






Summary on deep learning framework --- PyTorch
Updated on 2018-07-22 21:25:42
import os
os.environ["CUDA_VISIBLE_DEVICES"]="4"
1. install the pytorch version 0.1.11
## Version 0.1.11
## python2.7 and cuda 8.0
sudo pip install http://download.pytorch.org/whl/cu80/torch-0.1.11.post5-cp27-none-linux_x86_64.whl
pip install torchvision
install pytorch version 0.2.0
sudo pip install http://download.pytorch.org/whl/cu80/torch-0.2.0.post3-cp27-cp27mu-manylinux1_x86_64.whl
install pytorch version 0.4.0
step-1. Download the files from:
https://files.pythonhosted.org/packages/df/a4/7f5ec6e9df1bf13f1881353702aa9713fcd997481b26018f35e0be85faf7/torch-0.4.0-cp27-cp27mu-manylinux1_x86_64.whl
step-2. Install this file
pip install torch-0.4.0-cp27-cp27mu-manylinux1_x86_64.whl
Other visions of pyTorch can check this file: https://github.com/pytorch/pytorch.github.io/blob/master/_data/wizard.yml
You can also download related files from my Baidu Yun: https://pan.baidu.com/s/1mc_b6AB6P2YlV6lwxGOOzA
2. what happened when following errors occurs ???


Traceback (most recent call last):
File "examples/triplet_loss.py", line 221, in <module>
File "examples/triplet_loss.py", line 150, in main
File "build/bdist.linux-x86_64/egg/reid/evaluators.py", line 118, in evaluate
File "build/bdist.linux-x86_64/egg/reid/evaluators.py", line 21, in extract_features
File "/usr/local/lib/python2.7/dist-packages/torch/utils_v2/data/dataloader.py", line 301, in __iter__
File "/usr/local/lib/python2.7/dist-packages/torch/utils_v2/data/dataloader.py", line 163, in __init__
File "/usr/local/lib/python2.7/dist-packages/torch/utils_v2/data/dataloader.py", line 226, in _put_indices
File "/usr/lib/python2.7/multiprocessing/queues.py", line 390, in put
File "/usr/local/lib/python2.7/dist-packages/torch/multiprocessing/queue.py", line 17, in send
File "/usr/lib/python2.7/pickle.py", line 224, in dump
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/pickle.py", line 548, in save_tuple
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/pickle.py", line 600, in save_list
File "/usr/lib/python2.7/pickle.py", line 633, in _batch_appends
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/pickle.py", line 600, in save_list
File "/usr/lib/python2.7/pickle.py", line 633, in _batch_appends
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/pickle.py", line 562, in save_tuple
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/multiprocessing/forking.py", line 67, in dispatcher
File "/usr/lib/python2.7/pickle.py", line 401, in save_reduce
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/pickle.py", line 548, in save_tuple
File "/usr/lib/python2.7/pickle.py", line 286, in save
File "/usr/lib/python2.7/multiprocessing/forking.py", line 66, in dispatcher
File "/usr/local/lib/python2.7/dist-packages/torch/multiprocessing/reductions.py", line 113, in reduce_storage
RuntimeError: unable to open shared memory object </torch_29419_2971992535> in read-write mode at /b/wheel/pytorch-src/torch/lib/TH/THAllocator.c:226
Traceback (most recent call last):
File "/usr/lib/python2.7/multiprocessing/util.py", line 274, in _run_finalizers
File "/usr/lib/python2.7/multiprocessing/util.py", line 207, in __call__
File "/usr/lib/python2.7/shutil.py", line 239, in rmtree
File "/usr/lib/python2.7/shutil.py", line 237, in rmtree
OSError: [Errno 24] Too many open files: '/tmp/pymp-QoKm2p'
3. GPU 和 CPU 数据之间的转换:
(1)CPU ---> GPU: a.cuda()
(2)GPU ---> CPU: a.cpu()
(3) torch.tensor ---> numpy array:
a_numpy_style = a.numpy()
(4)numpy array ---> torch.tensor:
1 >>> import numpy as np
2 >>> a = np.ones(5)
3 >>> b = torch.from_numpy(a)
4 >>> np.add(a, 1, out=a)
5 array([ 2., 2., 2., 2., 2.])
6 >>> print(a)
7 [ 2. 2. 2. 2. 2.]
