





深度学习框架pytorch
Recently the CES 2020 concluded in Vegas and for those who aren’t aware, CES is the annual trade show for consumer electronics around the world. As such, it an excellent indicator of the direction consumer technology is heading towards in the coming years.
最近,CES 2020在拉斯维加斯闭幕,对于那些不了解的人来说,CES是全球消费类电子产品的年度贸易展。 因此,它很好地表明了消费者技术在未来几年中的发展方向。
For exampple, the cover image presents to you Neon developed by Samsung’s STAR Labs which are Artificial Intelligence-powered virtual beings that look and behave like real humans. Unlike AI assistants like Siri or Alexa though, Neon isn’t programmed to be “know-it-all bots” or an interface to answer users’ questions and demands. Instead, the avatars are designed to converse and sympathize “like real people” in order to act as hyper lifelike companions. This includes being able to move, express themselves, and speak. They can also remember and learn things about their user, and speak in any language. CEO Pranav Mistry further explains the vision he has for his Neon.
例如,封面图像向您展示由三星STAR Labs开发的Neon,Neon是由人工智能驱动的虚拟生物 ,其外观和行为类似于真实的人类。 与Siri或Alexa等AI助手不同的是,Neon并未被编程为“无所不知的机器人”或界面来回答用户的问题和要求。 相反,化身旨在交流和同情“像真实的人”,以便充当超逼真的伴侣。 这包括能够移动,表达自我和说话。 他们还可以记住并学习有关其用户的信息,并以任何语言发言。 首席执行官Pranav Mistry进一步解释了他对霓虹灯的愿景。
“NEON IS LIKE A NEW KIND OF LIFE. NEONS WILL BE OUR FRIENDS, COLLABORATORS, AND COMPANIONS, CONTINUALLY LEARNING, EVOLVING, AND FORMING MEMORIES FROM THEIR INTERACTIONS.” — PRANAV MISTRY, NEON’S CEO.
“霓虹灯就像一种新的生活。 霓虹灯将成为我们的朋友,合作伙伴和伙伴,并通过他们的互动不断学习,发展并形成记忆。” — NEON首席执行官PRANAV MISTRY。
Apart from Neon, there were various innovative products revolving around AI and specifically, Deep Learning.
除了Neon,还有围绕AI(特别是深度学习)的各种创新产品。
So that’s wonderful but how is this relevant to the topic at hand you might ask.
太好了,但这与您可能会问的话题有什么关系。
Well, CES is often quoted to be the window to the future and that window has shown us that going into this new decade, it’s not going to be possible to talk about technology without in some part involving Artificial Intelligence or Machine Learning & Deep Learning (to be precise).
好吧,CES通常被认为是通向未来的窗口,而这个窗口向我们展示了进入新的十年,如果不涉及人工智能或机器学习与深度学习 ,就不可能谈论技术。准确地说)。
At Eduonix, we’ve thoroughly covered the officially supported Deep Learning API of Keras. If you’ve missed out, be sure to check the Keras series.
在Eduonix ,我们全面介绍了Keras官方支持的深度学习API 。 如果您错过了,请务必检查Keras系列。
Now because Deep Learning is such an active field, every once in a while something comes along that has the potential of changing the landscape in the field of Deep Learning. Facebook’s PyTorch is one such library. Since its stable release in early October 2018, many researchers have adopted it as a go-to library because of its ease of building a novel and even extremely complex graphs. So in the next few blogs, we’ll scuba dive into PyTorch starting with the one today!
现在,由于深度学习是一个活跃的领域,因此偶尔会出现一些可能改变深度学习领域格局的潜力。 Facebook的PyTorch就是这样的图书馆之一。 自2018年10月上旬稳定发布以来,由于其易于构建新颖甚至极为复杂的图形,许多研究人员已将其用作入门图书馆。 因此,在接下来的几篇博客中,我们将从今天开始深入研究PyTorch!
Before we start with today’s agenda, however, it would be unfair for us to proceed before making a proper case for the readers of why this blog is worth any of their time. So here’s a little graph showing the unique mentions of PyTorch (solid lines) vs TensorFlow (dotted lines) in various global conferences (marked out with different colors).
