








📑前言
内存映射中,我们经常讨论的是由虚拟内存定位物理内存(也就是folio或者page),实际上在很多场景中(比如内存回收),会涉及反向的操作,也就是反向映射。所谓反向映射,就是给定一个folio(page),将映射它的PTE(页表项)找出来。接下来我们来详细分析一下它的原理吧(本文仅分析匿名映射部分)。
一、匿名映射的mapping
匿名映射中,mapping可以用来找到anon_vma,anon_vma关联vma,通过folio和vma,就可以得出映射的虚拟地址address,最终由address和vma定位PTE,如图1所示。
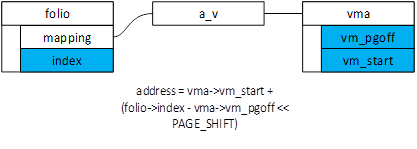
图1.匿名folio定位address示意图
图1中基本都是直来直去的关系,除了anon_vma和vma,它们实际上是多对多的关系,由anon_vma_chain结构体(以下简称avc)辅助实现。
我们从mmap返回,vma还没有映射任何物理页的情景说起。
第一次访问vma区间的地址,导致缺页异常。内核调用do_anonymous_page,申请一页内存,完成映射。
由于这是vma区间内的第一次缺页异常,vma相关的anon_vma和avc还不存在,处理异常的过程中会准备好它们,然后调用page_add_new_anon_rmap为该page(folio)建立反向映射,将anon_vma赋值给mapping字段。关键代码片段如下。
struct anon_vma *anon_vma = vma->anon_vma;
anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON;
WRITE_ONCE(page->mapping, (struct address_space *) anon_vma);
page->index = linear_page_index(vma, address);
代码中的address就是映射的虚拟地址,page->index实际上是page offset,该page在文件中的偏移量,也就是映射的是文件的第几页,计算代码如下。
pgoff = (address - vma->vm_start) >> PAGE_SHIFT;
pgoff += vma->vm_pgoff;
return pgoff;
vma->vm_pgoff是vma的起始地址对应的文件的page offset。
匿名映射没有对应文件,它的vma->vm_pgoff等于vma->vm_start >> PAGE_SHIFT。
这里需要明确一下,从内核的角度看,我们以MAP_ANONYMOUS调用mmap等完成的映射并不一定是匿名映射。置位MAP_SHARED的情况下,内核会生成“假”(pseudo)文件与之对应(shmem_zero_setup),就不是匿名的了,vma->vm_pgoff等于0。只有MAP_ANONYMOUS和 MAP_PRIVATE同时置位的情况下才是内核承认的匿名映射。
这里有以下两点需要注意。
- 整个vma可能会有多个页,它们的mapping字段是相等的,不等的是index字段。
- anon_vma和vma的关系并不依赖page,哪怕是vma映射中的其中一部分page改变映射了,从anon_vma到vma的路径并不会变。
单个进程的反向映射建立了,如图2所示。anon_vma到vma实际上是通过区间树(interval tree)实现的,为了看起来简洁些图中使用链表代替。
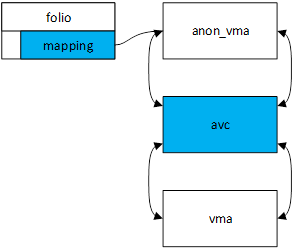
图2.匿名映射单个进程反向映射示意图
接下来考虑创建子进程的场景。在新进程创建的过程中,有些情况会调用dup_mmap复制原进程的内存空间,dup_mmap会复制vma,然后调用anon_vma_fork。anon_vma_fork会为新进程申请anon_vma,建立反向映射,完成后如图3所示。
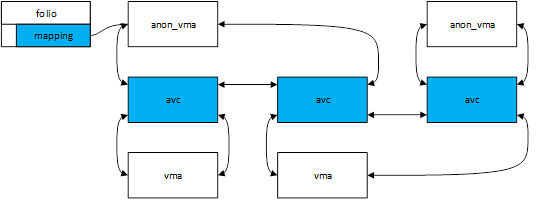
图3.创建子进程后匿名映射示意图
新进程创建完成后,从page->mapping出发,可以遍历所有映射它的PTE了。
再考虑COW的场景,缺页异常申请新的一页,将原页的内存复制到新页中,然后使用新页更新映射,根据前文中“需要注意的第2点”可以得出图4中的结果。
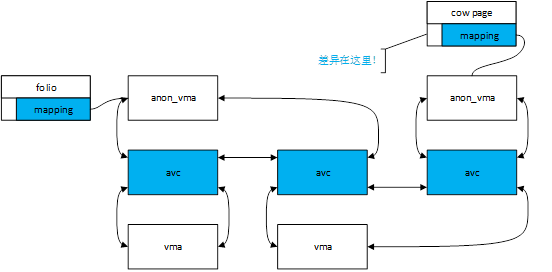
图4.COW发生后匿名映射示意图
可以看到,从原页依然可以遍历到没有映射它的vma(请仔细理解anon_vma和vma的关系并不依赖page),从新页出发倒是没有这个烦恼。
我们肯定不希望操作原页的时候会影响到没有映射它的vma,所以得到某个vma后,需要做进一步检查,原理是拿原页的pfn区间(一个folio可能包含多个连续的物理页)和vma映射的物理页的pfn做比较,落在区间内才是有效的,由check_pte实现。
有了以上的铺垫,我们可以分析匿名页的反向映射了,由rmap_walk_anon实现,核心逻辑如下。
void rmap_walk_anon(struct folio *folio, struct rmap_walk_control *rwc, bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff_start, pgoff_end;