8 >>> print(b)
9
10 2
11 2
12 2
13 2
14 2
15 [torch.DoubleTensor of size 5]
16
17 >>> c=b.numpy()
18 >>> c
19 array([ 2., 2., 2., 2., 2.])
4. Variable and Tensor:
==>> programs occured error:
expected a Variable, but got a Float.Tensor(), ~~~~
==>> this can be solved by adding:
from torch.autograd import Variable
hard_neg_differ_ = Variable(hard_neg_differ_)
==>> this will change the hard_neg_differ_ into a variable, not a Float.Tensor() any more.
we can read this reference: http://blog.csdn.net/shudaqi2010/article/details/54880748
it tell us:
>>> import torch
>>> x = torch.Tensor(2,3,4)
>>> x
(0 ,.,.) =
1.00000e-37 *
2.4168 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
(1 ,.,.) =
1.00000e-37 *
0.0000 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
[torch.FloatTensor of size 2x3x4]
>>> from torch.autograd import Variable
>>> x = Variable(x)
>>> x
Variable containing:
(0 ,.,.) =
1.00000e-37 *
2.4168 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
(1 ,.,.) =
1.00000e-37 *
0.0000 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
0.0000 0.0000 0.0000 0.0000
[torch.FloatTensor of size 2x3x4]
But, you can not directly convert the Variable to numpy() or something else. You can load the values in the Variable and convert to numpy() through:
value = varable.data.numpy().
5. Some Operations about tensor. obtained from blog: http://www.cnblogs.com/huangshiyu13/p/6672828.html
============改变数组的维度==================
已知reshape函数可以有一维数组形成多维数组
ravel函数可以展平数组
b.ravel()
flatten()函数也可以实现同样的功能
区别:ravel只提供视图view,而flatten分配内存存储
重塑:
用元祖设置维度
>>> b.shape=(4,2,3)
>>> b
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]])
转置:
>>> b
array([0, 1],
[2, 3])
>>> b.transpose()
array([0, 2],
[1, 3])
=============数组的组合==============
>>> a
array([0, 1, 2],
[3, 4, 5],
[6, 7, 8])
>>> b = a*2
>>> b
array([ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16])
1.水平组合
>>> np.hstack((a,b))
array([ 0, 1, 2, 0, 2, 4],
[ 3, 4, 5, 6, 8, 10],
[ 6, 7, 8, 12, 14, 16])
>>> np.concatenate((a,b),axis=1)
array([ 0, 1, 2, 0, 2, 4],
[ 3, 4, 5, 6, 8, 10],
[ 6, 7, 8, 12, 14, 16])
2.垂直组合
>>> np.vstack((a,b))
array([ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16])
>>> np.concatenate((a,b),axis=0)
array([ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16])
3.深度组合:沿着纵轴方向组合
>>> np.dstack((a,b))
array([[ 0, 0],
[ 1, 2],
[ 2, 4],
[ 3, 6],
[ 4, 8],
[ 5, 10],
[ 6, 12],
[ 7, 14],
[ 8, 16]])
4.列组合column_stack()
一维数组:按列方向组合
二维数组:同hstack一样
5.行组合row_stack()
以为数组:按行方向组合
二维数组:和vstack一样
6.==用来比较两个数组
>>> a==b
array([ True, False, False],
[False, False, False],
[False, False, False], dtype=bool)
#True那个因为都是0啊
==================数组的分割===============
>>> a
array([0, 1, 2],
[3, 4, 5],
[6, 7, 8])
>>> b = a*2
>>> b
array([ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16])
1.水平分割(难道不是垂直分割???)
