






Linux内存管理机制
1.虚拟地址
为了充分利用和管理系统内存资源,Linux采用虚拟内存管理技术,利用虚拟内存技术让每个进程都有4GB 互不干涉的虚拟地址空间。
进程初始化分配和操作的都是基于这个「虚拟地址」,只有当进程需要实际访问内存资源的时候才会建立虚拟地址和物理地址的映射,调入物理内存页。
打个不是很恰当的比方,这个原理其实和现在的某某网盘一样。假如你的网盘空间是1TB,真以为就一口气给了你这么大空间吗?那还是太年轻,都是在你往里面放东西的时候才给你分配空间,你放多少就分多少实际空间给你,但你和你朋友看起来就像大家都拥有1TB空间一样。
虚拟地址的好处 (1)避免用户直接访问物理内存地址,防止一些破坏性操作,保护操作系统 (2)每个进程都被分配了4GB的虚拟内存,用户程序可使用比实际物理内存更大的地址空间 (3)4GB 的进程虚拟地址空间被分成两部分:「用户空间」和「内核空间」

2.物理地址
- **不管是用户空间还是内核空间,使用的地址都是虚拟地址,当需进程要实际访问内存的时候,会由内核的「请求分页机制」产生「缺页异常」调入物理内存页。**
- 把虚拟地址转换成内存的物理地址,这中间涉及利用MMU 内存管理单元(Memory Management Unit ) 对**虚拟地址分段和分页(段页式)地址转换**。
3.Linux 内核会将物理内存分为3个管理区
ZONE_DMA
DMA内存区域。包含0MB~16MB之间的内存页框,可以由老式基于ISA的设备通过DMA使用,直接映射到内核的地址空间。
ZONE_NORMAL
普通内存区域。包含16MB~896MB之间的内存页框,常规页框,直接映射到内核的地址空间。
ZONE_HIGHMEM
高端内存区域。包含896MB以上的内存页框,不进行直接映射,可以通过永久映射和临时映射进行这部分内存页框的访问。

4.用户空间
- **用户进程能访问的是「用户空间」,每个进程都有自己独立的用户空间**,虚拟地址范围从从 0x00000000 至 0xBFFFFFFF 总容量3G 。
- 用户进程通常只能访问用户空间的虚拟地址,只有在执行内陷操作或系统调用时才能访问内核空间。
5.进程与内存
进程(执行的程序)占用的用户空间按照访问属性「 访问属性一致的地址空间存放在一起 」的原则,划分成 5个不同的内存区域。访问属性指的是“可读、可写、可执行等 。
1. 代码段
代码段是用来存放可执行文件的操作指令,可执行程序在内存中的镜像。
代码段需要防止在运行时被非法修改,所以只准许读取操作,它是不可写的。
2. 数据段
数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
3. BSS段
BSS段包含了程序中未初始化的全局变量,在内存中 bss 段全部置零。
4. 堆 heap
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。
当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
5. 栈 stack
栈是用户存放程序临时创建的局部变量,也就是函数中定义的变量(但不包括 static 声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。
从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
上述几种内存区域中数据段、BSS 段、堆通常是被连续存储在内存中,在位置上是连续的,而代码段和栈往往会被独立存放。
堆和栈两个区域在 i386 体系结构中栈向下扩展、堆向上扩展,相对而生。

6.内核空间
- 在 x86 32 位系统里,Linux 内核地址空间是指虚拟地址从 0xC0000000 开始到 0xFFFFFFFF 为止的高端内存地址空间,总计 1G 的容量, 包括了内核镜像、物理页面表、驱动程序等运行在内核空间 。
- **DMA区(DMA Zone)**:DMA(Direct Memory Access)区域是专门为支持直接内存访问的设备设计的,因为某些硬件设备(比如早期的 ISA 设备)只能访问物理内存的某个范围(通常在 16MB 以下),这部分内存被保留在 DMA 区。
