







 本文介绍了如何利用Scrapy爬虫框架来抓取LPL春季赛各队伍及其详细信息,包括战队信息、战队详情、队员信息等。作者首先发现网页采用异步加载,通过分析网络请求找到了所需数据的JS文件,并解析JSON格式的数据。接着,通过替换URL中的战队ID和队员ID获取不同页面的信息,最后展示了Scrapy项目创建和爬虫编写的步骤。
本文介绍了如何利用Scrapy爬虫框架来抓取LPL春季赛各队伍及其详细信息,包括战队信息、战队详情、队员信息等。作者首先发现网页采用异步加载,通过分析网络请求找到了所需数据的JS文件,并解析JSON格式的数据。接着,通过替换URL中的战队ID和队员ID获取不同页面的信息,最后展示了Scrapy项目创建和爬虫编写的步骤。
· Python 3.6.3
· Chrome浏览器 版本 64.0.3282.167(正式版本) (64 位)
· PyCharm Community Edition 2017.3.3
· Scrapy 1.4.0
本人平时喜欢玩英雄联盟,喜欢关注英雄联盟赛事。现在学了点爬虫的知识,就想尝试着把2018年Lpl春季赛各个战队的信息抓取下来保存。于是登录了官网('http://lpl.qq.com/'),进入战队页,用requests和BeautifulSoup写爬虫脚本,结果返回的是空的信息。
2018年lpl春季赛各大战队

右键查看网页源代码信息,发现源代码中没有任何关于战队的信息,只有跳转链接信息。

说明这个网页不是静态的网页,不能简单地通过结构网页获取信息。
右键'检查',点击'Network',点击'XHR',按F5刷新后,发现并没有任何我们想要的战队信息。
点击'JS'选项,发现其中一个文件叫'clublist.js',里面包含了各大战队的信息。
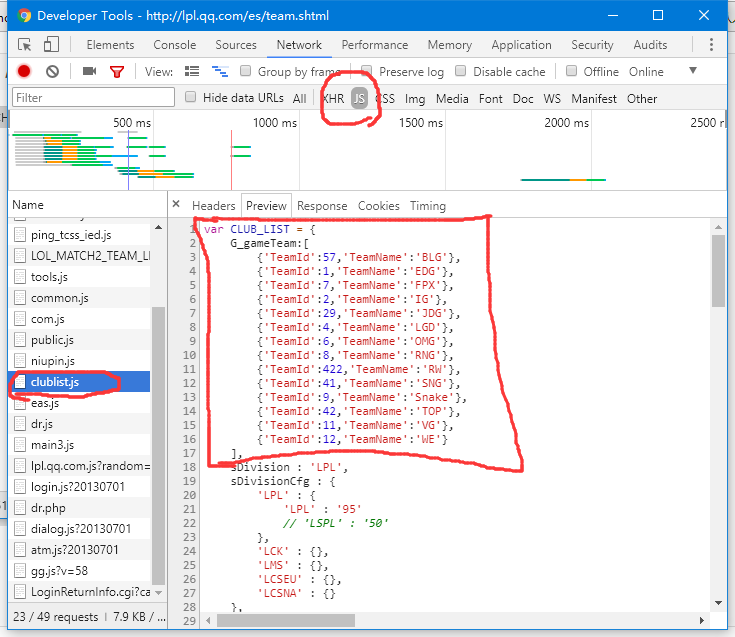
因为战队数目有限,就不用写代码抓取了,直接复制下来改写成字典信息。
TeamIDs = {
'BLG': 57, 'EDG': 1, 'FPX': 7,
'IG': 2, 'JDG': 29, 'LGD': 4,
'OMG': 6, 'RNG': 8, 'RW': 422,
'SNG': 41, 'Snake': 9, 'TOP': 42,
'VG': 11, 'WE': 12
}
获取到战队信息,接下来就获取战队详细信息。随便进入一个战队的详情页面,比如进入'BLG'战队。


该页面的链接形式是这样的:'http://lpl.qq.com/es/team_detail.shtml?tid=57',我发现'tid=57',正好是刚刚抓取到的战队信息里对应的'BLG'战队ID,我们可以通过改变数值就能访问各个战队的详情页面。
为了获取到详细信息,同样的,右键'检查',点击'Network',点击'XHR',F5刷新,发现第一个文件就是我们想要的文件。
其链接是这样的形式:'http://lpl.qq.com/web201612/data/LOL_MATCH2_TEAM_TEAM57_INFO.js',其中也有'57',说明通过改写战队ID也能访问其他战队的详情信息。
在'Preview'选项中,找到了战队介绍与战队队员的详细信息,以json格式储存。
其中有个'MemberID'的参数很重要,它是构成队员详情页URL的重要参数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