>>> np.hsplit(a,3)
[array([0],
[3],
[6]),
array([1],
[4],
[7]),
array([2],
[5],
[8])]
split(a,3,axis=1)同理达到目的
2.垂直分割
>>> np.vsplit(a,3)
[array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
split(a,3,axis=0)同理达到目的
3.深度分割
某三维数组:::
>>> d = np.arange(27).reshape(3,3,3)
>>> d
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26]])
深度分割后(即按照深度的方向分割)
注意:dsplite只对3维以上数组起作用
raise ValueError('dsplit only works on arrays of 3 or more dimensions')
ValueError: dsplit only works on arrays of 3 or more dimensions
>>> np.dsplit(d,3)
[array([[ 0],
[ 3],
[ 6],
[ 9],
[12],
[15],
[18],
[21],
[24]]), array([[ 1],
[ 4],
[ 7],
[10],
[13],
[16],
[19],
[22],
[25]]), array([[ 2],
[ 5],
[ 8],
[11],
[14],
[17],
[20],
[23],
[26]])]
===================数组的属性=================
>>> a.shape #数组维度
(3, 3)
>>> a.dtype #元素类型
dtype('int32')
>>> a.size #数组元素个数
9
>>> a.itemsize #元素占用字节数
4
>>> a.nbytes #整个数组占用存储空间=itemsize*size
36
>>> a.T #转置=transpose
array([0, 3, 6],
[1, 4, 7],
[2, 5, 8])
6. image paste using python:
im = Image.open('/home/wangxiao/Pictures/9c1147d3gy1fjuyywz23sj20dl09u3yw.jpg') box = (100,100,500,500)
region = im.crop(box)
im.paste(region,(100,70))
im.show()

7. pytorch save checkpoints
torch.save(model.state_dict(), filename)
8. install python3.5 on ubuntu system:
sudo add-apt-repository ppa:fkrull/deadsnakes
sudo apt-get update
sudo apt-get install python3.5
when testing, just type: python3.5
9. load imge to tensor & save tensor data to image files.
def tensor_load_rgbimage(filename, size=None, scale=None):
img = Image.open(filename)
if size is not None:
img = img.resize((size, size), Image.ANTIALIAS)
elif scale is not None:
img = img.resize((int(img.size[0] / scale), int(img.size[1] / scale)), Image.ANTIALIAS)
img = np.array(img).transpose(2, 0, 1)
img = torch.from_numpy(img).float()
return img
def tensor_save_rgbimage(tensor, filename, cuda=False):
if cuda:
img = tensor.clone().cpu().clamp(0, 255).numpy()
else:
img = tensor.clone().clamp(0, 255).numpy()
img = img.transpose(1, 2, 0).astype('uint8')
img = Image.fromarray(img)
img.save(filename)
10. the often used opeartions in pytorch:
########################## save log files #############################################
logfile_path = './log_files_AAE_2017.10.08.16:20.txt'
fobj=open(logfile_path,'a')
fobj.writelines(['Epoch: %d Niter:%d Loss_VAE: %.4f Loss_D: %.4f Loss_D_noise: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f \n'
% (EEEPoch, total_epoch, VAEerr.data[0], errD_noise.data[0], errD.data[0], total_errG.data[0], D_x, D_G_z1, D_G_z2)])
fobj.close()
# print('==>> saving txt files ... Done!')
########################### save checkpoints ###########################
if epoch%opt.saveInt == 0 and epoch!=0:
torch.save(netG.state_dict(), '%s/netG_epoch_%d.pth' % (opt.outf, epoch))
# torch.save(netD.state_dict(), '%s/netD_epoch_%d.pth' % (opt.outf, epoch))
# torch.save(netD_gaussian.state_dict(), '%s/netD_Z_epoch_%d.pth' % (opt.outf, epoch))
# ########################### save middle images into folders ###########################
# img_index = EEEPoch + index_batch + epoch
# if epoch % 10 == 0:
# vutils.save_image(real_cpu, '%s/real_samples.png' % img_index,
# normalize=True)
# fake = netG.decoder(fixed_noise)
# vutils.save_image(fake.data,
# '%s/fake_samples_epoch_%03d.png' % (img_index, img_index),
# normalize=True)
11. error: RuntimeError: tensors are on different GPUs
==>> this is caused you set data into GPU mode, but not pre-defined model.
12. torch.mm and torch.spmm
torch.mm(mat1, mat2) ---> 输入的两个矩阵相乘;
torch.spmm() --->
13. Expected object of type torch.cuda.LongTensor but found type torch.cuda.DoubleTensor for argument #2 'target'
File "/usr/local/lib/python2.7/dist-packages/torch/nn/functional.py", line 1332, in nll_loss
return torch._C._nn.nll_loss(input, target, weight, size_average, ignore_index, reduce)
RuntimeError: Expected object of type torch.cuda.LongTensor but found type torch.cuda.DoubleTensor for argument #2 'target'
==>> Solution: just add .long() to change the type of that variable, according to https://github.com/fastai/fastai/issues/71.
