







目录
多线程编程可以提高系统的并发性和响应性,但也会带来一些风险和挑战。这就涉及到了一个非常重要的问题-线程安全(重点)
1.观察线程不安全
这是一段线程不安全的代码
public class Main {
private static int count = 0;//此处定义一个Int类型的变量
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
//对count变量进行自增5w次
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread t2 = new Thread(()->{
//对count进行自增5w次
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t2.start();
// t1.join();
// t2.join();
System.out.println("count: " + count);
}
}按照我们的逻辑来说,两个线程分别让count自增了5w次,那么最后打印出来的结果应该是10w次才对,此处如果没有 join() 那么最后的结果会是10w次吗?我们来看代码的结果:
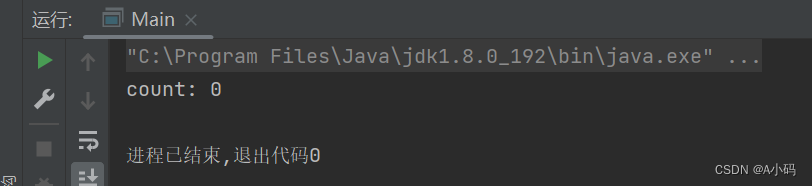
为什么答案是0?
当两个线程start的时候,此时start方法就分别去创建一个线程,然后这个线程去调用run方法(这里不赘述,详细请看博主之前的博客Thread类)这个过程需要一定时间,
但是由于主线程自上而下在运行,start方法后,就已经执行到对count的打印了,还没等到两个线程去完成count的自增,这个进程就结束了。
那么我们接下来让主线程等待两个线程完成了对count的自增,最后再打印count值,这个值会是10w吗?
第一次执行结果:
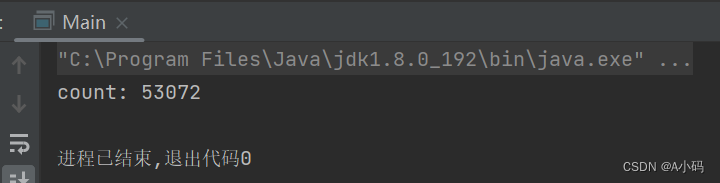
第二次执行结果:
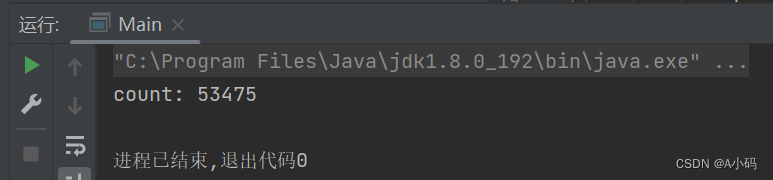
第三次执行结果:
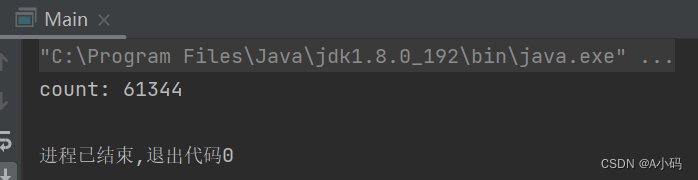
我们可以清晰看到三次执行的结果都不是我们预计中的10w次,明明我们预期结果是 10w,但是达不到预期,此时就可以认为程序出现了 BUG!
凡是实际结果与预期结果不同,都认为是出现了 BUG!
上述代码就是典型的线程安全问题,也可以称为线程不安全!
为什么会出现这样的问题?是多线程在捣鬼吗?如果我们不使用多线程会出现这样的问题吗?我们来看下面这简单的代码:
public class Main {
private static int count = 0;
public static void main(String[] args) {
for (int i = 0; i < 100000; i++) {
count++;
}
System.out.println("count: " + count);
}
}结果如下:
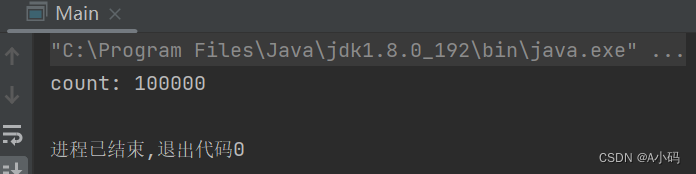
结果跟我们预计的一样,如此便可以得到结论:出现预计结果不一致的问题出在多线程身上!
