







nio:non-blocking io 非阻塞 IO
nio的三大组件
Channel & Buffer & Selector
- channel
channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 stream 要么是输入,要么是输出,channel 比 stream 更为底层
常见的channel
FileChannel // 文件
DatagramChannel // UDP
SocketChannel // TCP client端
ServerSocketChannel // TCP server端
- buffer
buffer 则用来缓冲读写数据,常见的 buffer
ByteBuffer
MappedByteBuffer
DirectByteBuffer
HeapByteBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
CharBuffer
- selector
selector 单从字面意思不好理解,需要结合服务器的设计演化来理解它的用途
1:多线程版设计
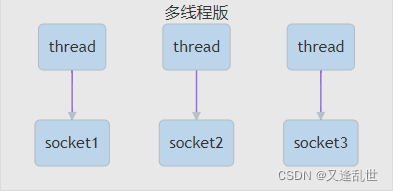
缺点:
-
内存占用高
-
线程上下文切换成本高
-
一个连接就占用一个线程,只适合连接数少的场景
2:线程池版设计
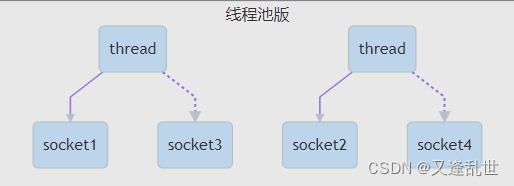
缺点:
-
阻塞模式下,线程仅能处理一个 socket 连接
-
仅适合短连接场景
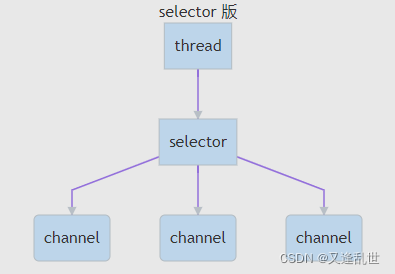
3:selector版设计
selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic)
调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理
读取文件示例切入知识点
public static void main(String[] args) {
// nio的方式
try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {
// 准备缓冲区 ,allocate(字节大小)
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true){
// 从 channel读取数据,向 buffer 写入
int len = channel.read(buffer);
if (-1 == len) {
break;
}
// 切换到读模式
buffer.flip();
while (buffer.hasRemaining()) { // 检测 是否还有剩余未读数据
byte b = buffer.get();
System.err.println((char) b);
}
buffer.clear(); // 切换到写模式
}
} catch (IOException e) {
e.printStackTrace();
}
}ByteBuffer 正确使用姿势
-
向 buffer 写入数据,例如调用 channel.read(buffer)
-
调用 flip() 切换至读模式
-
从 buffer 读取数据,例如调用 buffer.get()
-
调用 clear() 或 compact() 切换至写模式
-
重复 1~4 步骤
buffer是非线程安全的
ByteBuffer的常用函数
- 分配空间
/**
* 分配内存空间
*/
ByteBuffer.allocate(10);
ByteBuffer.allocateDirect(10);
// 区别
allocate: 类型 java.nio.HeapByteBuffer, 1:java堆内存,2:受到GC的影响,3:读写效率较低
allocateDirect:类型 java.nio.DirectByteBuffer, 1:直接内存,2:使用系统内存不会受到java GC的影响,3:读写效率高(少一次拷贝),4:分配内存的效率较低(调用系统分配内存的方法),使用不当会造成内存泄露- 向 buffer 中写入数据
// 1: 将channel中的数据写入到buffer
channel.read(buffer);
// 2: 调用buffer的put方法
buffer.put((byte)69);
- 从 buffer 中读取数据
// 1: 从 buffer 中读取数据,写到 channel 中
int bytes = channel.write(buffer);
// 2: 调用 buffer 的 get方法
byte b = buffer.get();
// 读取指定下标位置的数据,不会改变 position 的位置
buffer.get(int 字节下标);
// 读取指定的字节数,返回一个新的 buffer
ByteBuffer get(byte[] dst) get 方法会让 position 读指针向后走不能重复读取,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
- mark & reset
mark 做一个标记,记录 position 位置,reset 是将 position 重置到 mark 的位置
// 分配一个10 字节大小 的 buffer
ByteBuffer buffer = ByteBuffer.allocate(10);
// 向 buffer 中写入数据
buffer.put(new byte[]{'a', 'b', 'c', 'd'});
// 切换到读模式
buffer.flip();
// mark & reset
// mark 做一个标记,记录 position 位置,reset 是将 position 重置到 mark 的位置
System.err.println((char) buffer.get());
System.err.println((char) buffer.get());
buffer.mark(); // 读了两次 后 打了个标记