14. RuntimeError: multi-target not supported at /pytorch/aten/src/THCUNN/generic/ClassNLLCriterion.cu:16
File "run_train.py", line 150, in train_gcnTracker
loss_train = F.nll_loss(output.float(), labels.long())
File "/usr/local/lib/python2.7/dist-packages/torch/nn/functional.py", line 1332, in nll_loss
return torch._C._nn.nll_loss(input, target, weight, size_average, ignore_index, reduce)
RuntimeError: multi-target not supported at /pytorch/aten/src/THCUNN/generic/ClassNLLCriterion.cu:16
==>> Solution: change the label into a single class labels, i.e. 1,2,3, ... N. Do not use one-hot like labels, according to https://discuss.pytorch.org/t/runtimeerror-multi-target-not-supported-newbie/10216/6
15. Set GPU ID: export CUDA_VISIBLE_DEVICES=0
16. fig.savefig(os.path.join(savefig_dir,'0000.jpg'),dpi=dpi)
1 # Display
2 savefig = savefig_dir != ''
3 if display or savefig:
4 dpi = 80.0
5 figsize = (image.size[0]/dpi, image.size[1]/dpi)
6
7 fig = plt.figure(frameon=False, figsize=figsize, dpi=dpi)
8 ax = plt.Axes(fig, [0., 0., 1., 1.])
9 ax.set_axis_off()
10 fig.add_axes(ax)
11 im = ax.imshow(image, aspect='normal')
12
13 if gt is not None:
14 gt_rect = plt.Rectangle(tuple(gt[0,:2]),gt[0,2],gt[0,3],linewidth=3, edgecolor="#00ff00", zorder=1, fill=False)
15 ax.add_patch(gt_rect)
16
17 rect = plt.Rectangle(tuple(result_bb[0,:2]),result_bb[0,2],result_bb[0,3],
18 linewidth=3, edgecolor="#ff0000", zorder=1, fill=False)
19 ax.add_patch(rect)
20
21 # pdb.set_trace()
22
23 if display:
24 plt.pause(.01)
25 plt.draw()
26 if savefig:
27 fig.savefig(os.path.join(savefig_dir,'0000.png'),dpi=dpi)
File "/usr/local/lib/python2.7/dist-packages/matplotlib/figure.py", line 1563, in savefig
self.canvas.print_figure(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/matplotlib/backend_bases.py", line 2232, in print_figure
**kwargs)
File "/usr/local/lib/python2.7/dist-packages/matplotlib/backends/backend_agg.py", line 583, in print_jpg
return image.save(filename_or_obj, format='jpeg', **options)
File "/usr/local/lib/python2.7/dist-packages/PIL/Image.py", line 1930, in save
save_handler(self, fp, filename)
File "/usr/local/lib/python2.7/dist-packages/PIL/JpegImagePlugin.py", line 607, in _save
raise IOError("cannot write mode %s as JPEG" % im.mode)
IOError: cannot write mode RGBA as JPEG
==>> I find one blog talk about this issue from: blog. I change it type of saved image as ".png" and saved it successfully.
17. when I use torch.cat() to concatenate two tensors, it shown me errors like follows:
*** RuntimeError: Expected a Tensor of type torch.DoubleTensor but found a type torch.FloatTensor for sequence element 1 in sequence argument at position #1 'tensors'
==>> according to https://github.com/pytorch/pytorch/issues/2138 , we can solve it by adding:

18. RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
==== Start Cycle 0 ====
(' ==>> loss_attention: ', tensor(0.6981))
Traceback (most recent call last):
File "step_1_train_attention.py", line 187, in <module>
train_hardAttention()
File "step_1_train_attention.py", line 165, in train_hardAttention
loss_attention.backward()
File "/usr/local/lib/python2.7/dist-packages/torch/tensor.py", line 93, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/local/lib/python2.7/dist-packages/torch/autograd/__init__.py", line 89, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
