



1、Pandas数据结构
Pandas有两个重要的数据结构:
(1)Series:由数据和行索引组成,
·类似一个一维数组,具有数据和索引
·Series可以存储任何数据类型,并通过索引来访问元素;默认索引从0开始,也可以自定义索引
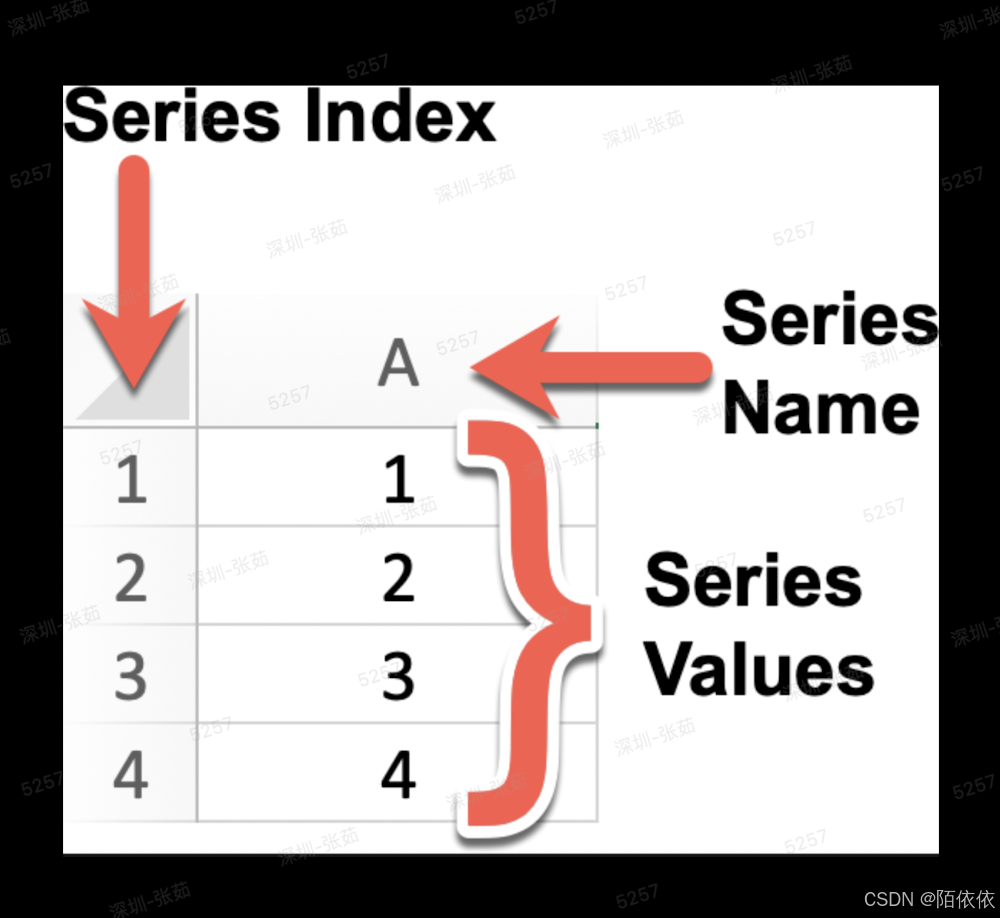
·可以使用pd.Series()构造函数创建一个Series对象,传递一个数据数组和一个可选的索引数组。
(2)DataFrame:有行索引、列索引和数据组成
·类似一个二维的表格或者数据库中的数据表,含有一组有序的列,每一列可以是不同的值类型
·既有行索引又有列索引,他可以被看做由Series组成的字典。
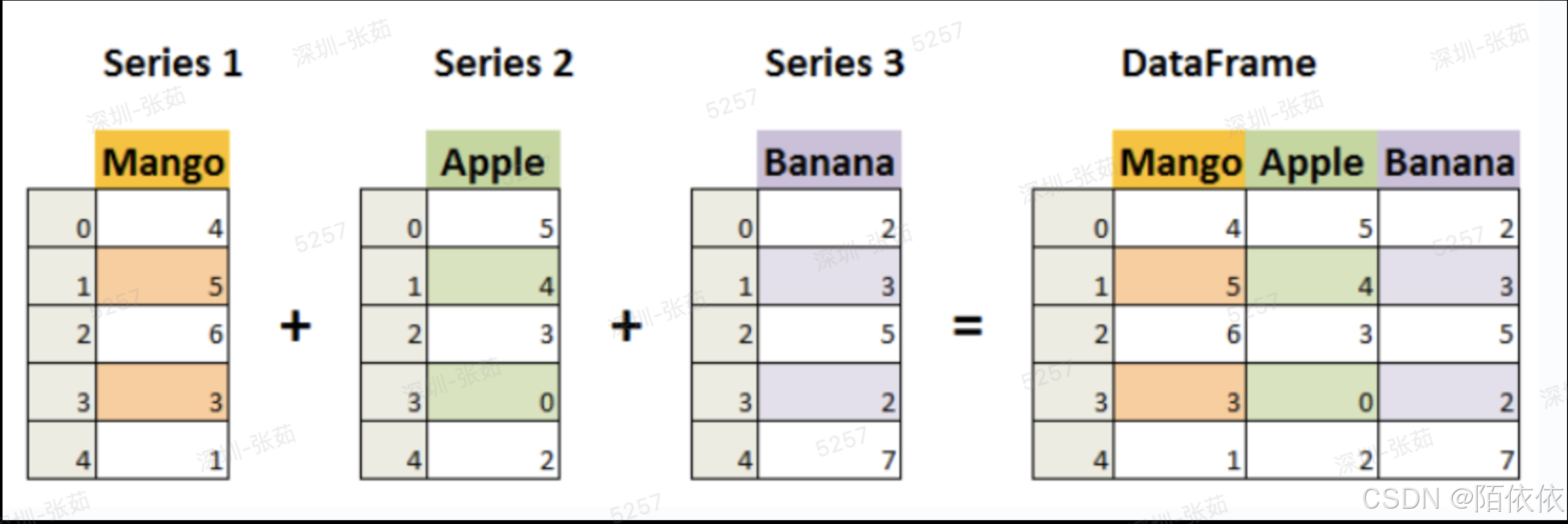
pandas里的两个数据解构series和DataFrame
series相当于一个竖向的一维列表, 但是同列表不一样的地方是,他可以定义他的表头和索引,例如:
import pandas as pd
s1 = pd.series([2,4,6],name="text",index=['a','b','c'])结果:

Series和DataFrame的区别:
- Series:由数据和行索引组成,DataFrame:有行索引、列索引和数据组成
Series是一维结构,只有索引,没有列名和列索引;而DataFrame是二维结构,有行索引和列索引(列名)
2、os库:与操作系统进行交互的库
例如:os.path.exists()
·检查路径是否存在
·使用 os.path.exists() 函数检查指定的路径是否存在。
3、df.shape 属性
(1)在 pandas 中,DataFrame 对象的 shape 属性用于返回该 DataFrame 的维度信息,以元组的形式呈现。示例如下:
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data)
# 查看 df 的 shape 属性
print("df 的 shape 属性:", df.shape)上述代码运行后,输出结果为 (3, 3),表示 df 有 3 行 3 列。
(2)df.shape[1]
df.shape[1] 表示取 df.shape 元组中的第二个元素,即 DataFrame 的列数。在上述示例中,df.shape[1] 的值为 3。
4、f.endswith(('.xls', '.xlsx')) 和f.endswith(('.xls' or '.xlsx'))
(1)f.endswith(('.xls', '.xlsx'))
在 f.endswith(('.xls', '.xlsx')) 中,f 是要检查的字符串,通常代表文件名;('.xls', '.xlsx') 是一个元组,包含了两个可能的后缀。endswith() 方法会检查 f 是否以元组中的任意一个字符串结尾。
返回值:如果 f 以 .xls 或 .xlsx 结尾,endswith() 方法返回 True;否则返回 False。
(2)f.endswith(('.xls' or '.xlsx'))
含义:在 Python 中,逻辑运算符 or 会对操作数进行布尔运算。'.xls' or '.xlsx' 会先判断 '.xls'的布尔值,由于非空字符串的布尔值为 True,所以 '.xls' or '.xlsx' 的结果就是 '.xls'。因此,f.endswith(('.xls' or '.xlsx')) 实际上等价于 f.endswith('.xls'),只会检查字符串 f 是否以 .xls 结尾。
5、map()方法和lambda函数
map()方法是pandas中series对象的方法,数据中的一列就是一个series,它可以对series中的每一个元素应用一个函数
lambda是一个匿名函数,其语法是lambda 参数:表达式。
例子:
map(lambda x: "连载中" if x == 0 else "已完结" 表示如果传入的参数 x 等于 0,就返回字符串 "连载中",否则返回字符串 "已完结"。)
表示对series对象的每一个元素应用lambda函数,
6、apply函数
作用:apply函数也是pandas中series对象的方法,它可以对series中的每一个元素应用一个自定义函数
7、isinstance函数
作用:isinstance() 是一个内置函数,用于检查一个对象是否是指定类或类型元组中某个类的实例。
例如:isinstance(value, str) 用于检查 value 是否为字符串类型
8、dropna函数和subset函数
dropna是pandas中dataframe对象的一个方法,用于移除包含缺失值(如NaN、NaT等)的行或列。。
subset参数则指定了在那些列中检查缺失值。。
df = df.dropna(subset=["最近一次更新"])
上面的代码表示,在最近一次更新列中寻找缺失值,然后将缺失值的行从数据框中删除
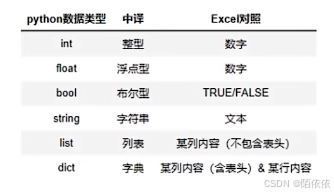
9、python的数据结构:
10、python代码,打开文件
语法:
with open('example.txt', 'r', encoding='utf-8') as file:
# 这里可以对文件进行读取操作
content = file.read()