但是,在我们开始今天的议程之前,对读者来说,为什么这个博客值得他们花费任何时间之前,对我们继续进行下去是不公平的。 因此,这是一张小图,显示了在各种全球性会议(以不同颜色标记)中PyTorch(实线)与TensorFlow(虚线)的独特提及。
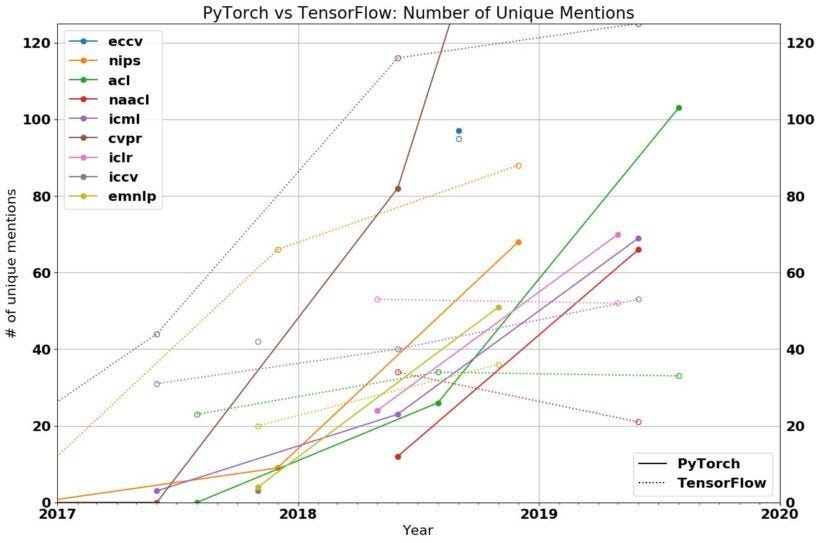
To put this into perspective, consider the tabulation below:
为了对此进行透视,请考虑以下表格:
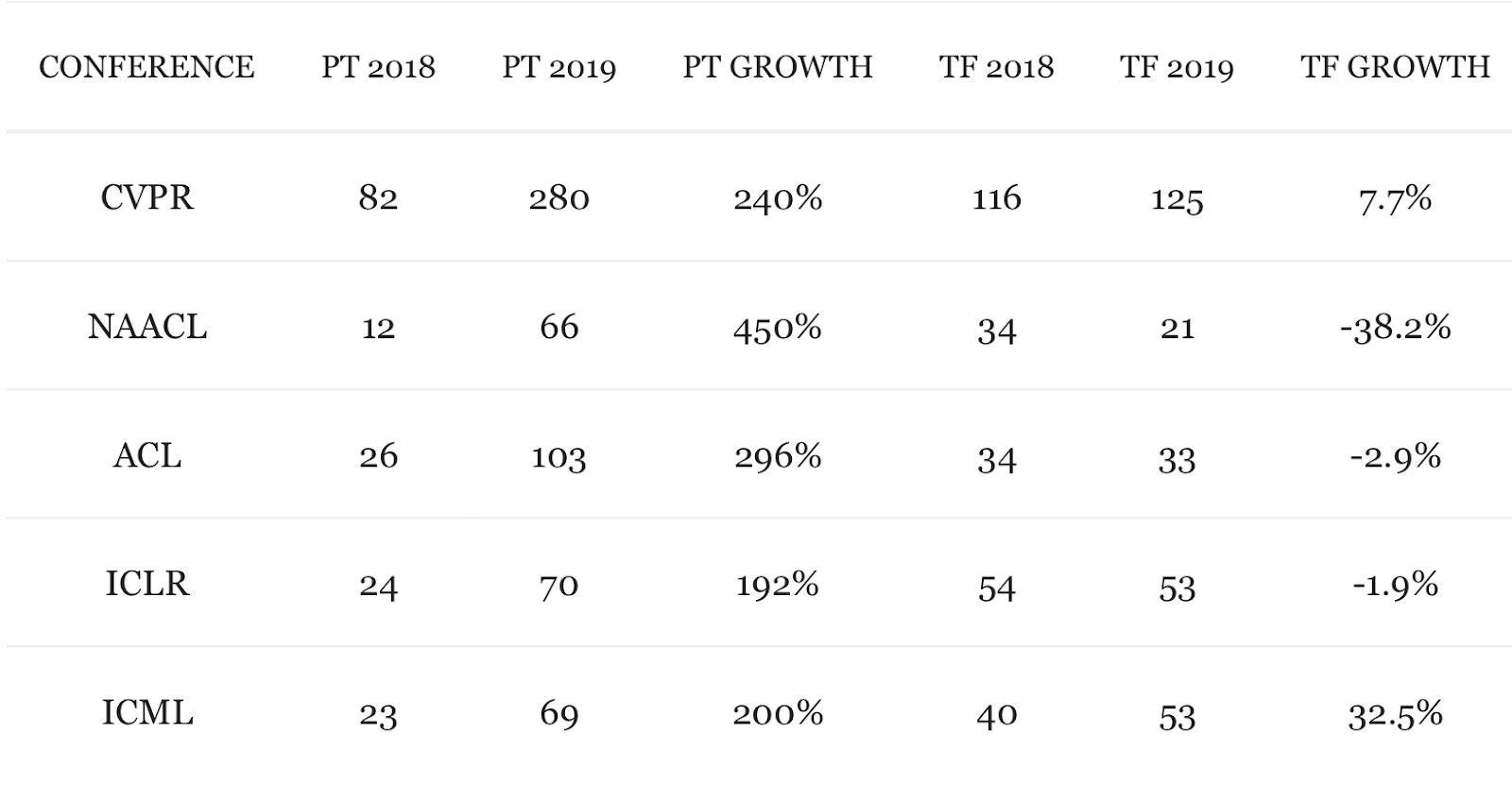
But hey! We get it. You’re not into research really rather just an Artificial Intelligence practitioner! Well, here’s another bit of data to put things into even better perspective for the practitioners:
但是,嘿! 我们懂了。 您实际上并不是在从事研究,而只是在从事人工智能工作! 好吧,这里还有一些数据可以为从业者提供更好的视角:
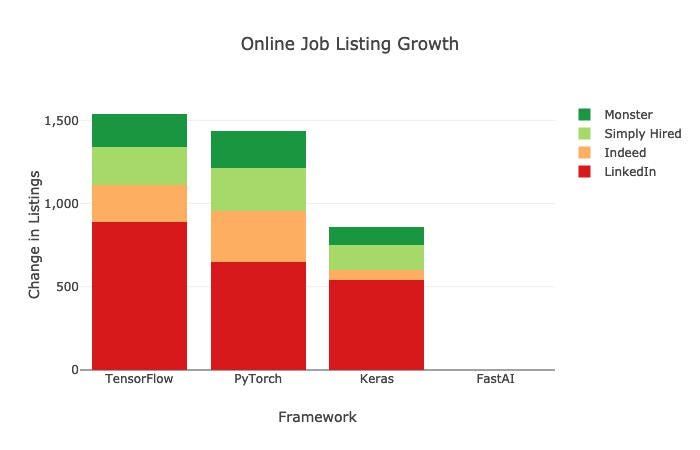
By the end of 2019, TensorFlow had 1541 new job listings vs. 1437 job listings for PyTorch on public job boards. Considering TensorFlow came out several years earlier than a stable release of PyTorch did and the research community, as well as the industry, had adopted TensorFlow as the de facto standard already by then, it’s now come pretty neck to neck between the two.
到2019年底,TensorFlow在公共工作委员会上有1541个新工作列表,而PyTorch有1437个工作列表。 考虑到TensorFlow的发布要比PyTorch的稳定版本早几年发布,并且当时研究界以及整个行业已经采用TensorFlow作为事实上的标准,因此两者之间并驾齐驱 。
A quick note to the readers: although it may seem like Keras is far out in the race, Keras is now officially bundled with every release of TensorFlow which means TensorFlow and Keras is very closely linked to each other. So your Keras expertise is not in vain but quite the opposite in fact!