==>> try this: loss_attention = Variable(loss_attention, requires_grad = True)
19. print the loss variation along with training:
import matplotlib.pyplot as plt
def show_plot(iteration,loss):
plt.plot(iteration,loss)
plt.show()
counter = []
loss_history = []
iteration_number= 0
for epoch in range(0,Config.train_number_epochs):
for i, data in enumerate(train_dataloader,0):
img0, img1 , label = data
img0, img1 , label = img0.cuda(), img1.cuda() , label.cuda()
optimizer.zero_grad()
output1, output2 = net(img0,img1)
loss_contrastive = criterion(output1,output2,label)
loss_contrastive.backward()
optimizer.step()
if i %10 == 0 :
print("Epoch number {}\n Current loss {}\n".format(epoch,loss_contrastive.item()))
iteration_number +=10
counter.append(iteration_number)
loss_history.append(loss_contrastive.item())
show_plot(counter,loss_history)
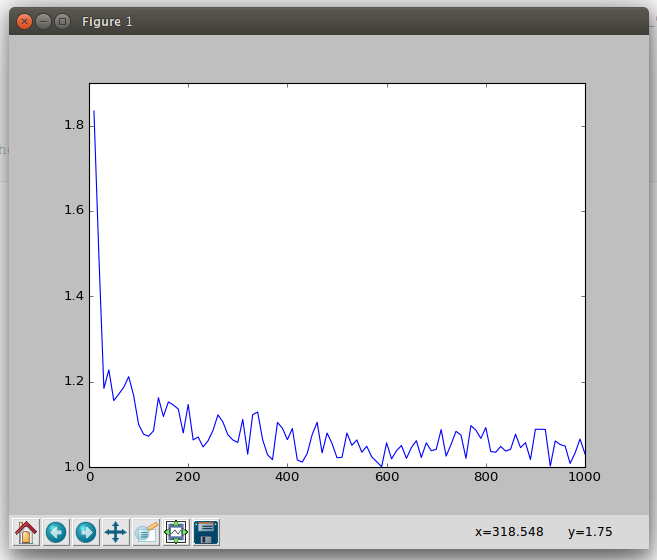
20. Model initialization for fc layers
1 ## Initialization for fc layers
2
3 from torch.nn import init
4
5 self.fc1 = nn.Linear(1024, 1024)
6 init.xavier_normal(self.fc1.weight)
21. PyTorch implementation for convolutional feature visualization:
reference github: https://github.com/leelabcnbc/cnnvis-pytorch/blob/master/test.ipynb
22. ValueError: invalid literal for int() with base 10: '135.5'
(Pdb) int(x)
*** ValueError: invalid literal for int() with base 10: '135.5'
(Pdb) round(float(x))
136.0
(Pdb)
==>> Solution:
int(round(float(initial_BBox[2])))
23. Loading pre-trained VGG-19 Model:
model_root='./vgg16-397923af.pth'
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
"""VGG 19-layer model"""
model = VGG(make_layers(cfg['D']))
model.load_state_dict(torch.load(model_root))
VGG_net = VGG(model)
VGG_net = VGG_net.cuda()
24. *** RuntimeError: CUDNN_STATUS_BAD_PARAM
==>> due to different input and given feature dimension.
25. *** RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
==>> follow the solution from this link.
To reduce memory usage, during the .backward() call, all the intermediary results are deleted when they are not needed anymore.
Hence if you try to call .backward() again, the intermediary results don’t exist and the backward pass cannot be performed (and you get the error you see).
You can call .backward(retain_graph=True) to make a backward pass that will not delete intermediary results, and so you will be able to call .backward() again.
All but the last call to backward should have the retain_graph=True option.
26. RuntimeError: function ConcatBackward returned a gradient different than None at position 3, but the corresponding forward input was not a Variable
g_loss.backward(retain_graph=True)
File "/usr/local/lib/python2.7/dist-packages/torch/autograd/variable.py", line 156, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, retain_variables)
File "/usr/local/lib/python2.7/dist-packages/torch/autograd/__init__.py", line 98, in backward
variables, grad_variables, retain_graph)
RuntimeError: function ConcatBackward returned a gradient different than None at position 3, but the corresponding forward input was not a Variable
==>> Similar operations like: output = torch.cat(Variable(x), y), will cause this problem. You need to check the variables you feed to the neural network and make sure they are all Variable.
