







如果想观看更多Java内容 可上我的个人主页关注我,地址
子逸爱编程-CSDN博客![]() https://blog.csdn.net/a15766649633?type=blog
https://blog.csdn.net/a15766649633?type=blog
使用工具 IntelliJ IDEA Community Edition 2023.1.4
使用语言 Java8
代码能力快速提升小方法,看完代码自己敲一遍,十分有用
目录
1.1 DataOutputStream类和DataInputStream类
2.2 对象输出流ObjectOutputStream实现序列化
2.2.1 ObjectOutputStream类的常用方法
2.3 对象输入流ObjectInputStream实现反序列化
2.3.1 对象输入流ObjectInputStream的基本概念
2.3.2 对象输入流ObjectInputStream的常用方法
1.数据操作流
前面学习的各类流实现了对文本文件的读写操作,但常见的文件读写操作还有一种二进制文件的读写操作。接下来介绍数据操作流DataOutputStream和DataInputStream,使用它们实现对二进制文件的读写操作。
1.1 DataOutputStream类和DataInputStream类
DataOutputStream类是OutputStream类的子类,利用DataOutput类写二进制文件的实现步骤与使用FileOutputStream类写文件的步骤极其相似,而且用到了FIleOutputStream类。同样,DataInputStream类是InputStream的子类,在使用上也与FileInputStream类很相似。
使用这个可以操作视频,图片,音频等二进制文件。
不使用数据操作流字节流的多样性将会缩减,字节流也可以先进行缓冲流再进行数据操作流,字节缓冲输入流类名:BufferedOutputStream,字节缓冲输出流类名:BufferedInputStream,用法与字符的相同,只不过如果要使用数据操作流还要再创建一个数据操作流,然后把缓冲流作为参数丢进去(也可以不使用缓冲,直接把字节流);
1.2 数据操作流贯穿示例
示例代码
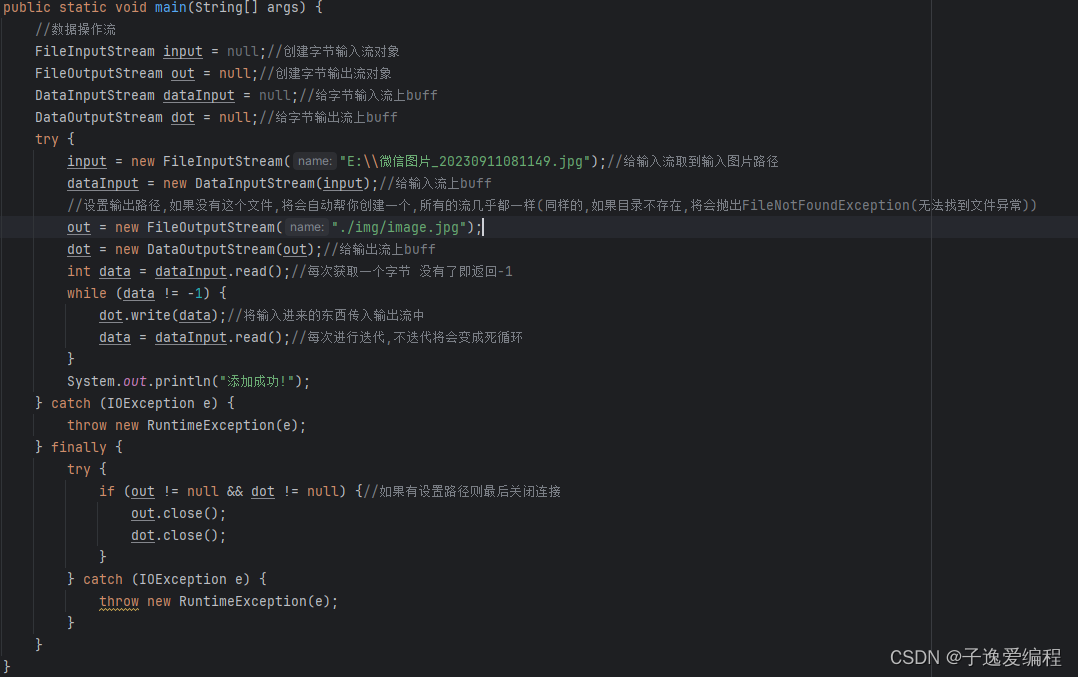 运行以上这段代码将把"E:\\微信图片_20230911081149.jpg"这个路径的图片二进制文件拷到"./img/image.jpg"路径中
运行以上这段代码将把"E:\\微信图片_20230911081149.jpg"这个路径的图片二进制文件拷到"./img/image.jpg"路径中
1.3 小结
DataOutputStream类可以按照与平台无关的方式(就是不管你是什么平台,Windows,Mac什么的都可以)向流中写入基本数据类型的数据,如int、float、long、double和boolean等。此外,DataOutputStream类的writeUTF()方法能写入采用UTF-8字符编码的字符串。
FileOutputStream out1=new FileOutputStream("路径");