print(content)优势:with 语句是 Python 的上下文管理器,它能自动管理资源的生命周期。在处理文件时,使用 with open(...) as ... 语句打开文件,在代码块结束后,会自动关闭文件,避免手动调用 file.close() 方法,防止因忘记关闭文件而导致资源泄漏。
代码解释
open('example.txt', 'r', encoding='utf-8'):调用open函数打开文件。'example.txt'是文件名;'r'表示以只读模式打开文件;encoding='utf-8'指定文件的编码格式为 UTF - 8,以正确处理包含中文等特殊字符的文件。as file:将打开的文件对象赋值给变量file,后续可以使用这个变量对文件进行操作。with语句块:在with语句块内,可以对文件进行读取、写入等操作。当代码块执行完毕后,文件会自动关闭。
不同模式下的写法:
(1) 写入模式“W“:
with open('example.txt', 'w', encoding='utf-8') as file:
text = "这是要写入的内容。"
file.write(text)这种模式下,如果文件不存在会创建新文件;如果文件已存在,则会覆盖原有内容。
(2) 追加模式('a')
with open('example.txt', 'a', encoding='utf-8') as file:
text = "追加的内容。"
file.write(text)追加模式下,如果文件不存在会创建新文件;如果文件已存在,则会在文件末尾追加内容。
(3)二进制读取模式('rb')
with open('example.jpg', 'rb') as file:
data = file.read()处理二进制文件(如图片、视频等)时,需要使用二进制模式。'rb' 表示以二进制只读模式打开文件。
(4)二进制写入模式('wb')
with open('new_example.jpg', 'wb') as file:
# 假设 data 是从其他地方获取的二进制数据
data = b'\x00\x01\x02'
file.write(data)'wb' 表示以二进制写入模式打开文件,用于写入二进制数据
注意:read和readline读取的文件返回值是字符串类型
11、自定义函数
(1)有参数输入,有返回值输出
def 函数名(参数):
...
return 参数输出(2)无参数输入,有返回值输出
def 函数名():
...
return 参数输出
#函数调用,并用一个变量接收函数返回值
a = 函数名()
(3)有参数输入,无返回值输出
def upload_data(date):
print(f"{data}已经更新的数据库")
upload_data(2025-3-19)(4)无参数输入,无返回值输出
def 函数名():
...
12、pandas用read_excel文件时,通常会发生数据类型发生改变的情况
解决办法是:
原来读取之前uid的数据是字符串类型,但是读取之后变成了数值类型,
读取前:
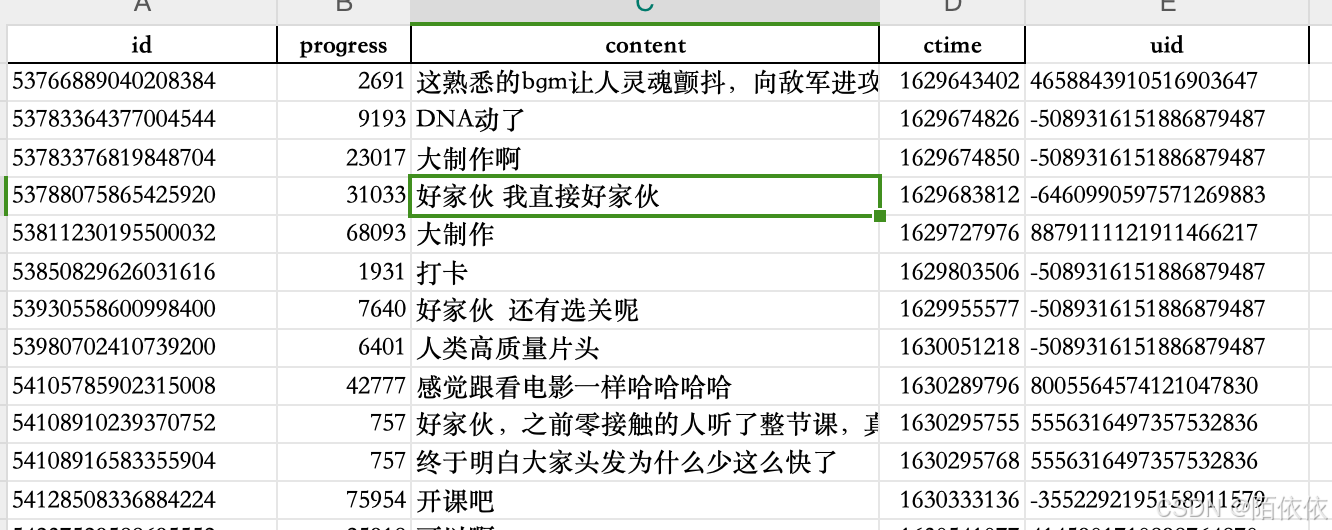
读取后,
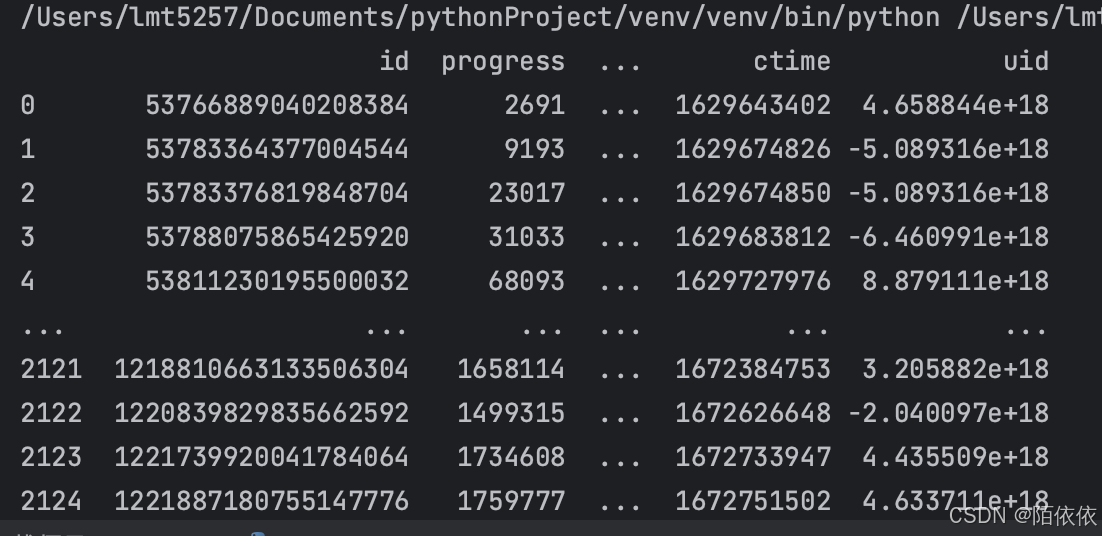
可以用info()方法查看每一列的数据类型, 看哪一列数据变了再来改
data.info()
结果:
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 2126 non-null int64
1 progress 2126 non-null int64
2 content 2126 non-null object
3 ctime 2126 non-null int64
4 uid 2086 non-null object发现id也变了,
解决办法一:
(1)加上converters={}
import pandas as pd
data = pd.read_excel('1、系统认识数据分析.xlsx', converters={'uid': str, 'id':str})
print(data)表示uid按照字符串类型读取
(2)解决办法二:astype方法
data['id'] = data['id'].astype(str)13、文件导出
# 导出excel文件
data.to_excel('test excel.xlsx')
# 导出csv文件
data.to_csv('test csv.csv')
#导出为txt文件,
data.to_csv('test.txt',sep='\t')注意:导出的csv文件,用excel打开的时候,会将文本型的数值转换为数值型的数值,并且用科学计数法表示,如下图:
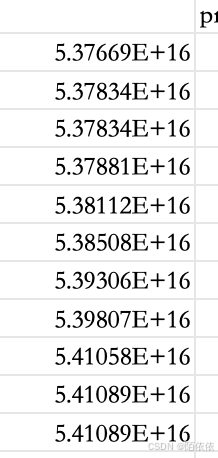
所以非要导出csv文件的话,可以先导出为txt文件,用excel打开txt文件,在分列的时候选择文本格式输出
14、pandas DataFrame对象的数据访问\筛选\去重
源数据:
(1)数据访问:
访问单列数据:id列
# 访问一列数据
print(data['id'])访问多列数据:id列和uid列
# 访问多列数据
print(data[['id', 'uid']])
访问单行数据:第一行,用iloc方法
# 访问行数据
print(data.iloc[1])访问多行数据:切片取数据,取1-5行
