







- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:API Server详解(一)
- Kubernetes控制平面组件:API Server详解(二)
- Kubernetes控制平面组件:调度器Scheduler(一)
- Kubernetes控制平面组件:调度器Scheduler(二)
- Kubernetes控制平面组件:Controller Manager详解
- Kubernetes控制平面组件:Controller Manager 之 内置Controller详解
- Kubernetes控制平面组件:Controller Manager 之 NamespaceController 全方位讲解
本文是kubernetes的控制面组件ControllerManager系列文章,本篇详细讲解了kubernetes 内置常用的Controller,包括:Job、HPA、ReplicaSet、StatefulSet、Namespace、NodeIpam/NodeLifecycle Controller、DaemonSet、Endpoint、EndpointSlice、Garbege Controller、CronJob、ControllerRevision、Lease
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.Job
1.1.Job 基本功能
- Kubernetes Job 是专为一次性任务和批处理作业设计的控制器,其核心功能是确保指定数量的 Pod 成功完成任务后终止。
- 核心功能
- 任务完成保障
- 创建并跟踪 Pod 执行状态,直到所有 Pod 成功退出(退出码为 0)。
- 支持设置 completions 指定任务需完成的 Pod 总数(默认 1)。
- 并行处理能力
- 通过 parallelism 控制同时运行的 Pod 数量,加速批处理任务执行。
- 支持两种模式:
- Non-parallel Job:单 Pod 运行直至成功。
- Parallel Job:多 Pod 并行运行,适用于大规模批处理。
- 失败重试机制
- 配置 backoffLimit 定义失败重试次数(默认 6 次)。
- 若 Pod 因非零退出码失败,Job 自动重启或新建 Pod 重试任务。
- 生命周期管理
- 自动清理:通过 ttlSecondsAfterFinished 设置任务完成后自动删除 Job 和 Pod 的延迟时间。
- 超时终止:activeDeadlineSeconds 强制终止运行超时的任务。
- 任务完成保障
- 注意事项
- 并行控制: 避免
parallelism设置过高导致资源争抢。 - 资源限制: 应为Job Pod配置合理的CPU/内存限制。
- 历史记录: 成功完成的Job默认不会自动删除,需手动清理或设置
.spec.ttlSecondsAfterFinished。不过虽然pod依旧存在,但实际上容器已经停止了,没有进程在跑,也没有资源开销了
- 并行控制: 避免
1.2.Job 使用示例
- 任务:计算pi的2000位
apiVersion: batch/v1 kind: Job metadata: name: pi spec: parallelism: 2 completions: 5 template: spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: OnFailure ```
1.3.Job Spec 核心字段
| 字段名称 | 类型/格式 | 默认值 | 描述 |
|---|---|---|---|
| parallelism | int32 | 1 | 允许同时运行的 Pod 最大数量(实际运行数可能小于该值,取决于剩余任务数) |
| completions | int32 | 1 | 任务需成功完成的 Pod 总数(不设置时,任何 Pod 成功即视为整体成功) |
| backoffLimit | int32 | 6 | 失败重试次数,超过后 Job 标记为 Failed |
| activeDeadlineSeconds | int64 | 无 | Job 最大运行时间(秒),超时强制终止任务 |
| ttlSecondsAfterFinished | int32 | 无 | Job 完成后自动删除的延迟时间(秒),0 表示立即删除 |
| template | PodTemplate | 必填 | 定义任务 Pod 的模板(包含容器、卷、重启策略等配置) |
| completionMode | string | NonIndexed | 任务完成模式:NonIndexed(默认,任意成功 Pod 累计)或 Indexed(需每个索引位成功) |
| suspend | bool | false | 是否暂停 Job(设为 true 后停止创建新 Pod,已运行 Pod 不受影响) |
| manualSelector | bool | false | 是否手动指定 Pod 选择器(需与 selector 字段配合使用,通常不建议开启) |
| selector | LabelSelector | 无 | 指定 Pod 标签选择器(需与 manualSelector: true 配合使用) |
| podFailurePolicy | Object | 无 | 定义 Pod 失败处理策略(如忽略特定错误码),需 Kubernetes 1.25+ |
1.4.字段使用注意事项
-
字段使用限制
- Job podTemplate 的 restartPolicy 不可设置为 Always,因为任务预期是执行完成一次后就结束,Always会使pod退出后重启启动。
- restartPolicy允许两个取值:OnFailure、Never。推荐使用OnFailure,配合backoffLimit,在pod失败时重启指定次数,达到次数会被置为Failed
- 如果restartPolicy==Never,那么backoffLimit其实就不生效的
-
版本兼容性
completionMode: Indexed需要 Kubernetes 1.21+podFailurePolicy需要 Kubernetes 1.25+
-
互斥关系
- 若设置
manualSelector: true,必须同时定义selector字段 completions与parallelism组合决定任务类型(详见下方场景)
- 若设置
-
典型场景配置
场景 配置示例 说明 单次任务 completions:1, parallelism:1单个 Pod 运行一次即完成 批量串行任务 completions:5, parallelism:1逐个运行 Pod,累计 5 次成功即完成 批量并行任务 completions:10, parallelism:3同时运行最多 3 个 Pod,累计 10 次成功即完成 工作队列任务 parallelism:3(不设 completions)并行运行 3 个 Pod,任意一个成功即完成(常用于消费队列场景) -
pod执行完成的终态位 Completed
2.Horizontal Pod Autoscaler (HPA)
2.1.HPA 基本功能
- HPA(水平 Pod 自动扩缩器)是 Kubernetes 的核心组件之一,用于根据实时负载动态调整 Pod 副本数量,以实现资源优化和高可用性。
- HPA 的核心功能是根据预定义指标自动调整 Pod 副本数量:
- 扩容:当指标(如 CPU 使用率、内存或自定义指标)超过目标阈值时,HPA 增加 Pod 副本以应对高负载。
- 缩容:当指标低于目标阈值时,HPA 减少 Pod 副本以节省资源。
- 示例场景:
- 若目标 CPU 利用率设置为 70%,当实际利用率达到 80%,HPA 将计算需要的副本数并扩容;若利用率降至 50%,则触发缩容。
- 实现原理
- 指标采集: 通过Metrics Server或Prometheus Adapter获取Pod指标。
- 算法计算: 使用公式:
期望副本数 = ceil(当前指标值 / 目标指标值)。 - 执行扩缩: 修改Deployment/ReplicaSet的
.spec.replicas值,触发副本数调整。
2.2.HPA 使用示例
2.2.1.示例 1:基于 CPU 指标的弹性伸缩
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: cpu-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-server
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
- 场景说明:当
web-server的 CPU 平均利用率超过 60% 时,HPA 将自动扩容 Pod,最多扩至 10 个副本;低于 60% 时缩至 2 个副本。
2.2.2.示例 2:多指标弹性伸缩(CPU + 自定义 QPS)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: multi-metric-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-gateway
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: requests-per-second
target:
type: AverageValue
averageValue: 1000
- 场景说明:同时监控 CPU 利用率和每秒请求数(QPS)。若 CPU >50% 或 QPS >1000,HPA 选择计算结果中较大的副本数进行扩容。
2.3.HPA Spec核心字段
| 字段名称 | 类型/格式 | 必填 | 描述 | 版本兼容性 |
|---|---|---|---|---|
scaleTargetRef | Object | 是 | 指定目标工作负载(如 Deployment、StatefulSet)的 API 版本、类型和名称 | v1+ |
minReplicas | int32 | 否 | 最小 Pod 副本数(默认 1) | v1+ |
maxReplicas | int32 | 是 | 最大 Pod 副本数(必须 ≥1) | v1+ |
metrics | []MetricSpec | 是 | 监控指标数组(支持 CPU、内存、自定义指标等) | v2beta2+ |
behavior | HorizontalPodAutoscalerBehavior | 否 | 控制扩缩容速率和冷却时间(如快速扩容/缓慢缩容) | v2beta2+ |
metrics 字段的子类型:
| 类型 | 适用场景 | 示例配置片段 |
|---|---|---|
| Resource | CPU/内存利用率 | type: Resource + resource.name: cpu + target.averageUtilization: 50 |
| Pods | Pod 自定义指标(如 QPS) | type: Pods + pods.metric.name: requests-per-second + target.value: 1k |
| Object | Kubernetes 对象指标(如 Ingress) | type: Object + object.metric.name: requests-per-second |
| External | 外部服务指标(如消息队列) | type: External + external.metric.name: queue_messages_ready |
2.4.使用注意事项
- Resource计算必需参数
- Pod 必须配置了
resources.requests,否则 HPA 无法获取 CPU/内存使用率。
- Pod 必须配置了
- 冷启动与预热机制
- 使用
initialDelaySeconds延迟首次指标采集(避免启动阶段误判)。 - 配置
startupProbe确保应用就绪后再接收流量。
- 使用
- 扩缩速度控制
- 通过
behavior字段限制步长(如每分钟最多扩容 2 个 Pod):behavior: scaleUp: policies: - type: Pods value: 2 periodSeconds: 60 - 在controller-manager参数中,通过
--horizontal-pod-autoscaler-downscale-stabilization设置缩容冷却时间,默认5分钟,避免抖动
- 通过
- 多指标优先级
- HPA 按所有指标计算结果的最大副本数扩容
- 版本兼容性
autoscaling/v1仅支持 CPU 指标autoscaling/v2支持自定义指标和扩缩行为控制
- 缩容禁用策略
- 场景:关键业务禁止自动缩容,需手动或外部系统触发。
behavior: scaleDown: selectPolicy: Disabled
2.5.外部服务指标 集成示例
- 自定义指标(Prometheus 集成)
