









Kubernetes 1.23.0 单节点部署
1. 环境准备
1.1 系统准备
| 主机名 | IP | 说明 | 系统 |
|---|---|---|---|
| k8s-master | 192.168.1.1 | Kubernetes集群的master节点 | CentOS 7.9 |
| k8s-node1 | 192.168.1.2 | Kubernetes集群的node节点 | CentOS 7.9 |
1.2 安全组准备
不使用公有云可跳过此步骤
| 协议类型 | 端口号 | 说明 |
|---|---|---|
| TCP | 2379 | etcd |
| TCP | 2380 | etcd |
| TCP | 10250 | kubelet api |
| TCP | 10251 | kube-scheduler |
| TCP | 10252 | kubelet controller manager |
| TCP | 6443 | kube-apiserver |
| TCP | 30000 - 32767 | NodePort端口范围 |
| TCP | 179 | Calico networking (BGP) |
| TCP | 5473 | Calico networking with Typha enabled |
| UDP | 51820 | Calico networking with IPv4 Wireguard enabled |
| UDP | 51821 | Calico networking with IPv6 Wireguard enabled |
| UDP | 4789 | Calico networking with VXLAN enabled |
1.3.节点环境装备
# 所有master和node节点执行:
# 关闭防火墙、iptables和selinux
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 禁用swap
vim /etc/fstab
swapoff -a
# 主机名互相解析
hostnamectl set-hostname master
vim /etc/hosts
10.0.0.27 node
10.0.0.17 master
# 时间同步
yum install -y chrony
systemctl enable --now chronyd
# 添加网桥过滤和地址转发功能
yum install -y bridge-utils
modprobe br_netfilter
cat > /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-arptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
user.max_user_namespaces=28633
EOF
sysctl -p /etc/sysctl.d/kubernetes.conf
2. 安装docker
# 所有节点执行:
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce
# 配置镜像加速器、使用 systemd 来管理容器的 cgroup
mkdir -p /etc/docker
cat <<EOF > /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"experimental": false,
"debug": false,
"max-concurrent-downloads": 10,
"registry-mirrors": ["https://pgavrk5n.mirror.aliyuncs.com"]
}
EOF
systemctl enable docker && systemctl start docker && systemctl status docker
3.切换国内源
# 所有节点执行:
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
4. 安装指定版本kubeadm、kubelet、kubectl
