






爬取某度某吧?高通过率百度旋转验证码逆向实现
声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在联系作者立即删除!
数据爬取
热门吧爬取
热门吧爬取分析
首先是进入网站的首页 看到热门吧
点击跳转热门吧页面,查看请求信息
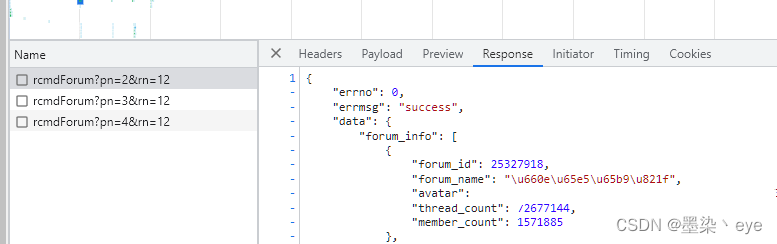
复制到postman之后,修改rn参数 发现所有的数据都回来了!!!那么就很简单了开始写代码!!
sprider 引擎
class HotTiebaSpider(scrapy.Spider):
name = 'hotTieba'
allowed_domains = DOMAINS
start_urls = HOT_TIEBA_URL
def __init__(self, mongo_uri, mongo_db, mongo_user, mongo_passwd):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.user = mongo_user
self.passwd = mongo_passwd
self.client = pymongo.MongoClient(self.mongo_uri, username=self.user, password=self.passwd)
self.db = self.client[self.mongo_db]
# 从setting.py中读取数据库连接信息
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_user=crawler.settings.get('MONGO_USER'),
mongo_passwd=crawler.settings.get('MONGO_PASSWORD')
)
def start_requests(self):
self.db[HOT_TIEBA].drop()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
for url in self.start_urls:
yield scrapy.Request(url=url, headers=headers)
def parse(self, response):
crawl_time = datetime.now()
response_json = json.loads(response.body)
if response_json['errno'] == 0:
data = response_json['data']
for forum_info in data['forum_info']:
forum_info['crawl_time'] = crawl_time
yield HotTiebaSpiderItem(forum_info)
hotTiebaItem
class HotTiebaSpiderItem(scrapy.Item):
forum_id = scrapy.Field()
forum_name = scrapy.Field()
avatar = scrapy.Field()
thread_count = scrapy.Field()
member_count = scrapy.Field()
crawl_time = scrapy.Field()
pipeline
class TiebaspiderPipeline(object):
def __init__(self, mongo_uri, mongo_db, mongo_user, mongo_passwd):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.user = mongo_user
self.passwd = mongo_passwd
self.client = pymongo.MongoClient(self.mongo_uri, username=self.user, password=self.passwd)
self.db = self.client[self.mongo_db]
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_user=crawler.settings.get('MONGO_USER'),
mongo_passwd=crawler.settings.get('MONGO_PASSWORD')
)
def open_spider(self, spider):
pass
def process_item(self, item, spider):
# 保存数据到MongoDB数据库
if isinstance(item, HotTiebaSpiderItem):
self.db[HOT_TIEBA].insert_one(dict(item))
elif isinstance(item, TiebaMessageSpiderItem):
self.db[TIEBA_MASSAGE].insert_one(dict(item))
return item
def close_spider(self, spider):
self.client.close()
启动脚本
import os
if __name__ == '__main__':
os.system("scrapy crawl hotTieba")
贴文爬取
贴文爬取分析
每个吧的请求都是:url+f?kw=吧,然后打开浏览器查看需要的html信息,找到自己想要的信息,xpath处理之后就得到想要的贴文了,
但是需要注意,直接请求的话,返回的信息都是在注释中的。
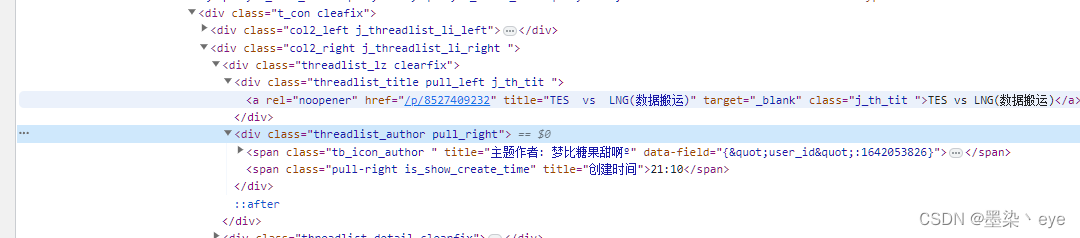
分析完毕,开始写代码!!!