那么为什么使用多线程会造成这样的问题呢?
答案便是:代码执行顺序的不确定性。
我们要知道多线程是同时执行多个线程的机制,每个线程独立执行,拥有自己的执行路径和执行状态。不同线程执行的速度和顺序是无法确定的,而且在多核处理器上,这些线程可能会同时并行执行。
当多个线程同时访问共享资源时,比如同一个变量或同一个文件,可能会出现竞争条件(Race Condition)。竞争条件可能会导致程序出现错误的结果或异常情况。
这样我们便可以进一步得出结论:
-
如果没有多线程,代码的执行顺序是固定的,代码执行顺序固定,程序的结果也就是固定的!
-
如果使用多线程,代码的执行顺序会出现更多的变数,执行顺序的可能性由于 CPU 的随机调度,可能出现了无数情况!
所以我们在使用多线程的时候,要解决执行顺序不确定的问题,确保每次执行的结果都正确!
而要解决这个问题,我们首先要理解 count++ 这个操作都做了什么?
count++这个自增操作看起来很不起眼,实际上在操作系统中,++这个操作是比较麻烦的事情,这个操作要分成三个步骤来完成:
-
先把内存中的值,读取到 CPU 寄存器中 (load)
-
把 CPU 寄存器的数值进行 +1 运算 (add)
-
把得到的结果写回到内存中 (save)
由于 CPU 是随机调度的,所以就可能出现以下的情况:
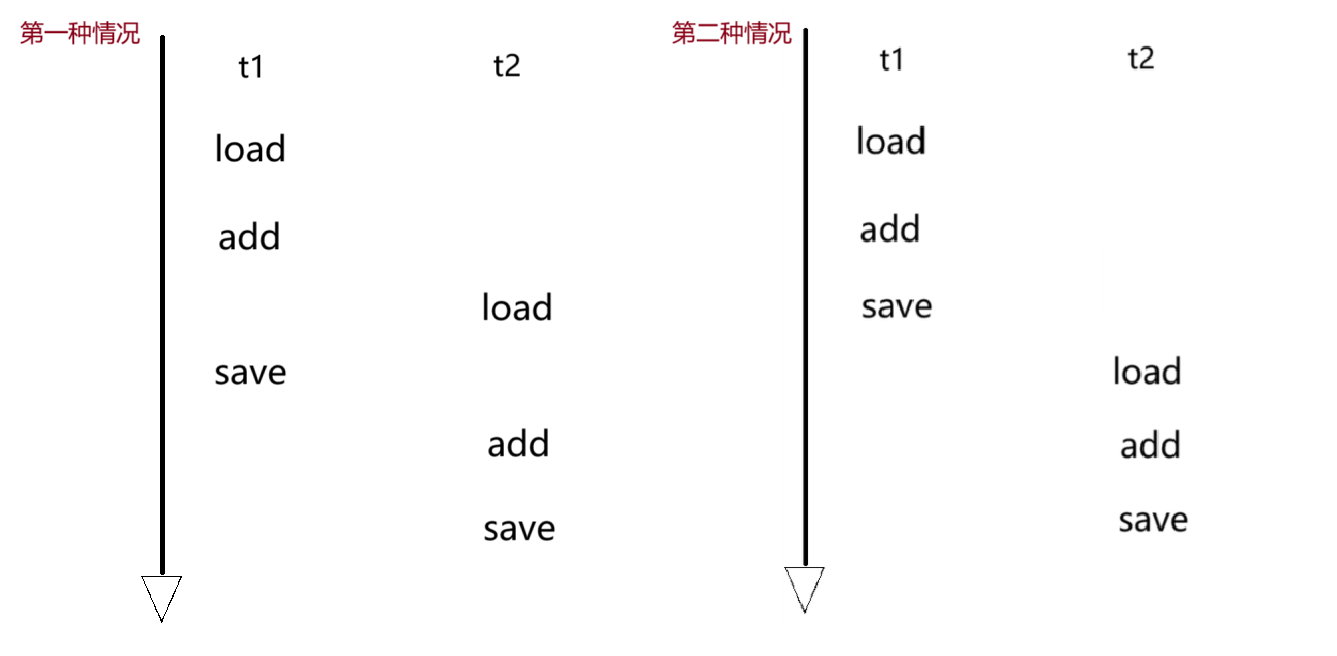
第一种情况:t1线程完成count的自增但是还没有把结果返回,此时t2线程就读取了count的值
这种情况造成两次提交的结果,count只加了一次!
