







JAVA系统中常用算法归类:
一、限流算法
每个API接口都是有访问上限的,当访问频率或者并发量超过其承受范围时候,我们就必须考虑限流来保证接口的可用性或者降级可用性.即接口也需要安装上保险丝,以防止非预期的请求对系统压力过大而引起的系统瘫痪.
漏桶算法,令牌桶算法,计数算法
- 漏桶算法
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率
- 令牌桶算法
令牌桶算法(Token Bucket)和 Leaky Bucket 效果一样但方向相反的算法,更加容易理解.随着时间流逝,系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10ms)往桶里加入Token(想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了.新请求来临时,会各自拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务.
- 计数算法
按照设定的速率对每个请求进行计算,然后滑动窗口来判断是否超过限制。
相关组件
- Google开源工具包Guava提供了限流工具类RateLimiter
- (网关限流)Spring Cloud Zuul RateLimit项目Github地址 https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit
- eureka组件实现的令牌桶限流
应用场景
- 接口调用频率限制
- 程序逻辑执行速率控制
- 事务超频处理
- 网关请求限流
二、分布式算法
负载均衡算法:
- Hash算法,一致性hash(环形hash),虚拟节点
常用的算法:是对hash结果取余数 (hash() mod N ):对机器编号从0到N-1,按照自定义的 hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器。
1、算法简述
一致性哈希算法(Consistent Hashing Algorithm)是一种分布式算法,常用于负载均衡。Memcached client也选择这种算法,解决将key-value均匀分配到众多Memcached server上的问题。它可以取代传统的取模操作,解决了取模操作无法应对增删Memcached Server的问题(增删server会导致同一个key,在get操作时分配不到数据真正存储的server,命中率会急剧下降)。
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - (2^32)-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和(2^32)-1在零点中方向重合。
下一步将各个服务器使用H进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如下:

接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性哈希算法,数据A会被定为到Server 1上,D被定为到Server 3上,而B、C分别被定为到Server 2上。
2、容错性与可扩展性分析
下面分析一致性哈希算法的容错性和可扩展性。现假设Server 3宕机了:

可以看到此时A、C、B不会受到影响,只有D节点被重定位到Server 2。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果我们在系统中增加一台服务器Memcached Server 4:

此时A、D、C不受影响,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
3、虚拟节点
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:

此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六个虚拟节点:

- 轮循算法
多个节点轮流选择,轮询负载表现为每个节点依次路由。
利用JDK的concurrent包下 AtomicInteger 原子操作类的CAS原理,进行整数自增,然后对节点数取模,得到本次轮询的索引。
- 最少连接算法
逐个考察Server,如果Server被tripped了,则忽略,在选择其中ActiveRequestsCount最小的server。该策略性能较差
- 随机算法
随机产生实例选择的索引,算法简单,性能高,负载在小范围内不均匀
- 加权法
环形hash算法+虚拟节点,使请求根据权重值,不均匀分布。
- 响应速度算法
每次路由记录响应时间,选择响应时间最短的实例进行路由。保证不同硬件环境下实例可资源均衡利用。
相关组件:
- nginx 负载均衡配置
- springcloud-ribbon 负载均衡
分布式计算算法:
- Paxos算法
Paxos主要用于保证分布式存储中副本(或者状态)的一致性。副本要保持一致,那么,所有副本的更新序列就要保持一致。解决分布式条件下的一致性问题,
Paxos解决这一问题利用的是选举,少数服从多数的思想,只要2N+1个节点中,有N个以上同意了某个决定,则认为系统达到了一致
https://www.cnblogs.com/esingchan/p/3917718.html
相关组件:
- Google的Chubby、MegaStore
- Spanner数据库
- Hadoop中的ZooKeeper
- Raft算法
过去, Paxos一直是分布式协议的标准,但是Paxos难于理解,更难以实现,Google的分布式锁系统Chubby作为Paxos实现曾经遭遇到很多坑。
来自Stanford的新的分布式协议研究称为Raft,它是一个为真实世界应用建立的协议,主要注重协议的落地性和可理解性。
https://www.jdon.com/artichect/raft.html
三、排序算法
https://www.cnblogs.com/guoyaohua/p/8600214.html
- 冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
public static void bubbleSort(int[] numbers) { int temp = 0; int size = numbers.length; for(int i = 0 ; i < size-1; i ++) { for(int j = 0 ;j < size-1-i ; j++) { if(numbers[j] > numbers[j+1]) //交换两数位置 { temp = numbers[j]; numbers[j] = numbers[j+1]; numbers[j+1] = temp; } } } }
- 选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
/** * 选择排序 * @param array * @return */ public static int[] selectionSort(int[] array) { if (array.length == 0) return array; for (int i = 0; i < array.length; i++) { int minIndex = i; for (int j = i; j < array.length; j++) { if (array[j] < array[minIndex]) //找到最小的数 minIndex = j; //将最小数的索引保存 } int temp = array[minIndex]; array[minIndex] = array[i]; array[i] = temp; } return array; }
- 插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
/** * 插入排序 * @param array * @return */ public static int[] insertionSort(int[] array) { if (array.length == 0) return array; int current; for (int i = 0; i < array.length - 1; i++) { current = array[i + 1]; int preIndex = i; while (preIndex >= 0 && current < array[preIndex]) { array[preIndex + 1] = array[preIndex]; preIndex--; } array[preIndex + 1] = current; } return array; }
- 希尔排序
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
/** * 希尔排序 * * @param array * @return */ public static int[] ShellSort(int[] array) { int len = array.length; int temp, gap = len / 2; while (gap > 0) { for (int i = gap; i < len; i++) { temp = array[i]; int preIndex = i - gap; while (preIndex >= 0 && array[preIndex] > temp) { array[preIndex + gap] = array[preIndex]; preIndex -= gap; } array[preIndex + gap] = temp; } gap /= 2; } return array; }
- top k 算法(小顶堆算法)
问题描述:有N(N>>10000)个整数,求出其中的前K个最大的数。(称作Top k或者Top 10)
问题分析:由于(1)输入的大量数据;(2)只要前K个,对整个输入数据的保存和排序是相当的不可取的。
可以利用数据结构的最小堆来处理该问题。
最小堆如图所示,对于每个非叶子节点的数值,一定不大于孩子节点的数值。这样可用含有K个节点的最小堆来保存K个目前的最大值(当然根节点是其中的最小数值)。
每次有数据输入的时候可以先与根节点比较。若不大于根节点,则舍弃;否则用新数值替换根节点数值。并进行最小堆的调整。
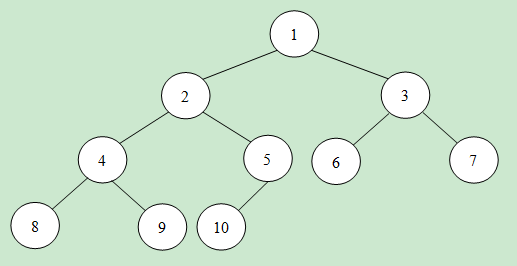
实现代码以及说明:
package AlgorithmTopK; public class TopK { public int[] createHeapOther(int a[], int k) { int[] result = new int[k]; for (int i = 0; i < k; i++) { result[i] = a[i]; } for (int i = 1; i < k; i++) { int child = i; int parent = (i - 1) / 2; int temp = a[i]; while (parent >= 0 &&child!=0&& result[parent] >temp) { result[child] = result[parent]; child = parent; parent = (parent - 1) / 2; } result[child] = temp; } return result; } public int[] createHeap(int input[], int K) { //创建小根堆,复杂度最坏是nlgK int heap[] = new int[K]; for(int i=0;i<K;i++) heap[i] = input[i]; for(int i = 1;i < heap.length;i++) { int child = i; int parent = (child-1) / 2; while(parent >= 0 && child!