TiebaMessageSpider 引擎
def get_message_result(crawl_time, top_li, is_top, tieba_name):
if len(top_li.xpath(".//div[contains(@class ,'mediago-ad')]")) > 0:
return {}
title_a = top_li.xpath(".//div[contains(@class ,'hreadlist_title')]/a")
message_href = title_a.xpath("./@href").extract()[0]
message_title = title_a.xpath("./@title").extract()[0]
author_a = top_li.xpath(".//div[contains(@class ,'threadlist_author')]//span[@class='frs-author-name-wrap']/a")
author_href = author_a.xpath("./@href").extract()[0]
author_data_field = author_a.xpath("./@data-field").extract()[0]
author_json = json.loads(author_data_field)
user_id = author_json['id']
user_un = author_json['un']
return {
"message_href": message_href,
"message_title": message_title,
"author_href": author_href,
"user_id": user_id,
"user_un": user_un,
"is_top": is_top,
"tieba_name": tieba_name,
"crawl_time": crawl_time
}
class TiebaMessageSpider(scrapy.Spider):
name = "message"
allowed_domains = DOMAINS
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
def __init__(self, mongo_uri, mongo_db, mongo_user, mongo_passwd):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.user = mongo_user
self.passwd = mongo_passwd
self.client = pymongo.MongoClient(self.mongo_uri, username=self.user, password=self.passwd)
self.db = self.client[self.mongo_db]
hotTiebas = self.db[HOT_TIEBA]
params = []
for hotTieba in hotTiebas.find():
param = {
"kw": hotTieba['forum_name'],
"ie": "utf8",
"pn": 0
}
params.append(param)
self.params = params
self.start_url =START_URL
self.client.close()
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'),
mongo_user=crawler.settings.get('MONGO_USER'),
mongo_passwd=crawler.settings.get('MONGO_PASSWORD')
)
def start_requests(self):
for param in self.params:
param_encode = urlencode(param)
url = self.start_url + param_encode
yield scrapy.Request(url=url, headers=self.headers, meta=param)
def parse(self, response):
params = response.request.meta
kw = params['kw']
print('kw: ', kw)
crawl_time = datetime.utcnow()
results = response.xpath("//code[@id='pagelet_html_frs-list/pagelet/thread_list']").extract()
if len(results) == 0:
results = response.xpath("//div[@id='pagelet_frs-list/pagelet/thread_list']").extract()
if len(results) == 0:
results = response.xpath("//div[@id='content_wrap']").extract()
for result in results:
replace_result = result.replace("<!--\n\n", '').replace(
"\n-->", '')
result_selector = Selector(text=replace_result)
top_lis = result_selector.xpath("//ul[@id='thread_top_list']/li")
for top_li in top_lis:
yield TiebaMessageSpiderItem(get_message_result(crawl_time, top_li, 1, kw))
general_lis = result_selector.xpath("//ul[@id='thread_list']/li")
for general_li in general_lis:
print(general_li)
yield TiebaMessageSpiderItem(get_message_result(crawl_time, general_li, 0, kw))
Item
class TiebaMessageSpiderItem(scrapy.Item):
message_href = scrapy.Field()
message_title = scrapy.Field()
author_href = scrapy.Field()