像不像数据库中的“读脏数据”?(一个事务更新的数据尚未提交,被另一事务读到)
第二种情况:t1线程完成了自增并返回结果,t2线程再开始读数据,然后自增返回结果
这种情况就是正常的两次提交,count加了两次! 是跟我们的预期结果一致的情况!
所以这就是为什么上述代码每次打印的结果都不同了,那有没有可能刚好打印 10w 呢?也是有可能的!但是这个概率真的很低哈!!
我们已知造成上述代码结果与我们预期不一致的原因是因为线程调度是随机的!那么,线程不安全的原因还有哪些呢?我们接着往下看
2.线程不安全的原因
2.1 随机调度
线程调度是随机的,这是线程安全问题的罪魁祸首!
随机调度使一个程序在多线程环境下,执行顺序存在多种情况
程序猿必须保证 在任意执行顺序下,代码都能够正常的工作!
这个问题在上述 count++ 的例子中,已经体现了,这里就不再赘述
2.2 修改共享数据
也就是多个线程修改同一个变量
在我们上述的线程不安全代码中,我们使用了2个线程针对count变量进行修改
此时这个count是一个多个线程都能访问到的“共享数据”
为什么修改共享数据会使线程不安全呢?其实我们上面的线程不安全代码也体现了:
- 多个线程对共享数据进行修改时,它们的执行顺序是不确定的。(本质)
- 当多个线程同时对共享数据进行修改时,可能会导致数据的不一致性。
- 由于每个线程都有自己的缓存,可能会导致缓存中的数据与主存中的数据不一致。
2.3 原子性
什么是原子性呢?原子性是指一个操作是不可分割的,要么完整地执行,要么不执行。其实这个概念的提出是因为当时人们误以为原子是物质最小的单位,认为原子不可再拆分,不像我们如今还发现了中子、质子等更小的单位!
我们要注意,一条java语句不一定是原子的,也不一定只有一条指令!
比如我们上述代码中的 count++ ,其实是由三步操作组成的!
- 从内存把数据读取到CPU
- 进行数据更新
- 把数据写回到CPU
不保证原子性,可能会出现我们上述代码例子中,一个线程中的add、save、load三步操作与别的线程的三步操作乱序进行的结果!
2.4 内存可见性
一个线程对共享变量值的修改,能够及时地被其他线程看到,那么便不会出现问题,如果没有被及时发现,那么其他线程可能读到了一个修改之前的值,也会造成线程不安全
这也是前文所说的数据库中的“读脏数据”的感觉!