# 所有节点执行:
# 建议不要安装最新版本,因为最新版本很多组件不兼容,造成安装报错。
yum install -y kubelet-1.23.0 kubeadm-1.23.0 kubectl-1.23.0
# 设置kubelet开机启动
systemctl enable kubelet
5. 初始化K8S
5.1 下载镜像
由于国内无法访问镜像地址k8s.gcr.io,而且阿里云镜像仓库地址也不存在指定版本的,这里建议去 hub.docker.com 搜索kube-proxy 找一个更新频繁、且使用较多的,下面是我的拉取镜像脚本
5.1.1先查询需要的版本
[root@k8s-master docker]# kubeadm config images list
I0516 16:11:19.931203 3838 version.go:255] remote version is much newer: v1.27.1; falling back to: stable-1.23
k8s.gcr.io/kube-apiserver:v1.23.17
k8s.gcr.io/kube-controller-manager:v1.23.17
k8s.gcr.io/kube-scheduler:v1.23.17
k8s.gcr.io/kube-proxy:v1.23.17
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
5.1.2 docker仓库搜索对应版本的kube-proxy
我这里选择 kubesphere 下载的人比较多、更新也频繁
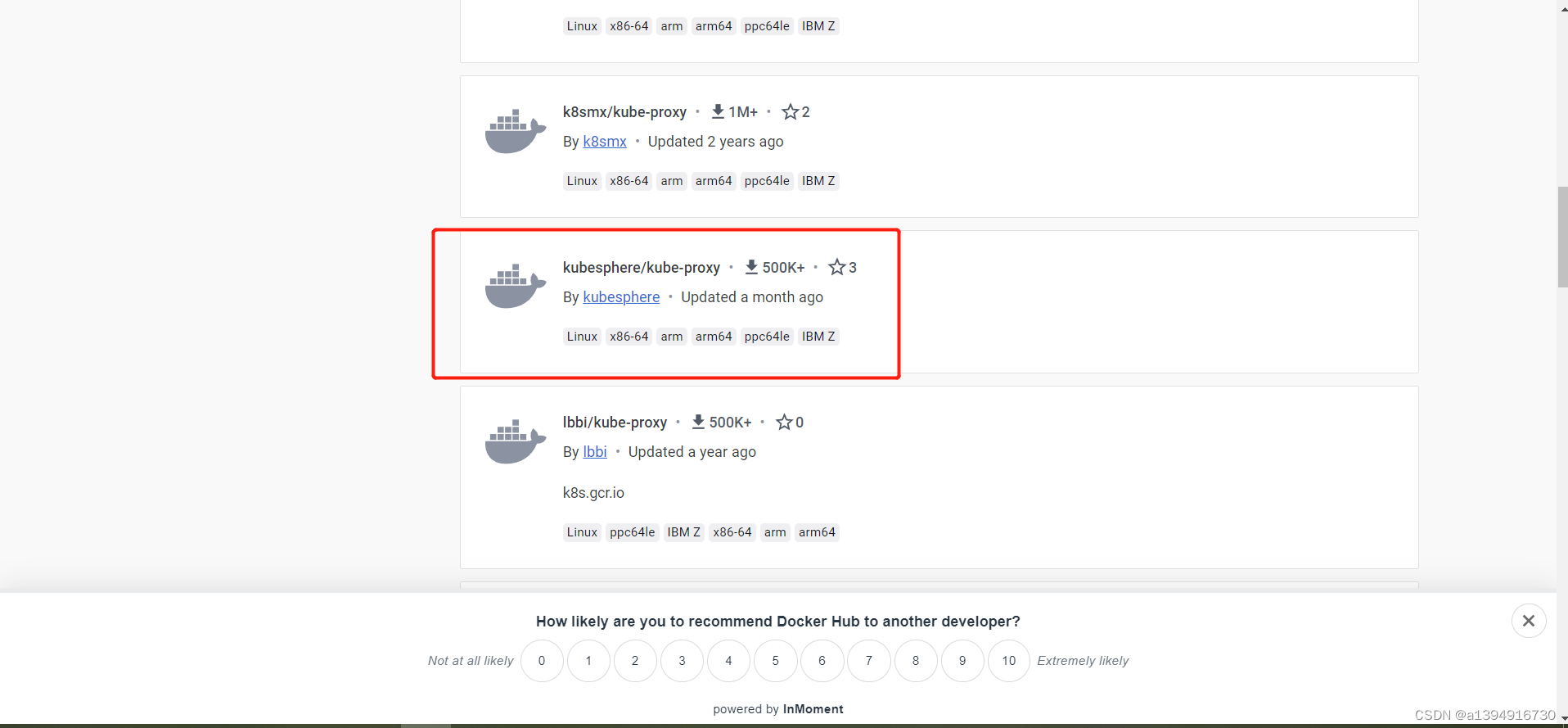
5.1.3 编写拉取镜像脚本
由于设计的镜像比较多,并且需要将镜像重新打标签为k8s.gcr.io,故这里我写了一段脚本,用来拉取镜像并改名
脚本执行完了一定要检查镜像有没有拉取全
set -o errexit
set -o nounset
set -o pipefail
##这里定义版本,根据6.1.1步骤查询到的修改版本号
KUBE_VERSION=v1.23.17
# pause版本
KUBE_PAUSE_VERSION=3.6
# etcd版本
ETCD_VERSION=3.5.1-0
# coredns 版本
COREDNS_VERSION=v1.8.6
##这是原始仓库名,最后需要改名成这个
GCR_URL=k8s.gcr.io
##在docker选择的仓库
DOCKERHUB_URL=kubesphere
# k8s.gcr.io仓库撒花姑娘coredns 的镜像名为 coredns/coredns:xx,格式不一样,不能跟其他的镜像放到一起处理
COREDNS_IMAGE_NAME=coredns:$COREDNS_VERSION
COREDNS_GCR_IMAGE_NAME=coredns/$COREDNS_IMAGE_NAME
##这里是镜像列表
images=(
kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
)
##这里是拉取和改名的循环语句
for imageName in ${images[@]}
do
echo "docker pull $DOCKERHUB_URL/$imageName && docker tag $DOCKERHUB_URL/$imageName $GCR_URL/$imageName && docker rmi $DOCKERHUB_URL/$imageName"
docker pull $DOCKERHUB_URL/$imageName && docker tag $DOCKERHUB_URL/$imageName $GCR_URL/$imageName && docker rmi $DOCKERHUB_URL/$imageName
done
# 这里拉取coredns并改名
echo "docker pull $DOCKERHUB_URL/$COREDNS_IMAGE_NAME && docker tag $DOCKERHUB_URL/$COREDNS_IMAGE_NAME $GCR_URL/$COREDNS_IMAGE_NAME && docker rmi $DOCKERHUB_URL/$COREDNS_IMAGE_NAME"