print(data.iloc[1:6])访问多行数据的某个字段,比如id字段:
print(data.iloc[1:6]['id'])访问多列多行:
# 访问多列多行
print(data[['id', 'uid']].iloc[1:6])
print(data.iloc[1:6][['id', 'uid']])(2)数据筛选:
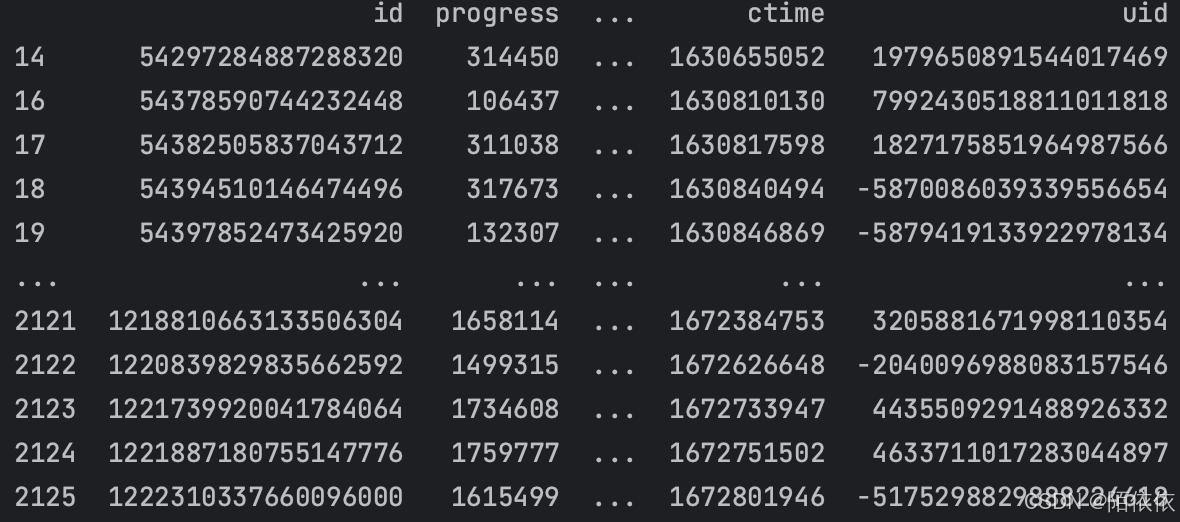
# 筛选progress列,大于10万的数据
print(data['progress'] >= 100000)结果返回的是布尔值:
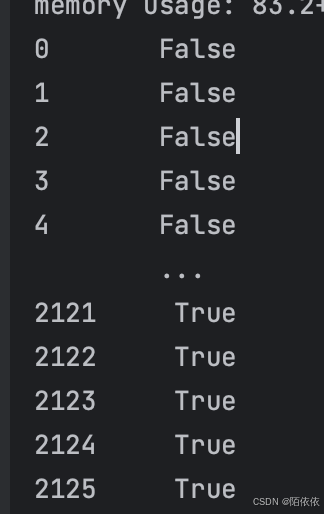
如果要筛选出数据,见:
print(data[data['progress'] >= 100000])结果:
(3)数据去重
print(data.drop_duplicates(subset='uid', keep='first', inplace=True))方法:drop_duplicates(subset='uid', keep='first', inplace=True))
参数解释:
·· subset='uid':根据uid字段进行去重,
··keep='first' :去重时,保留第一条数据,也可以是keep='last'最后一条数据,
··inplace=True:去重后替换原来的数据,
15、DataFrame对象数据合并与连接
(1)数据合并 pd.concat
import pandas as pd
data = pd.read_excel('1、系统认识数据分析.xlsx', converters={'uid': str})
print(len(data))
data2 = pd.read_excel('2、EXCEL基础操作.xlsx', converters={'id': str, 'uid': str})
print(len(data2))
# concat连接两个数据,axis=0沿着y轴方向,从上到下合并
print(pd.concat([data, data2], axis=0))使用 pd.concat 函数将 data 和 data2 两个 DataFrame 沿着垂直方向(axis=0)合并,然后打印合并后的结果。
可能存在的问题及改进建议
- 列名不一致问题
如果两个 Excel 文件的列名不完全一致,pd.concat 合并时会保留所有的列,缺失值会用 NaN 填充。你可以提前检查并处理列名,确保合并时列名匹配。
# 检查列名
print(data.columns)
print(data2.columns)
# 如果需要,可以重命名列名
data2 = data2.rename(columns={'id': 'uid'}) # 假设将 'id' 列重命名为 'uid'
- 索引问题
pd.concat 合并后,新的 DataFrame 会保留原来的索引。如果需要重新生成连续的索引,可以使用 reset_index 方法。
merged_data = pd.concat([data, data2], axis=0)
merged_data = merged_data.reset_index(drop=True)
print(merged_data)
- 数据类型一致性
虽然你已经指定了部分列的数据类型为字符串,但其他列的数据类型可能不一致,这可能会影响后续的数据处理。可以使用 astype 方法统一数据类型。
# 假设所有列的数据类型都转换为字符串
merged_data = merged_data.astype(str)
print(merged_data)(2)数据连接merge
merge方法通常用于基于一个或多个键将不同 DataFrame 中的行连接起来,类似于 SQL 中的JOIN操作。
源数据:concat_data.xlsx
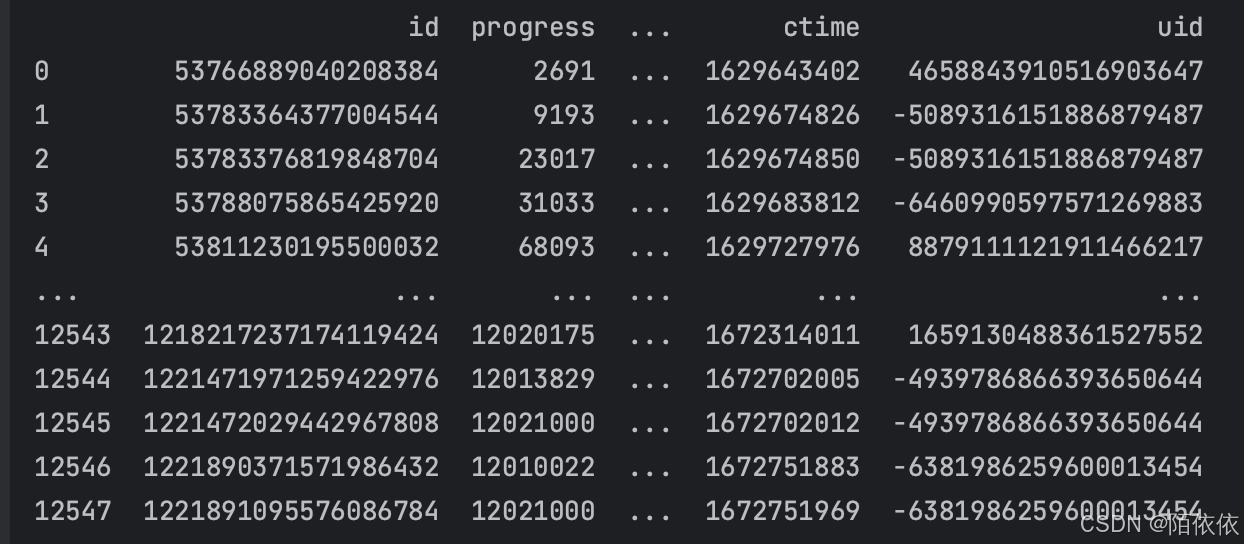
user_level.xlsx

用法说明:
- z连接的列名一样的时候,直接连接:
-
print(pd.merge(concat_data, user_level, how='inner', on='uid')) -
concat_data连接user_level表,how='inner'进行内连接,on='uid'根据字段uid进行连接,(两个表都是uid列名一样的)
完整代码:
import pandas as pd
data = pd.read_excel('1、系统认识数据分析.xlsx', converters={'uid': str})
# print(len(data))
data2 = pd.read_excel('2、EXCEL基础操作.xlsx', converters={'id': str, 'uid': str})
# print(len(data2))
# concat连接两个数据,axis=0沿着y轴方向,从上到下合并
concat_data = pd.concat([data, data2], axis=0)
user_level = pd.read_excel('user_level.xlsx', converters={'id': str, 'uid': str})