2.5 指令重排序
指令重排序其实就是编译器好心办坏事!为什么这么说呢?我们看下面的例子:
木兰辞都学过吧?其中有这么一小段:东市买骏马,西市买鞍鞯,南市买辔头,北市买长鞭。
于是木兰就去买东西了!她这样买东西:
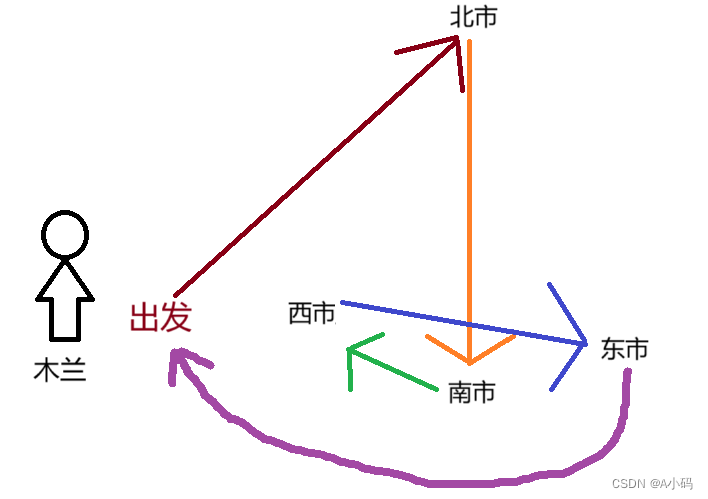
这样是不是很麻烦?东跑一下,西跑一下,木兰都不知道自己哪里去了,哪里没去,而且多走了没必要的路程,于是优化了一下购买顺序:
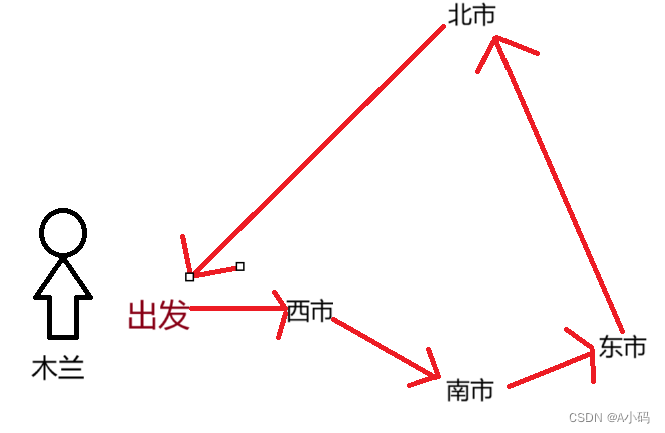
按照这样的顺序,木兰买东西的效率就高多了
指令重排序,就像上述一样,可以少走一些路,优化了效率。
编译器对于指令重排序的前提是 "保持逻辑不发生变化",对于单线程环境来讲,比较容易判断,但是在多线程的环境下就没那么容易了,多线程代码执行复杂程序更高,编译器很难在编译阶段对代码的执行结果进行预判,因此编译器激进的指令重排序很容易导致重排后的逻辑和之前不等价,就比如:木兰家要为木兰送行,临别吃顿丰盛的饭,要买好几样木兰喜欢吃的菜,于是木兰的弟弟就跟木兰去买东西,要买的东西多了,两个人就容易买重复或者少买了一些东西
3.synchronized 加锁操作
3.1 synchronized是什么?
synchronized是Java语言中的一个关键字,用于实现线程的同步。当一个方法或一个代码块被synchronized修饰时,只有一个线程可以进入该方法或代码块,其他线程需要等待,直到获得锁才能执行。这样可以保证多个线程在访问共享资源时的安全性,避免出现数据不一致或冲突的问题。
3.2 synchronized的特性
1) 互斥
synchronized 会起到互斥效果,某个线程执行到某个对象的synchronized中时,其他线程如果也执⾏到同⼀个对象的 synchronized ,就会阻塞等待.
- 进⼊ synchronized修饰的代码块,相当于加锁
- 退出 synchronized修饰的代码块,相当于解锁
比如说:学校的校花受很多人欢迎,结果有一天成了我的女朋友,那么在我没有和她分手之前,其他男生都不可以去追她
注意理解阻塞等待
针对每⼀把锁,操作系统内部都维护了⼀个等待队列.当这个锁被某个线程占有的时候,其他线程尝试进行加锁,就加不上了,就会阻塞等待,⼀直等到之前的线程解锁之后,由操作系统唤醒⼀个新的线程,再来获取到这个锁.