System.err.println((char) buffer.get());
System.err.println((char) buffer.get());
buffer.reset(); // 重置 position 位置到 mark 标记的位置
System.err.println((char) buffer.get());
System.err.println((char) buffer.get());
/*
* 打印结果
* a
* b
* c
* d
* c
* d
*/字符串 与 ByteBuffer 之间的互相转换
字符串转 ByteBuffer
// 第一种方式 // 字符串转 ByteBuffer
ByteBuffer buffer1 = ByteBuffer.allocate(10);
buffer1.put("hello_1".getBytes(StandardCharsets.UTF_8));
buffer1.flip(); // 切换读模式
System.err.println((char) buffer1.get()); // 打印 h
// 第二种方式 // 字符串转 ByteBuffer
ByteBuffer buffer2 = StandardCharsets.UTF_8.encode("hello_2"); // 这种转换的方式,自动切换到 读模式
System.err.println((char) buffer2.get()); // 打印 h
// 第三种方式 // 字符串转 ByteBuffer
ByteBuffer buffer3 = ByteBuffer.wrap("hello_3".getBytes(StandardCharsets.UTF_8)); // 这种转换的方式,自动切换到 读模式
System.err.println((char) buffer3.get()); // 打印 hByteBuffer 转字符串
buffer1.flip(); // buffer1 没有自动切换读模式,要先切换到读模式
CharBuffer charBuffer1 = StandardCharsets.UTF_8.decode(buffer1);
String str1 = charBuffer1.toString();
System.err.println(str1); // 打印 ello_1
CharBuffer charBuffer2 = StandardCharsets.UTF_8.decode(buffer2);
String str2 = charBuffer2.toString();
System.err.println(str2); // 打印 ello_2- Scattering Reads 分散读取
需求,有一段文本文件,文件中有多部分内容,例如 zhangsanlisi,两个名字,需要把这段文本分开获取
/*
* 在已知长度的情况下
*/
try (RandomAccessFile file = new RandomAccessFile("data2.txt", "rw")) {
FileChannel channel = file.getChannel();
ByteBuffer zBuffer = ByteBuffer.allocate(8);
ByteBuffer lBuffer = ByteBuffer.allocate(4);
channel.read(new ByteBuffer[]{zBuffer, lBuffer});
zBuffer.flip();
lBuffer.flip();
CharBuffer zChar = StandardCharsets.UTF_8.decode(zBuffer);
String z = zChar.toString();
System.err.println(z);
CharBuffer lChar = StandardCharsets.UTF_8.decode(lBuffer);
String l = lChar.toString();
System.err.println(l);
} catch (IOException e) {
e.printStackTrace();
}- Gathering Writes 集中写入
ByteBuffer zhangSanBuffer = StandardCharsets.UTF_8.encode("zhangSan");
ByteBuffer liSiBuffer = StandardCharsets.UTF_8.encode("liSi");
ByteBuffer wWuBuffer = StandardCharsets.UTF_8.encode("王五");
try (FileChannel channel = new RandomAccessFile("data3.txt", "rw").getChannel()) {
channel.write(new ByteBuffer[]{zhangSanBuffer, liSiBuffer, wWuBuffer});
} catch (IOException e) {
e.printStackTrace();
}粘包、半包
需求:网络数据传输到服务器端,多条数据之间使用\n符号进行分隔,但由于某种原因导致数据在接收时进行了重新组合
例如:
// 发送数据
zhangsan\n
lisi\n
wWu\n
// 接收数据
zhangsan\nlis // 粘包,一条数据中组合了另一条的数据叫黏包
i\nwWu\n // 半包,一条数据被分开了叫半包
解决办法:
public static void main(String[] args) {
ByteBuffer source = ByteBuffer.allocate(12);
source.put("zhangsan\nlis".getBytes(StandardCharsets.UTF_8));
split(source);
source.put("i\nwWu\n".getBytes(StandardCharsets.UTF_8));
split(source);
}
/**
* 处理粘包、半包