# concat_data连接user_level表,how='inner'进行内连接,on='uid'根据字段uid进行连接,(两个表都是uid列名一样的)
print(pd.merge(concat_data, user_level, how='inner', on='uid'))结果:
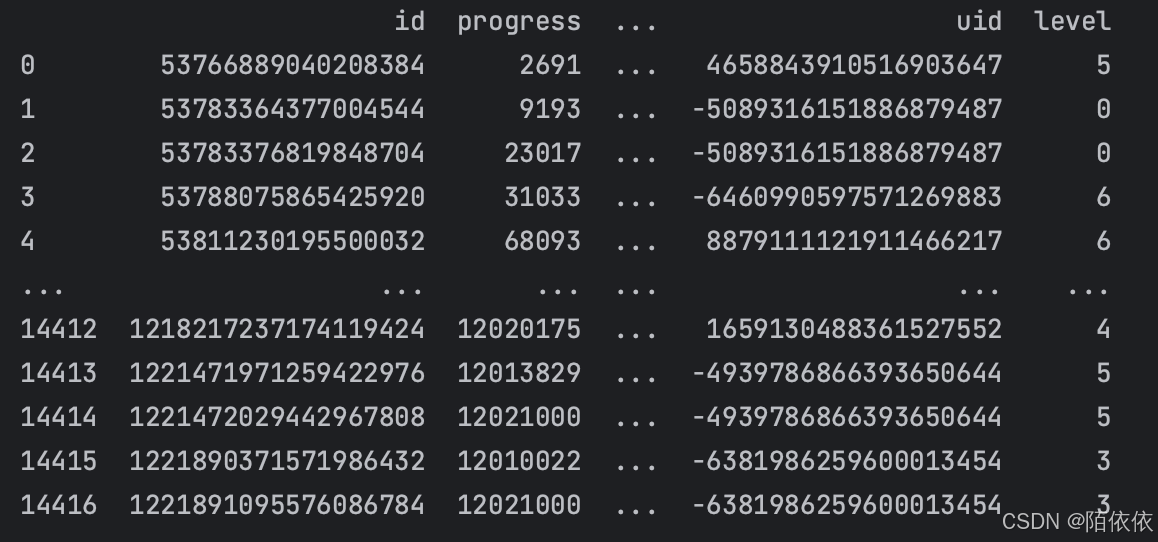
- 连接的列名不一样,用left_on和right_on
user_level.rename(columns={'uid': "user_id"}, inplace=True)
print(pd.merge(concat_data, user_level, how='inner', left_on='uid',right_on='user_id'))更改user_level uid字段名为user_id,再连接的时候就用left_on='uid',right_on='user_id'
16、sort_values方法排序和匿名函数lambda
(1):sort_values排序
# 对data数据进行排序,方法sort_values(),不写默认是升序排序
print(data.sort_values('uid'))
# 先按照uid排序,再按照time排序,ascending=False表示降序排序表示uid和time都按照降序排序
print(data.sort_values(['uid', 'time'], ascending=False))
# 先按照uid升序排序,再按照time降序排序,
print(data.sort_values(['uid', 'time'], ascending=[True, False]))参数说明:
ascending=False表示降序排序,True是升序排序,默认不写也是升序
(2)匿名函数lambda
作用:简化代码,当需要定义一个简单的函数,且该函数只在一处使用时,使用 lambda 函数可以避免使用 def 关键字定义函数带来的代码冗余。
add = lambda x:x+5
print(add(5))
add1 = lambda x,y:x+y
print(add1(5,5))这里使用 lambda 表达式定义了一个匿名函数,它接受一个参数 x,并返回 x + 5 的结果。然后将这个匿名函数赋值给变量 add。
总结:
这段代码很好地展示了 lambda 表达式在定义简单函数时的便捷性。不过,lambda 函数通常适用于简单的、一次性使用的场景,如果函数逻辑较为复杂,建议使用 def 关键字来定义普通函数,这样可以提高代码的可读性和可维护性。
17、DataFrame对象的分组、聚合和转换
(1)groupby分组
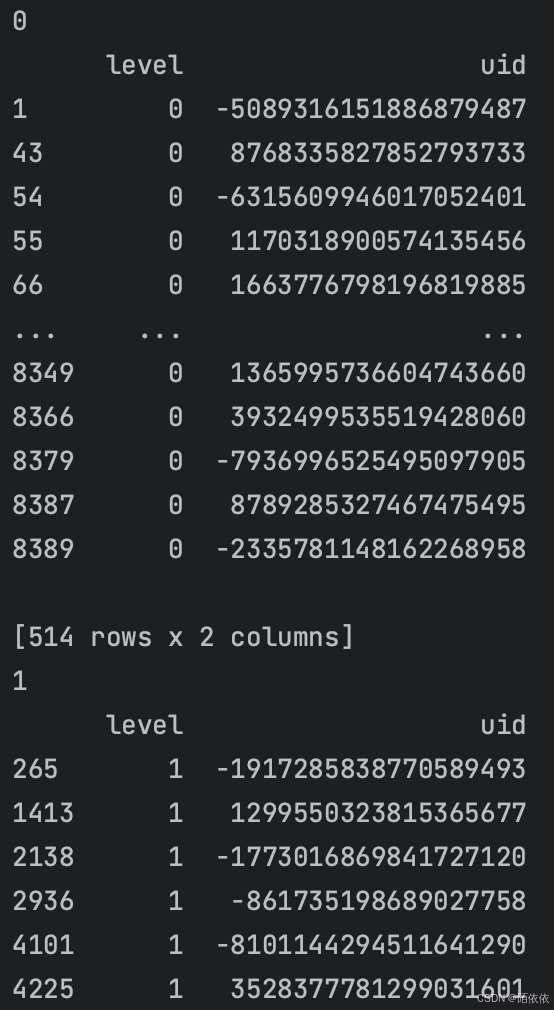
# 生成一个<pandas.core.groupby.generic.DataFrameGroupBy object at 0x104483f40>管理者对象,不是直接的数据
user_managers = user_data.groupby('level')
# 分组后计数,在对象的基础上进行操作
print(user_managers.count())在上述代码中,user_data.groupby('level')按 level列对 DataFrame 进行分组,得到的 grouped 就是一个 DataFrameGroupBy 对象。
若你想查看分组后的具体数据或者对分组后的数据进行进一步操作,需要在 DataFrameGroupBy 对象上调用相应的方法,下面是一些常见的操作:
- 用for循环,展示出来数据:
for name,f in user_managers:
print(name)
print(f)结果:
(2)数据聚合
history:
history = pd.read_excel('history.xlsx')
# 数据分组
data_managers = history.groupby('商品名称')
# 分组后对某个字段进行数据聚合
print(data_managers['消耗'].sum())聚合是在分组后才能运用的,sum()函数在这里就是聚合函数,
结果:
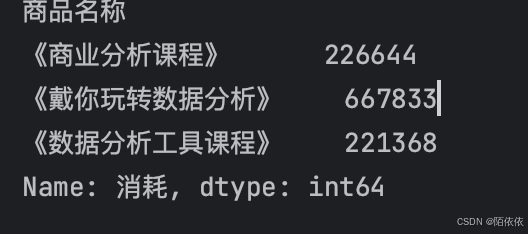
这个聚合的结果是一个series对象:
print(type(data_managers['消耗'].sum()))
# 结果:<class 'pandas.core.series.Series'>也可以变成一个DataFrame对象:(只需要在消耗外面再加一个中括号)
因为包含了列名,所以是一个DataFrame对象
print(data_managers[['消耗']].sum())
print(type(data_managers[['消耗']].sum()))
# 结果:<class 'pandas.core.frame.DataFrame'>
多字段聚合:
print(type(data_managers[['消耗','GMV']].sum()))- 聚合函数agg()
作用:在 Pandas 中,agg() (它是 aggregate() 的别名)是一个非常强大的方法,可用于对 Series、DataFrame 或 GroupBy 对象进行聚合操作。借助 agg() 方法,你能够对数据运用一个或多个聚合函数,从而得到所需的统计信息。
用法:
# 对字段进行相同的聚合
.agg([fun1,fun2...])