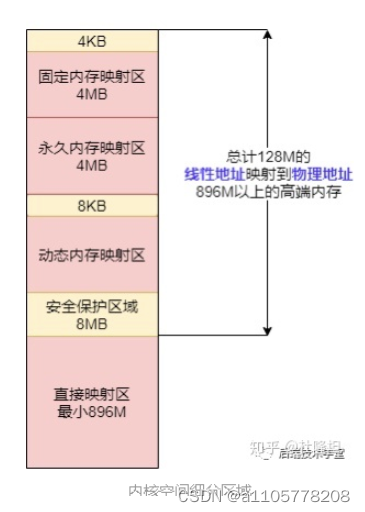
- **直接映射区**
(1)直接映射区 Direct Memory Region:从内核空间起始地址开始,最大896M的内核空间地址区间,为直接内存映射区。
(2)直接映射区的896MB的「线性地址」直接与「物理地址」的前896MB进行映射,也就是说线性地址和分配的物理地址都是连续的。内核地址空间的线性地址0xC0000001所对应的物理地址为0x00000001,它们之间相差一个偏移量PAGE_OFFSET = 0xC0000000
(3)该区域的线性地址和物理地址存在线性转换关系「线性地址 = PAGE_OFFSET + 物理地址」也可以用 virt_to_phys()函数将内核虚拟空间中的线性地址转化为物理地址。
- **高端内存线性地址空间**
(1)内核空间线性地址从 896M 到 1G 的区间,容量 128MB 的地址区间是高端内存线性地址空间,为什么叫高端内存线性地址空间?
下面给你解释一下:
前面已经说过,内核空间的总大小 1GB,从内核空间起始地址开始的 896MB 的线性地址可以直接映射到物理地址大小为 896MB 的地址区间。
请问你现在你家的内存条多大?快醒醒都2021年了,一般 PC 的内存都大于 1GB 了吧!
所以,内核空间拿出了最后的 128M 地址区间,划分成下面三个高端内存映射区,以达到对整个物理地址范围的寻址。而在 64 位的系统上就不存在这样的问题了,因为可用的线性地址空间远大于可安装的内存。
- **动态内存映射区**
vmalloc Region 该区域由内核函数vmalloc来分配,特点是:线性空间连续,但是对应的物理地址空间不一定连续。vmalloc 分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。
- **永久内存映射区**
Persistent Kernel Mapping Region 该区域可访问高端内存。访问方法是使用 alloc_page (_GFP_HIGHMEM) 分配高端内存页或者使用kmap函数将分配到的高端内存映射到该区域。这个区域通常用于长期映射的内存。比如说,内核需要长期使用的数据结构或者缓冲区就会被映射到这个区域。
- **固定映射区**
Fixing kernel Mapping Region 该区域和 4G 的顶端只有 4k 的隔离带,其每个地址项都服务于特定的用途,如 ACPI_BASE 等。这部分区域是为了满足一些特殊需求,比如高端内存(highmem)的映射,页表的初始化等。这部分区域的地址是固定的,而且这部分区域的大小也是固定的。


7.内存数据结构
这里列举两个管理虚拟内存区域的数据结构。
**用户空间内存数据结构**
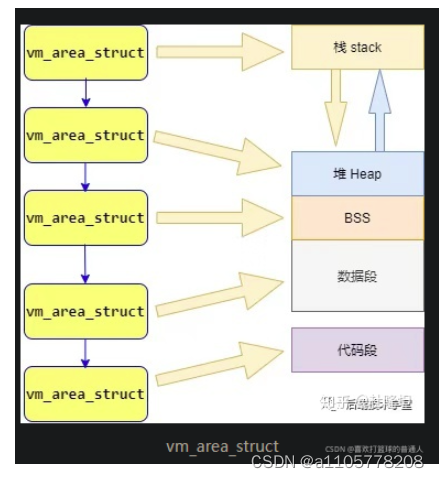
(1)在前面「进程与内存」章节我们提到,Linux进程可以划分为 5 个不同的内存区域,分别是:代码段、数据段、BSS、堆、栈,内核管理这些区域的方式是,将这些内存区域抽象成vm_area_struct的内存管理对象。
(2)vm_area_struct是描述进程地址空间的基本管理单元,一个进程往往需要多个vm_area_struct来描述它的用户空间虚拟地址,需要使用「链表」和「红黑树」来组织各个vm_area_struct。
(3)链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
内核空间动态分配内存数据结构
(1)在内核空间章节我们提到过「动态内存映射区」,该区域由内核函数vmalloc来分配,特点是:线性空间连续,但是对应的物理地址空间不一定连续。vmalloc 分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。
(2)vmalloc 分配的地址则限于vmalloc_start与vmalloc_end之间。每一块vmalloc分配的内核虚拟内存都对应一个vm_struct结构体,不同的内核空间虚拟地址之间有4k大小的防越界空闲区间隔区。