DataOutputStream out=new DataOutputStream(out1);
out.writeByte(1);//其他的基本数据类型也可以,改最后的数据类型就可以了
out.writeUTF("Hello");
DataInputStream类与DataOutputStream类搭配使用,可以按照与平台无关的方式从流中读取基本数据类型的数据,如int、float、long、double和boolean等。此外,DataInputStream类的readUTF()方法能读取采用UTF-8字符编码的字符串。
FileInputStream in1=new FileInputStream("路径");
DataInputStream in=new DataInputStream(in1);
System.out.println(in.readByte());//其他的基本数据类型也可以,改最后的数据类型就可以了
System.out.println(in.readUTF());
2. 序列化和反序列化
2.1 序列化和反序列化
2.1.1序列化和反序列化基本概念
![]()
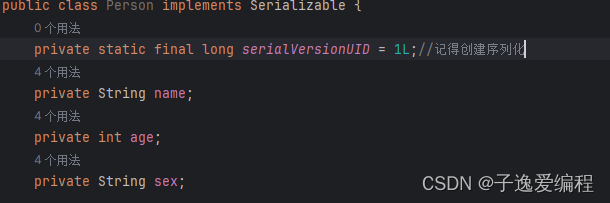
在设置中的检查把这个打勾,可以在类名处按alt+enter就可以创建序列号;
对象序列化和反序列化操作时可能会遇到版本兼容性问题。在对象进行序列化或反序列化操作的时候,要考虑JDK版本。如果序列化的JDK版本和反序列化的JDK版本不统一,就有可能发生错误。所有在序列化操作中引入了一个serialVersionUID的常量,可以通过此常量验证版本的一致性。在进行反序列化时,JVM会把传来的字节流中的serialVarsionUID与本地相应实体(类)的serialVarsionUID进行比较。如果二者相同,就认为版本是一致的,可以进行反序列化;否则会出现序列化版本不一致的异常。
当实现java.io.Serializable接口的类没有显示定义名为serialVersionUID、类型为long的变量是,Java序列化机制在编译时会自动生成一个此版本的serialVersionUID变量。如果不希望通过编译自动生成,也可以直接显示定义这个变量。
例如,可以在Person类中加入以下常量:
private static final long serialVersionUID=1L;
序列化时包名和文件名不能为中文,要规范,不然会运行错误;
在前面的内容中实现了通过java程序读写文件。事实上,在开发中检查需要将对象的信息保存在磁盘中以便以后检索。可以将对象中的属性信息逐一记录到文本文件中,但这样程序员不得不为每一个对象编写代码;当使用时再将这些信息从文本文件中还原,这样需要对对象中的信息进行逐一处理,过程很烦琐且非常容易出错,而序列化提供了实现这个目标的便捷方法。
简单来说,序列化就是将对象的状态更轻松简单地存储到特定的存储介质中的过程,也就是将对象状态转换为可保持或可传输的过程。使用序列化的意义也在于将java对象序列化后,可以将其转换成字节序列,这些字节序列可以被保存在磁盘上,也可以借助网络进行传输,同时序列化后的对象保存的是二进制状态,这样实现了平台无关性,即可以将在Windows操作系统中实现序列化的一个对象,传输到Linux操作系统的机器上。反序列化时将特定的存储介质中的数据重新构建对象的过程,通过反序列化后得到相同对象,而无需担心数据因平台不同出现异常。