注意:
- 上⼀个线程解锁之后,下⼀个线程并不是立即就能获取到锁.而是要靠操作系统来"唤醒".这也是操作系统线程调度的⼀部分⼯作.(谁家刚分手就立马和人好上了,那是给绿了吧?)
- 假设有ABC三个线程,线程A先获取到锁,然后B尝试获取锁,然后C再尝试获取锁,此时B和C
都在阻塞队列中排队等待.但是当A释放锁之后,虽然B⽐C先来的,但是B不⼀定就能获取到锁,而是和C重新竞争,并不遵守先来后到的规则(有种东西叫做一见钟情,不是你追的久你就更有机会)
synchronized的底层是使用操作系统的mutex lock实现的
2) 可重入
synchronized同步块对同⼀条线程来说是可重⼊的,不会出现自己把自己锁死的问题;
什么是"把自己锁死"?
⼀个线程没有释放锁,或者又尝试再次加锁
//第⼀次加锁,加锁成功
lock();
//第⼆次加锁,锁已经被占用,阻塞等待.
lock();按照之前对于锁的设定,第⼆次加锁的时候,就会阻塞等待.直到第⼀次的锁被释放,才能获取到第⼆个锁.但是释放第⼀个锁也是由该线程来完成,结果这个线程已经躺平了,啥都不想干了,也就无法进行解锁操作.这时候就会死锁

这样的锁称为不可重⼊锁.
Java中的synchronized是可重⼊锁,因此没有上面的问题.
for (int i = 0; i < 50000; i++) {
synchronized (locker) {
synchronized (locker) {
count++;
}
}
}在可重⼊锁的内部,包含了"线程持有者"和"计数器"两个信息.
- 如果某个线程加锁的时候,发现锁已经被人占用,但是恰好占用的正是自己,那么仍然可以继续获取到锁,并让计数器自增.
- 解锁的时候计数器递减为0的时候,也就是才真正释放锁.(才能被别的线程获取到)
例如网红疯狂小杨哥之前的作品中,就有一个道具,超级无敌居多锁的铁箱!为了不让老弟玩电脑,老哥把主机锁进去了,然后加上了N把锁 ,这个时候老弟想要玩电脑,只能解完这N把锁,减为0的时候,才能拿到主机!感兴趣的可以看看该作品

3.3 synchronized使用示例
3.3.1 针对指定对象加锁
目录2中提到了造成线程不安全的5个原因,其中“随机调度”,线程抢占式执行,这个是操作系统内核规定的,我们无法更改,我们收拾不了随机调度,还收拾不了“修改共享数据”吗?我们可以不允许线程访问同一变量,但是这样就削弱了多线程优势了!既然“随机调度”收拾不了,“修改共享数据”又不好下手,那我们接着只能从“原子性”下手了,柿子还是得找软的捏!
通过原子性,我们可以解决指令不是原子性所造成的线程安全问题!
回顾目录3.1,当一个方法或一个代码块被synchronized修饰时,只有一个线程可以进入该方法或代码块,其他线程需要等待,直到获得锁才能执行。
也就是说:synchronized 关键字进行加锁,可以保证加锁的代码块是原子性的!
public class ThreadDemo {
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
Object object = new Object();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
synchronized (object) {
count++;
}
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
synchronized (object) {
count++;
}
}
});
t1.start();
t2.start();
// 下面的等待是为了让两个线程都自增完成
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
// 第一次执行打印结果:count = 100000
// 第二次执行打印结果:count = 100000
// 第三次执行打印结果:count = 100000上述代码针对 object 这个对象加锁,一个对象只有一把锁
当 t1 线程执行到 count++ 时就会尝试获取 object 的锁,如果获取到了,就进行加锁操作(尝试打开心上人的心房,进去后就上锁!) 并执行 count++,只有执行完 synchronized 代码块的内容后,才会自动释放锁(感情走到了终点,你会自动开锁,走出他的心房)
如果 t1 在执行 count++ 的过程中,t2也执行到 count++ 了,此时 t2 就会尝试获取 object 对象锁,但是 object 已经被 t1 加锁了,那么 t2 就只能阻塞等待了(狭路相逢勇者胜!已有对象请等待!),等 t1 释放锁,t2 才能获取锁,并加锁!那么 t1 只有执行完 synchronized 代码块后,自动释放锁!