27. Shown me the following error when use nn.BCELoss():
CUDA error after cudaEventDestroy in future dtor: device-side assert triggeredTraceback (most recent call last):
File "main.py", line 122, in <module>
g_gen_loss = loss_function(fake_map, batch_map)
File "/usr/local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.6/site-packages/torch/nn/modules/loss.py", line 486, in forward
return F.binary_cross_entropy(input, target, weight=self.weight, reduction=self.reduction)
File "/usr/local/lib/python3.6/site-packages/torch/nn/functional.py", line 1603, in binary_cross_entropy
return torch._C._nn.binary_cross_entropy(input, target, weight, reduction)
RuntimeError: cudaEventSynchronize in future::wait: device-side assert triggered
Exception ignored in: <bound method tqdm.__del__ of 0%| | 0/100 [44:41<?, ?it/s]>
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/tqdm/_tqdm.py", line 931, in __del__
self.close()
File "/usr/local/lib/python3.6/site-packages/tqdm/_tqdm.py", line 1133, in close
self._decr_instances(self)
File "/usr/local/lib/python3.6/site-packages/tqdm/_tqdm.py", line 496, in _decr_instances
cls.monitor.exit()
File "/usr/local/lib/python3.6/site-packages/tqdm/_monitor.py", line 52, in exit
self.join()
File "/usr/local/lib/python3.6/threading.py", line 1053, in join
raise RuntimeError("cannot join current thread")
RuntimeError: cannot join current thread
==>> Find one solution for this issue from: https://github.com/NVIDIA/pix2pixHD/issues/9:
"Get's fixed applying nn.BCEWithLogitsLoss() instead of nn.BCELoss() in networks.py line 82 --it restricts loss values between 0 and 1 before applying the loss."
28. Shit issues about nn.GRU to encode the natural language: RuntimeError: CuDNN error: CUDNN_STATUS_SUCCESS
Traceback (most recent call last):
File "train_mim_langTracking.py", line 373, in <module>
train_mdnet()
File "train_mim_langTracking.py", line 180, in train_mdnet
encoder_output, encoder_hidden = encoder(textEmbedding[ei], encoder_hidden.cuda())
File "/usr/local/lib/python2.7/dist-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "./modules/model.py", line 39, in forward
output, hidden = self.gru(embedded, hidden)
File "/usr/local/lib/python2.7/dist-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/torch/nn/modules/rnn.py", line 192, in forward
output, hidden = func(input, self.all_weights, hx, batch_sizes)
File "/usr/local/lib/python2.7/dist-packages/torch/nn/_functions/rnn.py", line 324, in forward
return func(input, *fargs, **fkwargs)
File "/usr/local/lib/python2.7/dist-packages/torch/nn/_functions/rnn.py", line 288, in forward
dropout_ts)
RuntimeError: CuDNN error: CUDNN_STATUS_SUCCESS
A28: h0, c0 = h0.cuda(), c0.cuda(), according to: https://discuss.pytorch.org/t/cuda-error-runtimeerror-cudnn-status-execution-failed/17625.
29. Deep copy with "clone" operation
A29: vis_feat = x.data.clone()
30. How to Train the Deep Network with Multi-GPU in one machine ?
A30: Here is a Code example from: https://www.jianshu.com/p/b366cad90a6c ( 但是这个代码不能直接跑,因为他只是一个案例,而且有语法错误之类的)。
PyTorch 官方文档给出的接口代码 torch.nn.DataParallel 的解释如下:https://pytorch.org/docs/0.4.1/nn.html#dataparallel
>>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2]) >>> output = net(input_var)
但是有时候想直接运行,还是不行的,比如我(T_T)。我定义的模型中包含了 RoI 的相关操作,该操作原本的调用方式是:
align_h = model.roi_align_model.aligned_height
这个时候,必须改为: align_h = model.module.roi_align_model.aligned_height ,区别就是:中间加一个 module 作为过度才可以。
另外一个 bug 是:原本可以正常执行的代码,加了并行化的模块后,不行了。比如:
==== Start Cycle 0 ====
Traceback (most recent call last):
File "train_lang_coAttention_MultiGPU_version.py", line 311, in <module>
train_mdnet()
File "train_lang_coAttention_MultiGPU_version.py", line 182, in train_mdnet
cur_feat_map = model(cur_scene, language, k, out_layer='conv3')
File "/usr/local/lib/python2.7/dist-packages/torch/nn/modules/module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/torch/nn/parallel/data_parallel.py", line 123, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/usr/local/lib/python2.7/dist-packages/torch/nn/parallel/data_parallel.py", line 133, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/usr/local/lib/python2.7/dist-packages/torch/nn/parallel/parallel_apply.py", line 77, in parallel_apply
raise output
TypeError: forward() takes at least 3 arguments (2 given)
这里,提示我仅仅给了 2 个参数。但是不加这个模块,是可以正常运行的。这是不是说明了,某些 bug 的存在导致了该错误?那么,是什么 bug 呢???
