第一种
INSERT INTO tb_name [ (col1_name,col2_name ,...) ]
VALUES(col1_value,col2_value ,...) [, (col1_value,col2_value ,...)...]
如:
INSERT INTO test_db.test_tb (stu_num, NAME, age, sex)
VALUES
(1123, 'Tom', 10, 'm'),
(1124, 'Jary', 11, 'f');
优先采用使用一条语句多条更新
第二种
INSERT INTO tb_name SET col1_name={expr | col1_value},...;
如:
INSERT INTO test_db.test_tb set stu_num=1125,name='Luna',age=12,sex='f';
第三种
INSERT INTO tb_name SELECT (col1_value | expr) [ UNION | unoin ALL ] SELECT(col1_value | expr )...;
如:
INSERT INTO test_db.test_tb
SELECT 1126,'Luna',12,'f' UNION
SELECT 1127,'Jury',15,'f' ;
UPDATE
UPDATE tb_name SET col_name = col_value [ WHERE where_expr ] [ ORDER BY... ][ LIMIT row_count ]
如:
UPDATE test_db.test_tb SET name=‘Mary’WHERE stu_num=1123;
DELETE
DELETE FROM tb_name [WHERE where_expr] [ORDER BY ...][LIMIT row_count]
如:
DELETE FROM test_db.test_tb WHERE stu_num=1123;
最安全的删除,可以恢复还原
DROP TABLE tb_name;
最快速最无脑的删除,全没了
TRUNCATE TABLE tb_name;
只删表数据,不删表结构
1)使用WHERE条件能确定到具体的某条记录上的更新或删除语句,不能有歧义导致误删数据。避免使用分组及排序语句。
2)TRUNCATE和DELETE只删除数据不删除表的结构(定义),但是DELETE可以回滚,会出发DELETE触发器,而TRUNCATE则不可以回滚,且不会触发DELETE触发器。DROP删除数据及结构,不能回滚。
3)速度和效率上一般来说: DROP> TRUNCATE> DELETE,但是要慎用前两者。
查询
SELECT
[ STRAIGHT_JOIN ] [ SQL_SMALL_RESULT | SQL_BIG_RESULT ]
[ SQL_CACHE | SQL_NO_CACHE ] [ HIGH_PRIORITY ]
[ DISTINCT | DISTINCTROW | ALL ] select_expression ,...
[ INTO { OUTFILE | DUMPFILE } 'file_name' export_options ]
[ FROM table_references ] [ FORCE INDEX | IGNORE INDEX ]
[ WHERE where_definition ]
[ GROUP BY col_name ,...]
[ HAVING where_definition ]
[ ORDER BY { unsigned_integer | col_name | formula } [ ASC | DESC ] ,...]
[ LIMIT [ OFFSET ,] rows ]
简单查询
-
无限定条件查询:
查询单个列:SELECT name FROM test_db.test_tb;
查询多个列:SELECT name, age,sex FROM test_db.test_tb;
查询所有列:SELECT * FROM test_db.test_tb;(实际生产中不要使用select * 通配查询) -
WHERE条件:
查找年龄大于15周岁的多个列信息:SELECT NAME,age,sex FROM test_db.test_tb WHERE age > 15;查找年龄大于15周岁并且性别为男的多个列信息:
SELECT NAME, age, sex FROM test_db.test_tb WHERE age > 15 AND sex = ‘男’;查找主键ID为11,12,13,14,15的信息:
SELECT NAME, age, sex FROM test_db.test_tb WHERE id IN (11,12,13, 14,15);查找姓李的人的信息:
SELECT name, age,sex FROM test_db.test_tb WHERE name LIKE '李%';查找年龄在15到30岁之间,并且这些人的主键id要在100以内的人的姓名:
SELECT NAME, age, sex FROM test_db.test_tb WHERE NAME LIKE '李%'; -
ORDER BY 排序:
根据年龄排序:SELECT name, age,sex FROM test_db.test_tb where age>15 order by age asc;根据两个条件进行倒序排序:
SELECT NAME, age, sex FROM test_db.test_tb WHERE NAME LIKE '王%' ORDER BY createtime DESC, age DESC; -
GROUP BY 分组:
每个班级的人数汇总:select count(1),class_id from student group by class_id;班级人数男女总数:
select count(1),sex from student group by sex; -
查询中使用函数:
查询test_db.test_tb表的总行数:SELECT COUNT(*) FROM test_db.test_tb ;查询最小年龄是多少:
SELECT MIN(age) FROM test_db.test_tb ;按年龄分组,查找每个年龄各有多少人数,并且其总人数大于10人:
SELECT COUNT(*) stu_sum,age FROM test_db.test_tb GROUP BY age HAVING stu_sum>10;常用的函数
COUNT()、SUM()、MAX()、MIN()、FROM_UNIXTIME()、UNIX_TIMESTAMP()、NOW()、SUBSTRING_INDEX()、IFNULL()、CASE...WHEN...THEN...ELSE...END -
子查询
查询所有年龄为最小年龄的人信息:SELECT NAME, age, sex FROM test_db.test_tb WHERE age = ( SELECT MIN(age) FROM test_db.test_tb );查询性别为男并且大于平均年龄的人的信息,并且按照年龄从大到小排序,取年龄最大的三条:
SELECT NAME AS '姓名', age AS '年龄', sex AS '性别' FROM test_db.test_tb WHERE sex = '男' AND age > ( SELECT AVG(age) FROM test_db.test_tb ) ORDER BY age DESC LIMIT 0,3; -
Union | Union All
select price,name from A where datetime between 1532511000 and 1532073600 union select price,name from B where datetime between 1532511000 and 1532073600 union select price,name from C where datetime between 1532511000 and 1532073600;
JSON
用于多表中字段之间的联系
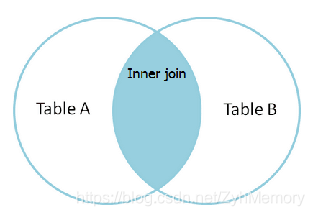
INNER JOIN(内连接,或等值连接):
取得两个表中存在连接匹配关系的记录。
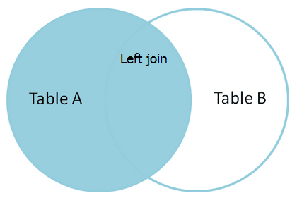
LEFT JOIN(左连接):
取得左表的完全记录,右表无对应匹配记录的以NULL显示。
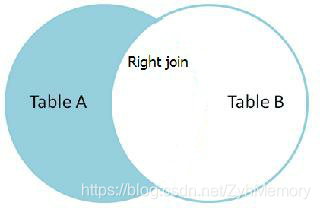
RIGHT JOIN(右连接):
与 LEFT JOIN 相反,取得右表完全记录,左表无对应匹配记录的以NULL显示。
CROSS JOIN (交叉连接):
得到的结果是两个表的乘积,即笛卡尔积。(禁用!)
例一:
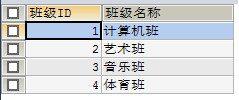
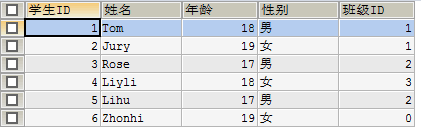
SELECT sid 学生ID,sname 姓名, sage 年龄, ssex 性别, NAME 班级名称
FROM student s INNER JOIN class c ON s.`classid` = c.`id`;
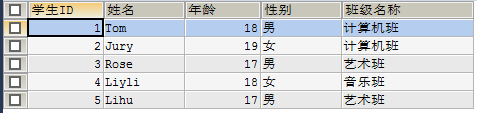
SELECT sid 学生ID, sname 姓名, sage 年龄, ssex 性别, NAME 班级名称
FROM student s LEFT JOIN class c ON s.`classid` = c.`id`;
