







web scraper 简介
- 一、什么是web scraper
web scraper是一款网站数据提取工具,类似于爬虫,但不需要像python爬虫那样编写代码,使用门槛较低,适用于轻度的数据爬取。web scraper主要以谷歌扩展插件的形式存在,开发者介绍的Cloud Scraper暂时没了解过。
以下是开发者给出的工具简介
Web site data extraction tool
Start web scraping in minutes. Use our free chrome extension or automate tasks with our Cloud Scraper. No software to download, no Python/php/JS needed.
-
二、如何安装web scraper
目前越来越多的浏览器开始适配扩展插件,但还是建议在谷歌浏览器上安装使用(需要科学上网)。在chrome网上应用店直接搜索web scraper,点击安装即可。
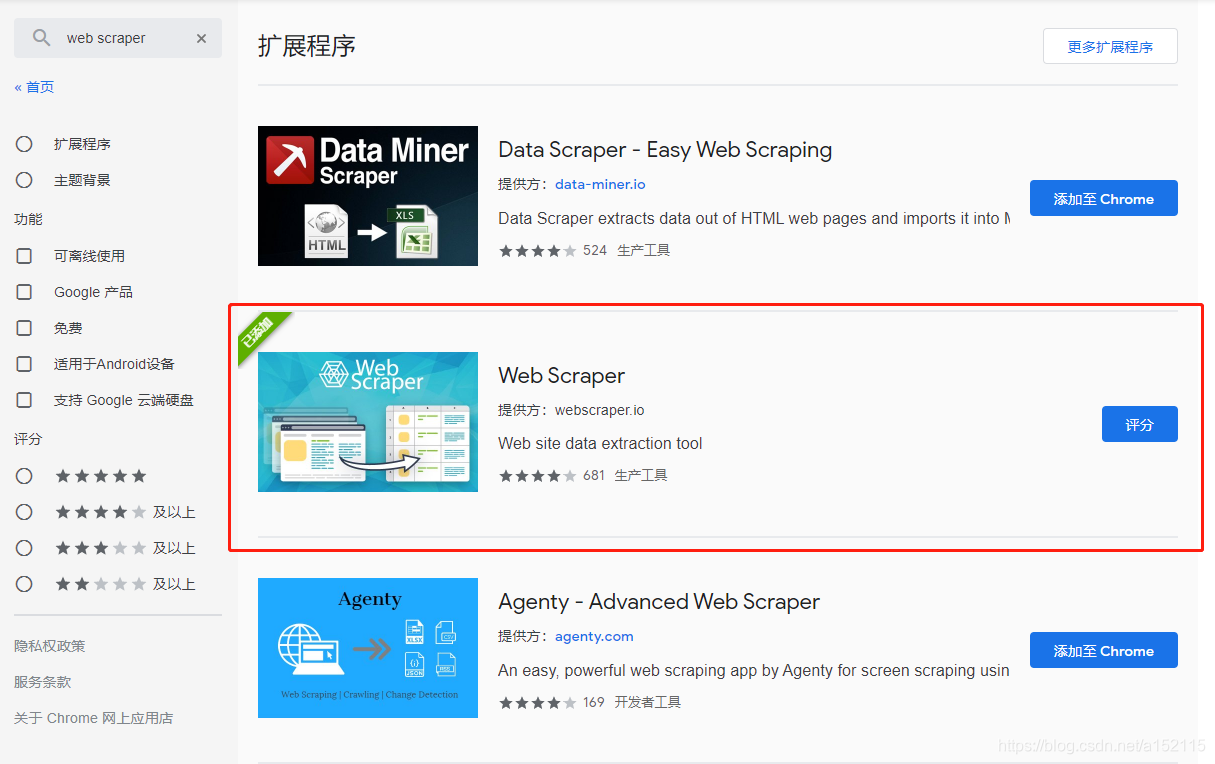