31. (pysot) wangxiao@wx:~/Downloads/pysot/experiments/siamrpn_mobilev2_l234_dwxcorr$ CUDA_LAUNCH_BLOCKING=1 python -u ../../tools/test.py --snapshot model.pth --dataset VOT2018 --config config.yaml
loading VOT2018: 100%|██████████████████████████████████| 60/60 [00:00<00:00, 66.26it/s, zebrafish1]
THCudaCheck FAIL file=/opt/conda/conda-bld/pytorch_1535493744281/work/aten/src/THC/THCGeneral.cpp line=663 error=11 : invalid argument
cudaCheckError() failed : an illegal memory access was encountered
A31. anybody know what happened?
32. 这个函数不能随便用:torch.nn.utils.clip_grad_norm_(model.parameters(), 0.25)
本来原本的代码中不带这句话,收敛的很正常。但是后来因为某些原因,我加上了这个。结果 loss 一直降不下来,维持在 200 左右,坑得很啊,然后我将其注释掉之后,重新跑,loss 分分钟下来了。
Q33. Model transform from caffe to pytorch:
A33. https://github.com/last-one/Pytorch_Realtime_Multi-Person_Pose_Estimation/tree/master/caffe2pytorch
import caffe
from caffe.proto import caffe_pb2
import torch
import os
import sys
sys.path.append('..')
import pose_estimation
from utils import save_checkpoint as save_checkpoint
def load_caffe_model(deploy_path, model_path):
caffe.set_mode_cpu()
net = caffe.Net(deploy_path, model_path, caffe.TEST)
return net
def load_pytorch_model():
model = pose_estimation.PoseModel(num_point=19, num_vector=19, pretrained=True)
return model
def convert(caffe_net, pytorch_net):
caffe_keys = caffe_net.params.keys()
pytorch_keys = pytorch_net.state_dict().keys()
length_caffe = len(caffe_keys)
length_pytorch = len(pytorch_keys)
dic = {}
L1 = []
L2 = []
_1 = []
_2 = []
for i in range(length_caffe):
if 'L1' in caffe_keys[i]:
L1.append(caffe_keys[i])
if '_1' in pytorch_keys[2 * i]:
_1.append(pytorch_keys[2 * i][:-7])
else:
_2.append(pytorch_keys[2 * i][:-7])
elif 'L2' in caffe_keys[i]:
L2.append(caffe_keys[i])
if '_1' in pytorch_keys[2 * i]:
_1.append(pytorch_keys[2 * i][:-7])
else:
_2.append(pytorch_keys[2 * i][:-7])
else:
dic[caffe_keys[i]] = pytorch_keys[2 * i][:-7]
for info in zip(L1, _1):
dic[info[0]] = info[1]
for info in zip(L2, _2):
dic[info[0]] = info[1]
model_dict = pytorch_net.state_dict()
from collections import OrderedDict
weights_load = OrderedDict()
for key in dic:
caffe_key = key
pytorch_key = dic[key]
weights_load[pytorch_key + '.weight'] = torch.from_numpy(caffe_net.params[caffe_key][0].data)
weights_load[pytorch_key + '.bias'] = torch.from_numpy(caffe_net.params[caffe_key][1].data)
model_dict.update(weights_load)
pytorch_net.load_state_dict(model_dict)
save_checkpoint({
'iter': 0,
'state_dict': pytorch_net.state_dict(),
}, True, 'caffe_model_coco')
if __name__ == '__main__':
caffe_net = load_caffe_model('../caffe_model/coco/pose_deploy.prototxt', '../caffe_model/coco/pose_iter_440000.caffemodel')
pytorch_net = load_pytorch_model()
convert(caffe_net, pytorch_net)
Q34. SRU issue: ModuleNotFoundError: No Module named 'cuda_functional':
A34. pip install sru[cuda] will solve this problem.