(3)与用户空间的虚拟地址特性一样,这些虚拟地址与物理内存没有简单的映射关系,必须通过内核页表才可转换为物理地址或物理页,它们有可能尚未被映射,当发生缺页时才真正分配物理页面。

8.物理内存管理
在Linux系统中通过分段和分页机制,把物理内存划分 4K 大小的内存页 Page(也称作页框Page Frame),物理内存的分配和回收都是基于内存页进行。
假如系统请求小块内存,可以预先分配一页给它,避免了反复的申请和释放小块内存带来频繁的系统开销。
假如系统需要大块内存,则可以用多页内存拼凑,而不必要求大块连续内存。你看不管内存大小都能收放自如,分页机制多么完美的解决方案!
But,理想很丰满,现实很骨感。如果就直接这样把内存分页使用,不再加额外的管理还是存在一些问题,下面我们来看下,系统在多次分配和释放物理页的时候会遇到哪些问题。
DMA控制器和DMA总线的作用
上述过程中的数据搬移过程就是DMAC控制器做的事情,而DMA总线起到了连接设备、DMA控制器和内存的作用。DMA总线允许设备直接与内存进行通信,而无需CPU的参与。这样可以减轻CPU的负担,提高系统的性能。对于没有DMA总线连接的设备,无法利用DMA映射和DMA控制器进行高效的数据传输。
DMA(Direct Memory Access,直接内存访问)是一种允许某些硬件子系统(如硬盘驱动器,声卡,图形卡等)在不需要CPU的情况下访问系统内存的技术。
在DMA传输过程中,DMA控制器接管了数据传输任务,这就释放了CPU,使其可以执行其他任务。DMA控制器在传输过程中会读取源设备的数据,然后写入目标设备。
在你的描述中,"DMA映射的是内存RAM的物理地址,返回给设备一段地址",这部分描述的是DMA缓冲区的创建。DMA缓冲区是一块物理内存,它被映射到内核空间,用于存储设备数据。
设备(例如,一个ADC转换器)是DMA传输的起点,它将数据发送到DMA控制器。DMA控制器再将这些数据传输到DMA缓冲区,这个缓冲区就是DMA传输的终点。
所以,你的理解是对的。DMA传输过程中,设备是数据的源(起点),DMA映射的缓冲区则是数据的目标(终点)。
关于DMA内存到内存的使用DMA的原因
实际上,在内存到内存的数据传输中,DMA映射并不是必需的。CPU确实可以直接通过MMU机制访问内存中的数据。然而,在某些情况下,使用DMA控制器进行内存到内存的数据传输仍然是有益的,原因如下:
-
减轻CPU负担:CPU只需要配置好DMA的控制过程 设置好目标地址 DMA通道 源地址 传输方向,即可交给DMAC控制器去实现数据的搬运,CPU可以去做其他事情,当完成后DMAC可以通过给CPU发送一个中断来通知CPU 传输的完成。如果在DMA数据传输的过程中CPU需要读取DMA传输过来的地址的话,得保持数据一致性 需要屏蔽cache。
-
提高效率:DMAC通常对数据传输进行优化,可以在高速总线上更有效率的传输数据,并且一般DMAC有多条通道传输数据,这意味着可以同时进行多个内存到内存的数据传输任务,从而提高系统的并行性能。
应用层DMA映射
在 Linux 中,使用 DMA 时,通常需要为 DMA 操作分配一块特殊的内存,这块内存通常被称为 DMA 缓冲区。这个 DMA 缓冲区是在物理内存中的一块区域,它的地址是连续的,并且它不能被操作系统的内存管理子系统(如页替换等)移动或换出。
DMA 缓冲区通常由内核来分配和管理,但用户空间的程序通常无法直接访问这块内存,因为用户空间和内核空间有不同的地址空间。因此,要让用户空间的程序访问 DMA 缓冲区,通常需要进行内存映射。这就是 mmap 系统调用的作用:它会创建一个新的虚拟内存区域,这个区域映射到 DMA 缓冲区的物理地址,这样,用户空间的程序就可以通过这个虚拟内存区域来访问 DMA 缓冲区了。
至于 DMA 操作的细节,通常是这样的:当硬件设备(如 ADC)准备好要发送或接收数据时,它会通过 DMA 控制器(DMAC)向 DMA 缓冲区发送或从 DMA 缓冲区接收数据。这个过程是通过 DMA 总线来完成的,而且这个过程是完全不需要 CPU 参与的。当 DMA 操作完成后,DMA 控制器会产生一个中断,通知 CPU 数据已经准备好,可以进行处理了。