metrics: - type: External external: metric: name: http_requests_total selector: matchLabels: service: api-gateway target: type: AverageValue averageValue: 500- 说明:通过 Prometheus Adapter 提供业务自定义指标(如 HTTP 请求总数)。
2.6.验证与监控
- 查看 HPA 状态
kubectl get hpa <NAME> -w - 输出示例:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS cpu-hpa Deployment/web 45%/60% 2 10 5
3.ReplicaSet
3.1.ReplicaSet 基本功能
- ReplicaSet(RS)是 Kubernetes 中用于维护无状态应用 Pod 副本数量的基础控制器,通过标签选择器管理 Pod 生命周期,确保副本数始终符合用户定义的期望值。其核心能力包括:
- 副本维持:自动创建/删除 Pod 以匹配
replicas定义的副本数。 - 自愈能力:替换故障或被删除的 Pod。
- 标签驱动:通过
selector精准匹配 Pod。
- 副本维持:自动创建/删除 Pod 以匹配
- ReplicaSet以前叫:ReplicationController(RC),因为它只是一个资源对象,名字叫xxxController有歧义,所以后来改名叫ReplicaSet了,但ReplicationController已经产生一些用户了,所以没法下掉,就这样了
3.2.ReplicaSet 使用示例
3.2.1.示例 1:基础 ReplicaSet 定义
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: web-rs
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:1.18.0
ports:
- containerPort: 80
- 场景说明:
- 创建 3 个运行
nginx:1.18.0的 Pod,标签为app: web。 - 若 Pod 被删除或故障,RS 会自动重建新 Pod。
- 创建 3 个运行
3.2.2.示例 2:动态扩缩容
# 手动扩缩容
kubectl edit rs/web-rs # 修改 `spec.replicas` 值
kubectl scale rs/web-rs --replicas=5 # 命令直接扩容
- 场景说明:
- 副本数从 3 扩容至 5 时,RS 自动创建 2 个新 Pod。
- 缩容时,RS 按策略(如随机选择)删除多余 Pod。
3.3.ReplicaSet Spec 字段完整解析表
| 字段名称 | 类型/格式 | 必填 | 默认值 | 描述 | 版本兼容性 |
|---|---|---|---|---|---|
replicas | int32 | 否 | 1 | 期望的 Pod 副本数 | v1+ |
selector | LabelSelector | 是 | - | 标签选择器,匹配目标 Pod(必须与 template.metadata.labels 一致) | v1+ |
template | PodTemplateSpec | 是 | - | Pod 创建模板(定义容器、卷、探针等) | v1+ |
minReadySeconds | int32 | 否 | 0 | Pod 就绪后等待时间(秒),用于避免瞬时故障误判 | v1+ |
关键字段说明:
selector.matchLabels:需与template.metadata.labels严格匹配,否则 RS 创建失败。template.spec:定义 Pod 规格,支持完整 Pod 配置(如容器、资源限制、探针)。
3.4.使用注意事项
- 避免直接管理
- 推荐使用 Deployment 间接管理 RS,实现滚动更新和版本回滚。
- 直接操作 RS 时,镜像更新需手动删除旧 Pod(RS 仅替换副本,不触发滚动更新)。
- 标签选择器一致性
- 修改
selector或 Pod 标签可能导致 RS 失去对现有 Pod 的控制,需谨慎操作。
- 修改
- 资源清理
- 删除 RS 时默认级联删除 Pod(
kubectl delete rs <name> --cascade=orphan可保留 Pod)。
- 删除 RS 时默认级联删除 Pod(
- 版本兼容性
apps/v1是稳定版本,旧版本(如extensions/v1beta1)已废弃。
4.StatefulSet
4.1.StatefulSet 基本功能
-
StatefulSet 是 Kubernetes 中管理有状态应用的核心控制器
-
具备以下核心功能:
功能 描述 支持版本 唯一的pod名称 每个 Pod 的名称是按照序号编排的, s t s . N a m e − {sts.Name}- sts.Name−{序号},如 web-0、web-1… 稳定网络标识 每个 Pod 具有唯一且固定的 DNS 名称(如 web-0.nginx.default.svc.cluster.local)Kubernetes v1+ 持久化存储 通过 volumeClaimTemplates为每个 Pod 动态创建独立的 PVC/PV,数据与 Pod 生命周期解耦Kubernetes v1+ 有序部署与扩缩容 Pod 按顺序启动(0→N-1)、终止(N-1→0),适用于主从架构或依赖启动顺序的应用 Kubernetes v1+ 滚动更新策略 支持 RollingUpdate(顺序更新)、OnDelete(手动触发更新)和Partition(分区更新)Kubernetes v1.7+ -
StatefulSet名称的变化:
- StatefulSet 最初叫 PetSet(宠物集),比如一个鱼缸里有3条金鱼颜色分为红绿蓝,红的死掉就换一条红色,蓝的死掉就换一个蓝的,3条金鱼各不相同,需要独立处理,像照顾宠物一样照顾他们,代表有状态的集合
- 后来社区有人提了个issue,认为叫PetSet太残忍,有状态的是宠物一样照顾,那无状态的ReplicaSet 建出来的pod岂不都是 cattle(牲畜),可以任意丢弃…经过大量讨论后,最终决定还是把名字改了,改成 StatefulSet
4.2.StatefulSet 使用示例
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-ss
spec:
serviceName: nginx-ss
replicas: 1
selector:
matchLabels:
app: nginx-ss
template:
metadata:
labels:
app: nginx-ss
spec:
containers:
- name: nginx-ss
image: nginx
---
apiVersion: v1
kind: Service
metadata:
name: nginx-ss
labels:
app: nginx-ss
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx-ss
4.3.StatefulSet 核心字段
| 字段名称 | 类型/格式 | 必填 | 默认值 | 描述 | 版本兼容性 |
|---|---|---|---|---|---|
replicas | int32 | 否 | 1 | Pod 副本数量,定义 StatefulSet 需要维持的 Pod 实例数。 | v1+ |
selector | LabelSelector | 是 | - | 标签选择器,用于匹配 Pod。必须与 template.metadata.labels 完全一致,否则无法关联 Pod。 | v1+ |
template | PodTemplateSpec | 是 | - | Pod 模板定义,包括容器、资源限制、探针、存储挂载等配置。 | v1+ |
serviceName | string | 是 | - | 关联的 Headless Service 名称,用于为 Pod 提供稳定的 DNS 标识(如 web-0.serviceName)。 | v1+ |
volumeClaimTemplates | []PersistentVolumeClaim | 否 | - | 存储卷声明模板,动态创建 PVC,每个 Pod 独立绑定持久化存储卷。 | v1+ |
updateStrategy | UpdateStrategy | 否 | RollingUpdate | 更新策略: - RollingUpdate:按顺序逐个更新 Pod。- OnDelete:需手动删除 Pod 触发更新。- partition:分区更新(如仅更新序号≥N 的 Pod)。 | v1.7+ |
podManagementPolicy | string | 否 | OrderedReady | Pod 管理策略: - OrderedReady:按顺序创建/删除 Pod(0→N-1)。- Parallel:允许并行启动或删除 Pod。 | v1.7+ |
minReadySeconds | int32 | 否 | 0 | Pod 就绪后等待时间(秒),用于避免瞬时故障误判(如短暂 Ready 后立即 Crash)。 | v1+ |
revisionHistoryLimit | int32 | 否 | 10 | 保留的历史版本数量,用于回滚操作。 | v1+ |
persistentVolumeClaimRetentionPolicy | Object | 否 | Retain | 控制 PVC 的保留策略: - WhenDeleted:删除 StatefulSet 时保留 PVC。- WhenScaled:缩容时保留被删除 Pod 的 PVC。 | v1.23+ |
-
关键字段补充说明
-
volumeClaimTemplates- 动态生成 PVC,名称格式为
<模板名称>-<Pod名称>(如data-web-0)。 - 需预先配置
StorageClass,否则需手动创建 PV。
- 动态生成 PVC,名称格式为
-
updateStrategypartition字段(仅限RollingUpdate策略):指定从哪个序号开始更新。例如partition: 2表示仅更新序号≥2 的 Pod。
-
podManagementPolicyOrderedReady适用于主从架构(如 MySQL 主从同步需按顺序启动)。Parallel适用于无启动依赖的分布式系统(如 Cassandra 集群)。
-
serviceName- 必须指向一个已存在的 Headless Service(
clusterIP: None),否则 DNS 解析失效。
- 必须指向一个已存在的 Headless Service(
-
-
使用注意事项
- 删除 StatefulSet 不会自动删除 PVC:需手动清理或配置
persistentVolumeClaimRetentionPolicy。 - 缩容顺序:默认从高序号 Pod 开始删除,需确保数据同步(如数据库主节点优先保留)。
- 标签一致性:修改
selector或 Pod 标签会导致 StatefulSet 失去对 Pod 的控制。 - 冷启动问题:首次部署时,需等待前一个 Pod 完全就绪后再启动下一个。
- 删除 StatefulSet 不会自动删除 PVC:需手动清理或配置
-
版本兼容性参考
podManagementPolicy和updateStrategy需 Kubernetes v1.7+persistentVolumeClaimRetentionPolicy需 v1.23+
4.4.StatefulSet 服务发现
# sts yaml
spec:
# 一般为headless service名称
serviceName: nginx-headless-svc
# pod yaml
spec:
# 不指定时,默认为pod的名称:${sts.name}-${序号}
hostname: nginx-ss-0
# 默认是 sts.serviceName 名称
subdomain: nginx-headless-svc
- 为了给sts的pod 提供稳定的网络标识和精确的 Pod 发现机制,sts中提供了serviceName字段,用于关联一个headless svc,另外配合 pod 的 hostname 和 subdomain 就可以得到一个唯一的dns域名:
- 域名可以有两种表示方法,两种等同:
${pod-name}.${headless-service-name}.${namespace}.svc.${cluster-domain}${hostname}.${subdomain}.${namespace}.svc.${cluster-domain}- 其中
${cluster-domain}默认为 cluster.local,可以在 kubelet 配置文件中自定义
cat /var/lib/kubelet/config.yaml # 示例配置片段 clusterDNS: - 10.96.0.10 clusterDomain: cluster.local # 集群域名在此处定义 - 域名如何生效?