-
三、使用界面介绍
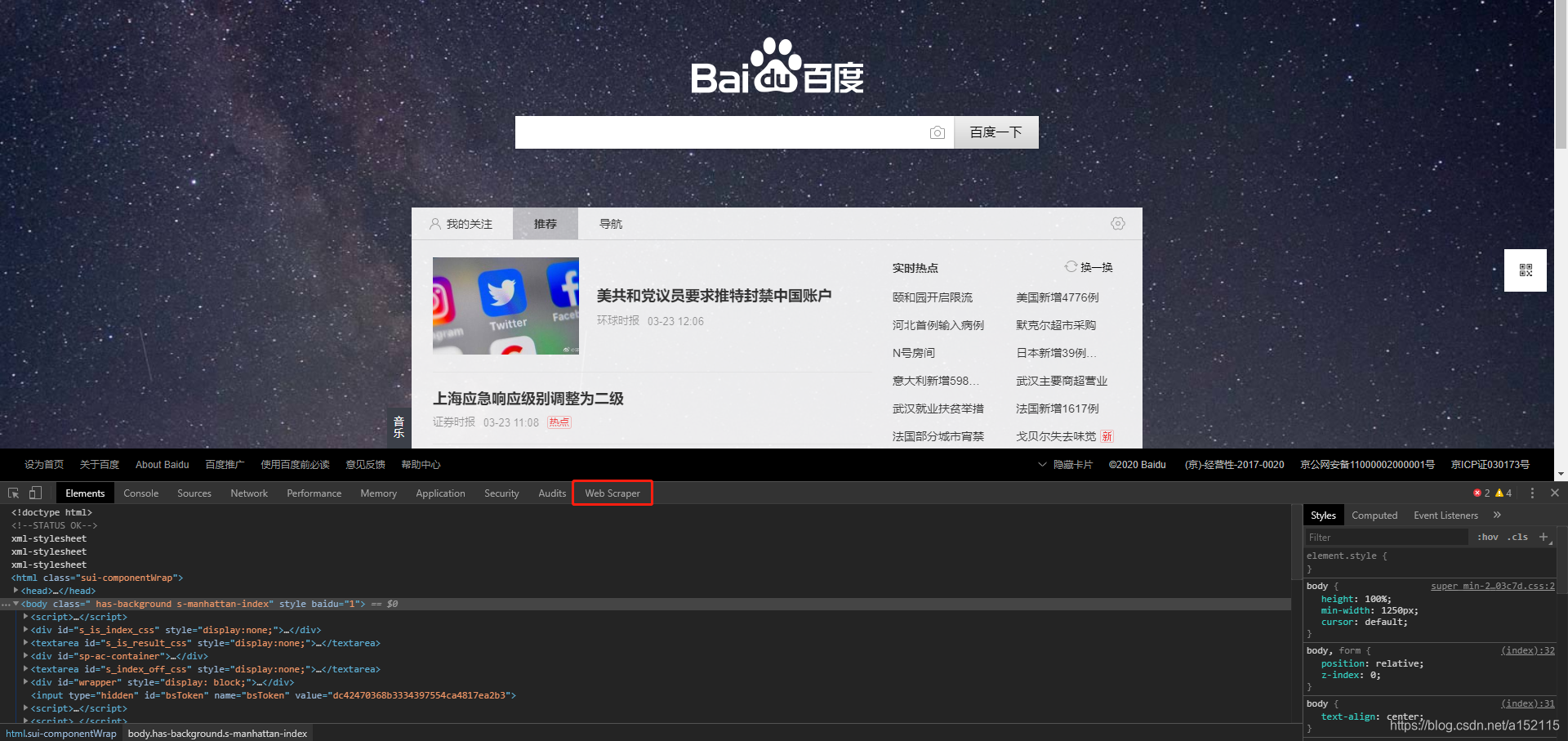
- 1.首先确认浏览器是否已经安装并启用,再按F12调出开发者工具界面,此时可以看到菜单栏多了一个web scraper。
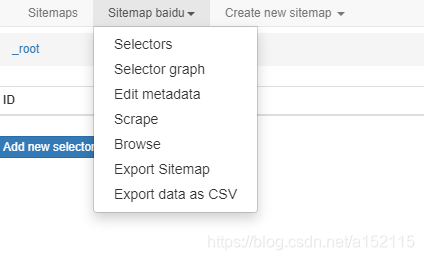
- 2.点击进入工具详细页面
菜单栏第一项Sitemaps主要记录已创建的sitemap(直译应该是网站预览)。第二项Sitemap主要是对现有sitemap的一些操作,如创建爬取节点、子节点以及执行爬取和导出任务都在这一项里进行。第三项Create new sitemap主要是新建和导入sitemap用。
- 1.首先确认浏览器是否已经安装并启用,再按F12调出开发者工具界面,此时可以看到菜单栏多了一个web scraper。
-
四、简单爬取下百度首页信息
- 1.爬取导航界面的网站名及地址。该工具有自动选择元素的功能,点击Select再在网页中选中想要获取的元素。由于采用树状结构更有利于数据的整理,所以我们先获取导航页面的所有元素,然后再依次获取我们想要的网站名及地址。
