






1.绪论
1.概述
职业病数据存储与可视化项目聚焦于职业病相关数据的高效管理与直观呈现。在当今社会,职业病问题日益受到关注,准确存储和分析职业病数据对于预防和控制职业病至关重要。通过本项目的实施,能够实现职业病数据的有序存储、快速查询与直观展示,为职业病防治工作提供有力的数据支持。
2.课题背景
随着工业化进程的加快,职业病问题愈发凸显,其发病率的上升趋势给劳动者健康和社会经济带来了双重压力。在此背景下,职业病数据的有效管理与深度分析显得尤为关键。传统数据库在应对海量职业病数据时存在诸多局限,而大数据技术的兴起提供了新路径。HBase 分布式数据库在数据存储方面优势显著,可满足大规模数据的存储与查询需求。同时,为了让医务人员和决策者能更直观地洞察数据规律,迫切需要开发功能完备且易用的数据可视化系统,以填补现有工具的不足,为职业病防治工作提供有力支持。
2.项目需求分析
1.数据存储需求
1.构建稳定且高效的分布式数据库架构,以存储海量职业病数据,确保数据的高可用性与可扩展性。
2.实现不同数据源(如Excel文件)与目标数据库(HBase、MySQL)之间的数据无缝导入,保证数据完整性与准确性。
3.优化数据存储结构,便于快速数据检索与分析,满足职业病数据多样化查询需求。
2.数据处理需求
1.对导入的数据进行清洗与转换,确保数据格式统一、质量可靠,如处理Excel文件中的数据格式,将其转换为适用于HBase和MySQL存储的格式。
2.建立高效的数据索引机制,加速数据查询速度,如在MySQL数据库中为关键字段创建索引,提高查询效率。
3.实现数据缓存策略,利用Redis缓存频繁访问的数据,减轻数据库查询压力,提升系统响应速度。
3.数据可视化需求
1.开发直观、友好的数据可视化界面,以图表(如柱状图、折线图、地图等)形式展示职业病数据的关键信息,如不同地区职业病发病情况、各类职业病危害因素分布等。
2.提供灵活的数据筛选与交互功能,使用户能够根据自身需求定制可视化内容,如按时间范围、地区、职业病类型等进行数据筛选与分析。
3.确保可视化系统能够实时反映数据变化,为职业病防治决策提供及时、准确的数据支持。
3.程序设计
1.开发环境配置
Hadoop:3.1.3
HBase:2.2.2
Redis:3.0.0
JAVA:1.8.0
Python:2.7.5;3.8.10
MySQL:8.0.31
2.项目所需模块
3.项目所需软件

![]()