docker pull $DOCKERHUB_URL/$COREDNS_IMAGE_NAME && docker tag $DOCKERHUB_URL/$COREDNS_IMAGE_NAME $GCR_URL/$COREDNS_GCR_IMAGE_NAME && docker rmi $DOCKERHUB_URL/$COREDNS_IMAGE_NAME
5.2 初始化k8s
我的k8s部署在阿里云公有云上,这里有几个问题:
- –apiserver-advertise-address对应的master节点地址要填内网地址
- 安全组必须开放2379、2380 、6443 端口
- kubernetes-version 设置的版本要与 6.1.3 步骤中的 KUBE_VERSION 版本一致
#master节点:
kubeadm init --apiserver-advertise-address=192.168.1.1 --kubernetes-version=v1.23.17 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=all
# 说明:
–apiserver-advertise-address #集群通告地址(master机器IP)
–image-repository #由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
–kubernetes-version #K8s版本,与上面安装的一致
–service-cidr #集群内部虚拟网络,Pod统一访问入口
–pod-network-cidr #Pod网络,与下面部署的CNI网络组件yaml中保持一致
5.2.1 输出下面的文本就表示初始化成功了
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.1:6443 --token vceoxo.hytglgdvaw3iraum \
--discovery-token-ca-cert-hash sha256:52a41e6c50917cc4ad99793c64c1f00a40f66439860f9a84dbc9063e2928c541
5.2.2 master节点创建必要文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
6. node节点加入集群
6.1 node节点执行初始化生成的join 命令
# 执行初始化生成的join 命令:
kubeadm join 192.168.1.1:6443 --token fnpbrc.e5s4jqrx8na4cpo9 \
--discovery-token-ca-cert-hash sha256:5ecaba93c59504941137c963584e81643c6b50ecda6c2c1f4a4f60ca8cd9a7a0
# 提示"kubectl get nodes",表示加入集群成功,可在master节点使用此命令查看node信息
# 如果忘记或者token过期(默认有效期24小时)需要执行以下命令:
kubeadm token create --print-join-command
6.2 出现下列输出表示加入集群成功
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
6.3 如果加入集群失败,可以删除节点重新添加
6.3.1 master节点删除node节点
# 在master执行删除
kubectl drain k8s-node1 --delete-local-data --force --ignore-daemonsets
kubectl delete node k8s-node1
6.3.2 node节点重置
# 在 node节点执行重置
kubeadm reset
7. 部署网络
访问 calico 查看k8s和calico版本关系
我这里的calico实际没有启动起来,在下面我会介绍问题的解决方案
# master节点执行:
# 下载calico YAML文件
curl https://docs.tigera.io/archive/v3.25/manifests/calico.yaml -O
#修改Pod网络(CALICO_IPV4POOL_CIDR),与前面kubeadm init的–pod-network-cidr指定的一样(大概4551行左右)
vim calico.yaml
......