synchronized 用的锁是JAVA对象头里的,可以粗略理解成每个对象在存储的时候,都有一块内存表示当前 "锁定" 状态
3.3.2 针对this加锁
在3.3.1中是针对object对象进行加锁,而这里可以针对this对象来进行加锁
public class Demo {
public int count = 0;
public void increment() {
synchronized (this) {
count++;
}
}
}this是对当前对象的引用,针对this对象来加锁,也就是针对当前对象进行加锁。
当我们调用increment方法时候,就需要一个Demo类型的对象来调用方法,谁调用了increment方法,谁就是这个this所引用的对象,也就是针对这个所引用的对象进行加锁
public static void main(String[] args) throws InterruptedException {
Demo d = new Demo();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
demo.increment();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
demo.increment();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(d.count);
}
// 打印结果:count = 100000此时通过 d 这个对象调用了 increment 方法,就是针对 d 这个对象加锁!
上述代码如果 t1 和 t2 线程都执行到了 d.increment() 里的 synchronized 代码块,此时就会发生锁竞争。当 t1 竞争到锁了,此时 t2 就需要阻塞等待,等到 t1 执行完 synchronized 代码块后释放锁了,t2 才能尝试获取锁。
注意:锁竞争,也叫锁冲突,只有在多个线程争同个锁时才会发生!
同时针对 this 加锁也可以写成如下所示:
public class Demo {
public int count = 0;
synchronized public void increment() {
count++;
}
}此时也是针对 this(当前对象) 加锁,只不过这里进入 increment 方法就会加锁,结束 increment 方法就会自动释放锁。
3.3.3 针对类对象加锁
类对象是什么?
类对象(Class Object)是指代表一个类的对象。在Java中,每个类都有一个对应的类对象,该类对象存储了类的信息,包括类的名称、属性、方法等。类对象可以通过反射来获取。
当我们针对静态方法加锁时,就是针对类对象加锁:
public class Demo {
synchronized public static void hello() {
System.out.println("hello world");
}
}此时也就是相当于针对 Demo.class 这个对象加锁!
3.3.4 疑难杂症
针对 synchronized 关键字 ,我们首先要记住这个单词,不能拼错,这个是最基本的!然后我们还要注意这个关键字是针对哪个对象加锁!
上面我们一共讲了3个针对不同对象的加锁:
- 针对指定对象加锁;
- 针对当前对象加锁;
- 针对类对象进行加锁
下面我创建一个demo类来举例:
例1:synchronized 修饰了 func1 和 func2 方法,如果 t1 线程正在执行 func1() 方法,此时就针对 d 这个类的实例化对象加锁了,如果此时 t2 想执行 func2() 就不行了!因为 d 已经被 t1 加锁了!
import static java.lang.Thread.sleep;
class demo{
synchronized public void func1() throws InterruptedException {
System.out.println("func1执行中");
System.out.println("停5秒,看func2是否执行");
sleep(5000);
System.out.println("5秒后");
}
synchronized public void func2() throws InterruptedException {
System.out.println("func2执行中");
sleep(1000);
}
}
public class Main {
public static void main(String[] args) throws InterruptedException {
demo d = new demo();
Thread t1 = new Thread(()->{
try {
d.func1();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread t2 = new Thread(()->{
try {
d.func2();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("执行完毕");
}
}上述代码中,demo类有两个被 synchronized 修饰的方法func1和func2,然后在主线程中创建了两个线程t1和t2,分别执行 func1方法 和 func2方法 ,我们看运行结果:
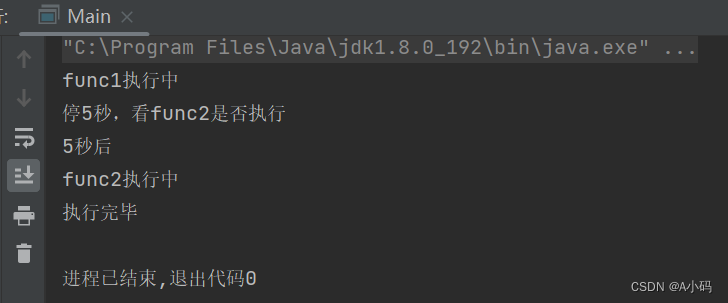
很明显,t1在执行 func1方法 时候,t2无法执行 func2方法!