user_id = scrapy.Field()
user_un = scrapy.Field()
is_top = scrapy.Field()
tieba_name = scrapy.Field()
crawl_time = scrapy.Field()
验证码校验
贴文爬取十分钟之后 就会开始旋转验证码校验 感谢大佬提供的模型 准确率还是很高的
模型链接:https://blog.csdn.net/qq_44749634/article/details/125914114
使用的是请求接口 完毕之后 通过selenium 得到返回的响应 传给scrapy中间件处理
禁用scrapy redict中间件
服务器检测到你有问题之后,会把你重定向到验证页面,所以我们需要自己去处理重定向请求
在setting.py中禁用重定向中间件 并使用我们自定义的下载中间件
DOWNLOADER_MIDDLEWARES = {
'tiebaspider.middlewares.TiebaspiderDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': None,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': None
}
验证码处理类
首先 打开页面 看一下加载请求
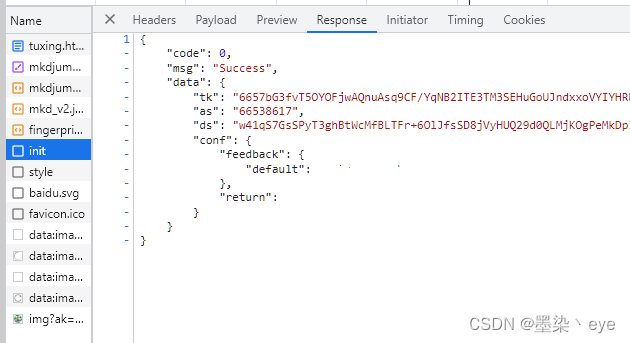
进入页面之后,发起了init请求,参数是ak 在跳转的url中可以得到参数ak ,响应得到tk 、as后面会用到
先来模拟下这个请求
def post_init(self):
params = {
"refer": self.refer,
"ak": self.ak,
"ver": 1,
"qrsign": ""
}
body = parse.urlencode(params)
headers = {
'Content-Type': self.URLENCODE_TYPE,
'Referer': self.refer,
'User-Agent': self.userAgent,
'Cookies': self.cookies
}
return self.session.post(url=self.INIT_URL, headers=headers, data=body)
之后发起style请求 参数是ak、tk 响应得到 backstr跟captchalist
"backstr": ""
"captchalist": [
{
"id": "spin-0",
"source": {
"back": {
"path": ""
}
},
"type": "spin"
}
模拟一下
def post_style(self):
headers = {
'Content-Type': self.URLENCODE_TYPE,
'Referer': self.DOMAINS,
'User-Agent': self.userAgent,
'Cookies': self.cookies
}
self.tk = self.beforeData['tk']
self.as_data = self.beforeData['as']
if self.backstr == '':
params = {
"refer": self.refer,
"ak": self.ak,
"tk": self.tk
}
else:
refresh = {"capId": "spin-0",
"backstr": self.backstr}
params = {
"refer": self.refer,
"ak": self.ak,
"tk": self.tk,
"isios": 0,
"type": 'spin',
"refresh": refresh,
"ver": 1
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Content-Type': self.URLENCODE_TYPE,
'Origin': self.DOMAINS,
'Referer': self.refer,
'User-Agent': self.userAgent,
'Cookies': self.cookies
}
body = parse.urlencode(flat_dict(params))
respose = self.session.post(url=self.STYLE_URL, headers=headers, data=body)
return respose
image接口获取图片
def post_image(self, respose):
style_data = respose.json()['data']
self.backstr = style_data['backstr']
headers = {
'Content-Type': self.URLENCODE_TYPE,
'Referer': self.DOMAINS,
'User-Agent': self.userAgent,
'Cookies': self.cookies
}
captcha = style_data['captchalist'][0]
element_source = captcha['source']
element_path = element_source['back']['path']
respose = self.session.get(url=element_path, headers=headers)
return respose
log接口是检验接口 as tk ak 在前面都可以得到 fs是加密后的验证信息。主要的校验值,只有acc_c 跟backstr 追踪一下log接口堆栈 很容易得到fs加密前的信息,除了这两个值 其他写死或置空都可以
加密很简单 第一次加密 首先使用as计算出一个新的key ,在利用这个key进行两次AES加密后就可以得到fs
返回值为ds 跟tk
之后进行二次校验c请求主要用作二次校验 使用log请求返回的ds跟tk,但是要注意,log,c请求不能跟之前求求在同一个session中请求,服务器会返回安全错误
模拟c接口与log接口
def post_log(self, png_path, respose):
with open(png_path, 'wb') as file:
file.write(respose.content)
image = Image.open(
png_path)
new_png_path = self.IMAGE_LOCAL_PATH + self.backstr[0:5] + '_new.png'
ocr = my_ocr()
image.save(new_png_path