- coreDns 会将该域名的解析,指向该pod的ip。如:
nginx-ss-0.nginx-headless-svc.default.svc.cluster.local 192.168.0.10 - 即使pod ip发生变化,域名也不会变,所有集群内其他应用都可以使用这个域名对该pod进行访问了
- coreDns 会将该域名的解析,指向该pod的ip。如:
- StatefulSet 服务发现 如何解决有状态应用的关键需求
- 唯一网络标识:为每个 Pod 生成固定 DNS 名称,即使 Pod 重启或迁移,其网络标识不变。
- 直接 Pod 通信:无头服务不分配 ClusterIP,DNS 查询直接返回 Pod IP 列表,支持有状态应用(如 MySQL 集群)通过固定域名直接通信。
- 拓扑状态保障:StatefulSet 要求 Pod 按顺序启动且名称固定,Headless Service 通过 DNS 记录绑定 Pod 名称与 IP,确保集群内通信的稳定性。
4.5.StatefulSet PVCTemplate
- StatefulSet 的
volumeClaimTemplates是 Kubernetes 为有状态应用设计的核心功能之一,用于动态管理持久化存储资源。
4.5.1.核心作用与设计原理
- 自动化 PVC 创建
volumeClaimTemplates为每个 StatefulSet Pod 动态生成唯一的 PersistentVolumeClaim(PVC),名称格式为<模板名>-<StatefulSet名>-<序号>。例如,模板名为data,StatefulSet 名为web,则生成的 PVC 为data-web-0、data-web-1等。- 设计意义:避免手动创建多个 PVC,简化运维流程。
- 数据持久化保障
- 每个 Pod 的 PVC 与 PersistentVolume(PV)绑定,即使 Pod 被删除重建,Kubernetes 会通过 PVC 名称匹配到原有 PV,确保数据持久性。
- 应用场景:数据库主从节点、分布式存储系统(如 Elasticsearch)等需独立存储的场景。
- 拓扑稳定性
- 结合 StatefulSet 的 Pod 命名规则(如
web-0、web-1),PVC 名称与 Pod 名称严格对应,维护存储与网络拓扑的一致性。
- 结合 StatefulSet 的 Pod 命名规则(如
4.5.2.配置方法与示例
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx-service"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
storageClassName: standard-sc
- 关键字段解析:
metadata.name:PVC 模板名称,影响生成的 PVC 名称前缀。spec.accessModes:存储访问模式(如ReadWriteOnce、ReadWriteMany),需与存储后端兼容。storageClassName:指定动态存储类(StorageClass),由集群管理员预先配置。
4.5.3.实际应用与注意事项
- 动态存储分配
- 当 StatefulSet 扩容时(如从 3 副本扩至 5),Kubernetes 自动按模板创建新 PVC 并绑定 PV。
- 验证命令:
kubectl get pvc # 查看生成的 PVC kubectl describe pod web-0 # 检查挂载状态
- 存储策略管理
- 回收策略:通过 PV 的
persistentVolumeReclaimPolicy控制数据保留(如Retain或Delete)。 - 自动扩容:结合支持动态扩容的 StorageClass,可配置 PVC 自动调整存储大小。
- 回收策略:通过 PV 的
- 多模板支持
- 一个 StatefulSet 可定义多个
volumeClaimTemplates,例如为日志和数据库分别挂载不同存储卷。
- 一个 StatefulSet 可定义多个
4.5.4.对比普通 Deployment 的 PVC 使用
| 特性 | StatefulSet + volumeClaimTemplates | Deployment + PVC |
|---|---|---|
| PVC 生成方式 | 自动按模板创建,名称唯一且有序 | 需手动定义每个 PVC |
| 数据与 Pod 绑定 | 强绑定,Pod 重建后自动关联原存储 | 需手动管理 PVC 与 Pod 的挂载关系 |
| 适用场景 | 有状态应用(如 MySQL、Kafka) | 无状态应用(如 Web 服务) |
5.Namespace
5.1.Namespace 基本功能
- namespace就相当于一个目录,可以将不同应用进行隔离
- NamespaceController核心逻辑:删除ns时,Namespace Controller 需要 把ns下所有数据先删除,才能删除ns
5.2.Namespace 核心字段
- namespace.spec中,只有一个字段:
Finalizers []FinalizerName,早期时用于拦截ns的删除 - 后面 finalizer 放在了 metadata 中,ns的spec下就没有什么了
namespace.status.phase:只有两个枚举值:Active、Terminating
5.3.Namespace Controller源码分析:如何编写一个controller
- 详见:Kubernetes控制平面组件:Controller Manager 之 NamespaceController 全方位讲解
- 本文以Namespace Controller 为例,详细讲述了kubernetes内置Controller的编写过程,包含kubernetes 内置controller struct 声明,Informer机制原理及代码分析、client-go Clientset 整合资源client的原理、kube-controller-manager如何启动内置controller等。另外对Namespace Controller 代码进行完整分析
6.NodeIpam/NodeLifecycle Controller
6.1.Node 基本功能
- Node 是 Kubernetes 集群的工作节点,负责运行容器化应用并管理其生命周期。核心功能如下:
- 容器运行环境
- 提供容器运行时(如 Docker、containerd)及 Kubernetes 组件(kubelet、kube-proxy)。
- 支持 Pod 生命周期管理(创建、销毁、重启)。
- 资源提供与管理
- 分配 CPU、内存、存储等资源给 Pod。
- 通过 kubelet 上报资源状态至控制平面。
- 调度与负载均衡
- 配合调度器(Scheduler)将 Pod 分配到最佳节点。
- 通过 kube-proxy 实现 Service 的负载均衡和网络规则。
- 健康监控与自愈
- 定期检查节点健康状态(如 Ready/NotReady)。
- 故障节点上的 Pod 自动驱逐并重新调度。
- k8s v1.16版本中 NodeController 被分为了 NodeIpamController 与 NodeLifecycleController
6.2.Node 使用示例
apiVersion: v1
kind: Node
spec:
providerID: "aws://us-east-1a/i-0abcdef1234567890"
podCIDR: "10.234.58.0/24"
podCIDRs:
- "10.234.58.0/24"
- "2001:db8::/64"
taints:
- key: "node-type"
value: "production"
effect: "NoSchedule"
unschedulable: false
6.3.Node Spec核心字段
| 字段名称 | 类型 | 功能说明 | 注意事项 |
|---|---|---|---|
| configSource | Object | 指定节点的动态配置来源(如 ConfigMap),用于 Kubelet 配置。 | - 已弃用(v1.22+),DynamicKubeletConfig 功能已移除 |
| externalID | string | 节点的外部标识符(如云平台实例 ID)。 | - 已弃用(v1.13+),推荐使用 providerID 替代 |
| podCIDR | string | 分配给节点的 Pod IP 范围(单网段),用于该节点上 Pod 的 IP 分配。 | - 由 NodeIpamController 自动分配 - 旧版本仅支持单网段 |
| podCIDRs | []string | 分配给节点的 Pod IP 范围(多网段),支持 IPv4/IPv6 双栈。 | - 第 0 项必须与 podCIDR 一致- 每个协议栈最多 1 个 CIDR |
| providerID | string | 云平台分配的节点唯一标识符,格式为 <ProviderName>://<ProviderSpecificNodeID>。 | - 用于云平台集成(如 AWS EC2 ID) - 手动设置需符合格式要求 |
| taints | []Object(污点列表) | 定义节点污点,控制 Pod 调度行为(如 NoSchedule、NoExecute)。 | - 需配合 Pod 的 tolerations 使用- 默认 Master 节点自带污点 |
| unschedulable | boolean | 标记节点是否可调度新 Pod(true 表示不可调度,类似 kubectl cordon 命令效果)。 | - 不影响已运行 Pod,需 kubectl drain 驱逐- 默认 false |
扩展说明与注意事项
-
弃用字段处理
- configSource:在 v1.22+ 集群中无效,需通过其他方式管理 Kubelet 配置(如静态配置文件)。
- externalID:云环境节点优先使用
providerID,非云环境可忽略。
-
Pod CIDR 管理
- 自动分配:由
NodeIpamController分配,需在kube-controller-manager中配置--cluster-cidr和--node-cidr-mask-size。 - 双栈支持:
podCIDRs允许同时定义 IPv4 和 IPv6 CIDR(如["10.234.58.0/24", "2001:db8::/64"])。
- 自动分配:由
-
污点(Taints)
NoSchedule:阻止新 Pod 调度(已有 Pod 不受影响)。NoExecute:驱逐不容忍的已有 Pod(需设置tolerationSeconds延迟驱逐)。内置污点:如node.kubernetes.io/not-ready(节点不健康时自动添加)。
# master默认具有这个污点 taints: - effect: NoSchedule key: node-role.kubernetes.io/master -
手动调度控制
- 不可调度模式:使用
kubectl cordon <node>设置unschedulable: true,维护完成后kubectl uncordon恢复。 - 驱逐 Pod:
kubectl drain会同时设置unschedulable并驱逐 Pod(需--ignore-daemonsets忽略 DaemonSet)。
- 不可调度模式:使用
6.4.Node Status核心字段
| 字段名称 | 类型 | 描述 | 注意事项 | 参考来源 |
|---|---|---|---|---|
| addresses | []Object | 节点的网络地址列表,包括 HostName、ExternalIP、InternalIP 等。 | - 具体字段由云厂商或物理机配置决定 - 合并操作可能导致数据损坏,建议全量更新 | |
| allocatable | map[string]string | 节点可分配资源(如 CPU、内存),表示可调度给 Pod 的资源总量(扣除系统预留)。 | - 默认与 capacity 一致,但排除系统组件占用- 影响调度器决策 | |
| capacity | map[string]string | 节点总资源量(如 CPU、内存、最大 Pod 数)。 | - 由 kubelet 上报- 包含所有资源类型(如 ephemeral-storage) | |
| conditions | []Object | 节点健康状况集合,包括 Ready、MemoryPressure、DiskPressure 等状态。 | - Ready 为 Unknown 或 False 超时(默认 5 分钟)将触发 Pod 驱逐 | |