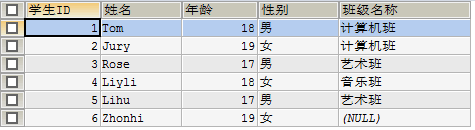
SELECT sid 学生ID, sname 姓名, sage 年龄, ssex 性别, NAME 班级名称
FROM student s RIGHT JOIN class c ON s.`classid` = c.`id`;
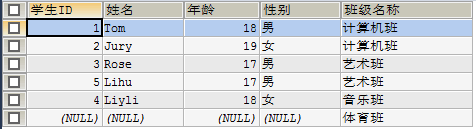
例二:
表字段:
student(sid,sname,sage,ssex)
course(cid,cname,tid)
score_course(sid ,cid,score)
teacher(tid ,tname)
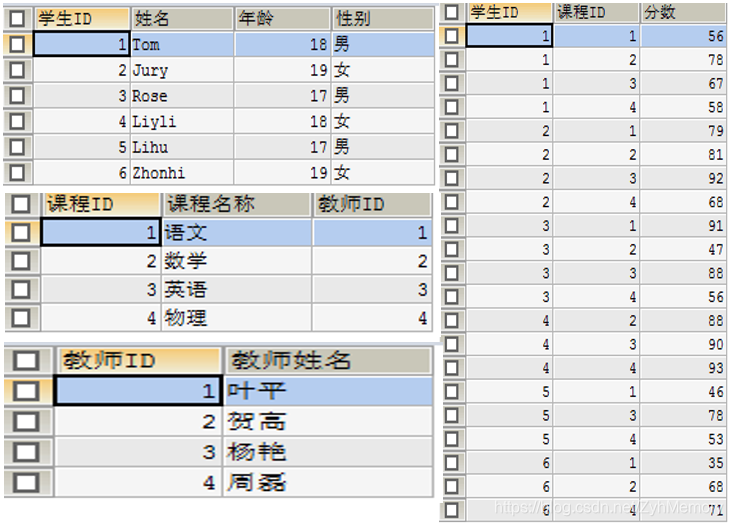
分页查询:查询学习的课程号为1的排名前三的学生ID:
SELECT sid '学生ID',score
FROM score_course
WHERE cid = 1
ORDER BY score DESC LIMIT 0,3
分组查询:查询没有学全所有课程的学生ID、姓名:
SELECT s.sid '学生ID', s.sname '姓名'
FROM student s, score_course sc
WHERE s.sid = sc.sid
GROUP BY s.sid
HAVING COUNT(*) = (SELECT COUNT(*) FROM course c)
关联查询:查询符合某个学生课程1成绩比课程2成绩分数高的所有同学的学生ID、姓名:
SELECT s.sid '学生ID', s.sname '姓名'
FROM student s
JOIN score_course sc ON s.sid = sc.sid
JOIN score_course sc2 ON sc.sid = sc2.sid
WHERE sc.cid = 1
AND sc2.cid = 2
AND sc.score > sc2.score
聚合查询:查询所有同学的学生ID、姓名、选课数、总成绩:
SELECT s.sid '学生ID', s.sname '姓名', COUNT(sc.cid) '选课数', SUM(sc.score) '总成绩'
FROM student s JOIN score_course sc ON s.sid = sc.sid
GROUP BY sc.sid
子查询:查找学过教师ID为1的课程的所有学生的学生ID:
SELECT DISTINCT sc.sid '学生ID'
FROM score_course sc
WHERE sc.cid = (
SELECT c.c
FROM course c
WHERE c.tid = 1)
case when查询:查询男生、女生人数:
SELECT SUM(CASE WHEN ssex = '男' THEN 1 ELSE 0 END) '男生人数',
SUM(CASE WHEN ssex = '女' THEN 1 ELSE 0 END) '女生人数'
FROM student
索引
为什么要建立和使用索引?
索引是独立数据之外而存在的一种存储介质,并且在mysql启动的时候会默认加载到缓冲池中(内存)。相对于从磁盘中物理读取数据内容,从内存中读取索引数据的速度更快(10倍+)。
索引命名
- 使用小写字母,过长的字段名可以采⽤缩写形式
- 普通索引按“idx_字段名称[_字段名称]”格式(idx_contractNo)
- 唯一索引按“uniq_字段名称[_字段名称]”格式(uniq_phone)
建立条件
- 目标的数据表有查询需求。(对无查询需求的日志表可以不建立索引提高写入速度)
- 目标数据表未来数据量大于1000条。
索引选择性
是指某个字段的不重复值的数量占总行数的比例,这个比例越接近1,则选择性越高,如果有该字段上的查询需求,更适合建立索引。
select count(distinct name)/count() from employee;
select count(distinct left(name,10))/count() from employee;
多列的索引选择性
查询:select name,mobile,status from employee where name=‘张三’ and status=0;
这个时候怎么建立索引?
1. 两个单列索引:idx_name(name)、idx_status(status)
2. 并列索引: idx_name_status(name,status)
3. 一个索引:idx_name(name)
select count(distinct name,status)/count(*) from employee; 0.9797
所以这里只需要idx_name即可实现很高的筛选度。
多列索引的索引hit原则?