# no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR #取消注释
value: "10.244.0.0/16" #取消注释,修改为初始化–pod-network-cidr指定的地址
# Disable file logging so `kubectl logs` works.
......
kubectl apply -f calico.yaml
# 稍等片刻,查看节点状态:
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 22h v1.23.0
k8s-node1 Ready <none> 6h42m v1.23.0
# 查看通信状态
[root@k8s-master ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-64cc74d646-qbtqt 1/1 Running 0 5h59m 10.244.36.70 k8s-node1 <none> <none>
calico-node-ptg7k 1/1 Running 0 5h8m 172.27.156.253 k8s-master <none> <none>
calico-node-zj79k 1/1 Running 0 6h1m 172.27.139.243 k8s-node1 <none> <none>
coredns-64897985d-cjjkh 1/1 Running 0 22h 10.244.36.68 k8s-node1 <none> <none>
coredns-64897985d-rk8gj 1/1 Running 0 22h 10.244.36.66 k8s-node1 <none> <none>
etcd-k8s-master 1/1 Running 4 (27m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-apiserver-k8s-master 1/1 Running 6 22h 172.27.156.253 k8s-master <none> <none>
kube-controller-manager-k8s-master 1/1 Running 4 (11m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-proxy-cfq26 1/1 Running 2 (27m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-proxy-f8sr6 1/1 Running 0 6h51m 172.27.139.243 k8s-node1 <none> <none>
kube-scheduler-k8s-master 1/1 Running 5 (16m ago) 22h 172.27.156.253 k8s-master <none> <none>
8. 部署nginx
#创建一个yaml文件
[root@k8s-master ~]# vim nginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
rel: stable
spec:
replicas: 3
selector:
matchLabels:
app: nginx
rel: stable
template:
metadata:
labels:
app: nginx
rel: stable
spec:
containers:
- name: nginx
image: nginx
[root@k8s-master ~]# kubectl apply -f nginx.yml
#再创建一个yaml文件:
[root@master ~]# vim nginx-service.yml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
[root@k8s-master ~]# kubectl apply -f nginx-service.yml
#查看服务 (Running说明启动成功)
[root@k8s-master ~]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-749d94b5db-krftv 1/1 Running 0 7h14m
pod/nginx-deployment-749d94b5db-rq7pr 1/1 Running 0 7h14m
pod/nginx-deployment-749d94b5db-tzr9v 1/1 Running 0 7h14m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23h
service/nginx-service NodePort 10.105.97.46 <none> 8022:31263/TCP 7h12m
# 浏览器打开10.105.97.46:31263就可以看到nginx页面了(端口31263是上边命令查询出来的)
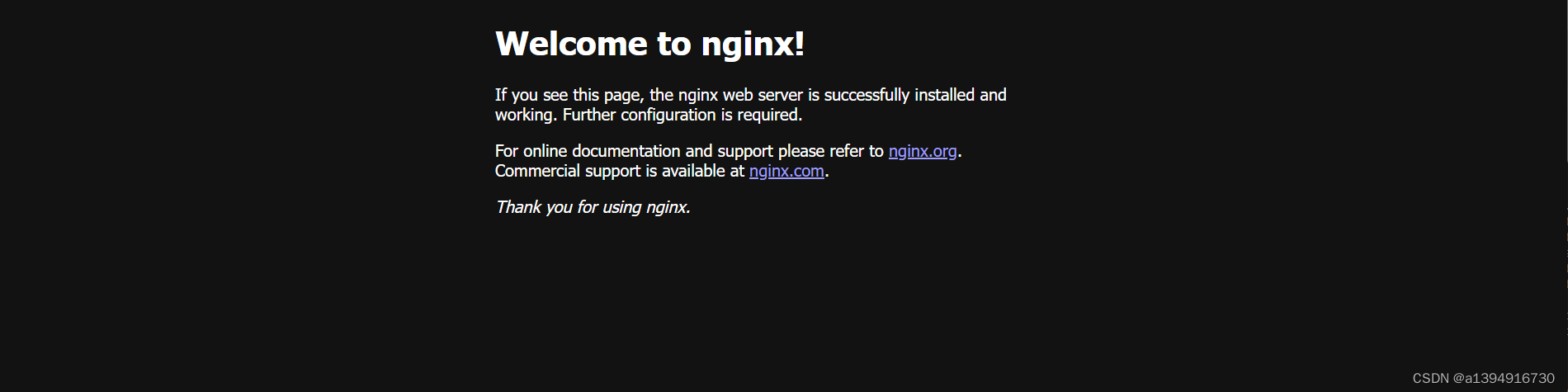
9. 踩坑
9.1 coredns和calico节点处于Pengding状态
这里 coredns 的问题是 calico 没有启动,所以coredns服务一直处于Pending状态
[root@k8s-master pki]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-64cc74d646-qbtqt 0/1 Pengding 0 5h49m <none> k8s-node1 <none> <none>