Q35. Save only or load only part of pre-trained pyTorch model:
A35. https://github.com/agrimgupta92/sgan
# Save another checkpoint with model weights and # optimizer state checkpoint['g_state'] = generator.state_dict() checkpoint['g_optim_state'] = optimizer_g.state_dict() checkpoint['d_state'] = discriminator.state_dict() checkpoint['d_optim_state'] = optimizer_d.state_dict() checkpoint_path = os.path.join(args.output_dir, '%s_with_model.pt' % args.checkpoint_name) logger.info('Saving checkpoint to {}'.format(checkpoint_path)) torch.save(checkpoint, checkpoint_path) logger.info('Done.') # Save a checkpoint with no model weights by making a shallow copy of the checkpoint excluding some items checkpoint_path = os.path.join(args.output_dir, '%s_no_model.pt' % args.checkpoint_name) logger.info('Saving checkpoint to {}'.format(checkpoint_path)) key_blacklist = ['g_state', 'd_state', 'g_best_state', 'g_best_nl_state','g_optim_state', 'd_optim_state', 'd_best_state', 'd_best_nl_state'] small_checkpoint = {} for k, v in checkpoint.items(): if k not in key_blacklist: small_checkpoint[k] = v torch.save(small_checkpoint, checkpoint_path) logger.info('Done.')
pretrained_dict=torch.load(model_weight) model_dict=myNet.state_dict() # 1. filter out unnecessary keys pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} # 2. overwrite entries in the existing state dict model_dict.update(pretrained_dict) myNet.load_state_dict(model_dict) ———————————————— 版权声明:本文为CSDN博主「lxx516」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/LXX516/article/details/80124768
Q36. 在使用 PyTorch 训练的过程中,显存占用越来越大,最终导致 out-of-memory?
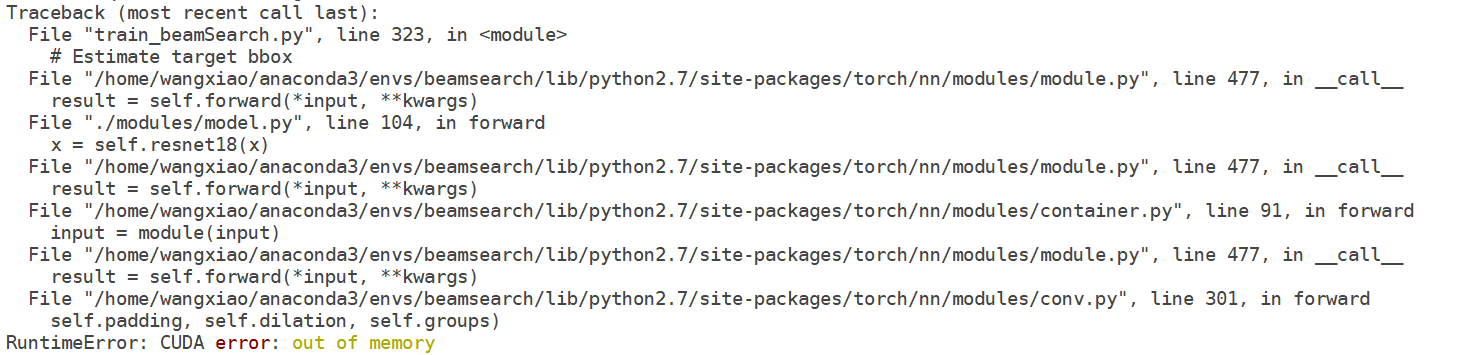
A36. 导致这种情况的一个可能的原因是(我自己遇到的):在计算 total loss 的时候,不能直接相加。要用 .data[0] 将数据取出来,才可以。不然,pyTorch 会自动将该部分加入计算图,导致显存占用越来越多,最终爆掉了。
Q37. *** RuntimeError: _sigmoid_forward_out is not implemented for type torch.cuda.LongTensor
A37. So, how to transform the torch.cuda.LongTensor style into the torch.cuda.FloatTensor ? Try this:
maxIoU = maxIoU.type(torch.cuda.FloatTensor)
Q38. File "training_demo.py", line 236, in <module>
main(args)
File "training_demo.py", line 218, in main
L2_loss.backward()
File "/home/wangxiao/anaconda2/envs/pygoturn/lib/python3.7/site-packages/torch/tensor.py", line 102, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/home/wangxiao/anaconda2/envs/pygoturn/lib/python3.7/site-packages/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
A38. First, you need to do: from torch.autograd import Variable, then, add this line before the backward function:
L2_loss = Variable(L2_loss, requires_grad = True)
Q39.
==















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