实现序列化和反序列化操作,需要使用对象操作流,下面将分别介绍对象输出流(ObjectOutputStream)和对象输入流(ObjectInputStream);
2.2 对象输出流ObjectOutputStream实现序列化
简单来说,对象的序列化,是把一个对象变为二进制的数据流的一种方法,通过对象序列化可以方便地实现对象的传输和存储。如果一个类的对象需要被序列化,则这个对象所属类必须实现java.io.Serializable;这个一定一定不要忘记了!!!超级超级重要,没加的话是无法序列化的。
因为在此接口中并没有定义任何方法,所以次接口是一个标识接口。一旦某个类实现了Serializable接口,该类的对象就是可序列化的。在JDK1.8类库中有些类(如String类、包装类和日期时间类等)实现了Serializable接口。现创建一个Person类,并标记该类的对象时可序列化的,代码如下:
在上面的代码中,因为Person类已经实现了Serializable接口,所以此类的对象时可以被序列化的,而如果完成序列化操作,就还需要依靠对象输出流,他可以将对象转成二进制字节数据输出到文件中保存。
2.2.1 ObjectOutputStream类的常用方法
| ObjectOutputStream(OutputStream out) | 创建对象输出流对象 | 构造方法 |
| final void writeObject(Object obj) | 将指定对象写入流 | 实例方法 |
2.2.2 序列化贯穿示例
示例代码
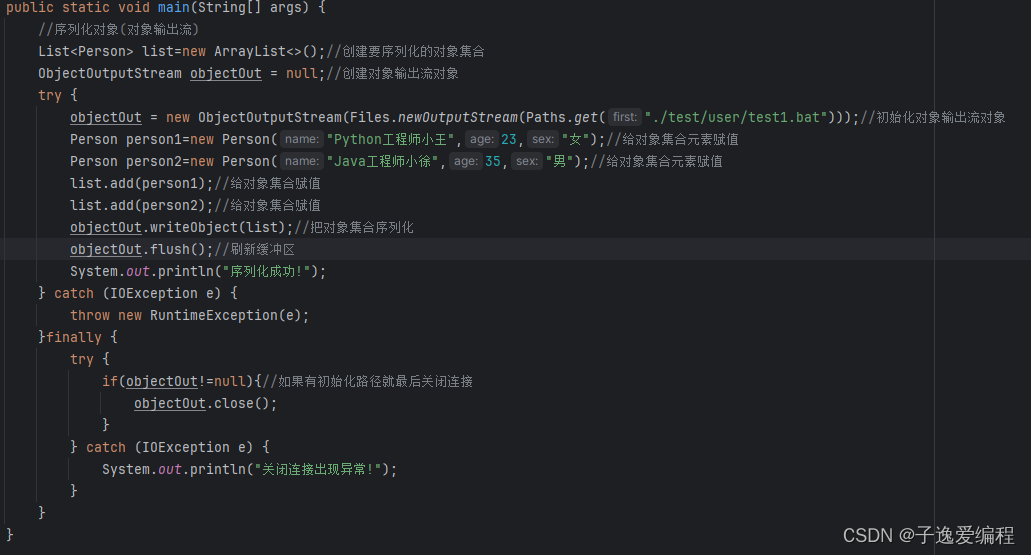 执行以上代码将会在""./test/user/"目录下创建一个"test1.bat"文件,然后里面就是序列化的对象;
执行以上代码将会在""./test/user/"目录下创建一个"test1.bat"文件,然后里面就是序列化的对象;
使用普通的对象也是同理,做法相同;

以上的获取路径方法可以记一下 ;
2.3 对象输入流ObjectInputStream实现反序列化
2.3.1 对象输入流ObjectInputStream的基本概念
既然能将对象的状态保存在存储介质中,那么如何将这些对象状态读取出来呢?这就要用到反序列化。反序列化就是序列化的相反操作,序列化是将对象的状态信息保存到存储介质中的过程,反序列化则是从特定存储介质中读取数据并重新构建成对象的过程。通过反序列化,可以将存储在文件上的对象信息读取出来,然后重新构建为对象。这样就不需要再将文件上的信息一一读取、并分析,重新组织为对象。
通常,对象中的所有属性都会被序列化,但是对于一些比较敏感的信息,如用户的密码,一旦序列化,人们完全可以通过读取文件或拦截网络传输数据的方式获得这些信息。因此,出于安全考虑,某些书香苑应限制被序列化,解决的办法是使用transient关键字修改不需要序列化的对象属性。