| config | Object | 动态 Kubelet 配置状态(通过 ConfigMap 传递)。 | - 已弃用(v1.22+),DynamicKubeletConfig 特性已移除 | |
| daemonEndpoints | Object | 节点上 Daemon 服务的端点信息(如 kubeletEndpoint 端口)。 | - 主要用于内部通信(如 kubelet 的 10250 端口) | |
| images | []Object | 节点上已下载的容器镜像列表(包括镜像名称、大小、版本)。 | - 由 kubelet 定期收集- 影响镜像垃圾回收策略 | - |
| nodeInfo | Object | 节点基础信息,包括内核版本、容器运行时版本、OS 类型等。 | - 示例:kernelVersion: 5.4.0, kubeletVersion: v1.25.3 | |
| phase | string | 节点生命周期阶段(如 Pending、Running)。 | - 已弃用,由 conditions 替代 | |
| volumesAttached | []Object | 已挂载到节点的持久卷(PV)列表(如 AWS EBS、GCE PD)。 | - 仅记录通过 CSI/In-Tree 插件挂载的卷 - 用于卷状态跟踪 | - |
| volumesInUse | []string | 节点当前正在使用的持久卷名称列表。 | - 防止卷被意外卸载或删除 - 影响 Pod 驱逐逻辑(如卷未卸载则延迟驱逐) | - |
1.关键字段扩展说明
-
conditions 字段详解
- Ready:节点是否健康(
True/False/Unknown)。 - MemoryPressure:内存是否不足。
- DiskPressure:磁盘容量或 inode 是否不足。
- PIDPressure:进程数是否过多。
- NetworkUnavailable:网络配置是否异常。
- Ready:节点是否健康(
-
allocatable 与 capacity 的区别
- capacity:物理资源总量(如
cpu: "4"表示 4 核)。 - allocatable:实际可调度资源(如
cpu: "3800m",扣除系统预留 200m)。
- capacity:物理资源总量(如
-
addresses 字段示例
"addresses": [ { "type": "HostName", "address": "node-01" }, { "type": "InternalIP", "address": "192.168.1.10" }, { "type": "ExternalIP", "address": "203.0.113.5" } ] -
volumesInUse 的作用场景
- 当节点故障时,若 Pod 使用本地卷(如
hostPath),volumesInUse会阻止 Pod 立即被调度到其他节点,直到卷释放或手动清理。
2.注意事项
- 当节点故障时,若 Pod 使用本地卷(如
-
弃用字段:
phase和config已弃用,建议使用conditions和静态配置替代。 -
健康检查机制:节点心跳通过
Lease对象更新(默认 10 秒一次),超时 40 秒标记为Unknown。 -
资源监控:
allocatable和capacity直接影响调度策略,需定期检查资源预留配置。
6.5.NodeIpamController 与 NodeLifecycleController
-
k8s v1.16版本中 NodeController 被分为了 NodeIpamController 与 NodeLifecycleController
-
原 NodeController 的问题
- 早期版本中,节点管理、IP 分配、驱逐逻辑耦合在单一控制器中,代码复杂度高且扩展性差。
-
拆分意义
- 职责分离:将 IP 地址管理 和 节点生命周期管理 解耦,提升代码可维护性。
- 功能增强:针对不同场景(如云环境、多网络插件)优化 IP 分配策略和节点故障处理逻辑。
功能维度 NodeIpamController NodeLifecycleController 核心职责 管理节点的 Pod CIDR 分配与回收,确保集群内节点 IP 段不重叠 监控节点 生命周期状态,处理节点健康检查、污点管理、Pod 驱逐及分区容灾策略 主要功能 • 新节点加入时分配 podCIDR
• 节点删除时回收 CIDR 供复用
• 支持多网段(IPv4/IPv6)• 节点心跳监控(通过 Lease和NodeStatus)
• 自动添加污点(如NotReady/Unreachable)
• 按策略驱逐 Pod(限速/分区容灾)关键参数配置 --cluster-cidr(集群总 CIDR)--node-cidr-mask-size(节点子网掩码)--node-monitor-grace-period(节点失联容忍时间)--pod-eviction-timeout(驱逐超时时间)--unhealthy-zone-threshold(分区容灾阈值)依赖特性门控 无 TaintBasedEvictions(污点驱逐)TaintNodesByCondition(基于节点状态自动污点)数据交互对象 Node.spec.podCIDRClusterCIDR(多网段场景)Node.status.conditions(节点状态)Pod(驱逐操作)Taint(污点标签)典型应用场景 • 节点扩容时自动分配 IP 段
• 跨云平台实现动态 CIDR 管理• 节点宕机时自动驱逐 Pod
• 磁盘压力触发NoSchedule污点
• 网络分区时暂停驱逐避免雪崩源码实现核心逻辑 通过 RangeAllocator或CloudAllocator分配 CIDR通过 TaintManager监听污点变化,结合RateLimitedTimedQueue限速驱逐 Pod性能优化方向 • 大规模集群启用 MultiCIDRRangeAllocator
• 云环境优先使用CloudAllocator• 调整 --node-eviction-rate和--secondary-node-eviction-rate限流参数
• 优化分区状态同步机制
7.DaemonSet
7.1.基本功能
- DaemonSet 是 Kubernetes 的核心工作负载控制器,专为 节点级服务 设计,主要功能包括:
- 全节点覆盖:确保集群中每个节点(或指定标签的节点)运行 唯一 Pod 副本
- 动态扩缩:自动感知节点变化,新节点加入时自动创建 Pod,节点移除时回收 Pod
- 系统级服务托管:适用于日志收集(Fluentd)、监控代理(Node Exporter)、网络插件(Calico)等场景
- 调度策略:支持污点容忍(Tolerations)、节点亲和性(Node Affinity)等高级调度规则
- DaemonSet一般是给管理员用的,运行一些管理服务
7.2.使用示例
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-logging
namespace: kube-system
spec:
selector:
matchLabels:
name: fluentd-logging
template:
metadata:
labels:
name: fluentd-logging
spec:
tolerations:
◦ key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
containers:
◦ name: fluentd
image: fluent/fluentd:v1.16
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
◦ name: varlog
hostPath:
path: /var/log
7.3.Spec 字段详解
| 字段名称 | 类型 | 功能说明 | 注意事项 |
|---|---|---|---|
selector.matchLabels | Object | 匹配 Pod 标签,必须与模板中的 metadata.labels 一致 | 创建后不可修改,否则会导致 Pod 悬浮 |
template | PodTemplate | 定义 Pod 规格,包含容器、卷等配置 | 必须设置 restartPolicy: Always(默认值) |
updateStrategy.type | String | 更新策略:RollingUpdate(滚动更新)或 OnDelete(删除重建) | 滚动更新需设置 maxUnavailable(默认 1) |
minReadySeconds | Integer | Pod 就绪后等待时间(秒) | 用于避免 Pod 未完全初始化就被标记为可用 |
revisionHistoryLimit | Integer | 保留的历史版本数量(默认 10) | 超过限制的旧版本会被自动清理 |
7.4.Status 字段详解
| 字段名称 | 类型 | 必填 | 功能说明 | 关键细节 |
|---|---|---|---|---|
| collisionCount | integer | 否 | 哈希冲突计数器,用于避免 ControllerRevision 名称冲突 | - 当创建新版本 ControllerRevision 时,若检测到哈希冲突则自增此值- 保证版本名称唯一性 |
| conditions | []Object | 否 | 记录 DaemonSet 当前状态的最新观察结果,包含 type、status、lastTransitionTime 等子字段 | - 常见类型:Progressing(滚动更新中)、Available(可用性状态)- 状态值: True/False/Unknown |
| currentNumberScheduled | integer | 是 | 已调度 DaemonSet Pod 的节点数量(符合调度条件的节点中实际运行 Pod 的数量) | - 统计满足 nodeSelector 和 tolerations 的节点数量 |
| desiredNumberScheduled | integer | 是 | 应调度 DaemonSet Pod 的节点数量(符合调度条件的节点总数) | - 等于匹配节点标签的节点数量 - 若未指定 nodeSelector,则等于集群所有节点数 |
| numberAvailable | integer | 否 | 可用 Pod 数量(满足就绪条件且运行时间超过 spec.minReadySeconds) | - 若 minReadySeconds 未设置,则与 numberReady 相同 |
| numberMisscheduled | integer | 是 | 错误调度的节点数量(在不满足条件的节点上运行的 Pod 数量) | - 通常由节点标签变更或污点更新导致 - 需手动清理或通过控制器自动回收 |
| numberReady | integer | 是 | 就绪 Pod 数量(Pod 的 readinessProbe 检查通过) | - 影响服务可用性 - 若 Pod 未配置 readinessProbe,则启动后自动标记为就绪 |
| numberUnavailable | integer | 否 | 不可用 Pod 数量(desiredNumberScheduled - numberAvailable) | - 用于评估滚动更新进度 - 高值可能表示更新受阻或节点资源不足 |
| observedGeneration | integer | 否 | DaemonSet 控制器观察到的资源版本号 | - 当 metadata.generation 大于此值时,表示有未应用的配置变更 |
| updatedNumberScheduled | integer | 否 | 已更新到最新版本的 Pod 数量(使用最新 spec.template 的 Pod) | - 仅在滚动更新期间变化 - 用于监控更新覆盖率 |
7.5.使用注意事项
- 资源限制
-
必须设置
resources.limits防止资源耗尽(尤其在大规模集群) -
示例:
limits: { cpu: "500m", memory: "1Gi" }- 节点调度控制
-
通过
nodeSelector限制部署范围(如node-role.kubernetes.io/worker: "true") -
使用
affinity实现复杂调度规则(如 GPU 节点专属调度)- 更新策略选择
-
生产环境推荐:
RollingUpdate滚动更新,设置maxUnavailable: 1 -
关键组件更新:
OnDelete策略需手动删除旧 Pod- 优先级配置
-
通过
priorityClassName: system-node-critical确保优先调度- 监控与运维
-
使用 Prometheus 监控字段:
kube_daemonset_status_desired_number_scheduled -
命令:
kubectl rollout status daemonset/<name>查看更新进度
7.6.滚动升级与 Deployment 对比
- daemonSet 升级策略的配置与 deployment 相同
updateStrategy: rollingUpdate: maxSurge: 0 maxUnavailable: 1 type: RollingUpdate - 二者升级过程的不同
- deployment:
- 通过监控podTemplate的hash值,生成新的replicaset,控制新旧replicaset数量的变化,完成滚动升级
- deployment 的 pod 名称里一般会有2个随机字符串,一个是replicaset生成的,一个是deployment生成的
- daemonset:
- 通过监控podTemplate的变化,生成新的controllerrevision(保存podTemplate),通过滚动升级配置决定升级哪些node上的pod,然后使用新的controllerrevision的podTemplate replace 到 daemonset 中,然后使用updateStrategy配置完成滚动升级即可
7.7.daemonset 容忍策略
- daemonset更多的应用于基础服务,如收集节点状态、日志信息等,所以有些daemonset会配置更多的tolerations,容忍更多的情况
- 比如下面的配置,在node not-ready、不可达、节点承压的时候都不会走
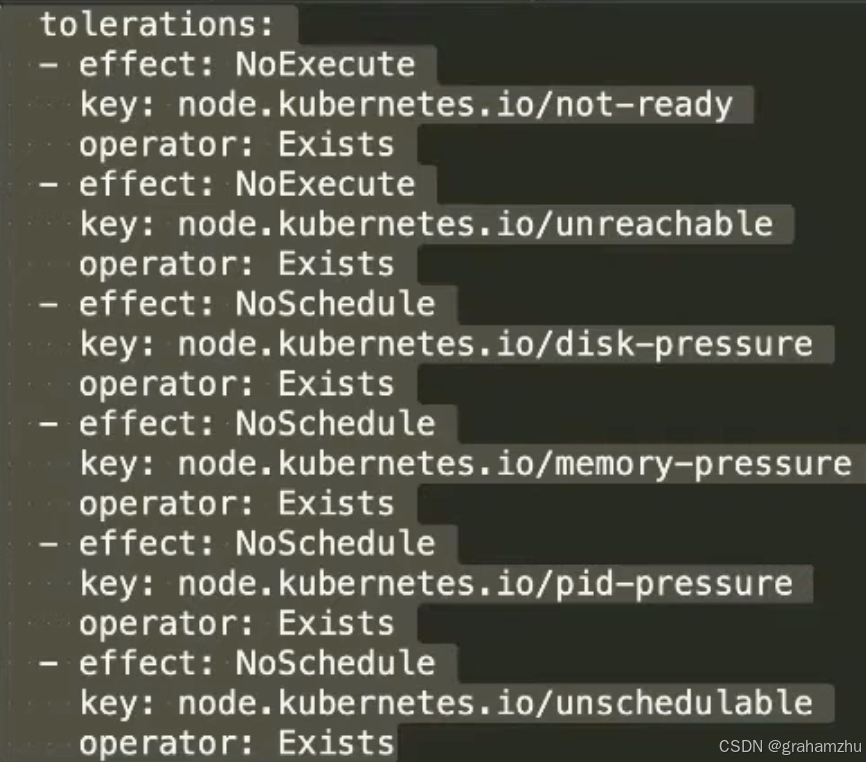
- 相比之下,deployment这种服务,在node有问题时,走掉反而是更好的。走了后可以重新调度到其他节点,完成故障转移
8.Endpoint
8.1.Endpoint 基本功能
- Endpoint 是 Kubernetes 的核心资源,用于管理服务(Service)与后端 Pod 的网络映射关系,主要功能包括:
- 服务发现
- 提供 Service 对应的后端 Pod 的实时 IP 地址和端口,供集群内组件(如 kube-proxy)发现服务。
- 动态更新
- 自动感知 Pod 状态变化(创建、删除、重启),实时更新地址列表。
- 负载均衡
- Service 基于 Endpoint 中的地址列表实现流量分发,支持轮询、随机等策略。
- 外部服务接入
- 允许通过手动创建 Endpoint 将集群外服务(如数据库)映射为 Kubernetes Service。
8.2.Endpoint 使用示例
8.2.1.自动生成 Endpoint(Service 带 Selector)
# Service 定义(自动关联 Pod)
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: my-release-1
meta.helm.sh/release-namespace: default
creationTimestamp: "2025-02-16T09:18:44Z"
labels:
app.kubernetes.io/component: etcd
app.kubernetes.io/instance: my-release-1
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: etcd
app.kubernetes.io/version: 3.5.18
helm.sh/chart: etcd-11.0.7
name: my-release-1-etcd
namespace: default
resourceVersion: "82111449"
spec:
clusterIP: 10.96.196.24
ports:
- name: client
port: 2379
protocol: TCP
targetPort: client
- name: peer
port: 2380
protocol: TCP
targetPort: peer
selector:
app.kubernetes.io/component: etcd
app.kubernetes.io/instance: my-release-1
app.kubernetes.io/name: etcd
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
---
apiVersion: v1
kind: Endpoints
metadata:
annotations:
endpoints.kubernetes.io/last-change-trigger-time: "2025-04-16T06:10:36Z"
creationTimestamp: "2025-02-16T09:18:44Z"
labels:
app.kubernetes.io/component: etcd
app.kubernetes.io/instance: my-release-1
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: etcd
app.kubernetes.io/version: 3.5.18
helm.sh/chart: etcd-11.0.7
name: my-release-1-etcd
namespace: default
subsets:
- addresses:
- ip: 10.244.0.111
nodeName: vm-226-235-tencentos
targetRef:
kind: Pod
name: my-release-1-etcd-0
namespace: default
resourceVersion: "93610940"
uid: 417e2aec-38f8-42c1-877f-906b863437ee
ports:
- name: peer
port: 2380
protocol: TCP
- name: client
port: 2379
protocol: TCP
- 当 Pod 启动后,Kubernetes 会自动创建同名 Endpoint:
kubectl get endpoints my-release-1-etcd - 输出示例:
NAME ENDPOINTS AGE my-release-1-etcd 10.244.0.111:2380,10.244.0.111:2379 76d
8.2.2.手动创建 Endpoint(接入外部服务)
# 手动定义外部数据库 Endpoint
apiVersion: v1
kind: Endpoints
metadata:
name: external-mysql # 必须与 Service 同名
subsets:
- addresses:
- ip: 192.168.1.100 # 外部数据库 IP
ports:
- port: 3306 # 外部数据库端口
# 创建无 Selector 的 Service
apiVersion: v1
kind: Service
metadata:
name: external-mysql
spec:
ports:
- port: 3306
8.3.Endpoint subsets 字段详解
-
endpoint没有spec,有个subsets字段,用于描述后端地址分组,每个分组对应一组 IP:Port
字段名称 类型 必填 功能说明 addresses Array of Object 是 后端实例地址列表 ports Array of Object 是 端口定义(需与 Service 的 targetPort 匹配) notReadyAddresses Array of Object 否 未就绪的后端地址(需配合 Readiness Probe 使用) -
三个字段的结构如下:
# addresses
RESOURCE: addresses <[]Object>
FIELDS:
hostname <string>
The Hostname of this endpoint
ip <string> -required-
The IP of this endpoint. May not be loopback (127.0.0.0/8), link-local
(169.254.0.0/16), or link-local multicast ((224.0.0.0/24). IPv6 is also
accepted but not fully supported on all platforms. Also, certain kubernetes
components, like kube-proxy, are not IPv6 ready.
nodeName <string>
Optional: Node hosting this endpoint. This can be used to determine
endpoints local to a node.
targetRef <Object>
Reference to object providing the endpoint.
# notReadyAddresses
RESOURCE: notReadyAddresses <[]Object>
FIELDS:
hostname <string>
The Hostname of this endpoint
ip <string> -required-
The IP of this endpoint. May not be loopback (127.0.0.0/8), link-local
(169.254.0.0/16), or link-local multicast ((224.0.0.0/24). IPv6 is also
accepted but not fully supported on all platforms. Also, certain kubernetes
components, like kube-proxy, are not IPv6 ready.
nodeName <string>
Optional: Node hosting this endpoint. This can be used to determine
endpoints local to a node.
targetRef <Object>
Reference to object providing the endpoint.
# ports
RESOURCE: ports <[]Object>
FIELDS:
appProtocol <string>
The application protocol for this port. This field follows standard
Kubernetes label syntax. Un-prefixed names are reserved for IANA standard
service names (as per RFC-6335 and
http://www.iana.org/assignments/service-names). Non-standard protocols
should use prefixed names such as mycompany.com/my-custom-protocol. This is
a beta field that is guarded by the ServiceAppProtocol feature gate and
enabled by default.
name <string>
The name of this port. This must match the 'name' field in the
corresponding ServicePort. Must be a DNS_LABEL. Optional only if one port
is defined.
port <integer> -required-
The port number of the endpoint.
protocol <string>
The IP protocol for this port. Must be UDP, TCP, or SCTP. Default is TCP.