# 对字段进行不同的聚合
.agg({‘字段1’:fun1,'字段2':fun2,...})
# 对字段进行多个不同的聚合
.agg({‘字段1’:[fun1,fun2,...],'字段2':fun,...})举例:
history = pd.read_excel('history.xlsx')
# 数据分组
data_managers = history.groupby('商品名称')
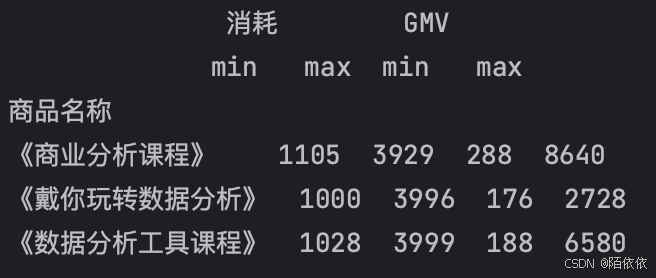
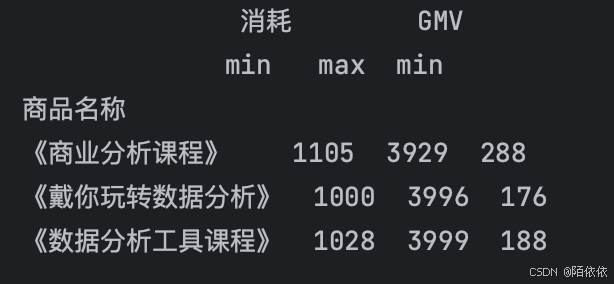
# 对消耗和GMV都进行min/max聚合
print(data_managers[['消耗', 'GMV']].agg(['min', 'max']))结果:
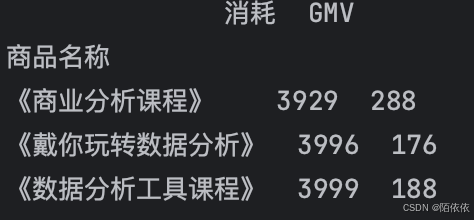
print(data_managers.agg({'消耗': 'max', 'GMV': 'min'}))结果:
# 对消耗进行min/max聚合,对GMV进行min聚合
print(data_managers.agg({'消耗': ['min', 'max'], 'GMV': 'min'}))结果:
- agg函数与自定义函数or lambda匿名函数结合
# 自定义函数
def diff(x):
return x.max()-x.min()
print(data_managers[['消耗', 'GMV']].agg(diff))
# lambda函数
print(data_managers[['消耗', 'GMV']].agg(lambda x:x.max()-x.min()))参数x指的是 data_managers[['消耗', 'GMV']]传来给agg的数据,是series数据,见上面👆
(3)数据转换transform
在 GroupBy 对象上使用 transform() 是它最常见的用法之一,常用于对分组数据进行转换操作,并将结果广播回原 DataFrame。
import pandas as pd
# 创建一个 DataFrame
data = {
'Category': ['A', 'B', 'A', 'B', 'A'],
'Value': [1, 2, 3, 4, 5]
}
df = pd.DataFrame(data)
# 按 Category 列分组并使用 transform() 计算每个分组的均值
df['Group_Mean'] = df.groupby('Category')['Value'].transform('mean')
print("分组后计算均值并广播回原 DataFrame 的结果:")
print(df)代码解释
df.groupby('Category')['Value'].transform('mean')按Category列对DataFrame进行分组,然后计算每个分组中Value列的均值。df['Group_Mean'] = ...将计算得到的均值广播回原DataFrame,作为新的一列Group_Mean。
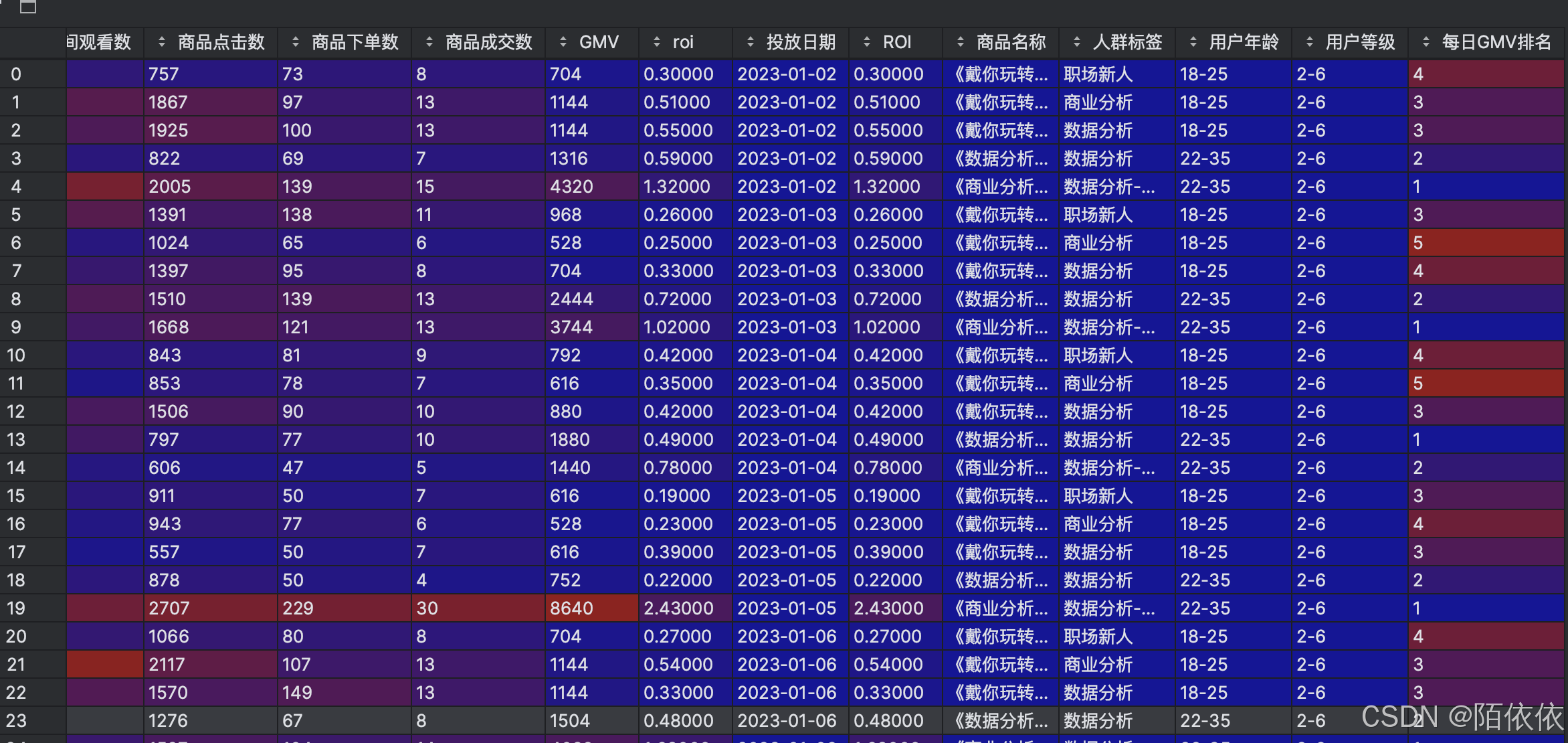
举例:每个投放日期内,广告计划ID的GMV排名:
# 每个投放日期内,广告计划ID的GMV排名
history['每日GMV排名'] = history.groupby('投放日期')['GMV'].rank(method='dense', ascending=False).astype(int)
print(history.head(20))'dense':相同值的排名相同,且排名是连续的。例如,若有两个值并列第 3 名,它们的排名均为 3,下一个不同的值的排名为 4
ascending:布尔值,控制排名的顺序。True 表示升序排名(默认值),False 表示降序排名。
结果:
- astype用法:
astype() 是一个非常实用的方法,它主要用于对 Series 或 DataFrame 的数据类型进行转换。下面为你详细介绍 astype() 方法的用法、参数以及常见应用场景。
Series.astype(dtype, copy=True, errors='raise')
DataFrame.astype(dtype, copy=True, errors='raise')参数解释
dtype:这是必需参数,用于指定要转换的数据类型。可以是 Python 内置的数据类型(如int、float、str等),也可以是 NumPy 数据类型(如np.int32、np.float64等),还可以传入一个字典,用于对不同列指定不同的数据类型。copy:可选参数,默认为True。如果设置为True,会返回一个新的对象,原对象不会被修改;如果设置为False,则尝试在原对象上进行修改。errors:可选参数,默认为'raise'。取值有'raise'和'ignore'。当设置为'raise'时,如果转换过程中出现错误,会抛出异常;当设置为'ignore'时,会忽略无法转换的部分,保留原数据类型。