) # 截取的验证码图片保存为新的文件
result = ocr.identification(
new_png_path)
e = round(int(result) / 360, 2)
mv_length = int(result) / 360 * (290 - 52)
print('预测旋转角度为:', result, '滑动距离为:', mv_length, '旋转百分比为', e)
self.updateFsJson(e)
fs = self.encrypt_data(key=self.as_data, rzData=self.fs_json, backstr=self.backstr)
params = {
"refer": self.refer,
"ak": self.ak,
"as": self.as_data,
"scene": '',
"tk": self.tk,
"ver": 1,
"fs": fs,
"cv": "submit",
"typeid": "spin-0",
"_": int(time.time()) * 1000
}
body = parse.urlencode(params)
returnData = request_log(body, self.backstr, self.refer)
return returnData
当返回的有url后就可以直接跳转了,这里我使用的是selenium,发送的请求,但是要保持所有的跳转都在一个session中,才能验证过去
def log_is_success(self, returnData):
result = None
print(returnData)
logdata = returnData['logdata']
beforeData = logdata['data']
backstr = returnData['backstr']
if 's' in beforeData.keys():
self.refer = beforeData['s']['url']
self.driver.get(beforeData['s']['url'])
# response = self.request_session.get(beforeData['s']['url'], allow_redirects=False)
url = self.driver.current_url
# url = response.headers.get('Location')
time.sleep(random.randint(5, 10))
if 'wappass' not in url:
print("成功", url)
status = 1
content = self.driver.page_source
# response = self.request_session.get(url, allow_redirects=False)
# content=response.content
result = content
self.current_url = url
else:
print("继续", url)
status = 2
ak_now = self.ak
matchObject = re.match(r'ak=(.*?)&', url, re.M | re.I)
if (matchObject):
ak_now = matchObject.group(1)
self.init(url, ak=ak_now, userAgent=self.userAgent, cookies=self.cookies, kw='看贴')
result = url
self.current_url = url
elif 'f' in self.beforeData.keys():
status = 3
print("安全风险")
else:
status = 0
self.beforeData = beforeData
self.backstr = backstr
return {"status": status, "result": result
}
TiebaspiderDownloaderMiddleware
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
newresponse = HtmlResponse(url=response.url, body=response.body, encoding='utf-8')
if response.status == 302 and 'wappass' in str(response.headers.get('Location'), 'utf-8'):
redirect_url = str(response.headers.get('Location'), 'utf-8')
refer = redirect_url
ak = ""
userAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
cookies = ''
matchObject = re.match(r'ak=(.*?)&', request.url, re.M | re.I)
if (matchObject):
ak = matchObject.group(1)
rotatingVerificationCode = RotatingVerificationCode(refer=refer, ak=ak, userAgent=userAgent,
cookies=cookies,
kw='看帖')
while True:
rotatingVerificationCode.open_session()
out = rotatingVerificationCode.request_verify()
redirect_url = rotatingVerificationCode.current_url
print('wappass' in redirect_url)
rotatingVerificationCode.close_session()
if 'wappass' not in redirect_url:
break
print(request.url)
newresponse = HtmlResponse(url=request.url, body=out, request=request, encoding='utf-8',
status=200)
return newresponse
总结
这个验证码逆向还是很简单的,稍微努努力就做完了,最后希望小伙伴们帮忙点赞关注加投币!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