现在有一如下多列索引:
idx_name_mobile_ctime(name,mobile,create_time)
可以使用到该索引的查询:
select name,mobile,status from employee where name='张三' and mobile='139*****' and create_time > 1494310361 and create_time < 1494312361;
select name,mobile,status from employee where name='张三' and mobile='139*****';
select name,mobile,status from employee where name='张三';
无法使用该索引的查询:
select name,mobile,status from employee where mobile='139*****' and create_time > 1494310361 and create_time < 1494312361;
select name,mobile,status from employee where mobile='139*****';
select name,mobile,status from employee where create_time > 1494310361 and create_time < 1494312361;
如何正确的使用多列索引呢?
需要考虑每层级的索引选择性:
select name,mobile,status from employee where name='张三' and mobile='139****' and create_time > 1494310361 and create_time < 1494312361;
分别查询一下3中索引选择性:
select count(distinct name)/count(*) from employee;
select count(distinct name,mobile)/count(*) from employee;
select count(distinct name,mobile,create_time)/count(*) from employee;
如果结果是:0.91 0.94 0.99 可以仅对name列建立单列索引即可。
如果结果是:0.61 0.94 0.99 可以对name,mobile列建立复合索引(即多列索引)即可。
如果除了上述包含3个条件的查询之外还有针对mobile列的单独高频率查询,建议另外建立一列为mobile的单列索引:idx_mobile。
前缀索引的适用场景
对某些长度较大的字段有需求建立索引的时候建立。 varchar(100)
语法格式
alter table employee add key idx_title(title(10));
如何选择合适的长度?
依然使用索引选择性进行长度圈定。
select count(distinct left(title,50))/count(distinct title) from employee; 0.999
select count(distinct left(title,8))/count(distinct title) from employee; 0.9574
select count(distinct left(title,6))/count(distinct title) from employee; 0.5286
根据上述查询结果,使用idx_title(title(8))
inner join、left join的关联字段一定要建立索引
select name,mobile from employee a inner join department b on a.department_id=b.id;
-- 这里employee的department_id的是否有索引直接影响到查询效率
不要使用in ()子查询的方式,很多情况下无法使用索引
select name,mobile from employee where department_id in (select id from department);
查询的字段如果是varchar类型一定要使用单引号括住常量值
先假设mobile字段是varchar字段(实际使用过程中纯数字的字段尽量使用int、bigint、decimal等数字类型)
select name,mobile from employee where mobile = 13934563352; -- 无法使用索引
select name,mobile from employee where mobile = '13934563352'; -- 可以使用索引
练习
- 现在有一个需求,需要创建一张超简单的学生表(tb_student),其中学生的属性有学号snum、姓名name、年龄age、性别sex和班级class_id,问这张表的创建语句如何写(MySQL语法)?
CREATE TABLE tb_student (
id BIGINT UNSIGNED NOT NULL auto_increment,
snum INT NOT NULL DEFAULT 0 COMMENT '学号',
NAME VARCHAR (10) NOT NULL DEFAULT '' COMMENT '学生姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
sex VARCHAR (2) NOT NULL DEFAULT '' COMMENT '性别',
class_id INT NOT NULL DEFAULT 0 COMMENT '班级id',
PRIMARY KEY (id),
KEY idx_sname (class_id)
) ENGINE = INNODB DEFAULT CHARSET utf8 COMMENT '学生表';
- 现在有两个学生,分别是小明和小红,信息分别为:
小明,学号201901211314,21岁,男,id为1013的班级;
小红,学号201901221314,20岁,女,id为1016的班级;
- 请问,如何将这两条信息写入到刚刚新建的表里面?
INSERT INTO tb_student (snum, NAME, age, sex, class_id)
VALUES(201901211314, '小明', 21, '男', 1013),
(201901221314, '小红', 20, '女', 1014);
- 假如1013班目前有36个人,请问,如何从这个表中使用sql得出1013班的平均年龄?并判断1013班和1014班哪个班平均年龄小,并按照从大到小的顺序排列?
SELECT class_id, avg(age) avg_age
FROM tb_student
GROUP BY class_id
ORDER BY avg_age DESC;

















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