18、数据清洗-字符串文本数据清洗函数
history原始数据:
(1)split --数据分割
注意:Series对象并没有split()方法。split()是 Python 字符串对象的方法,用于将字符串按指定分隔符分割成列表。- 解决方案:若要对
Series中的每个字符串元素应用split()方法,你可以使用Series的str访问器。str访问器提供了一系列字符串处理方法,可用于对Series中的每个字符串元素进行操作。
举例:
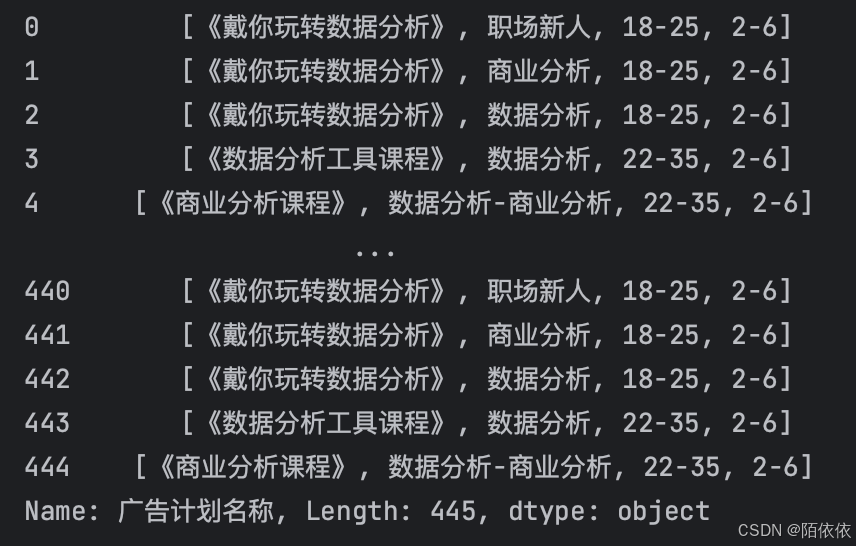
history = pd.read_excel('history.xlsx')
print(history['广告计划名称'].str.split('_'))结果:
将分割后的列表,变成dataframe对象:加上expand=True
print(history['广告计划名称'].str.split('_', expand=True))结果:

要取出某列数据,代码:
print(history['广告计划名称'].str.split('_', expand=True)[0])结果:

注意:因为上面都是视图操作,所以并不会改变原始数据history,如果想要改变,那就将上面处理的数据赋值给新的一列,插入到原始数据中:
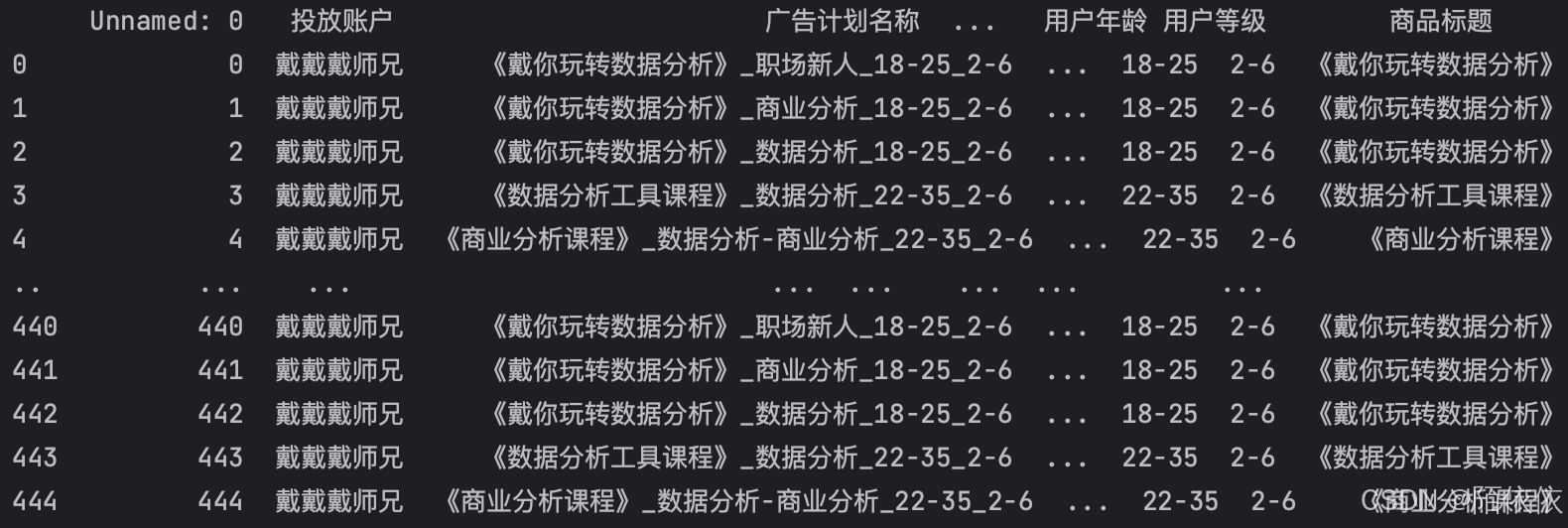
history['商品标题'] = history['广告计划名称'].str.split('_', expand=True)[0]
print(history)结果:
(2)contains --数据筛选
举例:筛选history数据中 广告计划名称 列的“戴你玩转数据分析”的所在行数据
history = pd.read_excel('history.xlsx')
print(history['广告计划名称'].str.contains('玩转'))结果:
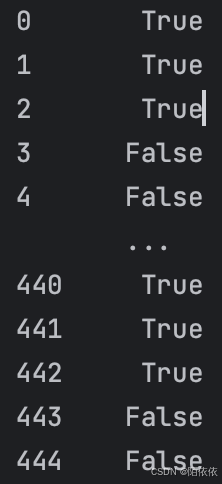
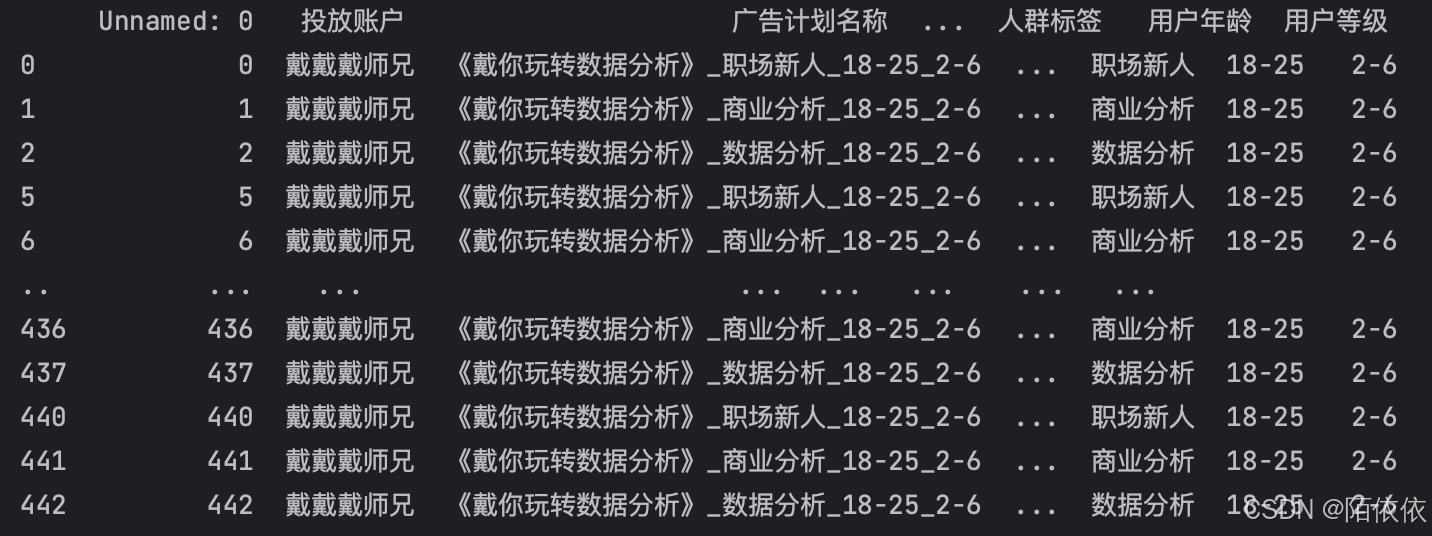
代码解释:结果返回的是布尔值,如果想要获取真实的数据,再调用一次就可以,看代码:
print(history[history['广告计划名称'].str.contains('玩转')])结果:
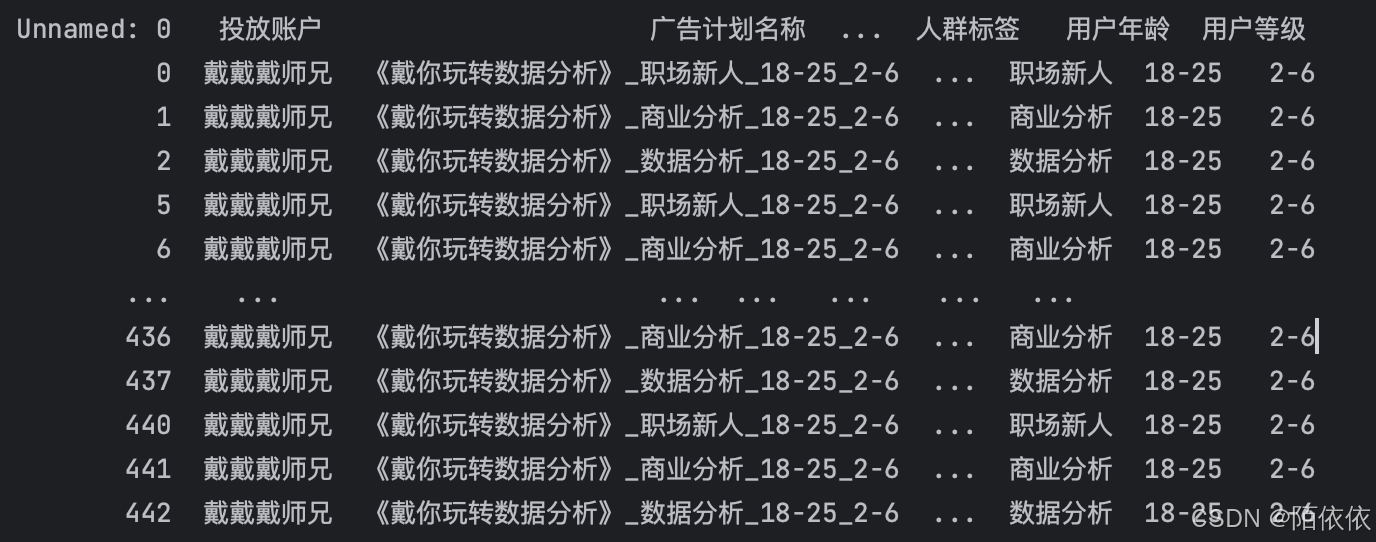
重新生成索引: reset_index(drop=True)
print(history[history['广告计划名称'].str.contains('玩转')].reset_index(drop=True))结果:
(3)replace --数据替换
print(history['广告计划名称'].str.replace('《》', '【】'))代码解释:
history['广告计划名称']:从history数据框里选取广告计划名称列,得到一个Series对象。.str:Series对象的str访问器,借助它可以对Series中的每个字符串元素使用字符串处理方法。.replace('《》','【】'):调用replace()方法,把广告计划名称列每个字符串里的《》替换成【】。
存在的问题:
在上述代码里,str.replace('《》', '【】') 尝试把 《》 作为一个整体进行替换。若你实际想分别替换 ’《 ‘ 和 ‘ 》’,可以这样操作:(先替换一个,再使用一次函数替换下一个)
print(history['广告计划名称'].str.replace('《', '【').str.replace('》', '】'))结果:

还可以配合正则表达式来使用:
result = history['广告计划名称'].str.replace(r'([《》])', lambda m: '【' if m.group(1) == '《' else '】', regex=True)
print(result)结果:
(4)extract --数据提取
作用:提取符合正则表达式的字符串
19、map、apply、applymap
history数据:
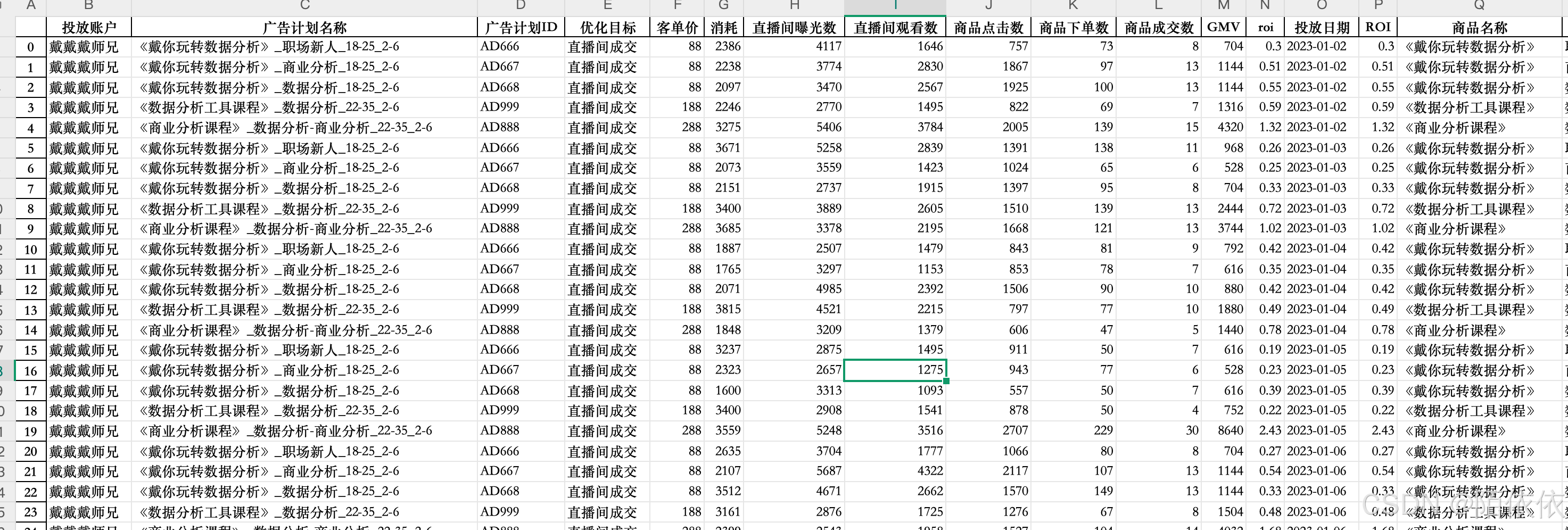
- map、apply、applymap的作用:
- 在 Pandas 中,