* 遇到\n符读一次,没有读完的和下次组合在一起读
*/
private static void split(ByteBuffer source) {
source.flip(); // 切换到读模式
for (int i = 0; i < source.limit(); i++) {
// 遇到换行符,表示找到一条完整的消息
if (source.get(i) == '\n'){
// 得到消息长度,= 换行符的索引 + 1 - 数据起始位置
int len = i + 1 - source.position();
// 把完整的消息写入一个新的 ByteBuffer
ByteBuffer target = ByteBuffer.allocate(len);
// 从 source 读,向 target 写
for (int j = 0; j < len; j++) {
target.put(source.get());
}
// 打印结果
target.flip();
String s = StandardCharsets.UTF_8.decode(target).toString();
System.err.println(s);
}
}
source.compact(); // 切换到写模式,这里不能使用 clear()切换到写模式,因为clear会把 buffer数据清空从position 0 重新写
}FileChannel
FileChannel 只能工作在阻塞模式下
- 获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法
* 通过 FileInputStream 获取的 channel 只能读
* 通过 FileOutputStream 获取的 channel 只能写
* 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
- 读取
会从 channel 读取数据填充 ByteBuffer,返回值表示读到了多少字节,-1 表示到达了文件的末尾
int readBytes = channel.read(buffer);- 写入
写入的正确姿势如下, SocketChannel有写入的上限
ByteBuffer buffer = ...;
buffer.put(...); // 存入数据
buffer.flip(); // 切换读模式
while(buffer.hasRemaining()) { // 先检查是否还有数据
channel.write(buffer);
}在 while 中调用 channel.write 是因为 write 方法并不能保证一次将 buffer 中的内容全部写入 channel
- 关闭
channel 必须关闭,不过调用了 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 close 方法会间接地调用 channel 的 close 方法
- 位置
获取当前位置
long pos = channel.position();设置当前位置
long newPos = ...;
channel.position(newPos);设置当前位置时,如果设置为文件的末尾
* 这时读取会返回 -1
* 这时写入,会追加内容,但要注意如果 position 超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00)
- 大小
使用 size 方法获取文件的大小
- 强制写入
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘。可以调用 force(true) 方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘
-
两个 Channel 传输数据
String FROM = "helloword/data.txt";
String TO = "helloword/to.txt";
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
from.transferTo(0, from.size(), to);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("transferTo 用时:" + (end - start) / 1000_000.0);- 超过 2g 大小的文件传输
public class TestFileChannelTransferTo {
public static void main(String[] args) {
try (
FileChannel from = new FileInputStream("data.txt").getChannel();
FileChannel to = new FileOutputStream("to.txt").getChannel();
) {
// 效率高,底层会利用操作系统的零拷贝进行优化
long size = from.size();
// left 变量代表还剩余多少字节
for (long left = size; left > 0; ) {
System.out.println("position:" + (size - left) + " left:" + left);
left -= from.transferTo((size - left), left, to);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 输出
position:0 left:7769948160
position:2147483647 left:5622464513
position:4294967294 left:3474980866
position:6442450941 left:1327497219下一章知识点请阅读:网络编程
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