calico-node-ptg7k 0/1 Pengding 0 4h58m 172.27.156.253 k8s-master <none> <none>
calico-node-zj79k 0/1 Pengding 0 5h52m 172.27.139.243 k8s-node1 <none> <none>
coredns-64897985d-cjjkh 0/1 Pengding 0 22h <none> k8s-node1 <none> <none>
coredns-64897985d-rk8gj 0/1 Pengding 0 22h <none> k8s-node1 <none> <none>
etcd-k8s-master 1/1 Running 4 (17m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-apiserver-k8s-master 1/1 Running 6 22h 172.27.156.253 k8s-master <none> <none>
kube-controller-manager-k8s-master 1/1 Running 4 (2m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-proxy-cfq26 1/1 Running 2 (17m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-proxy-f8sr6 1/1 Running 0 6h42m 172.27.139.243 k8s-node1 <none> <none>
kube-scheduler-k8s-master 1/1 Running 5 (6m24s ago) 22h 172.27.156.253 k8s-master <none> <none>
9.1.1 查看calico-node-ptg7k节点日志可以看到
Jul 27 10:17:27 cmpaas-core-new-mpp-j-1 kubelet[47192]: E0727 10:17:27.076332 47192 kuberuntime_manager.go:674] killPodWithSyncResult failed: failed to
"KillPodSandbox" for "d49635fa-a070-469d-9228-d64a900e4403" with KillPodSandboxError:
"rpc error: code = Unknown desc = networkPlugin cni failed to teardown pod \"kong-
migrations-pqwll_kong\" network: error getting ClusterInformation: Get
https://[169.169.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default:
dial tcp 169.169.0.1:443: i/o timeout"
9.1.2 查看kube-proxy-cfq26节点
我参考了别的博主,169.169.0.1:443: i/o timeout 问题基本就是kube-proxy的问题
9.1.2.1 问题:1、certs证书过期了 2、172.27.156.253没有加入证书中
W0517 08:26:49.480924 1 reflector.go:324] k8s.io/client-go/informers/factory.go:134: failed to list *v1.Service: Get "https://172.27.156.253:6443/api/v1/services?labelSelector=%21service.kubernetes.io%2Fheadless%2C%21service.kubernetes.io%2Fservice-proxy-name&limit=500&resourceVersion=0": x509: certificate is valid for 10.96.0.1, 192.168.0.1, not 172.27.156.253
E0517 08:26:49.480950 1 reflector.go:138] k8s.io/client-go/informers/factory.go:134: Failed to watch *v1.Service: failed to list *v1.Service: Get "https://172.27.156.253:6443/api/v1/services?labelSelector=%21service.kubernetes.io%2Fheadless%2C%21service.kubernetes.io%2Fservice-proxy-name&limit=500&resourceVersion=0": x509: certificate is valid for 10.96.0.1, 192.168.0.1, not 172.27.156.253
9.1.2.2 解决:重置cert和kubeconfig
# 1.删除apiserver token, 这一步一定要执行 不然步骤2中加入的ip不生效
rm /etc/kubernetes/pki/apiserver.*