8.4.Status 字段说明
- Endpoint 没有独立的状态字段,其健康状态通过以下方式体现:
- addresses/notReadyAddresses 区分就绪与未就绪实例
- Kube-Controller-Manager 监控 Pod 状态并更新 subsets
- kube-proxy 根据 Endpoint 更新 iptables/IPVS 规则
8.5.使用注意事项
- 命名强制关联
- Endpoint 必须与 Service 同名同命名空间 才能生效。
- 避免 Selector 冲突
- 手动创建 Endpoint 时,对应的 Service 必须不设 selector,否则会被自动生成的 Endpoint 覆盖。
- 外部服务接入规范
- 外部服务 IP 必须可达,且端口需开放访问权限。
- 建议通过
nodeName字段标注外部节点(例:- ip: 192.168.1.100nodeName: db-node1)。
- 大规模集群优化
- 当 Pod 数量超过 1000 时,建议使用 EndpointSlice 替代 Endpoint 以提高性能。
- 监控与调试
- 关键命令:
kubectl describe endpoints <name>查看详细信息 - 监控指标:
kube_endpoint_address_available(可用地址数)
- 关键命令:
8.6.Endpoint 与 EndpointSlice 对比
| 特性 | Endpoint | EndpointSlice |
|---|---|---|
| 设计目标 | 小规模集群 | 大规模集群(支持 10 万+端点) |
| 数据结构 | 单资源包含所有地址 | 分片存储(每片最多 1000 端点) |
| 地址类型 | 仅 IP | 支持 IP/FQDN |
| 拓扑信息 | 无 | 包含节点名称、可用区等元数据 |
| 兼容性 | 所有 Kubernetes 版本 | v1.21+ 默认启用 |
9.EndpointSlice
9.1.EndpointSlice 基本功能
- EndpointSlice 是 Kubernetes 用于优化大规模服务后端管理的核心 API 资源,主要特性包括:
- 可扩展分片机制
- 将服务端点拆分为多个切片(默认每个切片最多 100 个端点)
- 支持扩展到 10 万+ 端点的大规模服务
- 多维拓扑感知
- 记录端点所在的节点名称、可用区等信息,支持智能路由
- 双栈服务支持
- 独立管理 IPv4/IPv6/FQDN 地址类型
- 精细化状态追踪
- 包含
ready/serving/terminating三种状态条件
- EndpointSlice 通过label:
kubernetes.io/service-name指定关联的service
9.2.EndpointSlice 使用示例
9.2.1.自动生成 EndpointSlice(Service 带 Selector)
apiVersion: v1
kind: Service
metadata:
annotations:
meta.helm.sh/release-name: my-release-1
meta.helm.sh/release-namespace: default
creationTimestamp: "2025-02-16T09:18:44Z"
labels:
app.kubernetes.io/component: etcd
app.kubernetes.io/instance: my-release-1
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: etcd
app.kubernetes.io/version: 3.5.18
helm.sh/chart: etcd-11.0.7
name: my-release-1-etcd
namespace: default
resourceVersion: "82111449"
selfLink: /api/v1/namespaces/default/services/my-release-1-etcd
uid: 3c4d2738-bd6e-4e18-93f0-1e3270728e53
spec:
clusterIP: 10.96.196.24
ports:
- name: client
port: 2379
protocol: TCP
targetPort: client
- name: peer
port: 2380
protocol: TCP
targetPort: peer
selector:
app.kubernetes.io/component: etcd
app.kubernetes.io/instance: my-release-1
app.kubernetes.io/name: etcd
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
---
apiVersion: discovery.k8s.io/v1beta1
kind: EndpointSlice
metadata:
annotations:
endpoints.kubernetes.io/last-change-trigger-time: "2025-04-16T06:10:36Z"
creationTimestamp: "2025-02-16T09:18:44Z"
generateName: my-release-1-etcd-
generation: 577
labels:
endpointslice.kubernetes.io/managed-by: endpointslice-controller.k8s.io
kubernetes.io/service-name: my-release-1-etcd
name: my-release-1-etcd-rlcrn
namespace: default
ownerReferences:
- apiVersion: v1
blockOwnerDeletion: true
controller: true
kind: Service
name: my-release-1-etcd
uid: 3c4d2738-bd6e-4e18-93f0-1e3270728e53
resourceVersion: "93610945"
selfLink: /apis/discovery.k8s.io/v1beta1/namespaces/default/endpointslices/my-release-1-etcd-rlcrn
uid: 4d78aabf-7227-43ae-acf3-bd0ec3c57acd
addressType: IPv4
endpoints:
- addresses:
- 10.244.0.111
conditions:
ready: true
targetRef:
kind: Pod
name: my-release-1-etcd-0
namespace: default
resourceVersion: "93610940"
uid: 417e2aec-38f8-42c1-877f-906b863437ee
topology:
kubernetes.io/hostname: vm-226-235-tencentos
ports:
- name: peer
port: 2380
protocol: TCP
- name: client
port: 2379
protocol: TCP
- Kubernetes 会自动创建关联的 EndpointSlice:
# kubectl get endpointslice my-release-1-etcd-rlcrn NAME ADDRESSTYPE PORTS ENDPOINTS AGE my-release-1-etcd-rlcrn IPv4 2380,2379 10.244.0.111 76d
9.2.2.手动创建 EndpointSlice(高级场景)
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: custom-ep
labels:
kubernetes.io/service-name: external-service
addressType: IPv4
ports:
- name: https
protocol: TCP
port: 443
endpoints:
- addresses: ["203.0.113.89"]
conditions:
ready: true
nodeName: node-01
zone: us-west2-a
9.3.EndpointSlice Spec 字段详解
-
endpointslice没有spec字段,其配置全部为一级参数(与apiVersion/kind同级)
字段名称 类型 必填 功能说明 示例值/约束条件 addressTypestring 是 地址类型:IPv4/IPv6/FQDN IPv4 ports[]Port 是 协议端口定义 - name: http, protocol: TCPendpoints[]Endpoint 是 端点集合(每个端点包含地址、状态、拓扑信息) addresses: ["10.1.2.3"]metadata.labelsmap 否 标签系统: kubernetes.io/service-name必填kubernetes.io/service-name: svc -
Endpoint结构如下:
字段名称 类型 必填 功能说明 示例值/约束条件 addresses[]string 是 端点 IP 地址列表 conditions.readybool 否 是否就绪(排除终止中 Pod) truenodeNamestring 否 所在节点名称 node-01zonestring 否 可用区信息 us-west2-a -
Port结构如下:
字段名称 类型 必填 功能说明 示例值/约束条件 namestring 是 端口唯一标识符,与 Service 端口名称一致 web-metricsprotocolstring 是 指定传输层协议类型 trueportinteger 否 服务暴露的端口号,空值时需由消费者上下文解析 80、443appProtocolstring 否 标识应用层协议,支持高级流量管理(如 HTTP/2、WebSocket) http、myapp.com/grpc
9.4.EndpointSlice Status 字段说明
- EndpointSlice 无独立 Status 字段,其状态通过以下方式体现:
- Endpoint 条件字段
endpoints: - conditions: ready: true # 是否就绪(排除终止中 Pod) serving: true # 包含终止中 Pod 的就绪状态 terminating: false # 是否处于终止流程 - 控制器监控指标
endpoint_slices_managed_per_service:每个服务管理的切片数量endpoint_slices_created_total:总切片创建数
9.5.大规模pod数量下,endpointslice相比endpoint的优势
本节探讨某应用有1000 个 Pod,EndpointSlice 和 Endpoints 的表现如何
9.5.1.EndpointSlice 的生成结构
-
分片机制
- 默认分片规则:每个 EndpointSlice 默认存储最多 100 个端点(Pod IP+端口组合),可通过
kube-controller-manager --max-endpoints-per-slice=1000调整为每个分片最多 1000 个端点。
- 默认分片规则:每个 EndpointSlice 默认存储最多 100 个端点(Pod IP+端口组合),可通过
-
1000 Pod 的分片示例
- 若采用默认配置(100 端点/分片),将生成 10 个 EndpointSlice,每个分片包含 100 个 Pod 的端点信息。
- 若手动调整分片容量至 1000,则生成 1 个 EndpointSlice,包含全部 1000 个端点。
-
数据格式特征
- 每个 EndpointSlice 包含以下核心字段:
addressType: IPv4 # 地址类型(IPv4/IPv6/FQDN) ports: # 端口列表(最多 100 个端口) - name: http protocol: TCP port: 80 endpoints: # 端点列表(最多 1000 个端点) - addresses: ["10.1.2.3"] conditions: ready: true # 端点状态三元组(ready/serving/terminating) serving: true terminating: false nodeName: node-1 # 拓扑信息(节点、可用区) zone: us-west1-a
9.5.2.相比 Endpoints 的核心优势
-
性能优化
维度 Endpoints(传统) EndpointSlice(优化后) 优势说明 数据更新效率 单对象全量更新(即使 1 个 Pod 变化) 仅更新受影响的分片 1000 Pod 场景下,单次更新数据量从 1.5MB 降至 15KB(降低 99%) 网络传输压力 更新需广播整个对象(如 1.5MB * 3000 节点) 仅传输变更的分片(如 15KB * 1 分片) 在 3000 节点集群中,单次更新总数据量从 4.5GB 降至 45MB(减少 99%) etcd 负载 单对象频繁全量写入(易触发大小限制) 分片写入(避免大对象问题) 避免因单个对象超过 etcd 1.5MB 限制导致数据截断 -
功能扩展
特性 Endpoints(传统) EndpointSlice(优化后) 应用场景 拓扑感知路由 无 通过 nodeName和zone字段支持优化跨可用区流量调度(如优先同区域转发) 双栈服务支持 混合存储 IPv4/IPv6(易混乱) 独立分片管理(通过 addressType区分)同时支持 IPv4 和 IPv6 端点(需创建两个分片) 状态精细控制 仅 ready状态新增 serving和terminating状态支持优雅终止流程(如滚动更新时流量平滑切换) -
可扩展性
- 容量上限:
- Endpoints 最多支持 1000 个端点(受 etcd 限制),而 EndpointSlice 可扩展至 10 万+端点(实测数据)。
- 分片灵活性:
- 支持动态调整分片容量(默认 100,最大 1000),平衡更新频率与管理开销。
- 容量上限:
9.6.使用注意事项
- 版本兼容性
- v1.21+ 默认启用,旧版本需设置特性门控
