






神经网络非线性激励函数
1.sigmoid函数
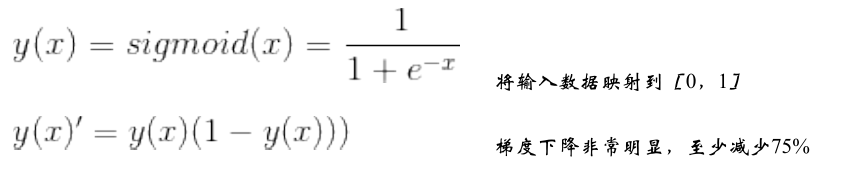
这应该是神经网络中使用最频繁的激励函数了,它把一个实数压缩至0到1之间,当输入的数字非常大的时候,结果会接近1,当输入非常大的负数时,则会得到接近0的结果。在早期的神经网络中使用得非常多,因为它很好地解释了神经元受到刺激后是否被激活和向后传递的场景(0:几乎没有被激活,1:完全被激活),不过近几年在深度学习的应用中比较少见到它的身影,因为使用sigmoid函数容易出现梯度弥散或者梯度饱和。当神经网络的层数很多时,如果每一层的激励函数都采用sigmoid函数的话,就会产生梯度弥散的问题,因为利用反向传播更新参数时,会乘以它的导数,所以会一直减小。如果输入的是比较大或者比较小的数(例如输入100,经Sigmoid函数后结果接近于1,梯度接近于0),会产生饱和效应,导致神经元类似于死亡状态。
2.tanh 函数

tanh函数及其导数的几何图像如下图:

tanh读作Hyperbolic Tangent,它解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
3.ReLU函数


ReLU函数并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
1. 解决了gradient vanishing(梯度消失)问题 (在正区间)
2.计算速度非常快,只需要判断输入是否大于0
3.收敛速度远快于sigmoid和tanh
为什么引入Relu呢?
1.采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
2.对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
3.Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
ReLU也有几个需要特别注意的问题:
1.ReLU的输出不是zero-centered(零均值化 / 中心化)
2.Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
尽管存在这两个问题,ReLU目前仍是最常用的激活函数,在搭建人工神经网络的时候推荐优先尝试!
4.Leaky ReLU 函数

Leaky Relu函数及其导数的图像如下图所示:
(注意左半边直线斜率非常接近0,所以看起来像是平的。α=0.01看起来就是这样的。)

人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为αx而非0,通常α=0.01。另外一种直观的想法是基于参数的方法,即ParametricReLU:f(x)=max(αx,x),其中α可由反向传播算法算出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
5.softmax函数
在机器学习尤其是深度学习中,softmax是个非常常用而且比较重要的函数,尤其在多分类的场景中使用广泛。他把一些输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。
首先我们简单来看看softmax是什么意思。顾名思义,softmax由两个单词组成,其中一个是max。对于max我们都很熟悉,比如有两个变量a,b。如果a>b,则max为a,反之为b。用伪码简单描述一下就是 if a > b return a; else b。
另外一个单词为soft。max存在的一个问题是什么呢?如果将max看成一个分类问题,就是非黑即白,最后的输出是一个确定的变量。更多的时候,我们希望输出的是取到某个分类的概率,或者说,我们希望分值大的那一项被经常取到,而分值较小的那一项也有一定的概率偶尔被取到,所以我们就应用到了soft的概念,即最后的输出是每个分类被取到的概率。
首先给一个图,这个图比较清晰地告诉大家softmax是怎么计算的。

下面为大家解释一下为什么softmax是这种形式。
首先,我们知道概率有两个性质:
1.预测的概率为非负数;
2.各种预测结果概率之和等于1。
softmax就是将在负无穷到正无穷上的预测结果按照这两步转换为概率的。
(1)将预测结果转化为非负数
下图为y=exp(x)的图像,我们可以知道指数函数的值域取值范围是零到正无穷。softmax第一步就是将模型的预测结果转化到指数函数上,这样保证了概率的非负性。

(2)各种预测结果概率之和等于1
为了确保各个预测结果的概率之和等于1。我们只需要将转换后的结果进行归一化处理。方法就是将转化后的结果除以所有转化后结果之和,可以理解为转化后结果占总数的百分比。这样就得到近似的概率。
总结一下softmax如何将多分类输出转换为概率,可以分为两步:
1.分子:通过指数函数,将实数输出映射到零到正无穷。
2.分母:将所有结果相加,进行归一化。
下图为斯坦福大学CS224n课程中最softmax的解释:















 1904
1904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