# 2.加入公网和内网ip 再初始化certs
kubeadm init phase certs all --apiserver-cert-extra-sans=172.27.156.253,192.168.0.1
# 3.删除旧的配置(我执行的时候跳过这一步,发现不影响后续,可跳过,我这里记录一下步骤)
cd /etc/kubernetes
rm -f admin.conf kubelet.conf controller-manager.conf scheduler.conf
# 4.重置配置
kubeadm init phase kubeconfig all
# 5.删除相应apiserver pod
docker stop `docker ps -q -f 'name=k8s_kube-apiserver*'`
docker rm `docker ps -q -f 'name=k8s_kube-apiserver*'`
# 6.重启kubelet
systemctl restart kubelet
9.1.3 重新查看就发现状态变成Running了
[root@k8s-master ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-64cc74d646-qbtqt 1/1 Running 0 5h59m 10.244.36.70 k8s-node1 <none> <none>
calico-node-ptg7k 1/1 Running 0 5h8m 172.27.156.253 k8s-master <none> <none>
calico-node-zj79k 1/1 Running 0 6h1m 172.27.139.243 k8s-node1 <none> <none>
coredns-64897985d-cjjkh 1/1 Running 0 22h 10.244.36.68 k8s-node1 <none> <none>
coredns-64897985d-rk8gj 1/1 Running 0 22h 10.244.36.66 k8s-node1 <none> <none>
etcd-k8s-master 1/1 Running 4 (27m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-apiserver-k8s-master 1/1 Running 6 22h 172.27.156.253 k8s-master <none> <none>
kube-controller-manager-k8s-master 1/1 Running 4 (11m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-proxy-cfq26 1/1 Running 2 (27m ago) 22h 172.27.156.253 k8s-master <none> <none>
kube-proxy-f8sr6 1/1 Running 0 6h51m 172.27.139.243 k8s-node1 <none> <none>
kube-scheduler-k8s-master 1/1 Running 5 (16m ago) 22h 172.27.156.253 k8s-master <none> <none>
9.2 node节点执行任意kubectl命令报错
The connection to the server lb.kubesphere.local:6443 was refused - did you specify the right host or port?
9.2.1 解决方案
9.2.1.1 复制master节点文件 /etc/kubernetes/admin.conf 到 node节点 /etc/kubernetes/ 目录下
9.2.1.2 node节点配置环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
9.2.1.3 执行kubectl命令验证
[root@k8s-node1 ~]# kubectl version
Client Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.12", GitCommit:"b058e1760c79f46a834ba59bd7a3486ecf28237d", GitTreeState:"clean", BuildDate:"2022-07-13T14:59:18Z", GoVersion:"go1.16.15", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.17", GitCommit:"953be8927218ec8067e1af2641e540238ffd7576", GitTreeState:"clean", BuildDate:"2023-02-22T13:27:46Z", GoVersion:"go1.19.6", Compiler:"gc", Platform:"linux/amd64"}
10.参考博文
Kubeadm部署k8s单点master
kubernetes报错笔记 (一) calico报错
k8s创建完集群之后coredns一直处于pending状态
如何修改 K8S Master节点 IP?可没想象中那么简单~
Error: kubernetes cluster unreachable: Invalid x509 certificate















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