给读者的提示:尽管Keras似乎在竞争中遥遥领先,但Keras现在已正式与TensorFlow的每个发行版捆绑在一起,这意味着TensorFlow和Keras彼此之间有着非常紧密的联系。 因此,您在Keras方面的专业知识并非徒劳,而是相反!
We’d like to think we’ve made a pretty convincing case for the people working in the industry and also for the practitioners. But if you’re an enthusiast or a hobbyist, just here for the fun, we reckon you’d be just fine ignoring PyTorch since most of the research papers still do have TensorFlow versions of their code released along with the PyTorch versions for you to look at. But we implore you to make this investment today because we don’t know how long it is until TensorFlow versions of the code stop being released altogether by researchers and everything is just PyTorch within the research community. Maybe this year, or the next, who knows? But the dark horse is taking the lead that’s for sure!
我们想认为我们已经为该行业的工作人员和从业人员提供了令人信服的案例。 但是,如果您是发烧友或业余爱好者,那么这里很有趣,我们认为您无需理会PyTorch,因为大多数研究论文仍将其代码的TensorFlow版本以及PyTorch版本发布给您,看着。 但是,我们恳请您今天进行这项投资,因为我们不知道研究人员完全停止发布TensorFlow版本的代码要花多长时间,而且一切都只是研究社区中的PyTorch。 也许今年或明年,谁知道? 但是,黑马确实可以带头!

耽误! 但是,PyTorch到底是什么东西? (Hold up! But what exactly is this PyTorch thing?)
Finally! We’re glad you asked. So surprise surprise but PyTorch is not just a Deep Learning framework. The creators had two goals with PyTorch:
最后! 我们很高兴您提出要求。 令人惊讶的是,PyTorch 不仅是深度学习框架。 创作者在PyTorch中有两个目标:
- A replacement for NumPy. NumPy的替代品。
- A deep learning platform that provides maximum flexibility and speed. 提供最大灵活性和速度的深度学习平台。
Let’s start with the first one.
让我们从第一个开始。
NumPy和PyTorch (NumPy and PyTorch)
We’re all familiar with NumPy and take it for granted because it’s one of the things that just happen to be there somehow in every Machine Learning program???
我们都熟悉NumPy并认为这是理所当然的,因为它是每个机器学习程序中碰巧存在的东西之一?
Well, the reason is that in Machine Learning or Deep Learning, we work with multidimensional arrays. For example, an image is often represented as an array of (height, width, number of color channels). So, for a grayscale (no color) image, we’d represent it as an array of shape (height, width, 1). Similarly, for a color image that would change to (height, width, 3). This is all very standard. It’s also standard to use NumPy to initialize these arrays. In scientific computing, these multidimensional arrays are called ‘Tensors’. I mean, it’s just neat because now instead of calling an image a multidimensional array, I can just call it a tensor.
好吧,原因是在机器学习或深度学习中 ,我们使用多维数组。 例如,图像通常表示为(高度,宽度,颜色通道数)的阵列。 因此,对于灰度(无彩色)图像,我们将其表示为形状数组(高度,宽度,1)。 类似地,对于将更改为(高度,宽度,3)的彩色图像。 这都是非常标准的。 使用NumPy初始化这些数组也是标准的。 在科学计算中,这些多维阵列称为“张量”。 我的意思是,这很简单,因为现在我可以将其称为张量,而不是将图像称为多维数组。
It goes something like this, a scalar (a single number) has zero dimensions, a vector has one dimension, a matrix has two dimensions and a tensor has three or more dimensions. That’s it!
这样,标量(单个数字)的维数为零,向量的维数为一,矩阵的维数为2,张量的维数为3或更多。 而已!

However, there’s a catch when you use NumPy arrays for computations. You cannot directly leverage the power of GPUs. PyTorch on the other end provides a framework to define tensors with direct GPU compatibility. So basically, PyTorch tensors are similar to NumPy’s arrays, with the addition being that PyTorch tensors can also be used on a GPU to accelerate computing. This is clearly an advantage over NumPy since Deep Learning heavily relies on GPU based model training.