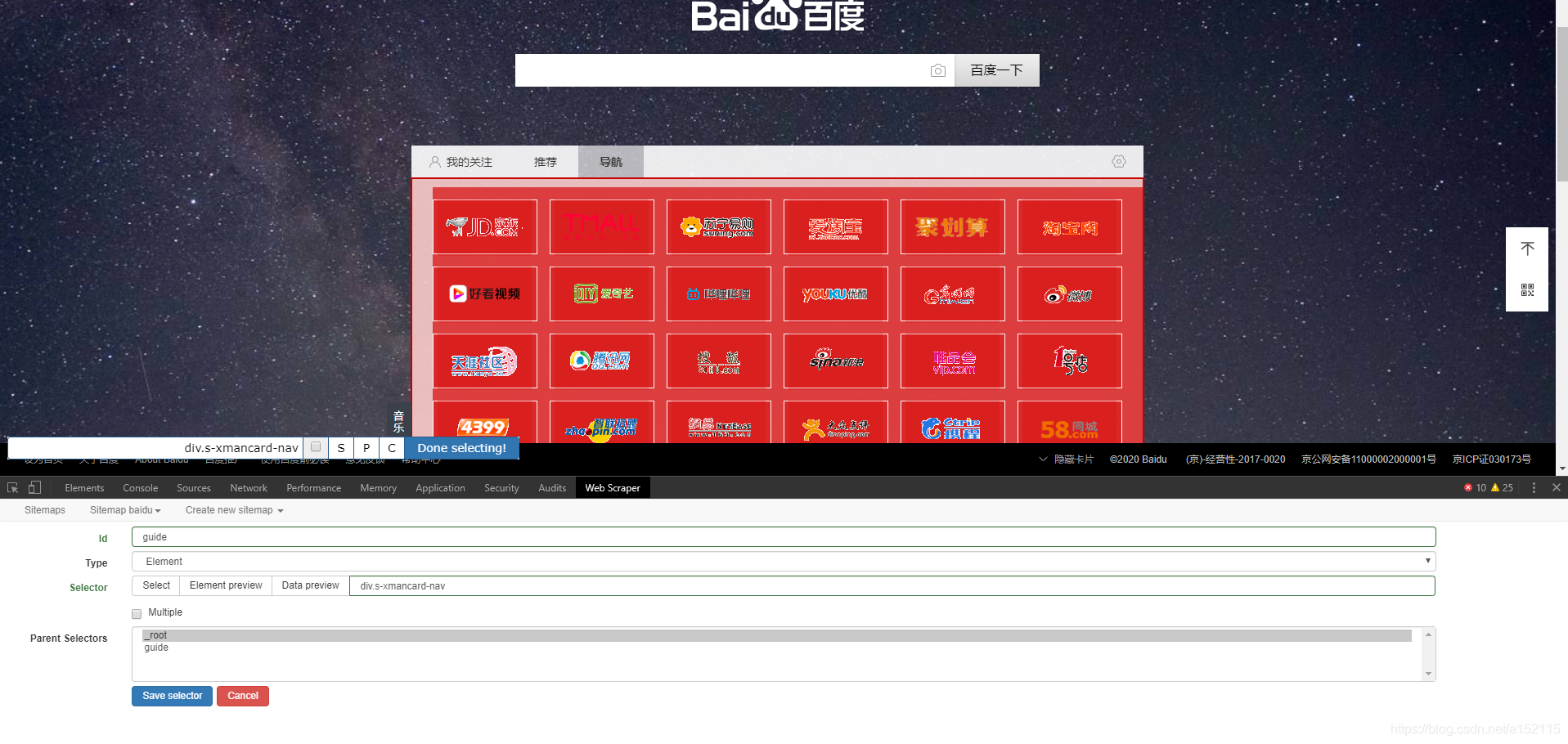
- 2.大致的爬取结构如下图。
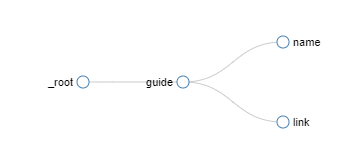
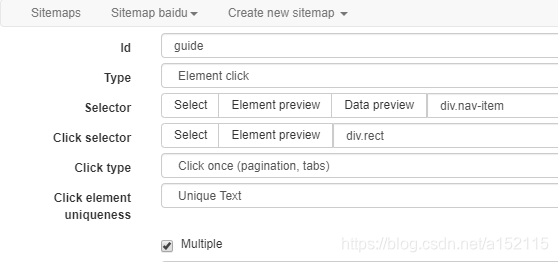
- 2.1 所有导航卡片爬取(由于进入页面时不会加载所有导航网站,所以type需要选取Element click,工具会模拟用户点击加载按钮来加载完全部界面)
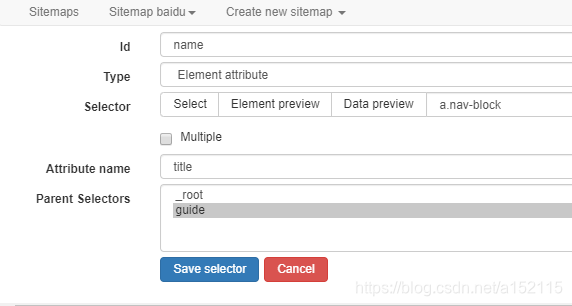
- 2.2 网站名爬取(注意此处不要勾选Multiple,因为前一级guide已经勾选Multiple,每一个导航卡片中只用爬取一次网站名,不然会因为数据条目不一致导致爬取失败)
- 2.3 网站链接爬取
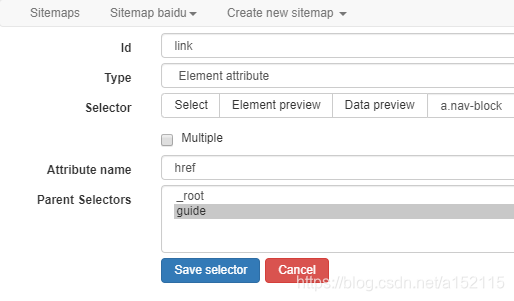
所有爬取节点的Selector可以自己根据网页结构输入,也可以点击Select后再在网页中想要爬取的元素自动生成。
- 2.1 所有导航卡片爬取(由于进入页面时不会加载所有导航网站,所以type需要选取Element click,工具会模拟用户点击加载按钮来加载完全部界面)