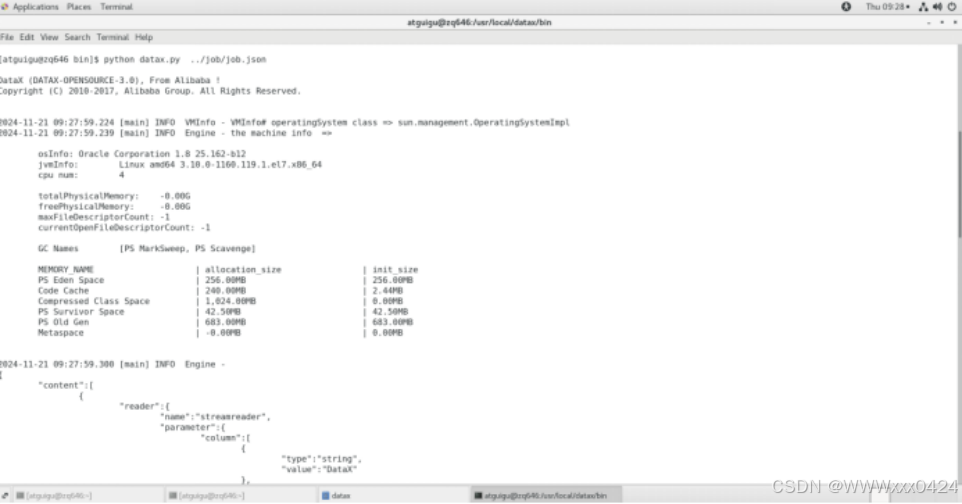
4.数据导入HBase
4.1 安装并配置HBase
4.1.1 HBase 安装与主节点配置
- 软件下载与解压:在主虚拟机节点上准确下载 HBase2.2.2版本,并成功解压至指定目录,为后续配置与启动做好准备。
- 关键文件配置:修改hbase-site.xml文件,合理配置 HBase 的存储路径为本地文件系统的特定目录,同时准确指定单独安装的Zookeeper集群地址,以及HBase主节点的地址和端口号,确保 HBase 与 Zookeeper 能正确通信与协同工作。
- 区域服务器文件编辑:仔细编辑 regionservers 文件,将 3 个虚拟机节点的主机名准确无误地写入其中,明确 HBase 集群的节点分布。
- 环境变量配置:将 HBase 和 Zookeeper 的 bin 文件加入到环境配置中,方便在任意路径下执行相关命令,提高操作便利性。
4.1.2 配置发布与从节点激活
- 配置文件与软件发布:通过scp命令,将主节点上的Zookeeper、HBase相关配置文件及软件目录准确发布到另外两台虚拟机,确保从节点具备与主节点一致的运行环境。
- 从节点环境激活:在另外两台虚拟机上成功激活环境,使从节点能够识别并应用新配置,为加入HBase集群做好准备。
4.1.3 HBase集群启动与验证
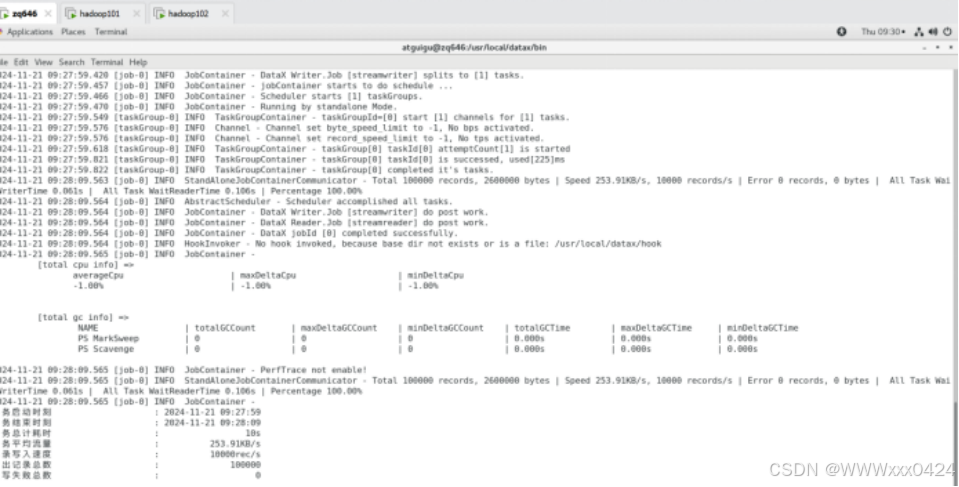
- 集群启动操作:在主节点上熟练执行启动脚本,启动 HBase 集群,触发集群初始化与服务启动流程。
- 进程检查验证:使用 jps 命令检查各个节点上的进程,确认QuorumPeerMain,HMaster和HRegionServer进程正常启动,验证 HBase 集群搭建成功。
4.2数据格式转换与导入至HBase
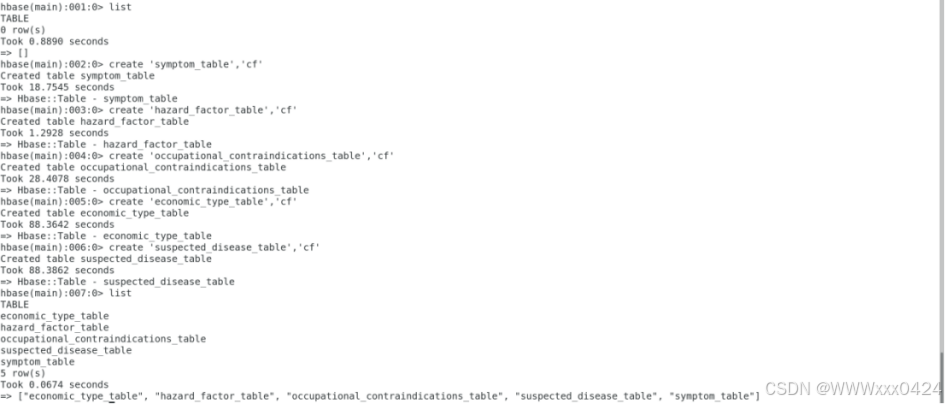
前提:在安装好的HBase中,创建五张表
4.2.1 Excel到CSV转换
开发了convert_excel_to_csv函数,利用pandas库的read_excel方法读取指定的 Excel 文件(如 “table4.xls”),并通过to_csv方法将其转换为 CSV 格式,同时确保不包含索引列,方便后续数据处理。在转换过程中,通过打印输出提示信息,明确转换进度与结果,实现了高效的数据格式转换,为后续导入HBase做准备。