struct anon_vma_chain *avc;
if (locked)
{
anon_vma = folio_anon_vma(folio); //1
}
else
{
anon_vma = rmap_walk_anon_lock(folio, rwc);
}
pgoff_start = folio_pgoff(folio); //2
pgoff_end = pgoff_start + folio_nr_pages(folio) - 1;
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root,pgoff_start, pgoff_end)
{
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(&folio->page, vma); //3
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg)) //4
continue;
if (!rwc->rmap_one(folio, vma, address, rwc->arg))
break;
if (rwc->done && rwc->done(folio))
break;
}
if (!locked)
anon_vma_unlock_read(anon_vma);
}
第1步,获得anon_vma,是给anon_vma->mapping赋值(见前文代码片段)的反过程。
第2步,调用folio_pgoff得到pgoff_start,然后根据folio的页数得到pgoff_end,用作遍历interval tree的时候筛选vma。folio_pgoff返回folio->index,赋值过程也见前文代码片段。
第3步,根据folio和vma计算得到虚拟地址,不考虑多页的情况下,计算过程如下。
pgoff_in_vma = page->index - vma->vm_pgoff
address = vma->vm_start + (pgoff_in_vma << PAGE_SHIFT)
这个计算过程对匿名映射和文件映射都适用。vma->vm_pgoff是vma基于文件的page offset,vma->vm_start是vma区间的其实虚拟地址,加上当前页在vma内的offset就可以得到虚拟地址了。匿名映射没有文件,vma->vm_pgoff等于vma->vm_start >> PAGE_SHIFT,用来做计算也是没有问题的。
这里anon_vma_interval_tree_foreach会筛选树上符合pgoff_start, pgoff_end区间的vma,难道anon_vma上的vma可以有不同的pgoff区间吗?答案是肯定的,为了简化问题,我们之前回避了anon_vma的重复利用问题,同一个进程符合条件的vma是可以共享anon_vma的(find_mergeable_anon_vma)。从这个角度看,vma->vm_pgoff等于vma->vm_start >> PAGE_SHIFT是合理的,同一个进程不同的vma计算得到的vma->vm_pgoff也不同。
第4步,调用rmap_walk_control(代码中简称rwc)提供的回调函数。rmap_walk_anon提供了遍历vma的方法,至于对每个vma做什么,是由调用它的函数决定的,比如folio_referenced函数希望遍历PTE,查看folio被不同PTE访问的次数,它的rwc定义如下。
struct folio_referenced_arg pra = {
.mapcount = folio_mapcount(folio),
.memcg = memcg,
};
struct rmap_walk_control rwc = {
.rmap_one = folio_referenced_one,
.arg = (void *)&pra,
.anon_lock = folio_lock_anon_vma_read,
.try_lock = true,
};
另外,rmap_walk_anon给出了vma、address和folio,但没有得到PTE,这个任务只能由rwc的回调函数自行完成,不过内核提供了page_vma_mapped_walk函数辅助完成该任务。
二、推荐阅读
2.1 一图速览

《图解Linux内核(基于6.x)》
京东:https://item.jd.com/14577130.html
2.2 内容简介
- 全书共五篇,以从易到难的顺序详细剖析了Linux内核开发的核心技术。“知识储备篇”介绍了Linux的数据结构、中断处理、内核同步和时间计算等内容,这些是理解后续章节的前提;之后通过“内存管理篇”“文件系统篇”“进程管理篇”详细介绍了Linux的三大核心模块;最后的“综合应用篇”则融合了前面诸多模块知识展示了Linux内核开发在操作系统、智能设备、驱动、通信、芯片、云计算和人工智能等热点领域的应用。书中的重点、难点均配有图表、代码和实战案例,力求直观、清晰。
- 学习本书的读者需要熟悉C语言,建议对Linux内核有一定了解。推荐初学者按照本书的编排顺序阅读,而熟悉Linux内核的读者可以跳过知识储备篇,直接从三大核心模块篇进行阅读。



















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