例如,若希望Person对象中的年龄信息不被序列化,只需在Person类的age属性前添加transient关键字,如下所示
private transient int age;
在完成以上修改后,age属性将被限制序列化;
2.3.2 对象输入流ObjectInputStream的常用方法
执行反序列化操作需使用对象输入流ObjectInputStream,他可以直接把序列化后的对象还原。ObjectInputStream类的常用方法如下所示:
| ObjectInputStream(InputStream in) | 创建对象输入流对象 | 构造方法 |
| final Object readObject() | 从指定位置读取对象 | 实例对象 |
在反序列化时,readObject()方法返回的是Object对象,因此,如果需要转换为Person对象,则需进行强制类型转换;
2.3.3 反序列化贯穿示例
示例代码
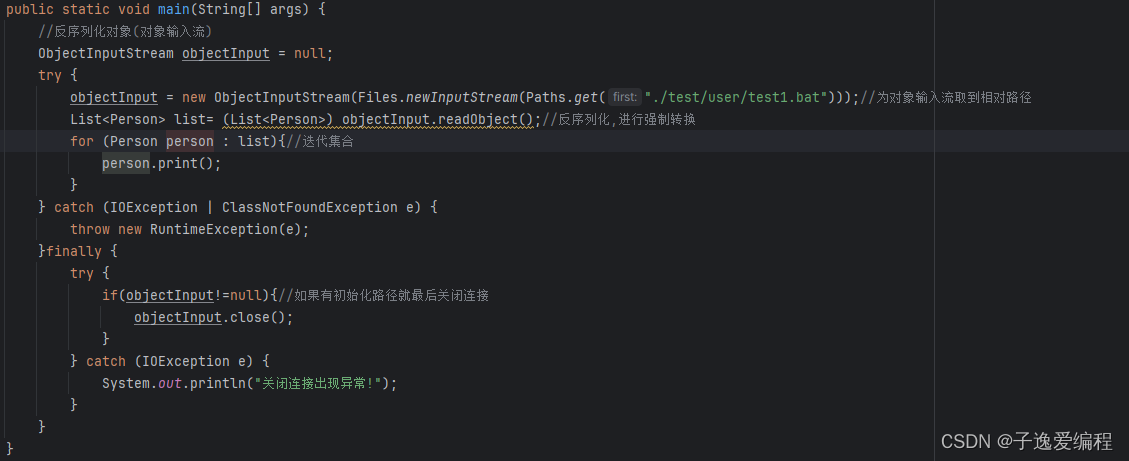 运行结果
运行结果

如果序列化中的对象是普通的对象也是同理,做法相同;
如果使用序列化方式向文件中写入多个对象,那么反序列化恢复对象时,也按照写入的顺序读取。
2.3.4 Java体系中常用流的分类
| 分类 | 字节输出流 | 字节输入流 | 字符输出流 | 字符输入流 |
| 基类 | OutputStream | InputStream | Writer | Reader |
| 文件流 | FileOutputStream | FileInputStream | FileWriter | FileReader |
| 缓冲流 | BufferedOutputStream | BufferedInputStream | BufferedWriter | BufferedReader |
| 对象流 | ObjectOutputStream | ObjectInputStream | ||
| 数据操作流 | DataOutputStream | DataInputStream |
所有的基类都是抽象类,无法直接创建实例,需要借助其实现类。
所有的输出流用于实现写数据操作,所有的输入流用于实现读取操作。这个输入和输出是相对程序而言的。
所有的文件流直接与存储介质关联,也就是需指定物理节点,属于节点流,其他流的创建需要在节点流的基础上进行封装,使其具有特殊的功能。例如,缓冲流在节点流的基础上增加缓冲区,对象流在节点流的基础上可实现序列化对象。
在操作文本文件时,应使用字符流。字节流可以处理二进制数据,它的功能比字符流更强大。因为计算机里所有的数据都是二进制数据,如果字节流处理文本文件,还需要把这些字节转成字符,就增加了编程的复杂度,降低了执行效率。所以当输入和输出是文本文件时,尽量使用字符流。如果是二进制文件,则应考虑使用字节流。
在实际开发中,可能会使用到其他类型的I/O流,它们也是四个抽象基类的实现类,用到时可查阅API帮助文档自行学习。















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