但是,当您使用NumPy数组进行计算时会遇到麻烦。 您无法直接利用GPU的功能。 另一端的PyTorch提供了一个框架来定义具有直接GPU兼容性的张量 。 因此,基本上,PyTorch张量类似于NumPy的数组,此外,PyTorch张量也可以在GPU上使用以加速计算。 这显然比NumPy更具优势,因为深度学习很大程度上依赖于基于GPU的模型训练。
好的,很好。 但是,如何定义PyTorch张量? (Okay okay, that’s great. But how do I define a PyTorch tensor?)
Right. Syntactically, defining a tensor in PyTorch is a breeze. But first, let us install the PyTorch library.
对。 从语法上讲,在PyTorch中定义张量很容易。 但首先,让我们安装PyTorch库。
# Python 3.x
pip3 install torch torchvision
# Python 2.x`
pip install torch torchvision
# Anaconda
conda install pytorch torchvision -c pytorchNow, let us construct a randomly initialized tensor:
现在,让我们构造一个随机初始化的张量:
import torch
x = torch.rand(5, 3)
print(x)Out:
出:
tensor([[0.7799, 0.1989, 0.5753],
[0.4624, 0.5366, 0.7436],
[0.8719, 0.9631, 0.3204],
[0.8461, 0.0422, 0.3457],
[0.9910, 0.8967, 0.5962]])Now, to construct a tensor filled zeros and of dtype long:
现在,构造一个填充零且dtype长的张量:
x = torch.zeros(5, 3, dtype=torch.long)
print(x)Out:
出:
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])That’s how simple it is! Just like NumPy! In fact, you can use standard NumPy-like indexing on these tensors too!
就是这么简单! 就像NumPy! 实际上,您也可以在这些张量上使用类似NumPy的标准索引!
print(x[:, 1])Out:
出:
tensor([0.1989, 0.5366, 0.9631, 0.0422, 0.8967])The syntax for addition remains exactly the same as for NumPy. For multiplication, we can use the torch.matmul(x, y) and for division, torch.div(x, y) where x and y are PyTorch tensors.
加法的语法与NumPy完全相同。 对于乘法,我们可以使用torch.matmul(x,y),对于除法,可以使用torch.div(x,y),其中x和y是PyTorch张量。
嘿! 你知道吗? 这很酷。 但是,当我对NumPy已经很满意时,为什么还要采用PyTorch? (Hey! You know what? That’s cool. But why should I adopt PyTorch when I’m already so comfortable with NumPy?)
Ah! See that’s the thing. PyTorch is not expecting that you migrate over to PyTorch leaving NumPy. In fact, NumPy arrays and PyTorch tensors are interconvertible!
啊! 看到就是这样。 PyTorch不希望您迁移到PyTorch并离开NumPy。 实际上,NumPy数组和PyTorch张量是可互换的!
We use the from_numpy() method!
我们使用from_numpy()方法!
import numpy as np
# define a NumPy array
a = np.ones(5)
# convert into pyTorch tensor
b = torch.from_numpy(a)
# change the NumPy array
np.add(a, 1, out=a)
print(a)
print(b)Out:
出:
[2. 2. 2. 2. 2.]
tensor([2., 2., 2., 2., 2.], dtype=torch.float64)Notice how changing the NumPy array changed the PyTorch Tensor automatically!
请注意,更改NumPy数组是如何自动更改PyTorch Tensor的!
We’ve mentioned earlier that the entire power of PyTorch over NumPy lies in able to leverage GPU acceleration. But what is the syntax for it?
前面我们已经提到,PyTorch优于NumPy的全部功能在于能够利用GPU加速。 但是它的语法是什么?
So let’s say we’ve got NumPy arrays and access to a GPU and would like to speed up our computations using PyTorch,
假设我们拥有NumPy数组并可以访问GPU,并希望使用PyTorch加快计算速度,
Here’s how we go about it:
这是我们的处理方法:
import torch
# check if a GPU device is available. If not, use the CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# The data is in NumPy arrays x and y, but we need to transform them into PyTorch's Tensors to leverage GPU speed.
# So we convert them using earlier syntax and then we send them to the chosen device
x_tensor = torch.from_numpy(x).to(device)
y_tensor = torch.from_numpy(y).to(device)Simple as that!
就那么简单!