4.2.2数据导入HBase操作
在insert_data_to_hbase_from_csv函数中,使用pandas的read_csv方法读取转换后的 CSV 文件(如 “table4.csv”)。针对读取的数据行,以每行第一列作为行键(假设为数据的唯一标识),并根据预定义的列映射关系(如column_mappings_table4中定义的 “编码” 对应 “cf:code”,“描述” 对应 “cf:description”),将数据转换为字节格式后,通过happybase库提供的put方法逐行插入到对应的 HBase 表(如 “economic_type_table”)中。在插入过程中,实时打印插入的数据行键,方便跟踪导入进度,同时通过异常处理确保数据插入的稳定性和准确性。

4.2.3 HBase 连接与整体流程控制
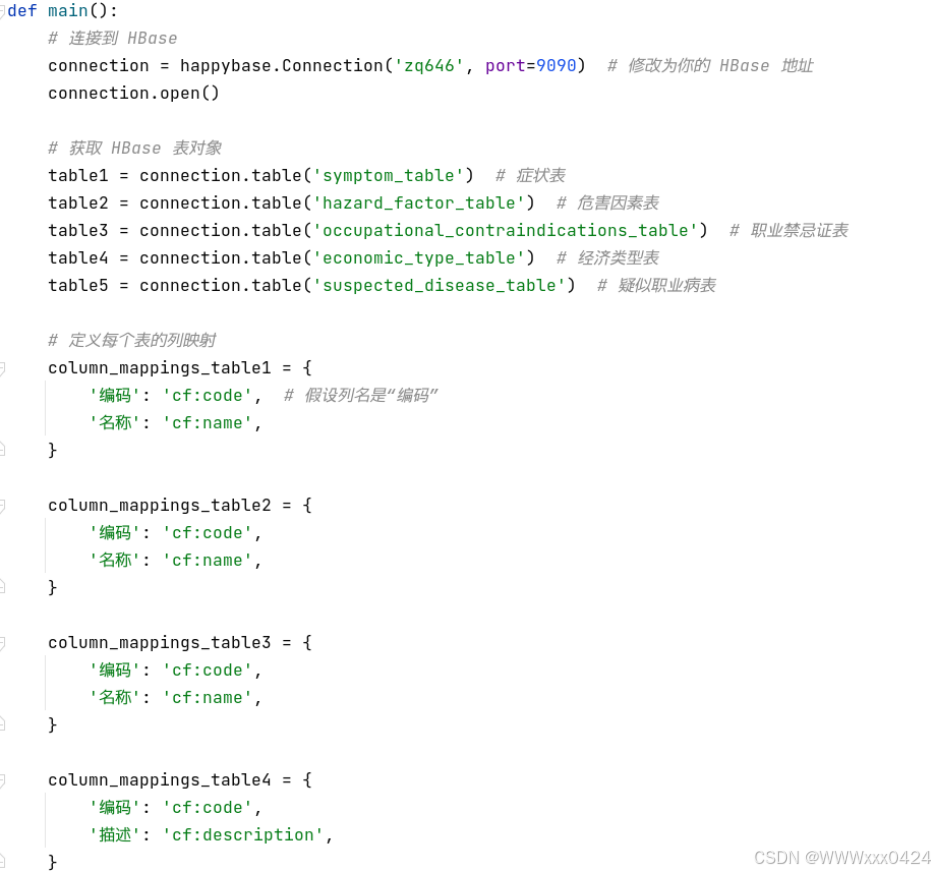

导入成功后的数据展示:
4.3数据导入MySQL
运用Pycharm开发了从HBase到MySQL的数据迁移功能,负责编写并优化整个数据迁移脚本,实现了数据的高效迁移。
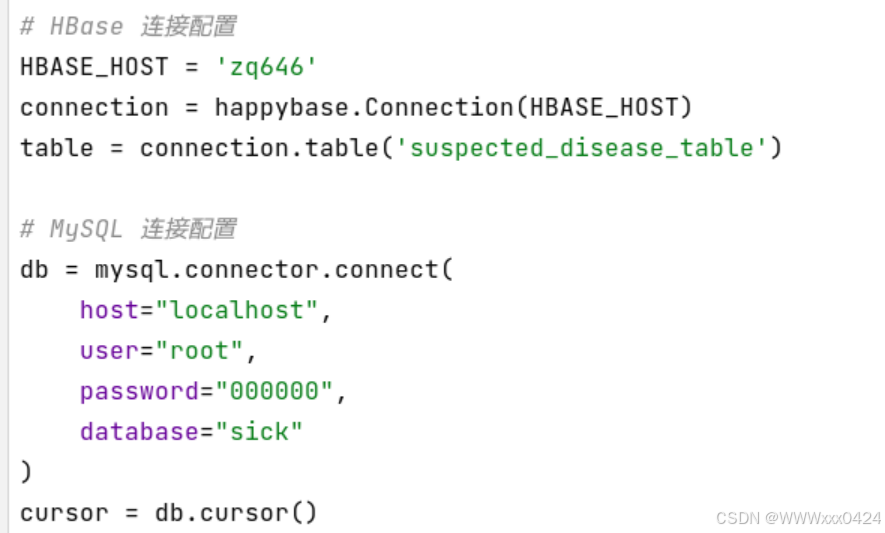
4.3.1连接配置
4.3.2数据提取与转换
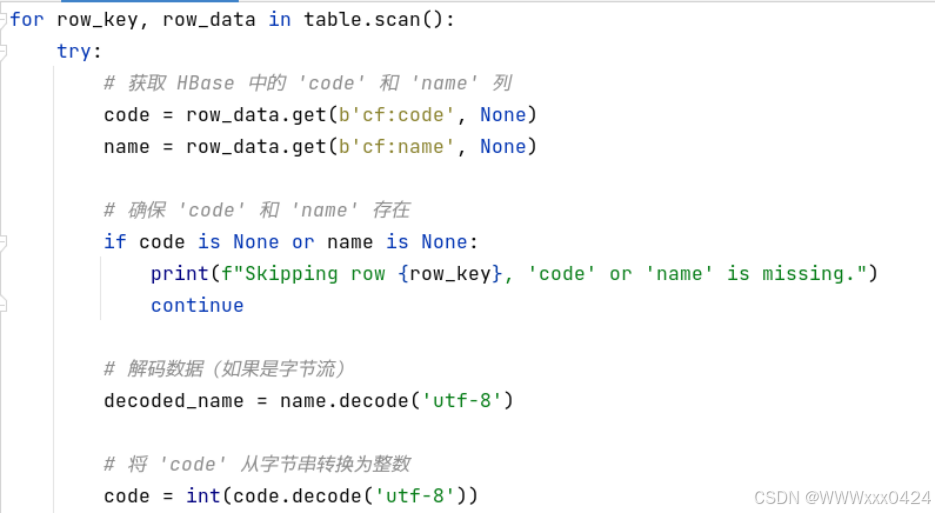
通过循环扫描HBase表(table.scan()),精确提取code和name列的数据。在提取过程中,考虑到数据可能以字节流形式存储,使用decode('utf-8')对字节流数据进行正确解码,确保数据能够被正确处理。
4.3.3数据插入与异常处理

存入MySQL的数据如下:





4.4 搭建Redis分布式集群
4.4.1创建集群目录与节点实例准备
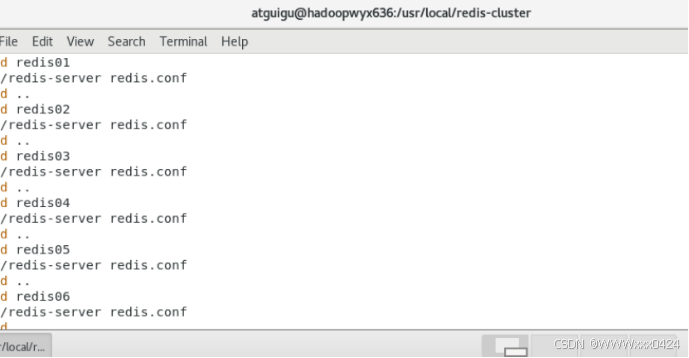
- 在/usr/local目录下新建redis-cluster目录,用于存放集群节点。
- 将redis目录下bin目录的所有文件复制到/usr/local/redis-cluster/redis01目录下(自动创建redis01目录),命令为 cp -r redis/bin/ redis-cluster/redis01。
- 删除redis01目录下的快照文件dump.rdb,并修改redis.conf文件。修改内容包括将端口号修改为 7001,开启集群创建模式(打开cluster-enabled yes的注释)。
- 将redis-cluster/redis01文件复制5份到redis-cluster目录下(创建redis02 - redis06目录),并分别修改其余5个文件下的redis.conf里面的端口号为7002 - 7006。
4.4.2启动 Redis 节点
- 创建批量启动 redis 节点的脚本文件 start-all.sh,文件内容如下:
- 修改start-all.sh脚本的权限,使之能够执行,指令为chmod +x start-all.sh。
- 执行start-all.sh脚本,启动6个redis节点。
4.4.3复制Ruby脚本工具并搭建集群
- 将redis/src目录下的redis-trib.rb文件复制到redis-cluster目录下,指令为cp redis-trib.rb /usr/local/redis-cluster。
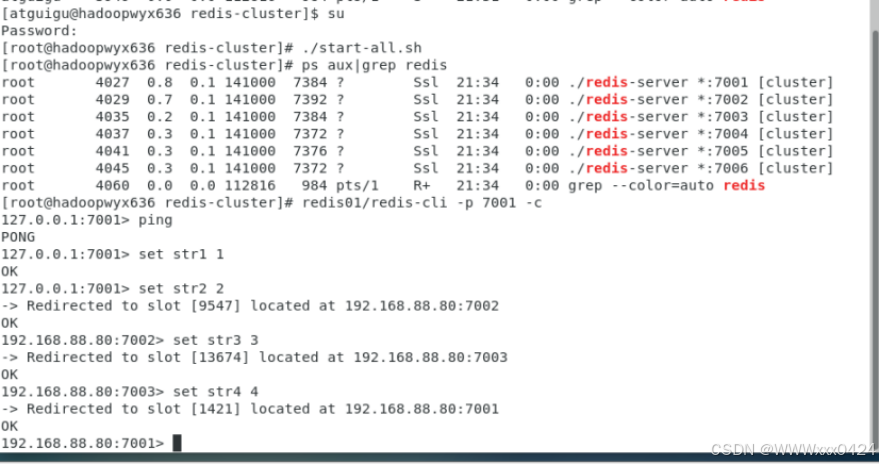
- 使用该脚本文件搭建集群,指令为./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006,中途手动输入 yes 确认。
4.4.4连接集群节点
使用redis01/redis-cli -p 7001 -c命令连接集群节点。
4.5数据导入Redis
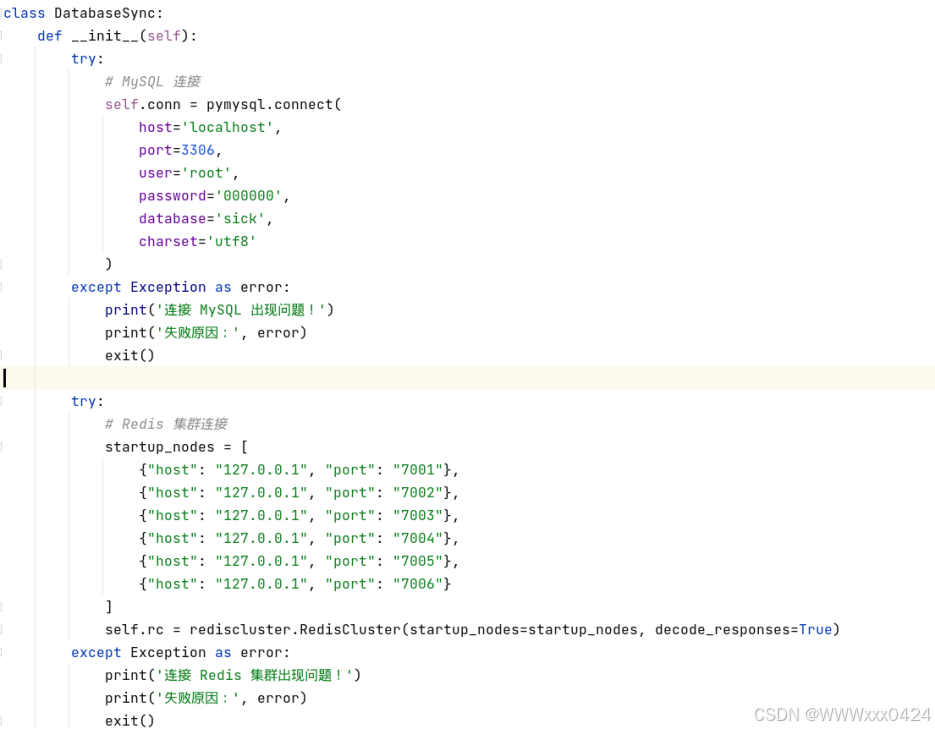
4.5.1连接建立(MySQL和Redis集群)
4.5.2数据缓存与更新
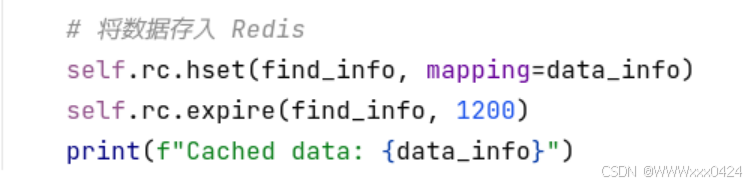
实现cache_data_from_mysql_to_redis方法达成MySQL到Redis的数据缓存。

为缓存数据设置了过期时间为1200秒,使用self.rc.expire方法实现,确保缓存数据的时效性,减少因数据过期导致的不一致问题。
4.5.3缓存管理与反馈
若查询到数据,通过self.rc.expire延长缓存过期时间至1200秒,确保数据可用性,并打印缓存命中信息。若未查询到数据,打印提示信息,方便后续业务处理。有效提升数据读取性能,减轻MySQL查询压力。

存入Redis的数据如下:

4.5.4解决Redis缓存持久性问题
可以使用save和bgsave手动保存redis内的数据,最后可以通过lastsave命令获取最后一次成功生成快照的时间,即时间戳。
4.5.5解决Redis中文输出乱码问题
修改启动Redis客户端时的命令。例: redis01/redis-cli -p 7001 -c --raw。