所以总结起来,DMA 是一种让硬件设备直接访问内存的技术,而 mmap 则是一种让用户空间的程序可以访问内核空间(包括 DMA 缓冲区)的内存的技术。通过这两种技术的结合,用户空间的程序就可以高效地处理来自硬件设备的数据了。
DMA映射的作用
内核通常在虚拟地址空间中工作,这意味着当它需要访问物理内存时,必须通过内存管理单元(MMU)将物理地址映射到虚拟地址。
这就是DMA映射的作用。DMA映射是在物理内存和内核虚拟地址空间之间创建一个映射。这使得内核能够访问DMA缓冲区,并且DMA设备也能够直接写入或读取该物理内存区域。
所以,当DMA完成数据传输后,内核可以通过该映射直接访问这些数据。然后,设备驱动程序通常会通过中断通知内核,数据已经被传输到了DMA缓冲区。
要注意的是,用户空间程序无法直接访问物理内存或DMA映射的内存。它们必须通过系统调用,如mmap,让内核将这些内存区域映射到用户空间。然后,用户空间程序才能访问这些内存区域。
DMA函数实现
-
向DMAC 申请一个DMA通道 申请后调用匹配函数 与DMAC中的通道完成匹配 申请完成 chan
-
分配DMA映射一块区域 比如一致性DMA映射 dma_alloc_coherent
-
完成DMA通道的参数设置 通道 目标地址 源地址 传输大小 传输控制标志比如完成后发送一个中断执行回调函数 desc
-
传输完成后回调函数callback实现
-
提交创建的传输描述符desc 即提交传输 但这个时候传输并没有开始 dmaengine_submit(desc);
-
启动通道上chan挂起的传输 dma_async_issue_pending(chan);
#include<linux/init.h>
#include<linux/kernel.h>
#include<linux/module.h>
#include<linux/dmaeengine.h>
#include<linux/dma-mapping.h>
#include<linux/slab.h>
struct dma_chan *chan;//分配一个DMA通道 DMA_channel
//该结构体提供了一种抽象,使得驱动程序和其他内核组件可以在
//不同类型的DMA控制器和硬件平台上使用统一的接口来执行DMA操作。
unsigned int *txbuf;//写通道缓冲区
unsigned int *rxbuf;//接收通道缓冲区
dma_addr_t txaddr;
dma_addr_t rxaddr;
static void dma_callback(void *data)
{
int i;
unsigned int *p=rxbuf;
printk("dma complete\n");
for(i=0;i<PAGE_SIZE/sizeof(unsigned int);i++)
printk("%d",*p++);//打印rxbuf中的数据
printk("\n");
}
static bool filter(struct dma_chan *chan,void *filter_param)//用于过滤的参数,通常是 DMA 通道的名称
{
printk("%s\n",dma_chan_name(chan));
return strcmp(dma_chan_name(chan),filter_param)==0;//对比通道名字 对比是否是所需要的dma通道
}
static int __init memcpy_init(void)
{
int i;
dma_cap_mask_t mask;//位掩码,用于在驱动程序中指定所需的DMA功能,以便在为设备分配DMA通道时进行匹配。
//例如 可以指定从内存到内存 内存到设备 或者设备到内存进行映射。
struct dma_async_tx_descriptot *desc;//用于描述异步DMA事务。这个结构体包含了用于执行
//DMA事务所需的信息,如源地址、目标地址、传输大小等。
char name[]="dma2chan0";//本DMA通道名称 用于与DMAC上的哪一个通道名称匹配