对于GPU,PyTorch似乎是一个不错的选择。 但是,如果我没有一个怎么办? 那我为什么要使用PyTorch? (PyTorch seems a good choice for a GPU. But what if I don’t have one? Why should I use PyTorch then?)
That’s a very valid question. So let us throw some speed tests your way.
这是一个非常有效的问题。 因此,让我们以您的方式进行一些速度测试。
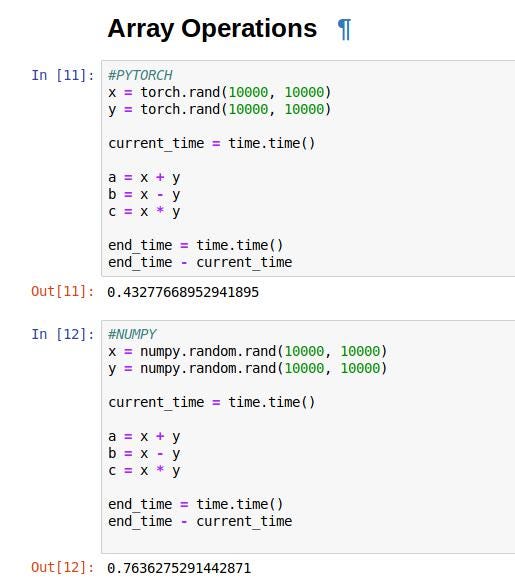
Clearly, PyTorch is faster than NumPy in basic mathematical operations. This is because of the faster array element access that PyTorch provides.
显然,在基本的数学运算中,PyTorch比NumPy更快。 这是因为PyTorch提供了更快的数组元素访问。
Let’s go for one more speed test. We’ll take a one-dimensional vector having size 10 billion random elements. And, try to access the middle element from both NumPy, as well as PyTorch.
让我们再进行一次速度测试。 我们将采用一维向量,其大小为100亿个随机元素。 并且,尝试从NumPy和PyTorch中访问中间元素。
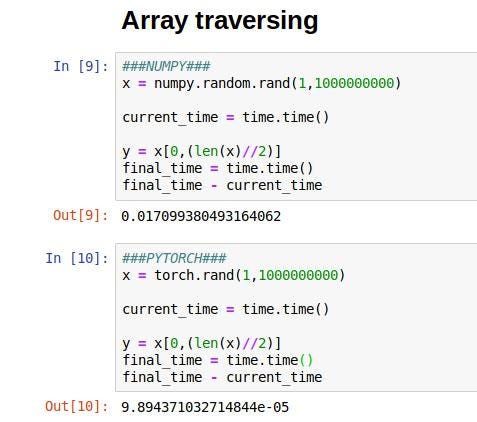
The result is decisive, PyTorch is clearly a winner in array traversing. It took about 0.00009843 seconds in PyTorch, while over 0.01 seconds for NumPy!
结果是决定性的,PyTorch显然是数组遍历的赢家。 在PyTorch中花费了大约0.00009843秒 ,而在NumPy 中花费了超过0.01秒 !
So should you completely ditch NumPy and use PyTorch everywhere? Not just yet. If you’re using TensorFlow, you’re probably better off using NumPy to avoid compatibility issues but if you’re using PyTorch to build your models, we highly recommend using PyTorch instead of NumPy.
那么,您应该完全放弃NumPy并在任何地方使用PyTorch吗? 不仅如此 如果您使用TensorFlow,最好使用NumPy以避免兼容性问题, 但是如果您使用PyTorch构建模型,我们强烈建议您使用PyTorch而不是NumPy。
哈! 也许我会同时使用它们,并在需要时将它们彼此转换! (Ha! Maybe I’ll just use both and convert them into each other as and when required!)
While that’s a very possible thing to do, we recommend against such a practice because interconversion between these two data types is both computationally heavy, and complex. And it is best to avoid doing so.
尽管这是很可能的事情,但我们建议您不要采用这种做法,因为这两种数据类型之间的相互转换在计算上既繁琐又复杂。 最好避免这样做。
So we talked about NumPy vs PyTorch with its basic syntax and compared the two on a variety of factors before coming to a conclusion. Now let’s move on and talk about why PyTorch has so rapidly gained popularity among the research community!