4.数据可视化
连接、搜索、加载、展示等功能模块
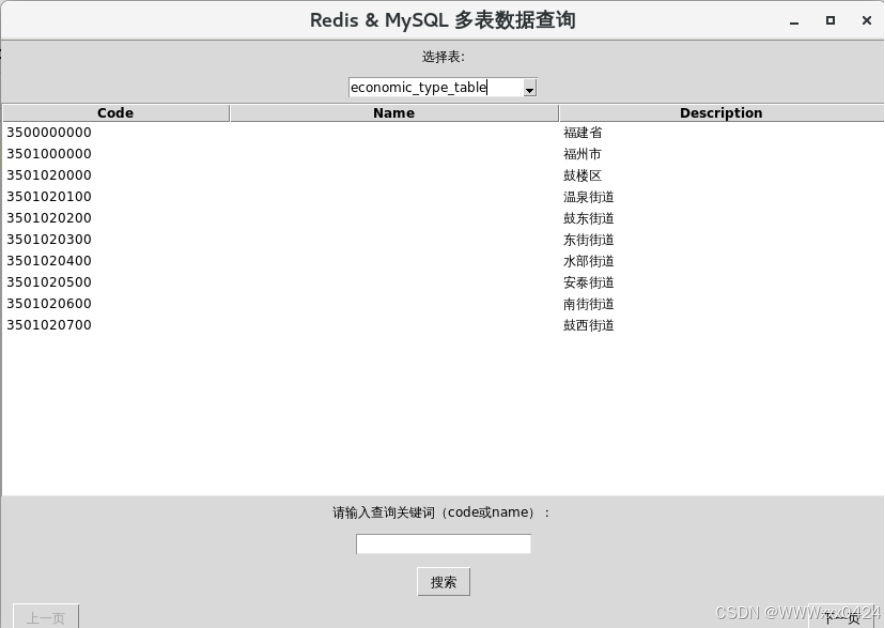
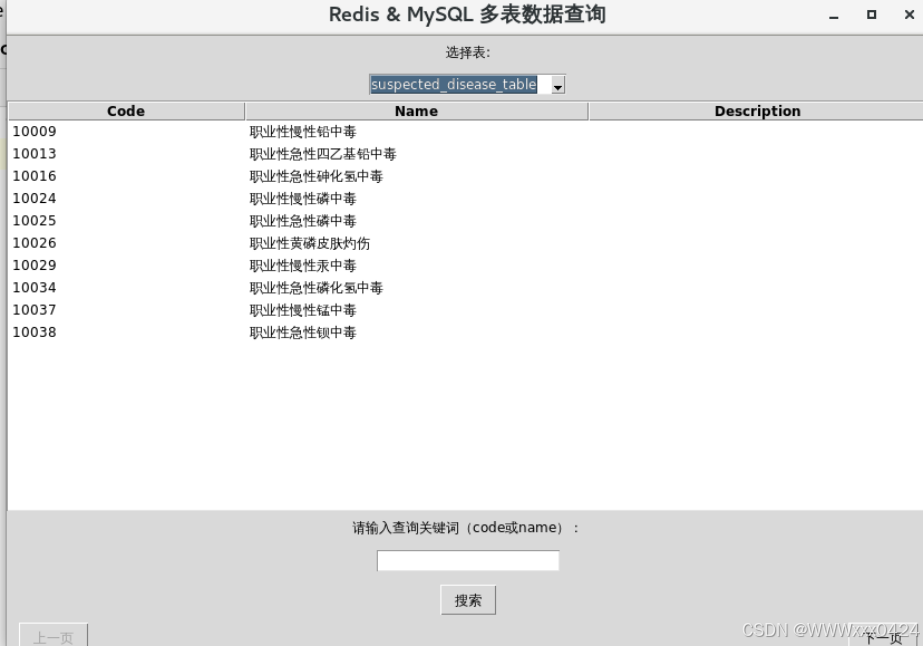
可选择的5张表部分:

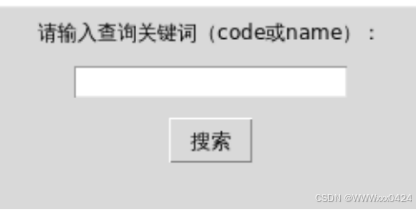
实现让用户输入查询关键词,并通过点击按钮触发相应的数据搜索操作,整体呈现出一个基础的搜索功能界面布局:

尝试建立与Redis集群的连接:

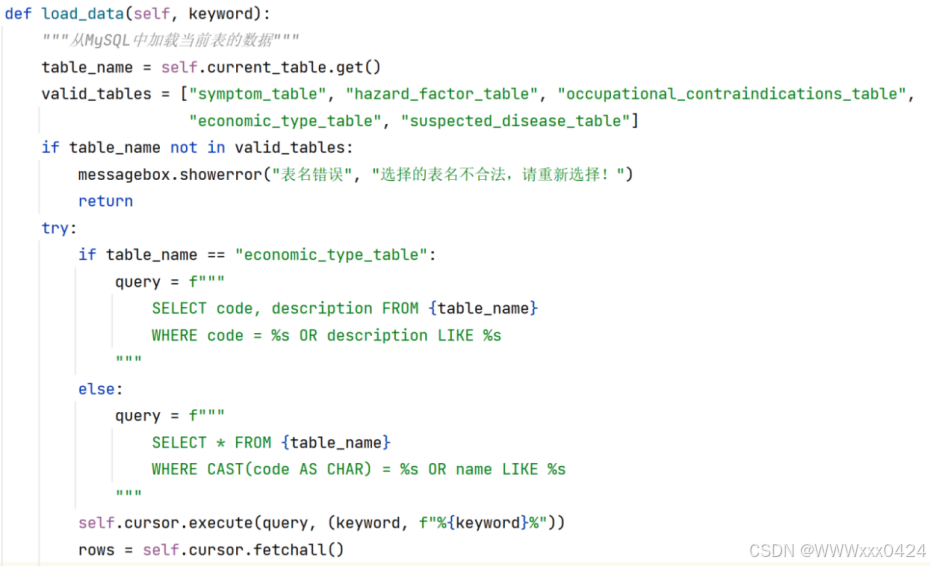
用户输入的关键词(keyword)从MySQL数据库中查询并获取当前选定表的数据:

