







 本文记录使用Spark3.1.3进行本地模式下的词频统计,包括Scala2.12.15的安装、HDFS与Spark集群的启动、在HDFS上准备数据,以及Spark项目创建、配置、运行和结果查看的过程。
本文记录使用Spark3.1.3进行本地模式下的词频统计,包括Scala2.12.15的安装、HDFS与Spark集群的启动、在HDFS上准备数据,以及Spark项目创建、配置、运行和结果查看的过程。
一、词频统计准备工作
- 单词计数是学习分布式计算的入门程序,有很多种实现方式,例如MapReduce;使用Spark提供的RDD算子可以更加轻松地实现单词计数。
- 在IntelliJ IDEA中新建Maven管理的Spark项目,在该项目中使用Scala语言编写Spark的WordCount程序,可以本地运行Spark项目查看结果,也可以将项目打包提交到Spark集群(Standalone模式)中运行。
(一)版本选择问题
-
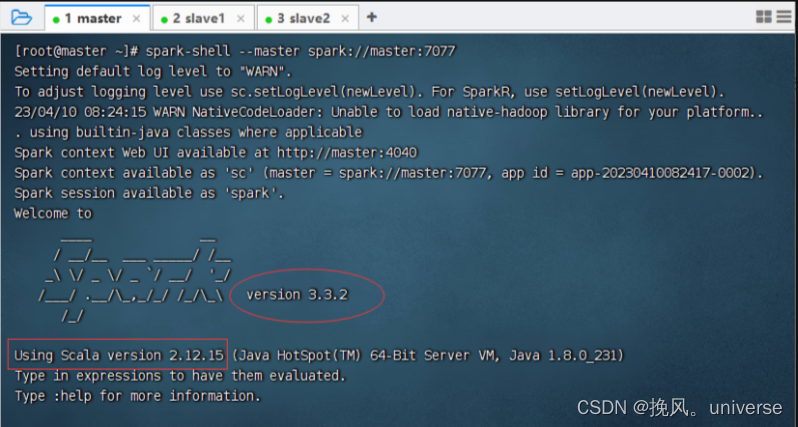
前面创建了Spark集群(Standalone模式),采用的是Spark3.3.2版本

- Spark3.3.2用的Scala库是2.13,但是Spark-Shell里使用的Scala版本是2.12.15
-
为了Spark项目打成jar包能够提交到这个Spark集群运行,本地就要安装Scala2.12.15
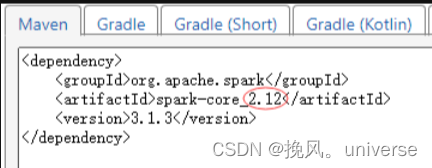
- 由于Spark项目要求Spark内核版本与Scala库版本(主版本.次版本)要保持一致,否则本地都无法运行项目。Spark3.2.0开始,要求Scala库版本就更新到了2.13,只有Spark3.1.3使用Scala库版本依然是2.12,因此Spark项目选择使用Spark3.1.3。
- Spark项目如果基于JDK11,本地运行没有问题,但是打成Jar包提交到集群运行会报错

- 卸载之前在Windows上安装的Scala2.13.10

(二)安装Scala2.12.15
- 从Scala官网下载Scala2.12.15 - Scala 2.12.15 | The Scala Programming Language
下载到本地
安装在默认位置
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