EndpointSlice=true
- v1.21+ 默认启用,旧版本需设置特性门控
- 分片容量调整
- 通过
--max-endpoints-per-slice调整分片大小(默认 100,最大 1000)
- 通过
- 标签管理
- 使用
endpointslice.kubernetes.io/managed-by标注管理实体 - 系统管理切片标签为
endpointslice-controller.k8s.io
- 使用
- 拓扑路由优化
- 结合
topologyKeys实现区域优先路由,减少跨区流量
- 结合
- 混合环境管理
- 手动创建切片时需确保与服务同名且
addressType匹配
- 手动创建切片时需确保与服务同名且
10.Garbege Controller
10.1.Garbege Controller基本功能
- Kubernetes 垃圾回收控制器(Garbage Controller)是 Kubernetes 控制平面的核心组件之一,主要用于管理对象的级联删除和依赖关系维护。其核心功能如下:
- 自动清理孤儿对象
- 当父对象(Owner)被删除时,自动清理其依赖对象(Dependent)。
- 支持多种删除策略
- Orphan 策略:非级联删除,仅删除父对象,保留依赖对象。
- Background 策略:立即删除父对象,后台异步清理依赖对象(默认策略)。
- Foreground 策略:先删除所有依赖对象,再删除父对象。
- Finalizer 管理
- 通过 Finalizer 机制确保资源在删除前完成清理逻辑(如释放存储卷、网络资源等)
10.2.Garbege Controller使用方法
10.2.1.删除策略配置
- 通过
kubectl delete或 API 指定策略:# 可以用 -h 查看参数详情 kubectl delete -h # 非级联删除(Orphan 策略),旧版本--cascade参数是bool类型,后来就直接指定orphan/... kubectl delete deployment/nginx --cascade=false # 后台级联删除(Background 策略,默认) kubectl delete deployment/nginx # 前台级联删除(Foreground 策略) kubectl delete deployment/nginx --wait=true - 或通过 API 指定
propagationPolicy字段。如:curl -X DELETE \ -H "Content-Type: application/json" \ -d '{"propagationPolicy":"Foreground"}' \ http://<API-SERVER>/apis/apps/v1/namespaces/default/deployments/nginx
10.2.2.Finalizer 配置
- 在资源定义中声明 Finalizer:
apiVersion: v1 kind: Pod metadata: finalizers: - custom-finalizer.example.com
10.3.Garbege Controller 基本原理
10.3.1.依赖关系图(DAG)
- 垃圾回收控制器通过构建有向无环图(DAG) 维护对象间的
ownerReference关系: - GraphBuilder:监听所有资源变化事件,构建 DAG 并维护以下队列:
graphChanges:存储资源变更事件(增/删/改)attemptToDelete:待级联删除的对象队列attemptToOrphan:待处理孤儿对象的队列
10.3.2.工作流程
10.3.3.Finalizer 机制
- Finalizer 是资源删除前的钩子,需在所有 Finalizer 被移除后,对象才能被删除。
- 内置 Finalizer 包括
OrphanFinalizer和ForegroundFinalizer,也可自定义。
10.4.注意事项
10.4.1.跨命名空间限制
- 禁止跨命名空间 OwnerReference:命名空间级资源不能拥有集群级资源,否则会导致 GC 异常。
- 示例错误:命名空间级 Deployment 拥有集群级 Namespace,会触发意外删除。
10.4.2.Finalizer 死锁风险
- 若 Finalizer 逻辑未正确处理(如依赖资源未清理),对象会进入
Terminating状态无法删除。需手动修复:kubectl patch pod/nginx -p '{"metadata":{"finalizers":null}}'
10.4.3.性能优化
- 调整 kube-controller-manager 的参数
--concurrent-gc-syncs可以控制并发处理数(默认 20)。 - 避免高频更新 OwnerReference(如大规模 Deployment 滚动更新)。
10.4.4.自定义资源处理
- 自定义控制器需显式处理 Finalizer 逻辑,防止资源泄漏。
- 推荐使用
client-go库的Finalizer工具函数。
10.4.5.通过 HTTP 端点获取 DAG 关系图
curl http://localhost:10252/debug/controllers/garbagecollector/graph
11.CronJob
11.1.CronJob 基本功能
- CronJob 是 Kubernetes 中用于管理周期性任务的控制器,通过 Cron 表达式定义任务的执行时间,实现以下功能:
- 定时任务:在指定时间点运行一次性任务(如凌晨备份)。
- 周期任务:按固定周期重复执行任务(如每日日志清理)。
- 并发控制:处理任务重叠问题(允许/禁止并发)。
- 历史记录:保留成功/失败的任务记录(默认保留 3 成功/1 失败)。
- 错误处理:支持重试策略和超时机制。
11.2.CronJob 使用示例
apiVersion: batch/v1 # Kubernetes ≥1.21 使用此版本
kind: CronJob
metadata:
name: log-cleanup
spec:
schedule: "0 3 * * *" # 每天凌晨3点执行
concurrencyPolicy: Forbid # 禁止并发执行
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
containers:
- name: cleaner
image: alpine:latest
command: ["/bin/sh", "-c", "rm -rf /logs/*.tmp"]
restartPolicy: Never
schedule: 使用标准 Cron 表达式(分 时 日 月 周)jobTemplate: 定义 Job 模板(继承 Job 控制器所有功能)
11.3.CronJob Spec 完整字段
| 字段名 | 类型 | 必选/可选 | 描述 |
|---|---|---|---|
schedule | string | 必选 | Cron 表达式(如 */5 * * * * 每5分钟) |
jobTemplate | object | 必选 | Job 模板定义(包含完整的 Pod 规范) |
concurrencyPolicy | string | 可选 | 并发策略:Allow(默认)、Forbid(禁止并发)、Replace(替换旧任务) |
startingDeadlineSeconds | int | 可选 | 任务启动超时时间(秒),超时则标记为失败 |
suspend | bool | 可选 | 暂停调度(默认 false) |
successfulJobsHistoryLimit | int | 可选 | 保留成功 Job 数量(默认 3) |
failedJobsHistoryLimit | int | 可选 | 保留失败 Job 数量(默认 1) |
timeZone | string | 可选 | 时区(如 Asia/Shanghai,Kubernetes ≥1.24 支持) |
11.4.CronJob Status 完整字段
| 字段名 | 类型 | 描述 |
|---|---|---|
active | []ObjectReference | 当前活跃的 Job 对象列表 |
lastScheduleTime | Time | 最后一次成功调度的时间 |
lastSuccessfulTime | Time | 最后一次成功完成 Job 的时间 |
conditions | []CronJobCondition | 状态条件(如 Scheduled、Completed) |
11.5.CronJob Controller实现原理
- 时间监控
- 控制器每 10 秒检查一次 Cron 表达式匹配的调度时间点。
- Job 创建
- 到达调度时间后,根据
jobTemplate创建 Job 对象。
- 到达调度时间后,根据
- 并发控制
- 根据
concurrencyPolicy处理可能的重叠任务(如终止旧任务)。
- 根据
- 状态跟踪
- 监控 Job 的执行状态,更新
lastScheduleTime等字段。
- 监控 Job 的执行状态,更新
- 历史清理
- 根据
*JobsHistoryLimit自动清理过期的 Job 记录。
- 根据
11.6.注意事项
- 时区问题
- 默认使用 UTC 时间,需在 Cron 表达式或容器内调整时区。
- 幂等性要求
- 任务逻辑需支持重复执行(如备份前检查是否已完成)。
- 版本兼容性
- Kubernetes <1.21 需使用
apiVersion: batch/v1beta1(已弃用)。
- Kubernetes <1.21 需使用
- 资源限制
- 在
jobTemplate.spec.template.spec中配置资源请求/限制。
- 在
- 精确性限制
- 最小调度间隔为 1 分钟,秒级任务需在容器内实现。
11.7.扩展补充
| 表达式 | 说明 |
|---|---|
0 * * * * | 每小时执行一次 |
0 2 * * 1 | 每周一凌晨2点执行 |
*/5 * * * * | 每5分钟执行一次 |
@daily | 每天午夜执行(同 0 0 * * *) |
12.ControllerRevision
12.1.ControllerRevision 基本功能
-
ControllerRevision 是 Kubernetes 用于管理控制器对象 版本历史记录 的核心 API 对象,主要实现以下功能:
功能 描述 版本快照 保存控制器(如 DaemonSet/StatefulSet)的不可变配置模板快照,实现精确版本回溯 版本追踪 通过递增的 revision字段记录配置变更顺序,支持查看历史版本列表回滚支持 与 kubectl rollout undo结合,快速恢复到指定历史版本配置跨版本对比 提供不同版本配置的差异对比基础,辅助故障排查
12.2.ControllerRevision 设计思想
12.2.1.声明式 API 范式
- 不可变快照:ControllerRevision 对象一旦创建即不可修改,确保版本数据完整性
- 解耦设计:将版本管理与控制器逻辑分离,降低控制器复杂度
- 通用性:支持多种控制器类型(DaemonSet/StatefulSet),统一版本管理接口
12.2.2.版本控制机制
- Hash 生成:基于控制器模板内容生成唯一 Hash,标识版本唯一性
- 版本链:通过
revision字段构建线性版本链,支持顺序回溯
12.3.ControllerRevision 使用示例
12.3.1.查看 ControllerRevision
# 查看 DaemonSet 关联的 ControllerRevision
kubectl get controllerrevision -l name=fluentd-elasticsearch -n kube-system
# 输出示例:
NAME CONTROLLER REVISION AGE
fluentd-elasticsearch-64dc6 daemonset/fluentd-elasticsearch 2 3h
12.3.2.版本回滚操作
# 回滚到 Revision=1 的版本
kubectl rollout undo daemonset/fluentd-elasticsearch --to-revision=1 -n kube-system
12.4.ControllerRevision Spec 完整字段
- ControllerRevision 结构中没有spec,只有 data + revision 保存版本信息
# k explain controllerrevision
KIND: ControllerRevision
VERSION: apps/v1
DESCRIPTION:
ControllerRevision implements an immutable snapshot of state data. Clients
are responsible for serializing and deserializing the objects that contain
their internal state. Once a ControllerRevision has been successfully
created, it can not be updated. The API Server will fail validation of all
requests that attempt to mutate the Data field. ControllerRevisions may,
however, be deleted. Note that, due to its use by both the DaemonSet and
StatefulSet controllers for update and rollback, this object is beta.
However, it may be subject to name and representation changes in future
releases, and clients should not depend on its stability. It is primarily
for internal use by controllers.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
data <map[string]>
Data is the serialized representation of the state.