map用于对Series中的每个元素进行映射转换,可接受函数、字典或另一个Series;apply能在Series上逐元素应用函数,也可在DataFrame上按行或列应用函数;applymap专门针对DataFrame,将函数应用于其每个元素。就是对series或者DataFrame运用自定义规则进行数据处理
map()方法-
作用对象:主要用于
Series对象。 -
功能:把一个函数或者一个映射关系应用到
Series的每个元素上。可以传入函数、字典或者另一个Series。 apply()方法-
作用对象:既可以用于
Series对象,也可以用于DataFrame对象。 -
功能:对
Series或DataFrame应用一个函数。在Series上使用时,和map()类似;在DataFrame上使用时,可以对行或列应用函数。
用法:
history = pd.read_excel('history.xlsx')
print(history['GMV'].map(lambda x: int(x)))
print(history['GMV'].apply(lambda x: int(x)))结果:
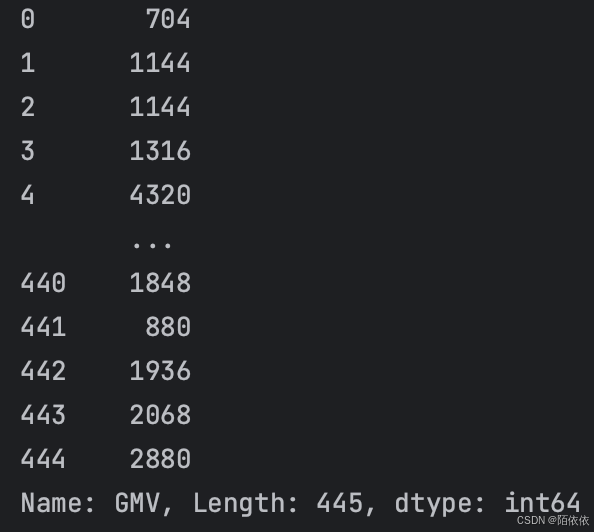
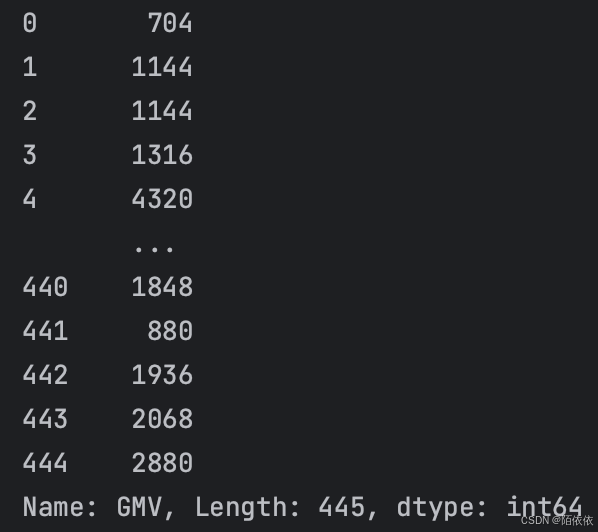
map和apply作用下的结果是一样的,含义是让history的GMV列运用lambda规则,将浮点型数据转换为整型。
map和apply的区别:
- map的参数可以是函数也可以是字典,但apply的参数只能是函数,
series/DaraFrame数据是如何传递的:
- series.map/series.apply,将series的数据逐个逐个传递给函数进行处理
- DataFrame.apply/DataFrame.applymap:是传递一个个series数据给函数进行处理
- 所以要根据传递的series类型来写函数,比如说series的一列数据是数值类型,那就不能用replace这种字符串的函数,
- 举例apply操作DataFrame对象:
history = pd.read_excel('history.xlsx')
def sum(x):
formular = x['客单价']+x['消耗']+x['直播间曝光数']
return formular
print(history.apply(sum,axis=1))代码解释:
在传递series时,默认是从上到下的,也就是axis=0,这里要找到:客单价、消耗、直播间曝光数列,应该是从左往右的,所以加上axis=1
- applymap不常用,这里不做说明。。
20、数据处理
(1)时间处理:
- 时间戳转换为日期格式datetime.fromtimestamp
# ctime列是时间戳,调用python内置模块datatime,然后用到模块datatime里面的类datatime
from datetime for datetime
# 转换方法:datetime.fromtimestamp,作为新的一列
combined_df['弹幕创建时间'] = combined_df['ctime'].map(datetime.fromtimestamp)
21、.plot() 方法绘图
pandas 库中的 .plot() 方法:
import pandas as pd
import numpy as np
# 创建一个示例 DataFrame
data = {
'A': np.random.randn(100).cumsum(),
'B': np.random.randn(100).cumsum()
}
df = pd.DataFrame(data)
# 使用 .plot() 方法绘制折线图
df.plot()
# 显示图形
import matplotlib.pyplot as plt
plt.show()代码解释
- 导入必要的库:导入
pandas和numpy库,numpy用于生成随机数据。 - 创建示例
DataFrame:生成包含两列随机数据的DataFrame。 - 使用
.plot()方法绘图:调用df.plot()方法绘制DataFrame中各列的折线图。 - 显示图形:导入
matplotlib.pyplot库并调用plt.show()方法显示绘制的图形。
pandas 的 .plot() 方法支持多种图表类型,通过 kind 参数指定,常见的类型有:
'line':折线图(默认值)'bar':柱状图'barh':水平柱状图'hist':直方图'box':箱线图'kde'或'density':核密度估计图'area':面积图'pie':饼图
22、pandas、os、datetime、matplotlib、time模块
pandas:
- 功能:一个强大的用于数据处理和分析的库,提供了高效的数据结构(如