unsigned int *p;
dma_cap_zero(mask);//清空MASK
dam_cap_set(DMA_MEMCOPY,mask);//将mask设置为 内存到内存映射
chan==dma_request_channel(mask,filter,name);//申请内存到内存 匹配函数为filter 名字为name 的DMA通道
if(!chan)
{
printk("dma_request_channer failure\n");
return -ENODEV;
}
txbuf=dma_alloc_coherent(chan->device->dev,PAGE_SIZE,&txaddr,GFP_KERNEL);//一致性DMA映射
//第一个参数DMA设备 第二个缓冲区大小 第三个得到的DMA缓冲区总线地址 第四个内存分配掩码
if(!txbuf)
{
printk("dma_alloc_coherent failure\n");
dma_release_channel(chan);
return -ENOMEM;
}
rxbuf=dma_alloc_coherent(chan->device->dev,PAGE_SIZE,&rxaddr,GFP_KERNEL);
if(!rxbuf)
{
printk("dma_alloc_coherent failure\n");
dma_free_coherent(chan->devicce->dev,PAGE_SIZE,txbuf,txaddr);//将之前映射tx的dma缓冲区取消掉
dma_release_channel(chan);
return -ENOMEM;
}
for(i=0,p=txbuf;i<PAGE_SIZE/sizeof(unsigned int);i++)
*p++=i;//从txbuf的起始位置开始赋值
//先解引用指针 p,将变量 i 的值赋给指针 p 指向的内存位置,然后将指针 p 自增,
//*p++ 操作时,我们实际上在修改 txbuf 所指向的内存区域的内容,而不是改变 txbuf 的地址。
for(i=0,p=txbuf;i<PAGE_SIZE/sizeof(unsigned int);i++)
printk("%d",*p++);
printk("\n");
memset(rxbuf,0,PAGE_SIZE);//读缓冲区清空
for(i=0,p=rxbuf;i<PAGE_SIZE/sizeof(unsigned int);i++)
printk("%d",*p++);
printk("\n");
//初始化desc
//第一个DMA通道 第二个目标接收DMA地址 第三个源发送DMA地址 第四个要传输的数据长度 第五个DMA 控制标志,用于指示 DMA 传输完成时发送一个中断,并且需要进行 ACK 操作。
desc=chan->device->device_prep_dma_memcpy(chan,rxaddr,txaddr,PAGE_SIZE,DMA_cTRL_ACK|DMA_PREP_INTERRUPT);
desc->callback=dma_callback;// DMA 传输完成后的回调函数
desc->callback_param=NULL;//回调函数的参数
dmaengine_submit(desc);//提交刚才出演输得描述符desc
dma_async_issue_pending(chan);//启动在通道上挂起的传输
return 0;
}
module_init(memcpy_init);
module_exit(memcpy_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Kevin Jiang <jiangxg@farsight.com.cn>");
MODULE_DESCRIPTION("simple driver using dmaengine");















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