- 3.实施爬取并导出数据表格
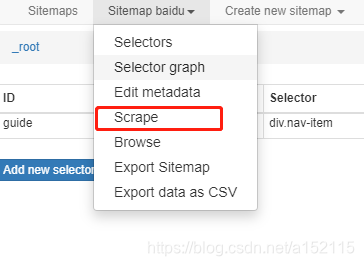
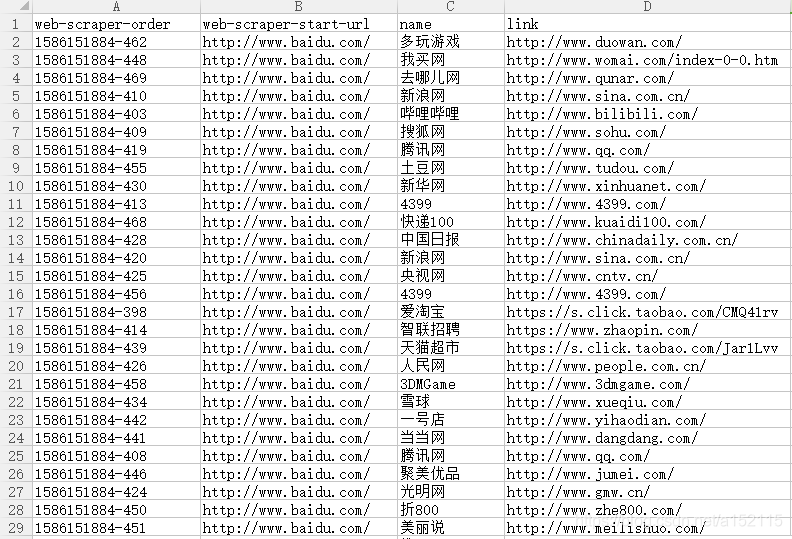
到这一次简单的爬取就结束了。
- 1.爬取导航界面的网站名及地址。该工具有自动选择元素的功能,点击Select再在网页中选中想要获取的元素。由于采用树状结构更有利于数据的整理,所以我们先获取导航页面的所有元素,然后再依次获取我们想要的网站名及地址。
-
五、总结
web scraper这款工具可以不用编写具体的爬虫代码实现数据爬取,但大体的爬取思路都是一样的。在一些简单的页面爬取上可以很直观的进行爬取,数据预览也十分方便。对于一些比较复杂的数据爬取上,对网页结构进行一定的分析后也能实现爬取。熟练使用后,可以十分便捷的实现直接在浏览器上爬取数据。

















 3592
3592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