因此,我们在讨论NumPy vs PyTorch的基本语法之前,先对各种因素进行了比较,然后得出了结论。 现在,让我们继续讨论为什么PyTorch如此Swift地在研究界中流行起来!
PyTorch作为深度学习框架 (PyTorch as a Deep Learning Framework)
PyTorch differentiates itself from other machine learning frameworks in that it does not use static computational graphs — defined once, ahead of time — like TensorFlow, Caffe2, or MXNet. Instead, PyTorch computation graphs are dynamic and defined by a run.
PyTorch与其他机器学习框架的不同之处在于,它不使用静态计算图(如TensorFlow,Caffe2或MXNet)提前定义一次。 相反,PyTorch计算图是动态的 , 由run定义 。
Woah Woah Woah! There’s too much happening! What does any of this even mean???
哇哇哇! 发生了太多事! 这什至是什么意思???
Alright. Let’s go over it nice and slow.
好的。 让我们慢慢来看看它。
动态图与静态图 (Dynamic vs Static Graphs)
Generally, in the majority of programming environments, adding two variables x and y representing numbers produces a value containing the result of that addition.
通常,在大多数编程环境中,将代表数字的两个变量x和y相加会产生一个包含该相加结果的值。
For example, in standard Python:
例如,在标准Python中:
x = 4
y = 2
x + yOut:
出:
6However, this is not the case in a static graph environment like TensorFlow. In TensorFlow, x and y would not be numbers directly, but would instead be handles to graph nodes representing those values, rather than explicitly containing them. Furthermore, and more importantly, adding x and y would not produce the value of the sum of these numbers, but would instead be a handle to a computation graph, which, only when executed, produces that value:
但是,在诸如TensorFlow的静态图环境中却不是这种情况。 在TensorFlow中,x和y不会直接是数字,而是会处理代表这些值的图形节点,而不是显式包含它们。 而且,更重要的是,将x和y相加不会产生这些数字之和的值,而是将其作为计算图的句柄,仅在执行时才会产生该值:
import tensorflow as tf
x = tf.constant(4)
y = tf.constant(2)
x + yOut:
出:
<tf.Tensor 'add:0' shape=() dtype=int32>As such, when we write TensorFlow code, we are in fact not programming, but metaprogramming — we write a program (our code) that creates a program (the TensorFlow computation graph). Naturally, the first programming model is much simpler than the second. It is much simpler to speak and think in terms of things that are than speak and think in terms of things that represent things that are.
因此,当我们编写TensorFlow代码时,实际上我们不是在编程,而是在元编程 -我们编写了一个程序(我们的代码)来创建程序(TensorFlow计算图)。 自然,第一种编程模型比第二种简单得多。 说话和思考要比表示存在的事物简单得多。
PyTorch’s major advantage is that its execution model is much closer to the former than the latter. At its core, PyTorch is simply regular Python, with support for Tensor computation like NumPy, but with added GPU acceleration of Tensor operations as we’ve seen above.
PyTorch的主要优势在于其执行模型比后者更接近前者。 PyTorch的核心只是普通的Python,支持Tensor计算(如NumPy),但如上所述,它又增加了Tensor操作的GPU加速。
One of the many reasons for PyTorch gaining popularity is because, going back to the simple showcase above, we can see that programming in PyTorch resembles the natural “feeling” of Python:
PyTorch受欢迎的许多原因之一是因为,回到上面的简单展示,我们可以看到PyTorch中的编程类似于Python的自然“感觉”:
import torch
x = torch.ones(1) * 4
y = torch.ones(1) * 2
x + yOut:
出:
6
[torch.FloatTensor of size 1]The choice of using static or dynamic computation graphs severely impacts the ease of programming. The aspect it influences most severely is the control flow.
使用静态或动态计算图的选择严重影响了编程的难易程度。 它影响最大的方面是控制流程 。
In a static graph environment, control flow must be represented as specialized nodes in the graph. For example, to enable branching, TensorFlow has a tf.cond() operation, which takes three subgraphs as input: a condition subgraph and two subgraphs for the if and else branches of the conditional. Similarly, loops must be represented in TensorFlow graphs as tf.while() operations, taking a condition and body subgraph as input. In a dynamic graph setting, all this is simplified. Since graphs are traced from Python code as it appears during each evaluation, control flow can be implemented natively in the language, using if clauses and while loops as you would for any other program.