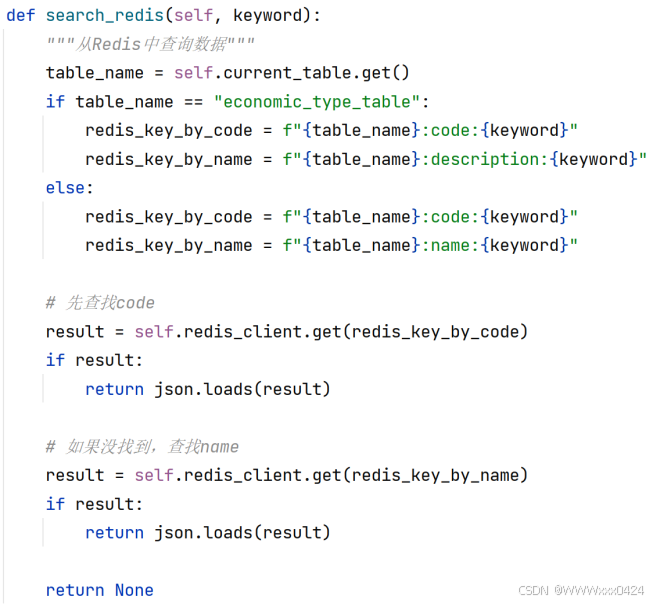
根据表名和查询关键词构造好用于在Redis中查询的键之后,进一步实现了从Redis中查找数据的完整流程:
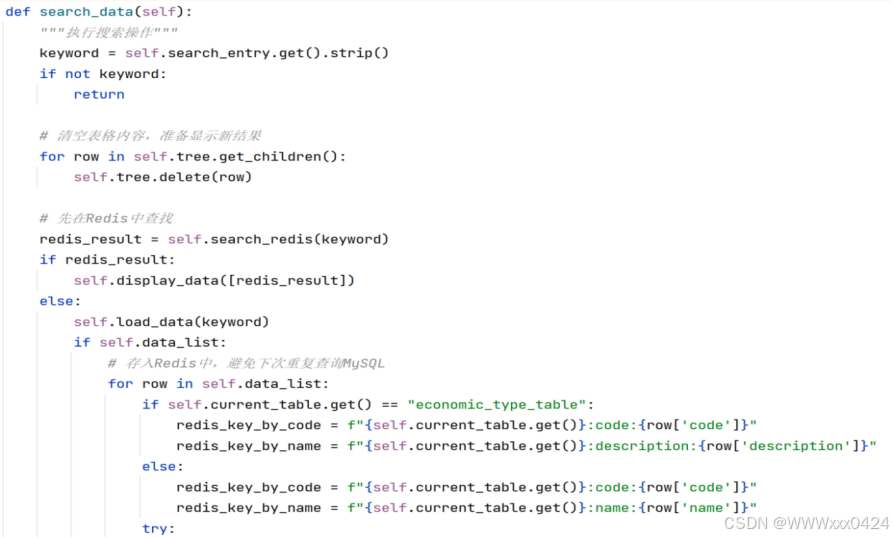
根据用户输入的关键词进行数据搜索的完整流程:

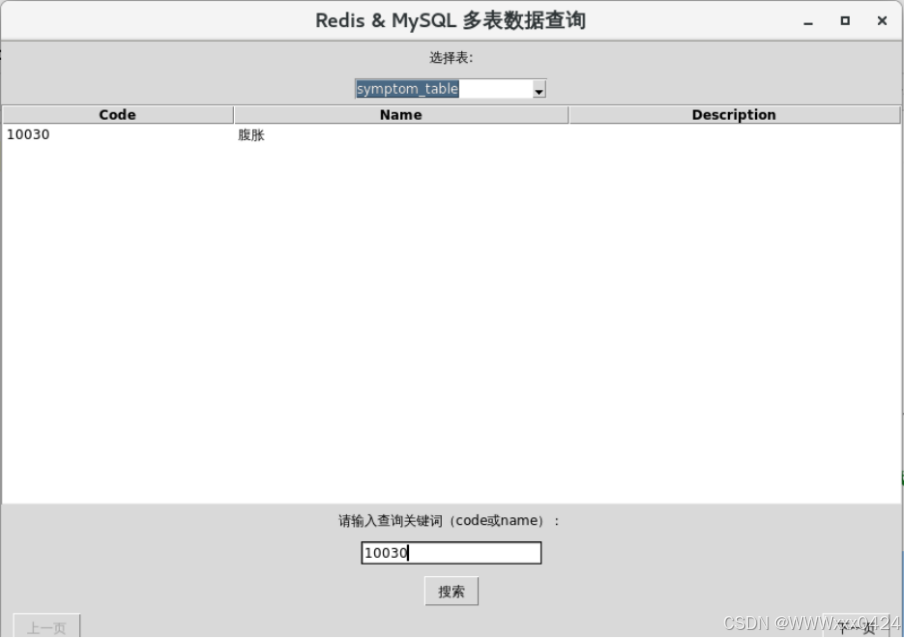
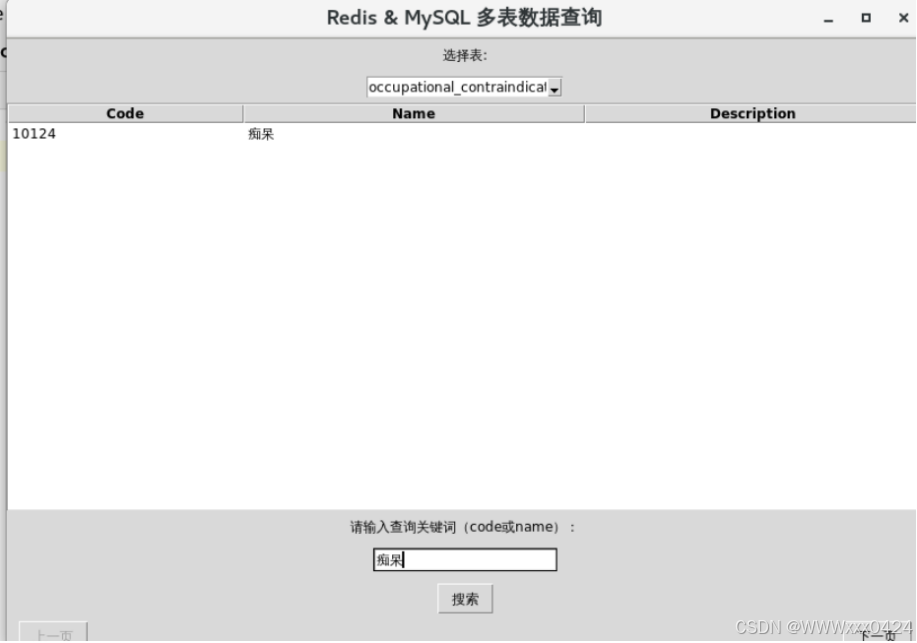
更换数据表:

更新分页按钮的可用状态:
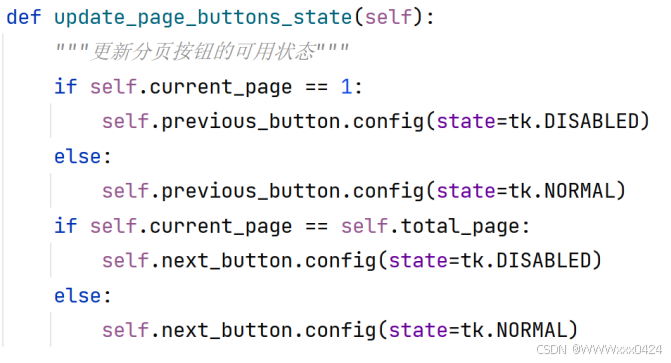
实现分页展示数据:
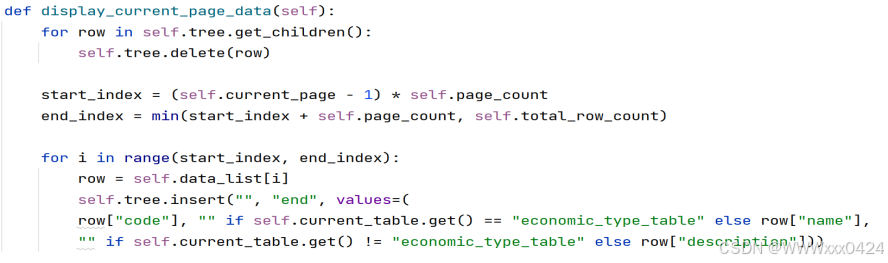
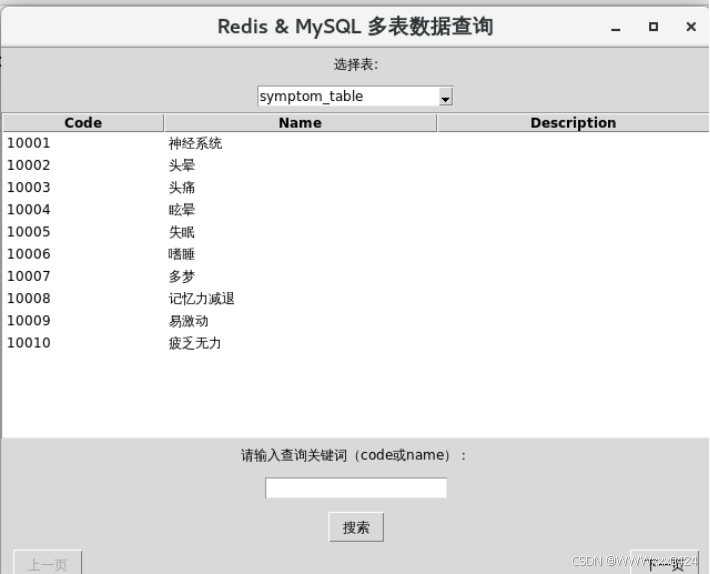
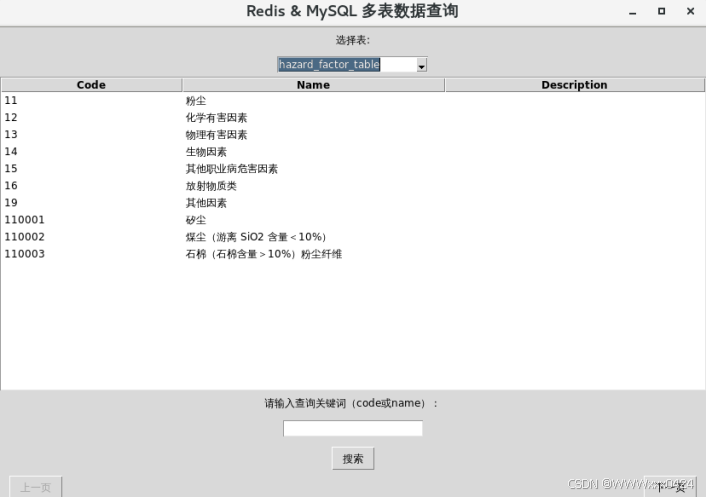
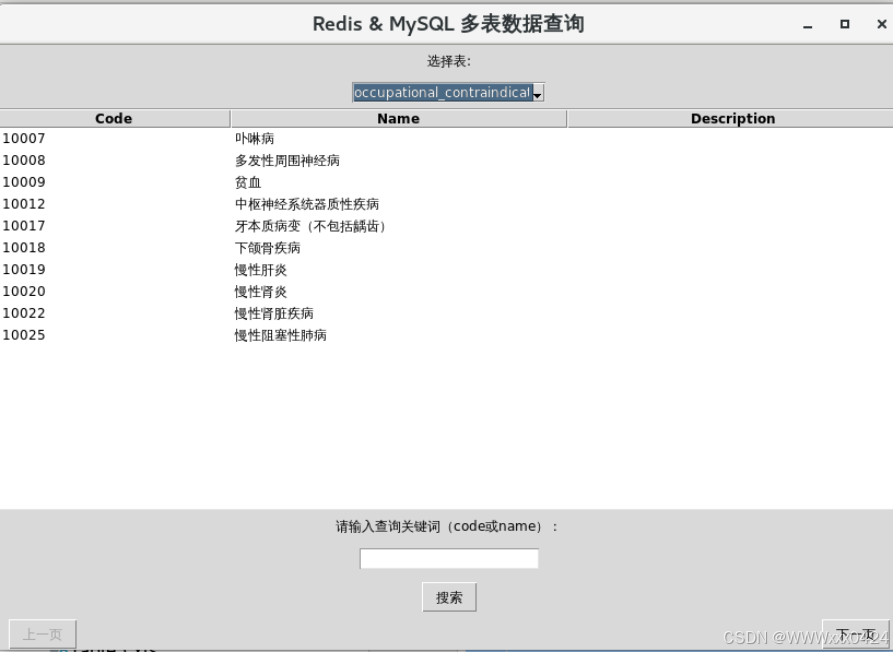
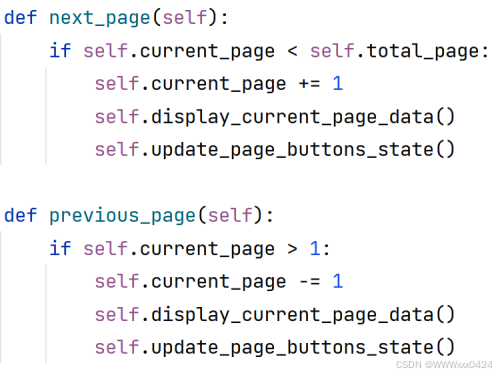
实现翻到上一页和下一页数据的功能:
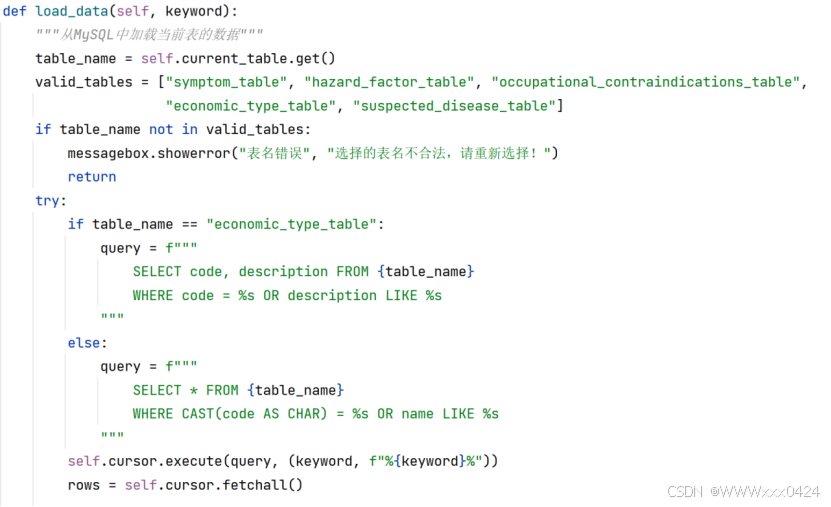
从MySQL中加载当前表的数据:
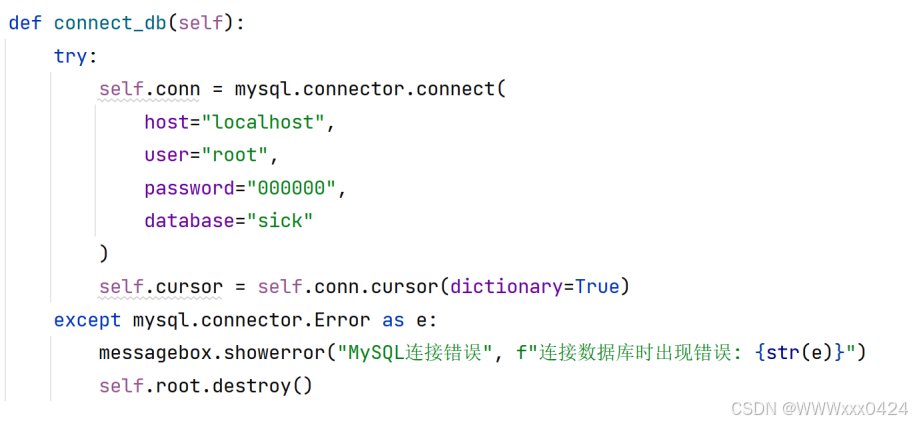
建立与MySQL数据库的连接,并初始化一个游标对象
5.项目总结
完成了项目要求的搭建具备至少 3 个节点的HBase分布式数据库,随后从 “职业病防治信息管理平台标准库.xls”里随机挑出5项数据,依据其结构设计了五张 相对应的HBase表并导入数据,接着借助Pycharm把HBase表数据导入MySQL数据库,然后搭建Redis分布式集群并用于缓存MySQL数据,最后实现数据可视化,对MySQL数据分页显示且支持关键字搜索,搜索时先查Redis,若查不到再查MySQL,比如在体检项目表中,输入编码“13907”或类别“神经系统”都能快速获取对应信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