=0 && heap[parent] > heap[child]) { int temp = heap[child]; heap[child] = heap[parent]; heap[parent] = temp; child = parent; parent = (parent - 1) / 2; } } return heap; } public void insertHeap(int heap[], int value) { heap[0] = value; int parent = 0; while(parent<heap.length) { //这个循环复杂度最坏是 logK int lchild = parent*2 + 1; int rchild = parent*2 + 2; int minIndex = parent; //指向左右儿子中最小的 if(lchild < heap.length && heap[lchild] < heap[parent]) minIndex = lchild; if(rchild < heap.length && heap[rchild] < heap[minIndex]) minIndex = rchild; if(minIndex == parent) { break; } else { int temp = heap[minIndex]; heap[minIndex] = heap[parent]; heap[parent] = temp; parent = minIndex; } } } public int[] getTopKByHeap(int input[], int K) { int result[] = createHeap(input, K); //复杂度最坏是 O(nlgK) for(int i=K;i<input.length;i++) { if(input[i] > result[0]) insertHeap(result, input[i]); //复杂度最坏是O(nlgK),而且内存消耗就K,不然海量数据排序,内存放不下,得用归并排序,最好最坏平均都是 O(nlgn) } return result; } public static void main(String[] args) { int a[] = {4,3,5,1,2,8,9,10};//待找TOP K 的排海量数据N int result[] = new TopK().getTopKByHeap(a, 6); System.out.print("TOP K is :"); for(int resultItem : result) { System.out.print(resultItem + " "); } }
四、信息安全算法
加解密算法:
算法选择:对称加密AES,非对称加密: ECC,消息摘要: MD5,数字签名:DSA
对称加密算法(加解密密钥相同)
| 名称 | 密钥长度 | 运算速度 | 安全性 | 资源消耗 |
| DES | 56位 | 较快 | 低 | 中 |
| 3DES | 112位或168位 | 慢 | 中 | 高 |
| AES | 128、192、256位 | 快 | 高 | 低 |
非对称算法(加密密钥和解密密钥不同)
| 名称 | 成熟度 | 安全性(取决于密钥长度) | 运算速度 | 资源消耗 |
| RSA | 高 | 高 | 慢 | 高 |
| DSA | 高 | 高 | 慢 | 只能用于数字签名 |
| ECC | 低 | 高 | 快 | 低(计算量小,存储空间占用小,带宽要求低) |
散列算法比较
| 名称 | 安全性 | 速度 |
| SHA-1 | 高 | 慢 |
| MD5 | 中 | 快 |
对称与非对称算法比较
| 名称 | 密钥管理 | 安全性 | 速度 |
| 对称算法 | 比较难,不适合互联网,一般用于内部系统 | 中 | 快好几个数量级(软件加解密速度至少快100倍,每秒可以加解密数M比特数据),适合大数据量的加解密处理 |
| 非对称算法 | 密钥容易管理 | 高 | 慢,适合小数据量加解密或数据签名 |
算法选择(从性能和安全性综合)
对称加密: AES(128位),
非对称加密: ECC(160位)或RSA(1024),
消息摘要: MD5
数字签名:DSA
轻量级:TEA、RC系列(RC4),Blowfish (不常换密钥)
速度排名(个人估测,未验证):IDEA <DES <GASTI28<GOST<AES<RC4<TEA<Blowfish
简单的加密设计: 用密钥对原文做 异或,置换,代换,移位
| 名称 | 数据大小(MB) | 时间(s) | 平均速度MB/S | 评价 |
| DES | 256 | 10.5 | 22.5 | 低 |
| 3DES | 256 | 12 | 12 | 低 |
| AES(256-bit) | 256 | 5 | 51.2 | 中 |
| Blowfish | 256 | 3.7 | 64 | 高 |
| 表5-3 单钥密码算法性能比较表 |
| 名称 | 实现方式 | 运算速度 | 安 全 性 | 改进措施 | 应用场合 |
| DES | 40-56bit 密钥 | 一般 | 完全依赖密钥,易受穷举搜索法攻击 | 双重、三重DES,AES | 适用于硬件实现 |
| IDEA | 128bit密钥 8轮迭代 | 较慢 | 军事级,可抗差值分析和相关分析 | 加长字长为32bit、密钥为256bit,采用232 模加、232+1模乘 | 适用于ASIC设计 |
| GOST | 256bit密钥 32轮迭代 | 较快 | 军事级 | 加大迭代轮数 | S盒可随机秘 密选择,便于软件实现 |
| Blowfish | 256-448bit 密钥、16轮迭代 | 最快 | 军事级、可通过改变密钥长度调整安全性 |
| 适合固定密钥场合,不适合常换密钥和智能卡 |
| RC4 | 密钥长度可变 | 快DESl0倍 | 对差分攻击和线性攻击具有免疫能力,高度非线性 | 密钥长度放宽到64bit | 算法简单,易于编程实现 |
| RC5 | 密钥长度和迭代轮数均可变 | 速度可根据 三个参数的 值进行选择 | 六轮以上时即可抗线性攻击、通过调整字长、密钥长度和迭代轮数可以在安全性和速度上取得折中 | 引入数据相倚转 | 适用于不同字长的微处理器 |
| CASTl28 | 密钥长度可变、16轮迭代 | 较快 | 可抵抗线性和差分攻击 | 增加密钥长度、形成CAST256 | 适用于PC机和 UNIX工作站 |
常见加密算法
1、DES(Data Encryption Standard):对称算法,数据加密标准,速度较快,适用于加密大量数据的场合;
2、3DES(Triple DES):是基于DES的对称算法,对一块数据用三个不同的密钥进行三次加密,强度更高;
3、RC2和RC4:对称算法,用变长密钥对大量数据进行加密,比 DES 快;
4、IDEA(International Data Encryption Algorithm)国际数据加密算法,使用 128 位密钥提供非常强的安全性;
5、RSA:由 RSA 公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的,非对称算法;
6、DSA(Digital Signature Algorithm):数字签名算法,是一种标准的 DSS(数字签名标准),严格来说不算加密算法;
7、AES(Advanced Encryption Standard):高级加密标准,对称算法,是下一代的加密算法标准,速度快,安全级别高,在21世纪AES 标准的一个实现是 Rijndael 算法;
8、BLOWFISH,它使用变长的密钥,长度可达448位,运行速度很快;
9、MD5:严格来说不算加密算法,只能说是摘要算法;
10、PKCS:The Public-Key Cryptography Standards (PKCS)是由美国RSA数据安全公司及其合作伙伴制定的一组公钥密码学标准,其中包括证书申请、证书更新、证书作废表发布、扩展证书内容以及数字签名、数字信封的格式等方面的一系列相关协议。
11、SSF33,SSF28,SCB2(SM1):国家密码局的隐蔽不公开的商用算法,在国内民用和商用的,除这些都不容许使用外,其他的都可以使用;
12、ECC(Elliptic Curves Cryptography):椭圆曲线密码编码学。
13、TEA(Tiny Encryption Algorithm)简单高效的加密算法,加密解密速度快,实现简单。但安全性不如DES,QQ一直用tea加密















 3617
3617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