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
metadata <Object>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
revision <integer> -required-
Revision indicates the revision of the state represented by Data.
| 字段名 | 类型 | 必选 | 描述 |
|---|---|---|---|
revision | int64 | 是 | 版本号(单调递增) |
data | RawExtension | 是 | 序列化的控制器模板数据(如 DaemonSet 的完整 YAML 配置) |
12.5.ControllerRevision Status 完整字段
- ControllerRevision 不包含 Status 字段。因为主要作为版本快照数据,所以也不需要status状态
12.6.应用举例:DaemonSet 版本管理流程
12.7.ControllerRevision 注意事项
| 注意事项 | 解决方案 |
|---|---|
| 不可变性限制 | 禁止直接修改 data 字段,需通过控制器创建新版本 |
| 版本数量控制 | 一般使用方会声明 .spec.revisionHistoryLimit 限制保留的历史版本数(默认无限制),比如statefulset |
| 跨版本兼容性 | 确保回滚版本的 API 版本与当前集群兼容 |
| 存储空间管理 | 定期清理过期 ControllerRevision 对象,避免占用过多 etcd 存储 |
13.Lease
13.1.Lease 基本功能
-
Lease 是 Kubernetes 中实现分布式协调的核心资源(
coordination.k8s.io/v1),主要服务于以下场景:功能 作用描述 实现原理 主从选举 确保分布式系统中只有一个实例成为 Leader(如 kube-scheduler/kube-controller-manager 的高可用) 基于 holderIdentity字段抢占 Lease,失败实例通过监听 Lease 变化触发重新选举分布式锁 控制对共享资源的互斥访问(如数据库 Schema 变更) 利用 resourceVersion实现乐观锁(Compare-and-Swap)机制节点心跳 替代传统的 Node Status 更新,降低 API 服务器压力 kubelet 每 10 秒更新 Lease 的 spec.renewTime,控制平面通过时间戳判断节点活性健康管理 监控组件实例的存活状态,实现故障自愈 若 Leader 未在 leaseDurationSeconds内续约,其他实例将接管 LeaseAPI 服务身份 从 Kubernetes v1.26 开始,每个 kube-apiserver 实例通过 Lease 声明自身存在 支持未来多 API 服务器间协调功能(如滚动升级时的流量切换)
13.2.Lease 使用示例
13.2.1.YAML 定义示例
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
name: my-app-lock
namespace: my-namespace
spec:
holderIdentity: "pod-123" # 当前持有者标识
leaseDurationSeconds: 30 # 租约有效期(秒)
renewTime: "2025-05-04T09:30:00Z" # 最后一次续约时间
13.2.2.Go 客户端实现领导者选举
import (
"k8s.io/client-go/tools/leaderelection"
"k8s.io/client-go/tools/leaderelection/resourcelock"
)
func main() {
lock := &resourcelock.LeaseLock{
LeaseMeta: metav1.ObjectMeta{Name: "my-lock", Namespace: "default"},
Client: clientset.CoordinationV1(),
LockConfig: resourcelock.ResourceLockConfig{Identity: "pod-123"},
}
lec := leaderelection.LeaderElectionConfig{
Lock: lock,
LeaseDuration: 15 * time.Second,
RenewDeadline: 10 * time.Second,
RetryPeriod: 2 * time.Second,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
// Leader 逻辑
},
OnStoppedLeading: func() {
// 释放资源
},
},
}
leaderElector.Run(ctx)
}
13.3.Lease Spec 字段详解
| 字段名 | 类型 | 必选 | 描述 |
|---|---|---|---|
holderIdentity | string | 否 | 当前持有者唯一标识(如 kube-scheduler-7be9e0) |
leaseDurationSeconds | int32 | 否 | 租约有效期(秒),持有者需在此时间内续约 |
acquireTime | Time | 否 | 租约首次获取时间(RFC 3339 格式) |
renewTime | Time | 否 | 最后一次续约时间(控制平面据此判断活性) |
leaseTransitions | int32 | 否 | 租约持有者切换次数(用于监控选举稳定性) |
13.4.Lease Status 字段详解
| 字段名 | 类型 | 描述 |
|---|---|---|
lastTransitionTime | Time | 最后一次状态变更时间(如 Leader 切换) |
message | string | 人类可读的状态描述(如 “Leader election failed”) |
reason | string | 状态变更原因(如 “HolderIdentityChanged”) |
13.5.Lease 使用场景
13.5.1.Lease 实现乐观锁
- Compare-and-Swap (CAS):所有 Lease 更新操作需携带当前
resourceVersion,若与服务器端版本不一致则拒绝操作 - 原子性保证:通过 etcd 的事务机制确保并发更新的原子性
13.5.2.Lease 实现节点心跳
13.5.3.Lease 实现领导者选举
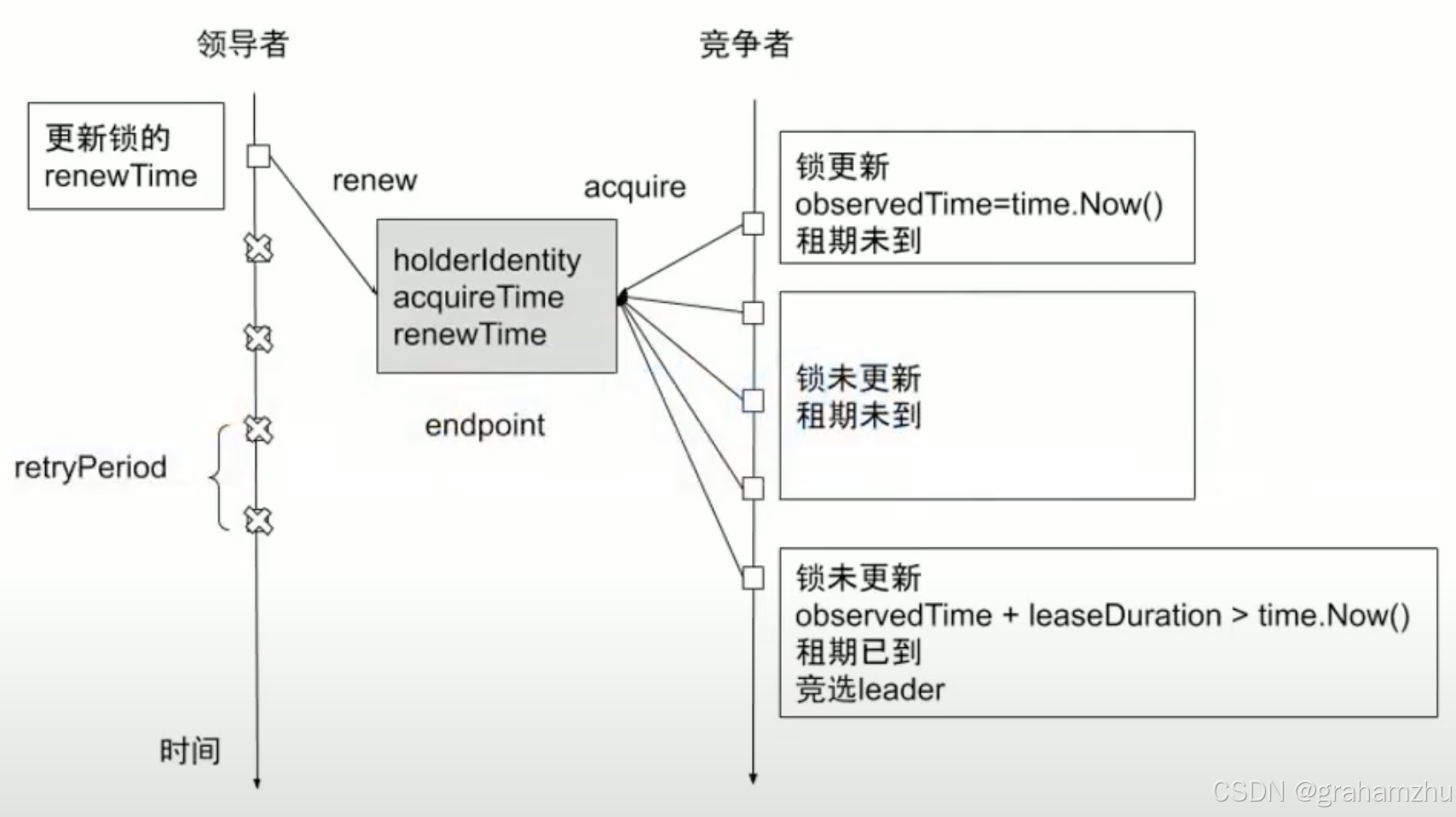
- 候选者启动:尝试创建或更新 Lease,将自身标识写入
holderIdentity - 续约循环:Leader 定期(
RenewDeadline)更新renewTime - 故障检测:若 Leader 未及时续约,其他候选者在重试创建或更新 Lease时成功了,就相当于触发了重新选举
- 状态同步:所有候选者通过 Watch 机制监听 Lease 变化
13.6.Lease 使用注意事项
13.6.1.高可用配置
- 副本数:至少部署 2 个候选者实例,避免单点故障
- 参数调优:
LeaseDuration: 15 * time.Second // 必须 > RenewDeadline RenewDeadline: 10 * time.Second // 必须 > RetryPeriod RetryPeriod: 2 * time.Second // 失败重试间隔
13.6.2.资源管理
- 命名空间隔离:节点心跳 Lease 必须放在
kube-node-lease - 对象清理:定期清理不再使用的 Lease(避免 etcd 存储膨胀)
13.6.3.监控指标
| 指标名称 | 告警规则示例 | 说明 |
|---|---|---|
lease_acquire_total | 突然增长可能表示选举不稳定 | 租约争夺次数 |
lease_renew_errors | 连续 3 次失败需告警 | 续约失败次数 |
lease_transitions_total | 1 小时内超过 5 次需排查 | Leader 切换频率 |
13.6.4.常见问题
- 时钟漂移:节点间需保持 NTP 同步(误差应 <<
leaseDurationSeconds) - 版本兼容:Kubernetes <1.14 需使用
configmaps或endpoints替代 - 性能影响:大规模集群需调整 etcd 的
--max-lease-ttl
13.7.Lease 与 ConfigMap 作为公共对象 对比
| 特性 | Lease | ConfigMap |
|---|---|---|
| 更新频率 | 高频(秒级) | 低频(分钟级) |
| 一致性保证 | 强一致性(通过 etcd 事务) | 最终一致性 |
| 资源开销 | 更低(仅存储关键字段) | 更高(可存储任意数据) |

















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