在静态图环境中,控制流必须表示为图中的专用节点。 例如,要启用分支,TensorFlow会执行tf.cond()操作,该操作将三个子图作为输入:条件子图和条件子条件if和else分支的两个子图。 类似地,循环必须在TensorFlow图中表示为tf.while()操作,并以条件和主体子图为输入。 在动态图形设置中,所有这些都得到了简化。 由于图形是从每次评估时显示的 Python代码中追踪而来的,因此可以像其他任何程序一样使用if子句和while循环以本地语言实现控制流。
This turns awkward and unintuitive TensorFlow code:
这将使笨拙且不直观的TensorFlow代码变成:
import tensorflow as tf
x = tf.constant(2)
y = tf.constant(3)
w = tf.while_loop(
lambda x: tf.matmul(x, y) < 10,
lambda x: tf.square(x), [x])
into natural and intuitive PyTorch code:
import torch.nn
x = torch.tensor([2])
y = torch.tensor([3])
while x.sum() < 100:
x = torch.square(x)The benefits of dynamic graphs from an ease-of-programming perspective reach far beyond this, of course. Simply being able to inspect intermediate values (like values being passed in and out of complex architecture model layers) with simple Python print statements (as opposed to tf.Print() nodes for TensorFlow) or a debugger is a big plus because computation graph in PyTorch is defined at runtime you can use our favorite Python debugging tools such as pdb, ipdb, PyCharm debugger. This is not the case with TensorFlow. At this stage, it is quite clear why a researcher would be inclined towards using PyTorch rather than TensorFlow!
当然,从易于编程的角度来看,动态图的好处远远不止于此。 只需能够使用简单的Python打印语句(与TensorFlow的tf.Print()节点相对)或调试器来检查中间值(例如,将值传入和传出复杂的体系结构模型层)是一个很大的优势,因为PyTorch是在运行时定义的,您可以使用我们最喜欢的Python调试工具,例如pdb,ipdb,PyCharm调试器。 TensorFlow并非如此。 在这个阶段,很明显为什么研究人员倾向于使用PyTorch而不是TensorFlow!
好的,我已经开始理解为什么PyTorch在研究界变得越来越流行,但是PyTorch的所有方式都不同于TensorFlow吗? (Okay, I have begun to understand why PyTorch is gaining popularity with the research community but is that all the ways in which PyTorch is different from TensorFlow?)
As a matter of fact, the answer is no. Apart from this, there are several other major differences when it comes to PyTorch than a framework like TensorFlow like in visualization support, pipelining support, deployment support, etc! But that’s nothing to worry about because we’ll go all of it in detail in the forthcoming blogs with the next blog being on how to define and train a Deep Neural Network with PyTorch!
事实上,答案是否定的。 除此之外,在PyTorch方面还有其他一些主要区别,除了TensorFlow之类的框架外,还包括可视化支持,管道支持,部署支持等! 但这没什么好担心的,因为我们将在即将发布的博客中详细介绍所有这些,而下一个博客将介绍如何使用PyTorch定义和训练深度神经网络!
We hope this has served as a basic introduction to PyTorch with the emphasis being on why the readers should invest time in PyTorch and the reason why it is gaining popularity with researchers around the world!
我们希望这是对PyTorch的基本介绍,重点在于读者为什么要花时间在PyTorch上以及为什么它在世界各地的研究人员中越来越受欢迎 !
希望您喜欢它,我们将在下一个博客中看到您! (I hope that you liked it and we’ll see ya in the next blog!)
Originally published at https://blog.eduonix.com on May 14, 2020
最初于 2020 年 5月14日发布在 https://blog.eduonix.com
翻译自: https://medium.com/eduonix/pytorch-the-dark-horse-of-deep-learning-frameworks-part-1-7dfab51c3f2c
深度学习框架pytorch















 4286
4286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