DataFrame和Series)和数据操作工具,可用于数据清洗、转换、分析等任务。
os:
- 功能:提供了使用操作系统功能的接口,如文件和目录操作、进程管理、环境变量等。
datetime:
- 功能:处理日期和时间的标准库,包含了
date、time、datetime、timedelta等类,用于创建、操作和格式化日期和时间。
matplotlib:
- 功能:一个用于数据可视化的库,能够创建各种静态、动态、交互式的图表,如折线图、柱状图、散点图等。
time:
- 功能:提供了处理时间相关的函数,如时间暂停、获取当前时间戳、格式化时间
23、time.gmtime() 和datetime.fromtimestamp()的区别:
在上述代码中,time.gmtime() 将时间戳转换为 UTC 时间的 struct_time 对象,datetime.fromtimestamp() 将时间戳转换为本地时间的 datetime 对象。
总的来说,如果只需要获取 UTC 时间的基本时间信息,并且对时间对象的操作要求不高,可以使用 time.gmtime()。如果需要更灵活地处理时间,包括进行各种时间计算、格式化输出等,建议使用 datetime.fromtimestamp() 获得 datetime 对象来进行操作。
24、struct_time 、 gmtime 、strftime函数
介绍:struct_time 和 gmtime 都是 Python 标准库 time 模块中的重要成员
gmtime 函数:
- 作用:
gmtime()函数将一个时间戳(从 1970 年 1 月 1 日 00:00:00 UTC 到现在的秒数)转换为 UTC(协调世界时)时间的struct_time对象。如果不传入参数,它会使用当前时间的时间戳。 - 语法:
time.gmtime([secs]),其中secs是可选参数,表示时间戳。
struct_time 类型:
- 作用:
struct_time是一个类(更准确地说是一个时间元组的表示),用于表示时间的各个组成部分,如年、月、日、时、分、秒等。gmtime函数返回的就是struct_time类型的对象。 - 属性:
struct_time对象包含多个属性,例如tm_year(年)、tm_mon(月,1-12)、tm_mday(日,1-31)、tm_hour(时,0-23)、tm_min(分,0-59)、tm_sec(秒,0-61)等。
strftime 函数:
在 time 模块里,strftime 是一个函数,它接收一个格式化字符串和一个 struct_time 对象作为参数,返回格式化后的字符串。
常用格式化代码
%Y:四位数的年份,例如2024。%m:两位数的月份,范围从01到12。%d:两位数的日期,范围从01到31。%H:24 小时制的小时数,范围从00到23。%M:分钟数,范围从00到59。%S:秒数,范围从00到59。
举例:gmtime 函数的用法:
progress数据:(单位s)
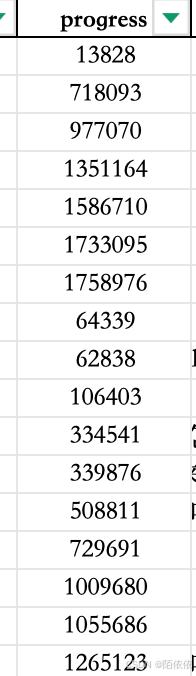
# 对时间戳进行转换,
print(combined_df['progress'].map(gmtime))结果:
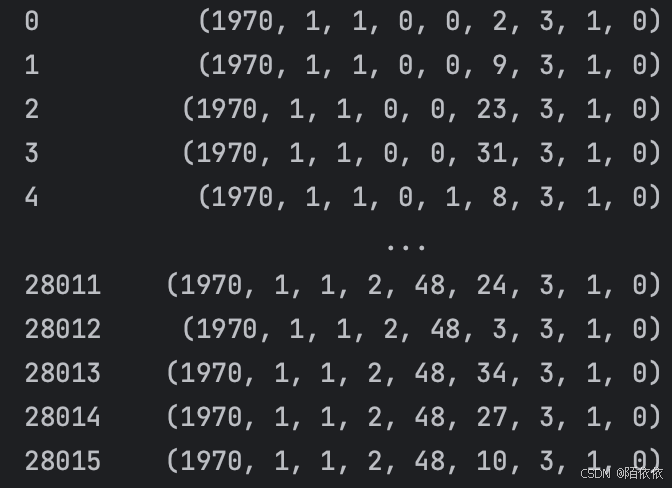
结果解读:从左到右分别是:年 月 日 时 分 秒 星期 当年的第几天 是否为夏令时
25、python字符串切片取值 ‘ .str ‘(用于series)
语法:
import pandas as pd
# 创建一个包含字符串的 Series
s = pd.Series(['apple', 'banana', 'cherry'])
# 提取每个字符串的最后 2 个字符
last_two_chars = s.str[-2:]
print("最后 2 个字符:")
print(last_two_chars)
# 提取每个字符串的奇数位置字符
odd_chars = s.str[1::2]
print("\n奇数位置字符:")
print(odd_chars)代码解释
s.str[-2:]:提取每个字符串的最后 2 个字符。s.str[1::2]:从每个字符串的索引 1 开始,以步长为 2 提取字符,也就是奇数位置的字符。
注意:
last_two_chars = s.str[-2:]这种切片语法本质上是借助pandas的.str访问器,它主要用于处理Series对象中的字符串数据。- 若直接在
DataFrame上使用.str访问器,会引发错误,因为.str访问器是专门为Series设计的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