上述代码中是否存在BUG了?
前面讲过了,线程安全问题最本质的原因是因为操作系统的随机调度,线程的抢占式执行,那么有没有一种可能,t2线程先t1一步,对 d 加锁了,导致t2先执行?
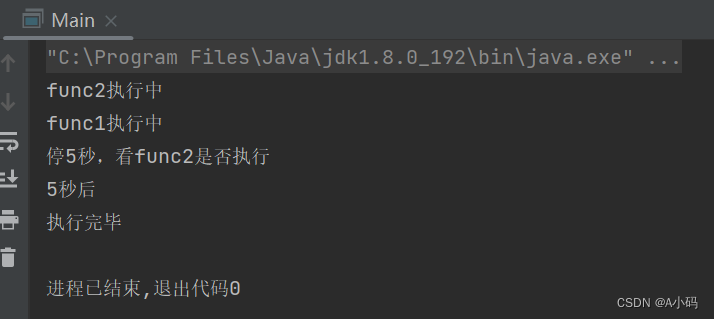
所以上述的代码是存在线程安全问题的!
例2:synchronized 修饰了 fun1 方法但是没有修饰 func2 方法,如果 t1 线程正在执行 func1(),此时 t2 仍然能执行 func2(),因为 func2 没有被 synchronized 修饰。
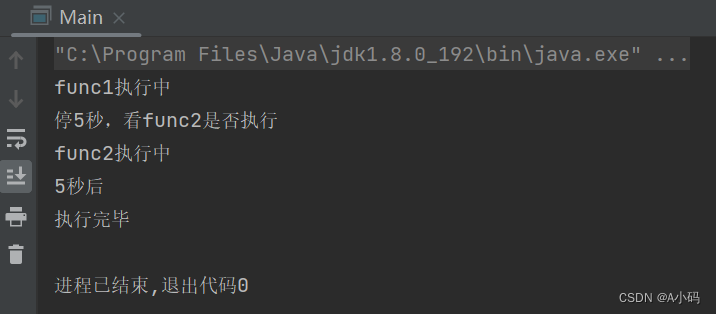
例3:synchronized 修饰了静态的 func1 方法,也修饰了普通的 func2 方法,如果 t1 线程正在执行 demo.func1(),此时 t2 能执行 d.func2 方法,因为是针对不同的对象加锁,t1 是针对 demo.class 类对象加锁,而 t2 是针对 d 实例化对象加锁。(例1和例2的方法都是普通方法)
注意区分 类对象和实例化对象,二者不同!
类对象是类的表示,它存储了类的静态成员(如静态方法、静态变量)和类的元信息。类对象是在类被加载时创建的,并且在整个程序运行期间只存在一份。
实例化对象是通过类创建的具体对象,它存储了类的非静态成员(如实例变量)和实例方法的具体值。每次创建类的实例对象时,都会在内存中分配一块新的空间。
类对象和实例化对象具有不同的属性和行为。类对象用于管理类的静态成员和提供类级别的操作,而实例化对象用于存储类的实例变量和提供实例级别的操作。
感谢观看,希望对您有所帮助!
下期预告:死锁问题
















 5711
5711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











